Python 康德乐大药房网站爬虫,使用bs4获取json,导入mysql
 自学两天,写个low点的爬虫代码。自己获取商品价格接口的过程,使用软件 Fiddler 进行抓包进行分析。调用接口进行异常判断
自学两天,写个low点的爬虫代码。自己获取商品价格接口的过程,使用软件 Fiddler 进行抓包进行分析。调用接口进行异常判断
故事开端
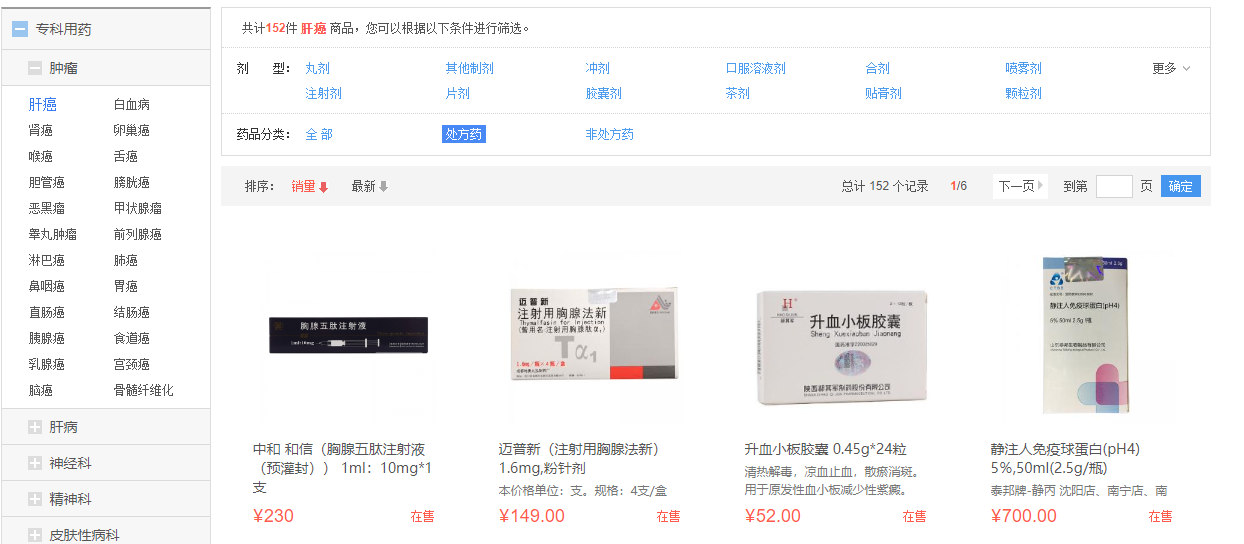
目标地址
https://www.baiji.com.cn 康德乐大药房
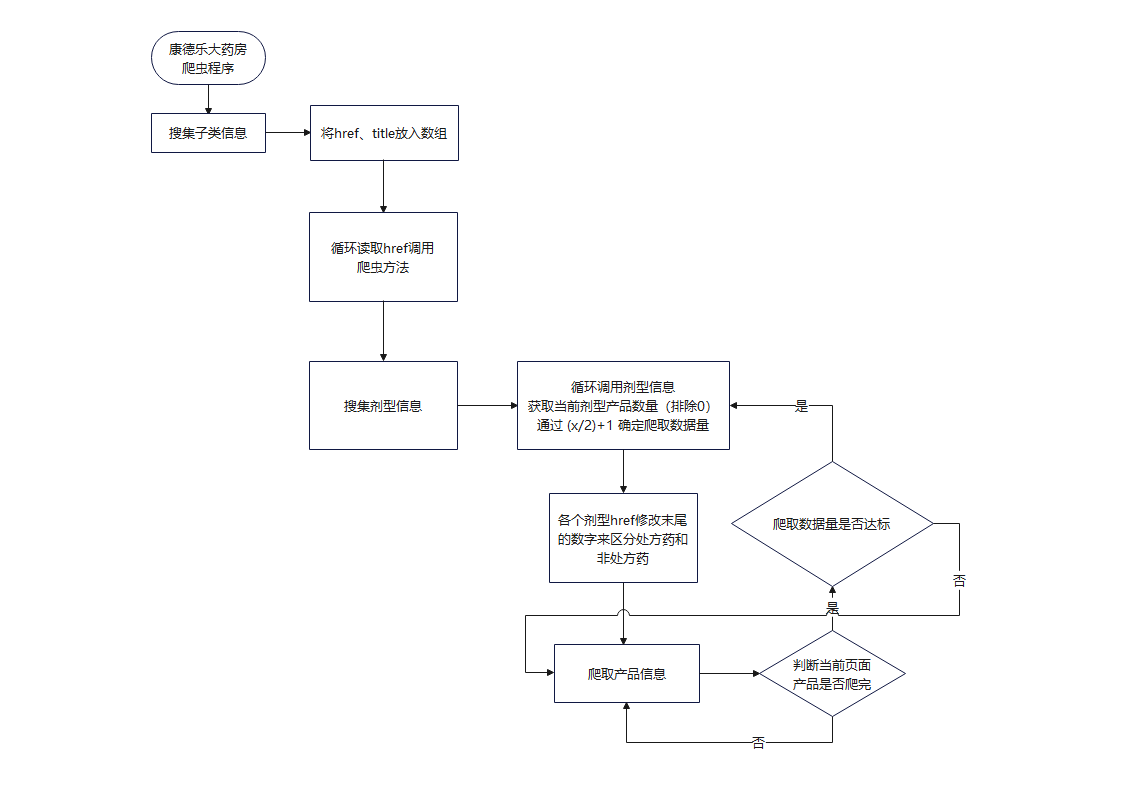
程序流程
"爬取数量是否达标"这块没有写代码,因为我发现单页数量够多了,每页爬一半数据大概有8000条
获取商品价格接口
我发现商品价格在soup结构里面没有生成,是空值,应该是动态请求加载的。
就讲一下这部分接口我是怎么获取的吧,使用软件 Fiddler 进行抓包,如果你不知道这是什么 Fiddler使用方式
随便打开一个网站
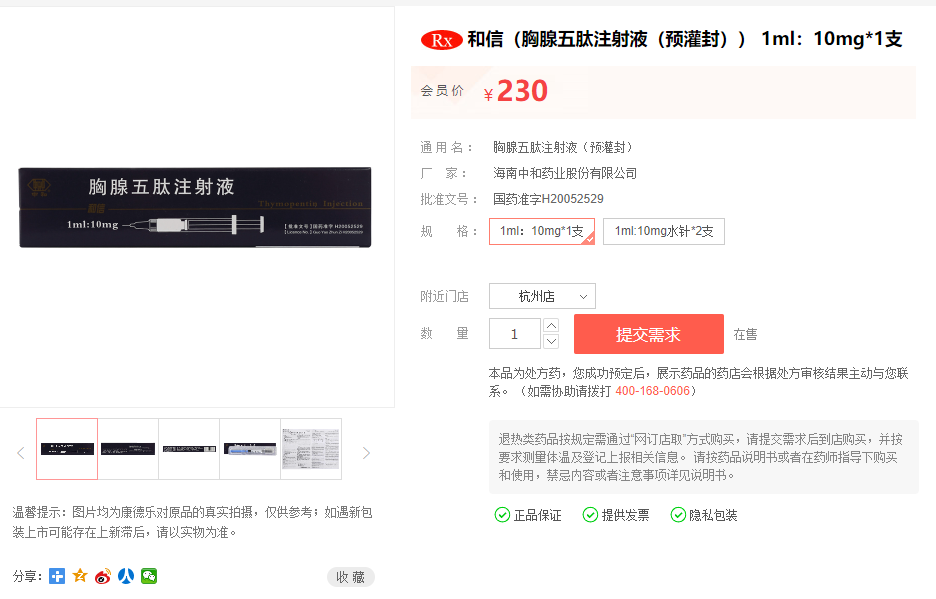

可以看到请求的地址,这是一个 get 请求,包含了三个参数分别是 jsonp+时间戳、act 方法、goods_id 商品id,返回体是一个json,显示商品价格(注意!商品可能缺货会返回 {"price":"特价中"},所以要做判断处理,可以看 spider.py 里的 product() 函数)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True可以看到我们先处理了 jsonp 转化为 json 对象,对取得的 json 的 price 键对应值进行 float 类型转换,如果转换失败会抛出异常,我们使用 try: ? expect: ? 的方式进行判断
代码
代码写的很难看,但是能用,Wow!It just works!
work.py
import os
import json
import threading
import requests
import re
import time
from spider import Spider
from bs4 import BeautifulSoup
class MyThread(threading.Thread):
"""重写多线程,使其能够返回值"""
def __init__(self, target=None, args=()):
super(MyThread, self).__init__()
self.func = target
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误
except Exception:
return None
host = "https://www.baiji.com.cn"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
res = requests.get(host, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
item_list = soup.find_all(class_='tcon')
items = []
for item in item_list:
a = item.find_all('a')
for i in a:
href = i['href'].strip('// http:')
title = i['title']
if re.search('category', href) != None:
items.append((href, title))
# ^ only for test 暴力开启多线程
infos = []
threads = []
start = time.perf_counter()
for item in items:
t = MyThread(target=Spider, args=(item,))
threads.append(t)
t.start()
print('启动!')
