Python Requests 速通爆肝、这么牛逼的库你还不会用吗?
 上网原理
爬虫原理
Get、Post
Requests 介绍
安装
常用方法
Http协议
开发者工具网络界面
Response对象
下载保存一张图片、一首音乐
添加Headers发送请求
判断HTTP状态码
Post文件上传
获取Cookies
RequestsCookieJar
会话维持
Session()
Cookies维持登录状态
InvalidHeader
重定向与请求历史
SSL 证书验证
设置代理
超时设置
自定义身份验证
异常处理
转换成JSON
Url编码
响应体内容工作流
块编码请求
回调钩子
流式请求
其他操作
上网原理
爬虫原理
Get、Post
Requests 介绍
安装
常用方法
Http协议
开发者工具网络界面
Response对象
下载保存一张图片、一首音乐
添加Headers发送请求
判断HTTP状态码
Post文件上传
获取Cookies
RequestsCookieJar
会话维持
Session()
Cookies维持登录状态
InvalidHeader
重定向与请求历史
SSL 证书验证
设置代理
超时设置
自定义身份验证
异常处理
转换成JSON
Url编码
响应体内容工作流
块编码请求
回调钩子
流式请求
其他操作
资料
Requests文档:Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
反馈请求信息测试平台:httpbin.org
本文章所有代码Response对象变量统一命名为 response 或 res
浏览器上网原理
浏览器接受链接后,会寻找链接的地址,这个地址的主人也是一台电脑(不过是超级电脑,也叫服务器,支持大量文件的存储和计算),我们访问的网页就是这台电脑(服务器)上的某个文件,如果文件被删除了,我们就找不到啦。
浏览器找到服务器后,会发送一个请求过去,告诉服务器我们需要访问上面文件。
服务器收到请求后,会把文件发送给浏览器,这一步叫响应。
先请求后响应,用爬虫程序实现发送请求接受服务器的响应,就是我们的任务啦。
爬虫原理
1
2 什么是爬虫?
3 爬虫指的是爬取数据。
4
5 什么是互联网?
6 由一堆网络设备把一台一台的计算机互联到一起。
7
8 互联网建立的目的?
9 数据的传递与数据的共享。
10
11 上网的全过程:
12 - 普通用户
13 打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
14
15 - 爬虫程序
16 模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
17
18 浏览器发送的是什么请求?
19 http协议的请求:
20 - 请求url
21 - 请求方式:
22 GET、POST
23
24 - 请求头:
25 cookies
26 user-agent
27 host
28
29 爬虫的全过程:
30 1、发送请求 (请求库)
31 - requests模块
32 - selenium模块
33
34 2、获取响应数据(服务器返回)
35
36 3、解析并提取数据(解析库)
37 - re正则
38 - bs4(BeautifulSoup4)
39 - Xpath
40
41 4、保存数据(存储库)
42 - MongoDB
43
44 1、3、4需要手动写。
45
46 - 爬虫框架
47 Scrapy(基于面向对象)
48
49 使用Chrome浏览器工具
50 打开开发者模式 ----> network ---> preserve log、disable cacheGet、Post 介绍
一般而言,我们所用的 HTTP 协议或 HTTPS 协议,使用的请求方式只有 GET 方式和 POST 方式。
- GET 方式: 访问某个网页前不需要在浏览器里输入链接之外的东西,因为我们只是想向服务器获取一些资源,可能就是一个网页。
- HTTP默认的请求方法就是GET
- 没有请求体
- 数据必须在1K之内
- GET请求数据会暴露在浏览器的地址栏中
- POST 方式:访问某个网页前需要在浏览器里输入链接之外的东西,因为这些信息是服务器需要的。 比如在线翻译,我们需要输入点英文句子,服务器才能翻译吧。
- 数据不会出现在地址栏中
- 数据的大小没有上限
- 有请求体
- 请求体中如果存在中文,会使用URL编码!
