商务分析——文本挖掘三个案例分析
三个案例
挖掘顾客评价,研究顾客满意度以改进生鲜电商平台
研究背景
在数字乡村发展战略指导下,我国生鲜电商进入了快速发展期。提高顾客转换率和留存率是生鲜电商赖以生存的关键,对顾客评价数据进行情感挖掘,将有助于把握顾客关注重心,优化供给,改善生鲜电商的产品和服务,提高顾客满意度,增强用户黏性,从而推动生鲜电商的发展。
研究过程
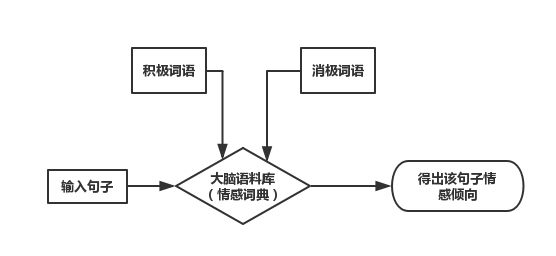
收集京东生鲜产品评论,通过高频词特征、语义网络和情感分析等方法,深入探究生鲜电商顾客的关注点和情感倾向。案例使用的是基于情感词典的情感分析方法,通过情感词典对文本中的词语进行分析和匹配,根据一定的规则计算出情感值,从而判断出文本的情感倾向。
数据获取
编写Python程序进行爬虫,爬取各个商品从2020年3月1日到2021年6月30日的评论,总共获得8 580条评论数据,其中新鲜水果2 990条、海鲜水产1 400条、精选肉类1 400条、冷饮冻食1 390条、蔬菜蛋品1 400条。包括4 990条好评,1 790条中评,1 800条差评。
基于词云图的特征分析
词云图将文本数据中的高频词汇清晰明了地展示出来,直观表达文本数据的意思,对大量文本数据进行可视化分析。通过对词云图进行分析,可以清楚得到在线评论的主题,可以了解消费者比较关注的因素。



京东生鲜的消费者对商品的关注点的关键词为新鲜、好吃、不错、满意、味道、质量、包装、口感、价格、物流、客服、服务、性格比等,说明消费者对产品全方面关注。
基于网络语义图的特征分析
语义网络由节点和有向线段组成,节点代表常识概念,有向线段代表这些概念之间的关系。通过对网络语义图的分析,可以突出中心词,以及展示与中心词紧密联系的词语。采用ROST CM 6文本挖掘软件对在线评论文本进行社会网络和语义网络分析。
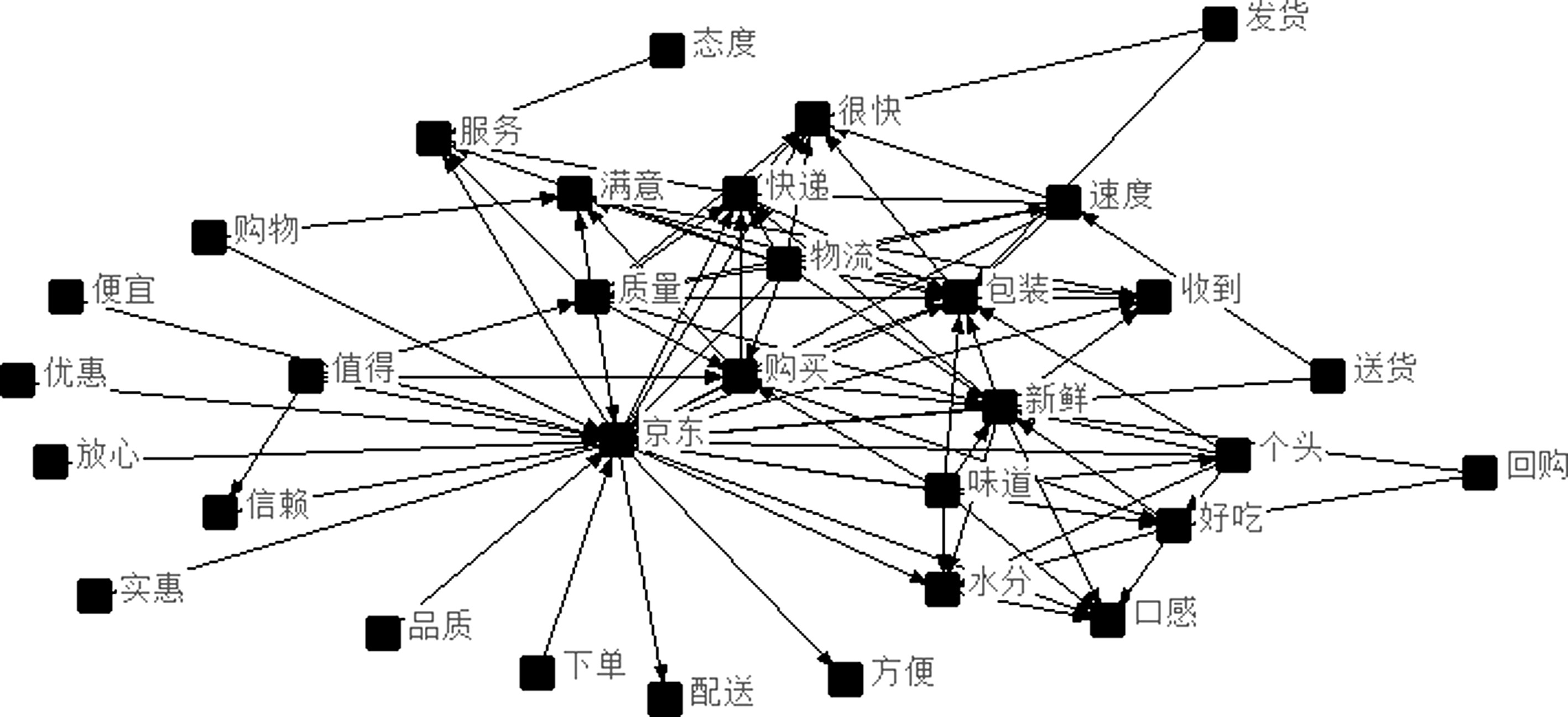
此外,“质量”“物流”“包装”“服务”等是网络语义图的核心节点,说明在线评论文本大量提及质量、物流、包装和服务。与“质量”一词紧密联系的情感词是“满意”和“新鲜”,与“物流”一词紧密联系的情感词是“很快”和“满意”,与“包装”一词紧密联系的情感词是“满意”,与“服务”一词紧密联系的词是“态度”。总的来说,消费者对京东生鲜各方面都较为满意,持正面评价。
测算顾客满意度
通过结巴分词对在线评论文本进行分词,然后进行词频统计。将高词频的词汇中明显与主题不相关的词语进行筛选,提取出在线评论文本中的高频特征词。通过K-means聚类算法对在线评论进行聚类,最终确定k=5,则将从物流、包装、服务、质量和价格这5个维度来衡量生鲜电商的顾客满意度。
| 特征词 | 相似词 |
|---|---|