# ^ 等待所有子线程结束,主线程再运行
for t in threads:
t.join()
result = t.get_result()
infos.extend(result)
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(infos, indent=4, ensure_ascii=False))
exit()
spider.py
import time
import os
import json
import requests
import re
from bs4 import BeautifulSoup
COUNT = 0
host = "https://"
host_ = "https://www.baiji.com.cn/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
path = os.path.dirname(__file__)
# ^ 主入口
def Spider(item):
# temp = []
# isPrescription = False
category = item[1]
classes = CatchClasses(item[0])
infos = GoPage(classes, category)
return infos
# ^ 获取所有剂型
def CatchClasses(url):
res = requests.get(host+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
temp = soup.find(class_="det").find_all('a')
classes = [a['href'] for a in temp]
titles = [a['title'] for a in temp]
return [classes, titles]
# ^ 进行爬虫
def GoPage(classes, category):
isPrescribed = True
length = len(classes[0])
href = classes[0]
titles = classes[1]
infos = []
for index, h_ in enumerate(href):
Collect(h_, '-0.html', titles, index, category, infos)
# ---------------------------------------------------------------------------- #
Collect(h_, '-1.html', titles, index, category, infos)
print('已处理', COUNT, '个商品')
return infos
def Collect(h_, add, titles, index, category, infos):
h = h_.replace('.html', add)
url = host_ + h
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
# ^ 获取该类别共几条商品记录
target = re.findall(r'共计<strong class="red">\d+</strong>', res.text)
target = re.search(r'\d+', target[0]).group(0)
target = int(target)
# ^ 如果商品记录为 0 直接跳过
if target != 0:
# ^ 减少爬的数据量
target = int(target/2+1)
print(titles[index], "需要获取的数据条目", target)
isPrescribed = False
products = GetProducts(h)
print("非处方页面共有", len(products), "个商品", time.ctime())
for product in products:
info = Product(product, index)
info['category'] = category
info['isPrescribed'] = isPrescribed
info['class'] = titles[index]
infos.append(info)
# ^ 获取当前页面所有产品
def GetProducts(url):
res = requests.get(host_+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
products = soup.find_all(class_='pro_boxin')
return products
# ^ 解析jsonp对象
def loads_jsonp(_jsonp):
try:
return json.loads(re.match(".*?({.*}).*", _jsonp, re.S).group(1))
except:
raise ValueError('Invalid Input')
# ^ 获取指定商品信息
# @ info 传入一个 class = pro_boxin 的soup对象
def Product(p, category):
global COUNT
COUNT += 1
a = p.find(class_="name").a
isStockOut = False # IMPORTANT
productname = a['title'] # IMPORTANT
QuantityPerunit = a.contents[0].strip().split(' ')[1] # IMPORTANT
describe = a.span.string # IMPORTANT
img = p.find('img')
try:
imageSrc = img['data-original'].strip('//') # IMPORTANT
# ^ 下载图片到本地
imageSrc = DownloadPic(imageSrc, category)
except:
imageSrc = None
# ^ 准备获取商品页面
href = a['href'] # IMPORTANT
# print(productname, unit, href)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True
# print(price)
return dict(
productname=productname,
QuantityPerunit=QuantityPerunit,
unitprice=price,
isStockOut=isStockOut,
notes=describe,
imageSrc=imageSrc
)
def DownloadPic(src, category):
category = str(category+1)
# print(src)
fileName = src.split('/')
fileName.reverse()
fileName = fileName[0].strip('/')
# print(fileName)
pic = requests.get(host+src)
savePath = path+'/goods_img/'+category+'/'
isExists = os.path.exists(savePath)
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(savePath)
with open(savePath+fileName, 'wb') as b:
b.write(pic.content)
return '/goods_img/'+category+'/'+fileName
json_to_mysql.py
import os
import json
import random
import mysql.connector
path = os.path.dirname(__file__)
db = mysql.connector.connect(
host="localhost",
user="root",
passwd="sql2008",
database="test",
auth_plugin='mysql_native_password'
)
cursor = db.cursor()
with open(path+'/data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data[0], len(data))
cursor.execute("SELECT categoryid, categoryname FROM t_categorytreeb")
res = cursor.fetchall()
categoryid = [i[0] for i in res]
categoryname = [i[1] for i in res]
print(categoryname.index('丙肝'))
cursor.execute("SELECT supplierid FROM t_suppliers")
res = cursor.fetchall()
suppliers = [i[0] for i in res]
print(suppliers)
# ^ 插入数据
sql = "INSERT INTO t_medicines(ProductName,QuantityPerunit,Unitprice,SupplierID,SubcategoryID,Photopath,notes,ytype,isPrescribed,isStockOut) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
val = [
]
print()
for item in data:
try:
# print(item['category'], categoryname.index(item['category']))
index = categoryname.index(item['category'].strip())
cid = categoryid[index]
except:
cid = None
val.append((
item["productname"],
item["QuantityPerunit"],
item["unitprice"],
random.choice(suppliers),
cid,
item["imageSrc"],
item["notes"],
item["class"],
item["isPrescribed"],
item["isStockOut"]
))
cursor.executemany(sql, val)
db.commit()
print(cursor.rowcount, "was inserted.")数据集
2020_3/data.zip (80MB)包括图片
故事结尾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号