判断Get、Post请求
- 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
- 点击页面上的超链接也一定是GET请求
- 提交表单时,表单默认使用GET请求,但可以设置为POST
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据!
Requests 官方介绍(笑死人)
Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
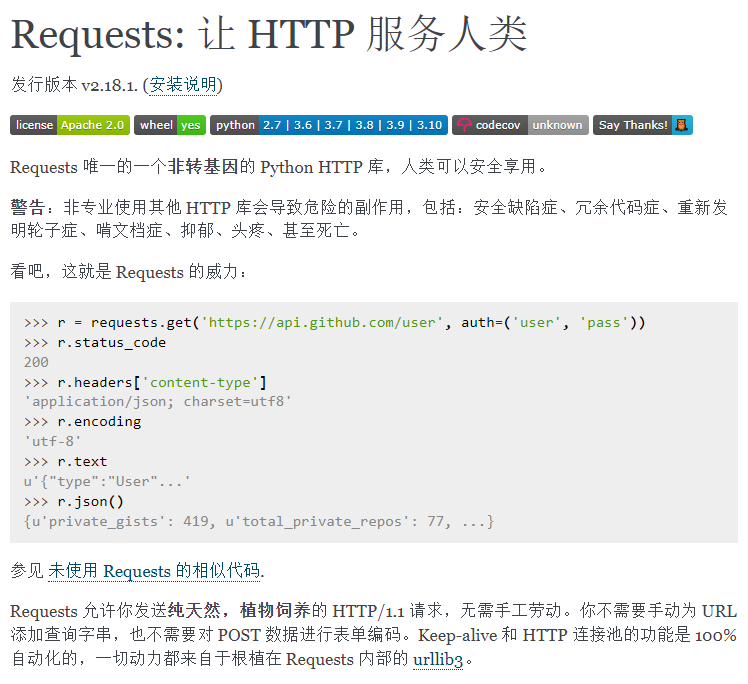

安装 Requests
终端输入 pip3 install requests
Requests 常用方法
- get() 方法能向服务器发送了一个请求,请求类型为 HTTP 协议的 GET 方式
- post() 方法也能向服务器发送一个请求,请求类型是 HTTP 协议的 POST 方式
Http 协议
请求url:
https://www.baidu.com
请求方式method:
GET、Post、Put、Delete、head、options...
请求头headers:
Cookie: 可能需要关注
User-Agent: 用来证明你是浏览器
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36
Host: www.baidu.com
注意: 去浏览器的request headers中查找
开发者工具网络界面
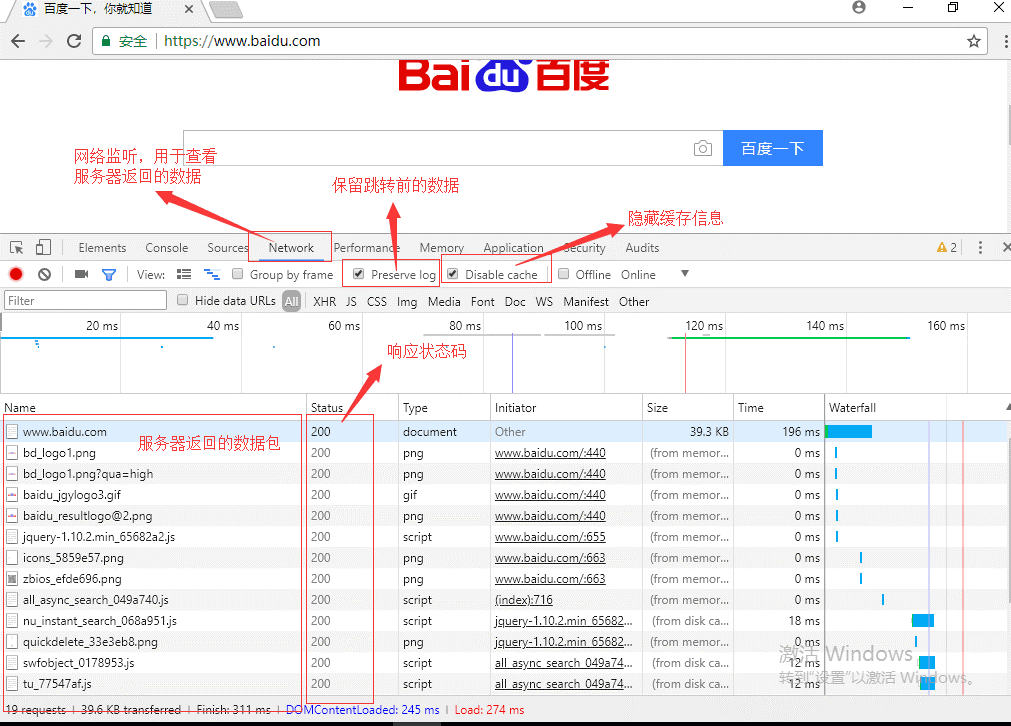
轻松上手
import requests
# ^ 引入 requests,实现请求
URL = 'http://www.weather.com.cn/data/sk/101010100.html'
# ^ 输入在浏览器的网址
res = requests.get(URL)
# ^ 发送 GET 方式的请求,并把返回的结果(响应)存储在 res 变量里头
# ^ get() 方法需要输入一个网页链接
print(type(res))
# ^ 通过 type 查看返回的数据是什么对象.
res.encoding = 'UTF-8'
print(res.content)
print(res.text)
# ^ 修改encoding编码,输出正确的内容
Response 对象
| 属性 | 功能 | 例子 |
|---|---|---|
| Response.status_code | 检查请求是否成功 | 200 代表正常,404 代表网页不存在。 |
| Response.encoding | 定义编码 | 如果编码不对,网页就会乱码的。 |
| Response.content | 把数据转成二进制 | 用于获取图片、音频类的数据。 |
| Response.text | 把数据转为字符串 | 用于获取文本、网页原代码类的数据。 |
Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。Response 就是响应数据 res 的对象类型。
print(response.status_code) # 获取响应状态码
print(response.url) # 获取url地址
print(response.text) # 获取文本
print(response.content) # 获取二进制流
print(response.headers) # 获取页面请求头信息
print(response.history) # 上一次跳转的地址
print(response.cookies) # # 获取cookies信息
print(response.cookies.get_dict()) # 获取cookies信息转换成字典
print(response.cookies.items()) # 获取cookies信息转换成字典
print(response.encoding) # 字符编码