| 物流 | 快递、送货、冷链、发货、速度 |
| 包装 | 破损、严实、完好、精美、箱内 |
| 服务 | 态度、热情、一如既往、客服、周到 |
| 质量 | 品质、品牌、不错、值得、信赖 |
| 价格 | 实惠、活动、经济、划算、便宜 |
依据提取出来的5类特征词,对在线评论文本进行筛选,将各类产品中含有该特征词的在线评论文本进行分类,从而计算各类产品各特征属性的顾客满意度。
| 满意度 | 物流 | 包装 | 服务 | 质量 | 价格 |
|---|---|---|---|---|---|
| 新鲜水果 | 2.56 | 2.12 | 2.98 | 2.34 | 2.96 |
| 海鲜水产 | 2.67 | 2.34 | 2.89 | 2.88 | 2.89 |
| 精选肉类 | 2.56 | 2.23 | 2.67 | 2.87 | 2.87 |
| 冷饮冻品 | 2.67 | 2.34 | 2.89 | 2.88 | 2.89 |
| 蔬菜蛋品 | 2.65 | 1.98 | 3.23 | 2.51 | 2.81 |
消费者对新鲜水果的服务和价格相对比较满意,对海鲜水产和冷冻饮品的服务、价格和质量相对比较满意,对精选肉类的质量和价格相对比较满意,对蔬菜蛋品的包装和价格相对比较满意。整体上,消费者对各类产品的价格和服务的满意度比较高,对包装满意度最低。
产品总体满意度测算
权重反映了消费者在生鲜电商平台上对各项指标的重要程度。常用的权重计算方法有TF-IDF权重、布尔权重和频度权重。运用TF-IDF算法计算物流、包装、服务、质量、价格这5个影响因素在新鲜水果、海鲜水产、精选肉类、冷饮冻食和蔬菜蛋品这5类产品中所占的权重。
| 产品类别 | 物流 | 包装 | 服务 | 质量 | 价格 |
|---|---|---|---|---|---|
| 新鲜水果 | 0.29 | 0.17 | 0.12 | 0.37 | 0.25 |
| 海鲜水产 | 0.37 | 0.13 | 0.13 | 0.56 | 0.41 |
| 精选肉类 | 0.30 | 0.10 | 0.07 | 0.64 | 0.44 |
| 冷饮冻品 | 0.32 | 0.14 | 0.11 | 0.43 | 0.51 |
| 蔬菜蛋品 | 0.34 | 0.11 | 0.11 | 0.60 | 0.22 |
京东生鲜平台上,在质量、价格和物流这3个维度的权重相对更多。
产品满意度计算
为了比较消费者对京东生鲜上各类产品的满意程度,分别计算出新鲜水果、海鲜水产、精选肉类、冷饮冻食和蔬菜蛋品这5类产品的顾客满意度。测算方式是将第i类产品第j个特征的权重与第i类产品第j个特征的顾客满意度相乘再求总和。
| 产品类别 | 新鲜水果 | 海鲜水产 | 精选肉类 | 冷饮冻食 | 蔬菜蛋品 |
|---|---|---|---|---|---|
| 满意度 | 3.066 2 | 4.465 5 | 4.277 5 | 4.212 2 | 3.598 3 |
消费者对京东生鲜上这5类产品的总体满意度排名最高为海鲜水产,排名最低为新鲜水果。
研究结果
研究表明:通过对在线评论进行情感分析,研究得到影响消费者对生鲜电商平台上产品的满意度因素依次为物流、包装、服务、质量和价格。研究结果表明,消费者在电商平台购买生鲜产品时最满意的是海鲜水产,其次为精选肉类,最不满意的是新鲜水果。整体上,消费者对各类产品的价格和服务的满意度比较高,对包装满意度最低。消费者对京东生鲜上不同种类的产品看重的特征不同。比如,对冷冻产品,消费者最看重价格,对其他种类产品,消费者最看重质量。整体上,消费者对京东生鲜的产品更看重质量、价格和物流。电商平台需要进一步扩大优势、加强商品包装、提供人性化服务。
学习心得
针对评论数据的数据清洗
- 文本中含有特殊字符和无意义的英文字符的评论,清除掉无意义字符。
- 由于用户未发表评论系统自动默认的“此用户未填写评价内容”此类评论,直接进行删除。
- 用户直接复制粘贴的重复评论,保留第一条评论。
- 文本中存在大量重复用词,用户存在凑字数的嫌疑,如“我认为这个橘子非常新鲜非常新鲜非常新鲜非常新鲜非常新鲜”,通过机械压缩为“我认为这个橘子非常新鲜”。
- 评论字数非常少的评论,如“很好”“还行”“一般”,这类评论表述模糊不清,不能确定是对商品某方面的评价,用于产品分析时没有什么意义,在进行短句删除处理时,删除掉原评论字符数或者机械压缩后的评论字符数小于等于3个字符的评论。
- 与商品评价完全无关的评论,这类评论需要手动剔除。
文本特征分析的方法
- 基于词云图的特征分析,进行可视化分析,了解用户比较关注的因素。
- 基于网络语义图的特征分析,直观地反映出评估对象与评论之间的联系。
对近义词处理构建特征词词典
由于中文博大精深,一个词语拥有众多表达方式,拥有大量近义词。如果对这类近义词忽略不计的话,将对研究结果产生一定的影响,因此,运用词向量法对特征属性进行相似词语的统计。将表达同一概念的多个同义词转化成表达这个概念的代表词,就可以将原有特征提取从词的层面上升到了主题概念的层面。
| 特征词 | 相似词 |
|---|---|
| 物流 | 快递、送货、冷链、发货、速度 |
| 包装 | 破损、严实、完好、精美、箱内 |
| 服务 | 态度、热情、一如既往、客服、周到 |
| 质量 | 品质、品牌、不错、值得、信赖 |
| 价格 | 实惠、活动、经济、划算、便宜 |
案例改进和扩展应用场景
案例中情感分析的方法是基于情感词典的,该方法的缺点是情感词典的扩充需要大量人力,词的上下文末未考虑情感变化。我认为还可以基于机器学习进行情感分析,抽取评论情感特征后,用常用分类算法对文本进行情感分类,从而得到文本的情感倾向。比如使用卷积神经网络CNN、支持向量机SVM、KNN等算法进行情感分类。机器学习的泛化能力强,对短文本、白话语句效果突出。