print(response.elapsed) # 访问时间下载保存一张图片
import requests
import os
# ^ 获取图片内容
cat = requests.get('https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/lazy.jpeg')
# ^ 打印响应cat的类型,响应内容cat.content的类型
print(type(cat),type(cat.content))
# ^ 获取当前代码目录
path = os.path.dirname(__file__)
# ^ 尝试打开文件,如果不存在就创建,以二进制的形式,赋给f变量后写入 cat.content 二进制数据
with open(path + '/lazy.jpg', 'wb') as f:
f.write(cat.content)
关于 open 函数第二个参数:
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
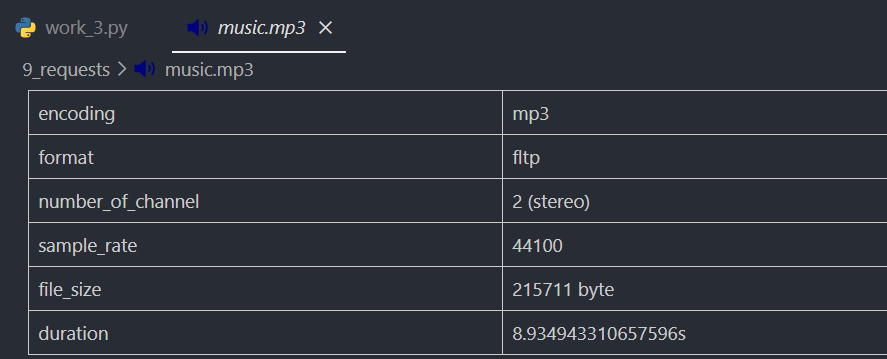
下载保存一首音乐
print(res.status_code) # 查看网页状态,200 表示正常
import requests
import os
# ^ 获取音乐内容
music = requests.get('https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/%E6%AC%A2%E4%B9%90%E6%B0%B4%E7%89%9B~%E8%A0%A2%E8%9B%86%E8%A0%95%E5%8A%A8.mp3')
# ^ 获取当前代码目录
path = os.path.dirname(__file__)
# ^ 判断连接是否成功
if music.status_code == 200:
# ^ 尝试打开文件,如果不存在就创建,以二进制的形式,赋给f变量后写入 music.content 二进制数据
with open(path + '/music.mp3', 'wb') as f:
f.write(music.content)
else:
print("下载失败")
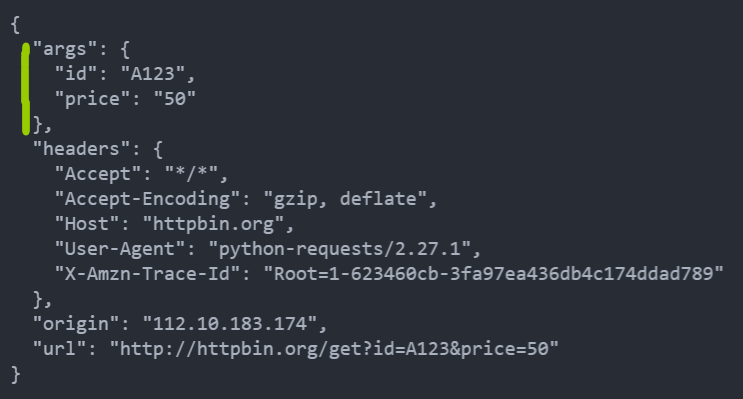
Get 请求
http://httpbin.org 是一个可以反馈我们请求信息的测试平台
import requests
# ^ 访问 http://httpbin.org 反馈我们的请求
res = requests.get('http://httpbin.org/get')
# ^ 打印响应内容
print(res.text)
# ^ 带参数get
res = requests.get('http://httpbin.org/get?id=A123&price=50')
print(res.text)
# ^ 更方便带参数get
data = {
'id': 'A123',
'price': '50'
}
res = requests.get('http://httpbin.org/get', params=data)
print(res.text) # http://httpbin.org/get?id=A123&price=50
# @ 将列表作为值传入
data = {
'id': ['A123', 'B456'],
'price': '50'
}
res = requests.get('http://httpbin.org/get', params=data)
print(res.text) # http://httpbin.org/get?id=A123&id=B456&price=50
# @ 字典里值为 None 的键都不会被添加到 URL 的查询字符串里
data = {
'id': ['A123', 'B456'],
'price': None
}