该案例的方法还可以应用到其他场景。例如,餐饮店可以根据美团、大众点评上用户提出的差评进行情感分析,找出用户差评主要的关键词,比如“脏”、“乱”、“贵”、“难吃”、“上菜”、“服务”等,店家可以根据这些关键词制定方案进行改进,比如“脏”可以重点关注店面环境,“难吃”可以换厨师,“上菜”需要提高上菜速度,“服务”需要对服务员进行更多的培训。
基于文本挖掘的游客对古镇旅游态度的分析
研究背景
随着“互联网+”时代的到来,“互联网+旅游”模式开始进入人们的生活,越来越多的游客会在结束旅程后在互联网上分享旅游体验。
研究过程
统计词频寻找属性特征
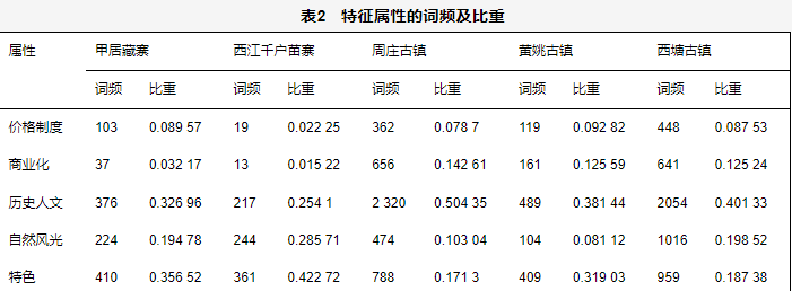
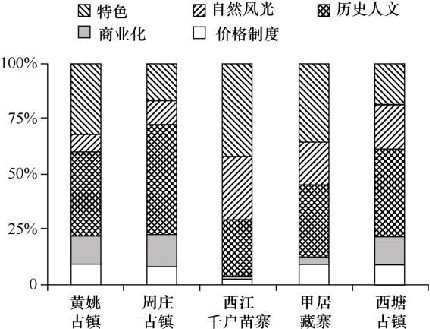
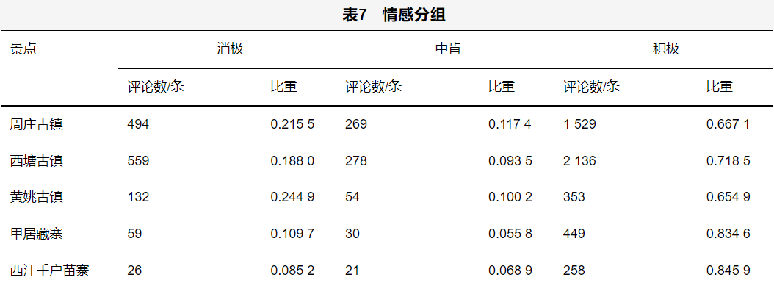
围绕游客的反馈,分析古镇旅游项目存在的问题及游客的态度。选取了5个各具特色的古镇——甲居藏寨、西江千户苗寨、周庄古镇、黄姚古镇、西塘古镇作为参考。利用大量的评论进行文本挖掘、统计词频,分析热门话题。再运用情感分析得到评分,进而分析游客的好感度及可能影响评价的因素。最后,结合因子分析建立综合模糊评分模型,以计算古镇旅游的最终得分。研究结果可作为参考,以此优化改善古镇旅游体验,保护历史文明遗址。案例中一共采集了6 647条分别关于甲居藏寨、西江千户苗寨、周庄古镇、黄姚古镇、西塘古镇的评论。将采集到的评论进行分词处理,即依据语义将一句话切分成一个个的词。依据统计的各景点的词频制作词云图,让统计结果更加直观,便于寻找主要属性特征。
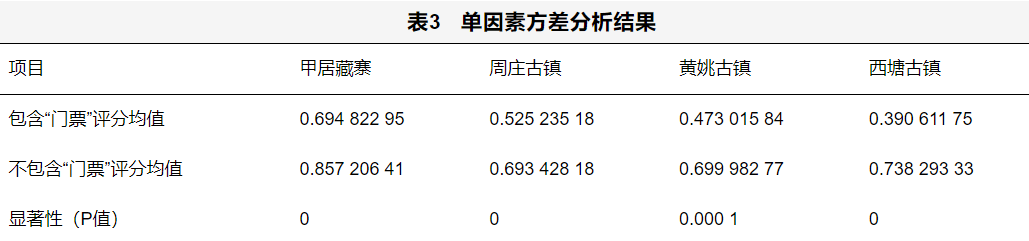
单因素方差分析
单因素方差分析用来分析一个因素是否明显造成两组数据的不同。其中,实验结果P值是决定是否接受原假设的关键阈值,它体现了实验组别之间差别的显著性。如果P值小于0.05,就有统计意义;如果大于0.05,说明所有组别都没有差别,即这个因素不对样本造成影响。在景点属性里,评论展现了人们对景区的价格制度具有较多的负面评价,而门票价格是价格制度里的主要组成。为证实人们确实不满意景区的收费制度,以门票为因素,假设其不对评论结果造成影响,进行单因素方差分析。若实验结果P值小于0.05,拒绝原假设,并认为门票制度确实对评价结果造成显著差别。基于情感分析输出结果,对各古镇门票进行单因素方差分析。先将包含“门票”一词的评论和没有该词的评论分开,单独构成数据,再进行单因素方差分析。图表没有包括西江千户苗寨的方差分析结果,原因是只有该古镇的实验结果P值大于0.05,“门票”因素才不造成显著影响,无需进一步讨论。观察图表可知,门票确实对甲居藏寨、周庄古镇、西塘古镇、黄姚古镇的游客的评分造成显著影响。并且包含门票的评分均值都低于不包含门票的评分。