res = requests.get('http://httpbin.org/get', params=data)
print(res.text) # http://httpbin.org/get?id=A123&id=B456
# ^ 解析成 json
print(res.json())
第一种
第二种

第三种

字典里值为 None 的键都不会被添加到 URL 的查询字符串里添加Headers发送请求
headers在爬虫中是非常必要的,很多时候如果请求不加headers,那么你可能会被禁掉或出现服务器错误…
import requests
response = requests.get("https://www.baidu.com/s?wd=helloworld")
print(response.text)
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
# }
# response = requests.get("https://www.baidu.com/s?wd=helloworld", headers=headers)
# print(response.text)不加 Headers 站点不返回具体搜索数据
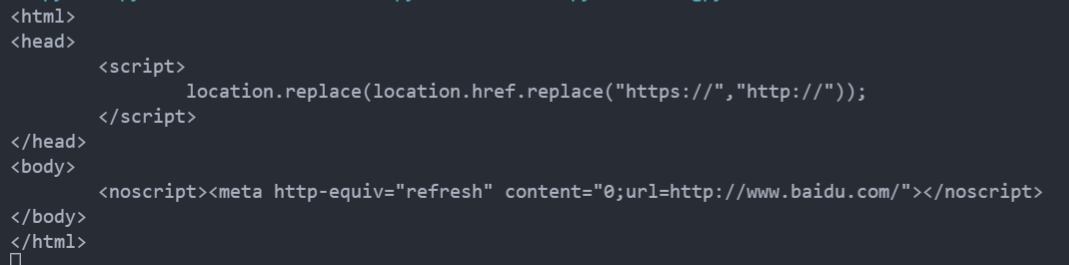
Post 请求
发送一个带headers、带参数的post请求,注意data是字典 dict 类型
import requests
data = {'id': 'A123', 'price': '50'}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
response = requests.post("http://httpbin.org/post", data=data, headers=headers)
print(response.text) 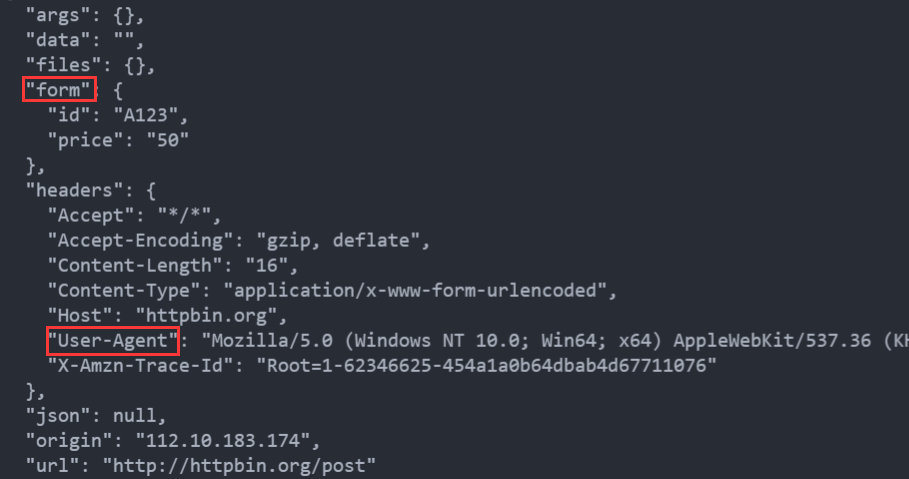
还可以为 data 参数传入一个元组列表。在表单中多个元素使用同一 key 的时候,这种方式尤其有效,字典会第二个值覆盖第一个值
payload = [("key1","value1"),("key1","value2")]
response = requests.post("http://httpbin.org/post",data = payload)
print(response.text)
判断HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
常用状态码
| 200 | 请求成功 |
| 301 | 资源(网页等)被永久转移到其它URL |
| 404 | 请求的资源(网页等)不存在 |
| 500 | 内部服务器错误 |
参考资料:HTTP状态码大全 - 常用参考表对照表
判断状态码
import requests
res = requests.get('https://baidu.com')
exit() if not res.status_code == requests.codes.OK else print('请求成功')
exit() if not res.status_code == 200 else print('请求成功')
Post 文件上传
上传单个文件
Requests支持流式上传,这允许你发送大的数据流或文件而无需先把它们读入内存。要使用流式上传,仅需为你的请求体提供一个类文件对象即可
可以发送文件,可以显式地设置文件名,文件类型和请求头,也可以发送作为文件来接收的字符串
import requests
import os
path = os.path.dirname(__file__)
files = {'files': open(path+'/lazy.jpg', 'rb')}
res = requests.post("http://httpbin.org/post", files=files)