模糊综合评价模型
每个古镇由于地理位置、开发程度和所在地的经济发展等因素不同,游客的好感度也会受影响。有的省份注重旅游业的发展,旅游市场规划和管理得较好,且服务业的发达程度也会影响人们的满意度。为了对古镇的旅游作出最终评分,构建了一个模糊综合评分模型。由于旅游业属于第三产业,为了方便获取数据,笔者取各景区所在地的第三产业占比作为因子分析的数据。目的是依据各地的第三产业的重要性决定各景区的权重。把5个景点当作5个不同的属性,旅游业发展规划良好的地区应赋予较大权重。
因子分析的基本目的就是用少数几个因子描述许多指标或因素之间的联系,即将比较密切的几个变量归在同一类中,每一类变量就成为一个因子,以较少的几个因子反映原资料的大部分信息。每个因子中,因子载荷越大,说明该因子对结果的贡献越大。运用因子分析可以得到景区所属地区的第三产业的贡献率,即可得到各地区的旅游业权重。所谓权重,是指某指标在整体评价中的相对重要程度。权重越大,则该指标的重要性越高,对整体的影响就越高。
为了得到总体游客的态度,不能单纯地计算评分结果的均值。原因是游客的评价通常不是单一的积极或消极这么简单。机器计算结果是基于字面表达上的积极词和消极词得来的。但是具体评判分值只依据一段文字表达不够准确。建立模糊评价模型可以包容情感分析带来的文字到数值转化的误差。而且由于模糊的方法更接近东方人的思维习惯,因此更适合对社会经济系统问题进行评价。
研究结果
- 游客选择古镇旅游,关注度最高的是其文化价值,其次是各个古镇的特色及环境。随着景区的开发,商业气息趋严重。而伴随着商业化的同时,每个古镇的特色会削弱,对游客的体验造成负面影响。游客对景区里的消费也十分敏感,在黄姚古镇、西塘古镇、周庄古镇,游客对商业化感受比重占到了12%以上,应该引起有关部门的重视,予以管束,在开发特色旅游的同时,保护景区的环境,营造良好的历史文化氛围。
- 除了不适当的商业化影响游客对古镇旅游的态度,消费制度也是关注热点。本文研究了游客对价格制度的态度及其影响。结论基于对门票价格的分析,游客确实对收费制度敏感,且对收费敏感的游客均持负面评价。在选取的5个研究对象里,只有一个古镇的游客表示门票等收费合理。大部分游客认为景区内物非所值,甚至抱怨有不透明收费的现象。这种充斥着消费气息的古镇旅游项目不利于长久发展。景区应结合自身的服务设施等调节景区内消费价格,整改冗余的收费项目。有关部门应予以管制,规范旅游市场。
学习心得
如何比较两组数据的变化趋势是不是有显著性差异
这其实是两个问题,即这两组数的变化趋势是否一致?这两组数是否有差异?