print(res.text)
# ^ 显式设置文件名,文件类型和请求头
files = {'file': ('cat.jpg', open(path+'/lazy.jpg', 'rb'), 'image/jpeg', {'Expires': '0'})}
res = requests.post("http://httpbin.org/post", files=files)
print(res.text)
# ^ 也可以发送作为文件来接收的字符串:
files = {'file': ('report.csv', 'some,data,to,send\nanother,row,to,send\n')}
res = requests.post("http://httpbin.org/post", files=files)
print(res.text)
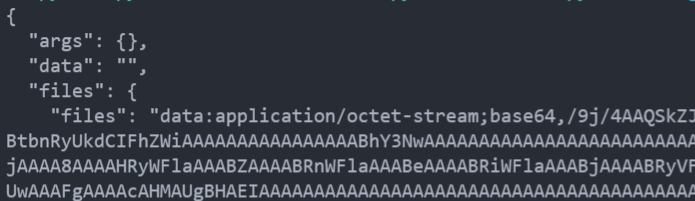
可以看到显示了文件的字节流
上传多个文件
假设你要上传多个图像文件到一个 HTML 表单,使用一个多文件 field 叫做 "images"
<input type="file" name="images" multiple="true" required="true"/>要实现,只要把文件设到一个元组的列表中
multiple_files = [
('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]强烈建议你用二进制模式(binary mode)打开文件。这是因为 requests 可能会为你提供 header 中的 Content-Length,在这种情况下该值会被设为文件的字节数。如果你用文本模式打开文件,就可能碰到错误。
Cookies
获取Cookies
通过 response.cookies获取cookies,是一个列表 list
用items()方法将其转化为元组组成的列表,遍历输出每一个Cookies的名称和值,实现Cookies的遍历解析
import requests
response = requests.get("https://www.bilibili.com/")
print(response.cookies)
for key, value in response.cookies.items():
print(key+'='+value)RequestsCookieJar
Cookie 的返回对象为 RequestsCookieJar,它的行为和字典类似,但接口更为完整,适合跨域名跨路径使用。还可以把 Cookie Jar 传到 Requests 中
# ^ CookieJar
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
response = requests.get('http://httpbin.org/cookies', cookies=jar)
print(response.text)会话维持
在requests中,如果直接利用get()或post()等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。
设想这样一个场景,第一个请求用post()方法登录了某个网站,第二次想获取成功登陆后的自己的个人信息,你又用了一次get()方法去请求这个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。
Session()
会话对象让能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能。所以如果向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。
假设我们需要读取cookie,先请求当前页面设置一个,再获取
import requests
# ^ 调用 接口 创建设置一个 cookie
requests.get('http://httpbin.org/cookies/set/id/A123')
# ^ 获取 cookies
response = requests.get('http://httpbin.org/cookies')
print(response.text)
上面那段代码中发起了两次get请求,相当于两个浏览器,相互独立,所以第二次get并不能得到第一次的cookie
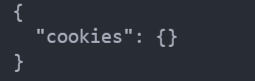
现在我们声明Session对象来发起两次get请求,Session用于会话维持
import requests
# ^ 调用 接口 创建设置一个 cookie
requests.get('http://httpbin.org/cookies/set/id/A123')
# ^ 获取 cookies
response = requests.get('http://httpbin.org/cookies')
print(response.text)
# ^ 声明Session对象发起两次get请求
s = requests.session()
s.get('http://httpbin.org/cookies/set/id/A123')
response = s.get('http://httpbin.org/cookies')
print(response.text)

会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的
# ^ 会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
res = s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
print(res.text)
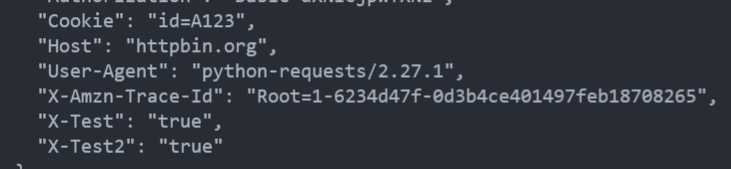
需要注意,就算使用了会话,像方法级别 (get、post...) 的参数 (如cookies=) 不会被跨请求保持。下面的例子只会和第一个请求发送 cookie
s = requests.session()
r = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(r.text)
# '{"cookies": {"from-my": "browser"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {}}'

with requests.Session() as s:
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')使用 with as 能确保 with 区块退出后会话能被关闭,即使发生了异常也一样
Cookies维持登录状态
打开开发者工具,查找headers里的Cookie
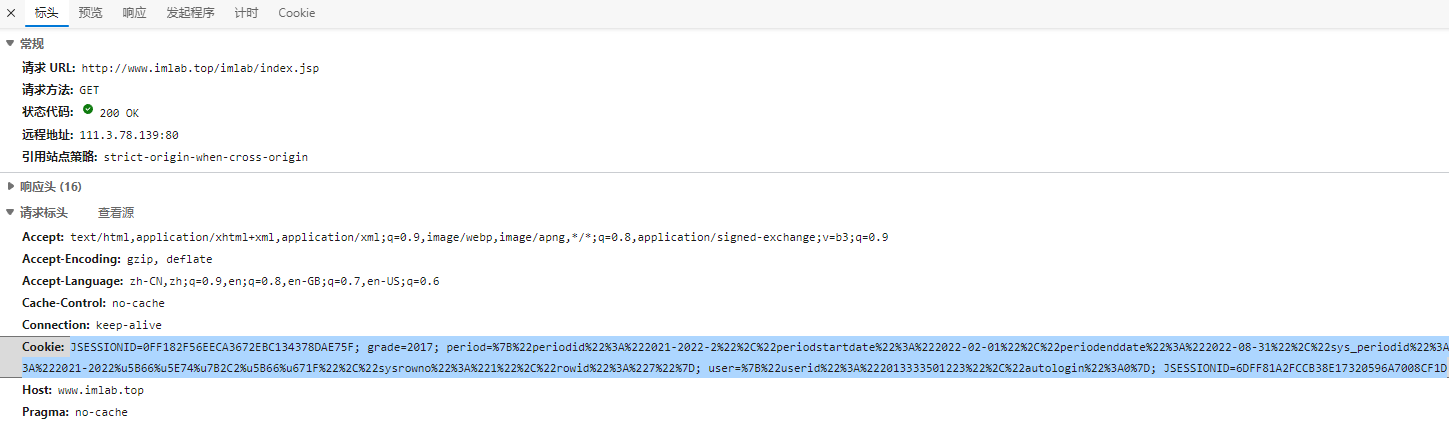
获取到的Cookies
JSESSIONID=0FF182F56EECA3672EBC134378DAE75F; grade=2017;
period=%7B%22periodid%22%3A%222021-2022-2%22%2C%22periodstartdate%22%3A%222022-02-01%22%2C%22periodenddate%22%3A%222022-08-31%22%2C%22sys_periodid%22%3A%222021-2022-2%22%2C%22periodtitle%22%3A%222021-2022%u5B66%u5E74%u7B2C2%u5B66%u671F%22%2C%22sysrowno%22%3A%221%22%2C%22rowid%22%3A%227%22%7D;