第一个问题:这两组数的变化趋势是否一致?分析两组数的变化趋势是否一致,应当选用相关性分析。
相关性分析,是指分析两组或多组数据间联系紧密程度的分析方法,通常用来分析和评估两组或多组数据的变化趋势是否一致。
假设这两组数据都是连续型变量,则选用皮尔逊相关系数,也叫线性相关系数。可以看出,数据A和数据B的相关系数为98.9%,为强相关,即数据A和数据B的变化趋势非常一致。
第二个问题:这两组数是否有差异?分析两组数是否有差异,应当选用方差分析。
方差分析,是分析两组或多组数据之间是否存在差异,以及差异显著性的分析方法,通常分为单因素方差分析和双因素方差分析。
模糊综合评价模型
在对某一事务进行评价时常会遇到这样一类问题,由于评价事务是由多方面的因素所决定的,因而要对每一因素进行评价;在每一因素作出一个单独评语的基础上,如何考虑所有因素而作出一个综合评语,这就是一个综合评价问题。
模糊评价的基本思想许多事情的边界并不十分明显,评价时很难将其归于某个类别,于是我们先对单个因素进行评价,然后对所有因素进行综合模糊评价,防止遗漏任何统计信息和信息的中途损失,这有助于解决用“是”或“否”这样的确定性评价带来的对客观真实的偏离问题。
简单地说模糊综合评价模型就是对评价对象就评价指标进行综合评判,最后给每个评价对象对于每个指标一个隶属度。
评判三号学生,学习成绩好或者不好、思想品德好或者不好、身体好或者不好听起来是不是就很模糊?怎么样就算学习成绩好了或者思想品德好了或者身体好了?其实这些指标就是模糊的概念。
标准假如就是评上和评不上。用模糊综合评价法得到的最终结果就是这名学生对于评上的隶属度和评不上的隶属度。假如评上的隶属度高一些,那这名学生肯定是被评上。
公安犯罪案件文本挖掘关键技术
研究背景
目前公安部门面临的一个主要问题就是如何对日益增长的包含涉案人员、涉案物品、户籍、简要案情文本等信息数据的大量案件进行准确和有效的分析。因此面对复杂的犯罪形势,面对日益庞大的公安信息量,迫切需要应用人工智能相关技术,对数据进行深层次的分析、研究各类信息的规律和关系、进一步挖掘各类信息的作用以更好地打击犯罪、防控犯罪。因此将数据挖掘技术有效地应用于犯罪分析是目前公安工作的迫切需要。
犯罪案件文本特征
案件文本主要来自于两部分,一是来自现有犯罪数据库中的自由文本案情描述。二是来自公安内部网络上的案情公告。
不管是犯罪数据库的自由文本案情描述还是公安内部网络的案情公告这些案件文本都具有以下的特征:
- 文本篇幅短小、属于短文本类型。现有案件文本长度主要在字之间属于短文本类型。
- 包含大量案件属性信息。一个案件文本主要包含以下属性信息作案时间、作案地点、涉案人员、作案手段、作案工具、损失物品、损失金额等。
由于犯罪数据库的自由文本案情描述及公安内部网络的案情公告,具有以上共同的特征,因此两种数据源在文本挖掘过程中具有共性。
犯罪案件文本挖掘的一般流程
根据公安部门案件串并分析的需要,重点研究为串并案业务人员提供文本挖掘的相关功能。犯罪案件文本挖掘的一般流程如下图。
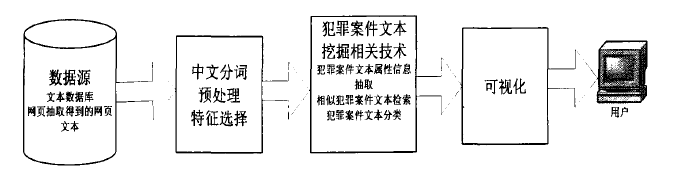
犯罪案件挖掘的一般流程与传统的文本挖掘-般流程相似。在犯罪案件文本挖掘相关技术中,主要包含三种技术:犯罪案件文本属性信息抽取,相似犯罪案件文本检索,犯罪案件文本分类。具体描述如下:
(1) 犯罪案件文本属性信息抽取是从案件文本中自动识别出人名,地名,作案手段,作案工具等属性,抽取的结果主要用于相似犯罪案件文本检索。
(2)相似犯罪案件文本检索实现了检索出与给定案件文本相似的案件文本集的方法,并对这些案件文本集按相似度大小排序。
(3)犯罪案件文本分类在给定犯罪案件类别分类体系的前提下,实现根据案件文本的内容自动判别文本所属的案件类别的方法。
学习心得
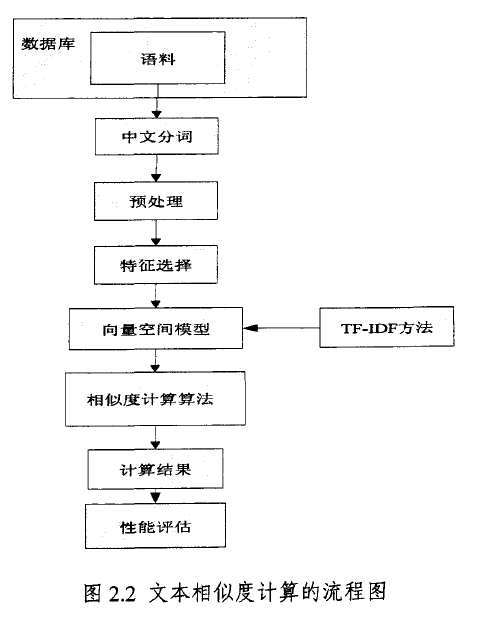
文本相似度计算的一般流程
文本相似度计算一般包含中文分词与处理、特征选择、将文本表示成向量空间模型、结合TF-IDF方法计算向量的权重、再利用相似度计算算法计算文本的相似度、最后得到结果等几个过程。
文本分类的一般流程
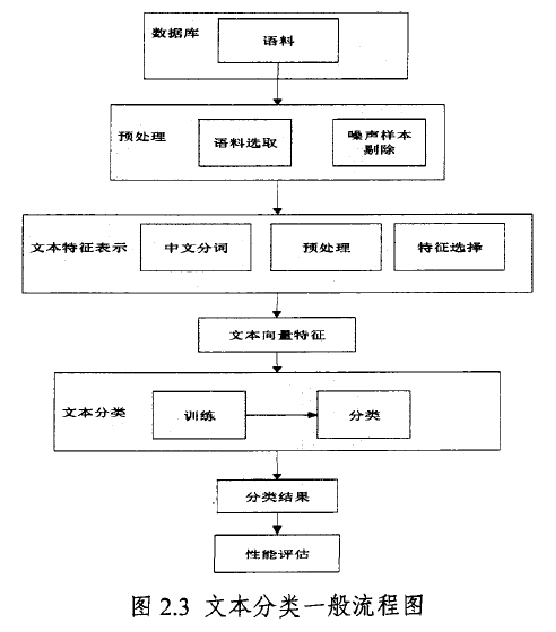
文本分类过程包含语料库构建、中文分词与预处理、特征选择、文本特征向量表示、文本分类和分类性能评估阶段。文本分类的一般流程图如下图。
预处理去停用词
对于案件文本分类,案件文本常常包含出现频率非常高但对文本分类无关的词例如“犯罪嫌疑人”、“受害人”、“价值”、“报案”等即公安领域的专用停用词。
停用词是在文本集合中出现频率很高,但是无用的词,如“的”、“了”、“还是”、“或者”等。去除这些词可以降低特征词的维度,同时可以提高挖掘效果。
朴素贝叶斯算法
在案件文本分类中,由于案件文本具有文本短小、出现单词频率低等特点,因此多变量贝努里模型适用于案件文本的表示。然而由于犯罪案件具有类别分布不均衡的特点,多变量贝努里模型在类别分布不均衡的时候,即当训练集各个类别所包含的文本数目差异较大时,将会影响分类的准确率。因此采用了改进型的多变量贝努里模型。
由于案例的改进型模型数理方面过于复杂,暂不做深入研究。而是学习了解了朴素贝叶斯算法的基本原理。
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。

朴素贝叶斯算法是假设各个特征之间相互独立! 这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
朴素贝叶斯分类器通常有两种实现方式:
- 基于贝努利模型,贝努利模型只考虑文本词汇是否出现而不考虑出现次数,这在最后的朴素贝叶斯分类器函数的编写上带来了很大的便利,第一个例子先使用贝努利模型简单尝试。
- 基于多项式模型,多项式模型考虑词在文档中出现的次数,使得出现频率不同的词被赋予了不同的权重。将在第一种模型的基础上实现。
学习资料
京东商品评论情感分析|语义网络分析 - 知乎 (zhihu.com)
传统情感分类方法与深度学习的情感分类方法对比_舞月月月月的博客-CSDN博客_情感词典的缺点
情感分析了解一下?一个比情感词典、机器学习更好的方法 - 云+社区 - 腾讯云 (tencent.com)