user=%7B%22userid%22%3A%222013333501223%22%2C%22autologin%22%3A0%7D; JSESSIONID=6DFF81A2FCCB38E17320596A7008CF1D代码
import requests
# ^ 方法一:在请求头中拼接cookies
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Cookie': "JSESSIONID=0FF182F56EECA3672EBC134378DAE75F; grade=2017; period=%7B%22periodid%22%3A%222021-2022-2%22%2C%22periodstartdate%22%3A%222022-02-01%22%2C%22periodenddate%22%3A%222022-08-31%22%2C%22sys_periodid%22%3A%222021-2022-2%22%2C%22periodtitle%22%3A%222021-2022%u5B66%u5E74%u7B2C2%u5B66%u671F%22%2C%22sysrowno%22%3A%221%22%2C%22rowid%22%3A%227%22%7D; user=%7B%22userid%22%3A%222013333501223%22%2C%22autologin%22%3A0%7D; JSESSIONID=6DFF81A2FCCB38E17320596A7008CF1D"
}
response = requests.get("http://www.imlab.top/imlab/index.jsp", headers=headers)
print(response.text)
# ^ 方法二:将cookies做为get的一个参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
}
cookies = {
'Cookie': "JSESSIONID=0FF182F56EECA3672EBC134378DAE75F; grade=2017; period=%7B%22periodid%22%3A%222021-2022-2%22%2C%22periodstartdate%22%3A%222022-02-01%22%2C%22periodenddate%22%3A%222022-08-31%22%2C%22sys_periodid%22%3A%222021-2022-2%22%2C%22periodtitle%22%3A%222021-2022%u5B66%u5E74%u7B2C2%u5B66%u671F%22%2C%22sysrowno%22%3A%221%22%2C%22rowid%22%3A%227%22%7D; user=%7B%22userid%22%3A%222013333501223%22%2C%22autologin%22%3A0%7D; JSESSIONID=6DFF81A2FCCB38E17320596A7008CF1D"
}
response = requests.get("http://www.imlab.top/imlab/index.jsp", headers=headers,cookies=cookies)
print(response.text)
成功用Cookies来维持登录状态
InvalidHeader
发生异常: InvalidHeader
Invalid return character or leading space in header: Cookie
出现此报错的原因是header请求头不能有空格
重定向与请求历史
- 默认情况下,除了 HEAD, Requests 会自动处理所有重定向。
- 可以使用响应对象的 history 方法来追踪重定向。
- Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。例如,Github 将所有的 HTTP 请求重定向到 HTTPS:
import requests