公安犯罪案件文本挖掘关键技术研究 - 道客巴巴 (doc88.com)
从零开始word2Vec详解 - 知乎 (zhihu.com)
[NLP] 秒懂词向量Word2vec的本质 - 知乎 (zhihu.com)
词向量余弦算法计算文本相似度_lazycece的博客-CSDN博客_词向量相似度
自然语言处理=======python利用word2vec实现计算词语相似度【gensim实现】_不良使的博客-CSDN博客_word2vec计算词的相似度
带你理解朴素贝叶斯分类算法 - 知乎 (zhihu.com)
TF-IDF算法(原理+python代码实现)_迪迦瓦特曼的博客-CSDN博客_tf-idf
机器学习算法——朴素贝叶斯(贝努利模型和多项式模型实现分类)_零壹博弈的博客-CSDN博客_朴素贝叶斯应用实例
Web 挖掘和文本挖掘|之间的差异Scion Analytics
Bitcoin movement prediction with text mining | IEEE Conference Publication | IEEE Xplore
[PDF] Web Crime Mining by Means of Data Mining Techniques | Semantic Scholar
Microsoft Word - 11575 Tamplate- (semanticscholar.org)
Microsoft Word - 11575 Tamplate- (semanticscholar.org)
(PDF) Investigating Crimes using Text Mining and Network Analysis (researchgate.net)
Predicting Crime and Other Uses of Neural Networks in Police Decision Making - PMC (nih.gov)
https://aircconline.com/ijdkp/V9N3/9319ijdkp02.pdf
如何比较两组数据的变化趋势是不是有显著性差异? (baidu.com)
使用深度学习技术对一组电影评论进行情感分析 - ScienceDirect
https://popups.uliege.be/0037-9565/index.php?id=5371&file=1
生鲜电商顾客网络评价数据的文本挖掘研究 - 中国知网 (cnki.net)
基于Python文本挖掘的湛江旅游目的地形象感知研究 - 中国知网 (cnki.net)
Text mining approaches for stock market prediction | IEEE Conference Publication | IEEE Xplore
模糊综合评价模型_The__Tyche的博客-CSDN博客_模糊综合评价模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号