# ^ 访问 http 百度自动重定向到 https
res = requests.get('http://bilibili.com/')
print(res.url)
print(res.history)
# https://www.bilibili.com/?rt=V%2FymTlOu4ow%2Fy4xxNWPUZ9cMXB0I9gJlG5%2FQ5%2FMXJts%3D
# [<Response [301]>, <Response [302]>] 如果使用的是GET、OPTIONS、POST、PUT、PATCH 或者 DELETE,那么可以通过 allow_redirects 参数禁用重定向处理,HEAD需要设置allow_redirects 开启重定向
res = requests.get('http://bilibili.com/',allow_redirects=False)
SSL 证书验证
Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。SSL 验证默认是开启的,如果证书验证失败,Requests 会抛出 SSLError:
response = requests.get('https://requestb.in')
print(response) # 抛出异常 SSLError:
response = requests.get('https://github.com', verify=True)
print(response)
为了避免这种情况的发生可以通过verify=False但是这样是可以访问到页面,但是会提示:InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
解决方法为:
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 就这一句就可以解决
response = requests.get("https://www.12306.cn",verify=False)
print(response.status_code)可以为 verify 传入 CA_BUNDLE 文件的路径,或者包含可信任 CA 证书文件的文件夹路径:
requests.get('https://github.com', verify='路径')或者将其保存在会话中:
s = requests.Session()
s.verify = '路径'注意:如果 verify 设为文件夹路径,文件夹必须通过 OpenSSL 提供的 c_rehash 工具处理。
还可以通过 REQUESTS_CA_BUNDLE 环境变量定义可信任 CA 列表。
如果将 verify 设置为 False,Requests 也能忽略对 SSL 证书的验证。
requests.get('https://kennethreitz.org', verify=False)
#<Response [200]>默认情况下, verify 是设置为 True 的。选项 verify 仅应用于主机证书。对于私有证书,也可以传递一个 CA_BUNDLE 文件的路径给 verify。也可以设置 # REQUEST_CA_BUNDLE 环境变量。
也可以指定一个本地证书用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组
requests.get('https://kennethreitz.org', cert=('/path/client.cert', '/path/client.key'))
<Response [200]>或者保持在会话中:
s = requests.Session()
s.cert = '/path/client.cert'
警告本地证书的私有 key 必须是解密状态。目前,Requests 不支持使用加密的 key。
设置代理
代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情)
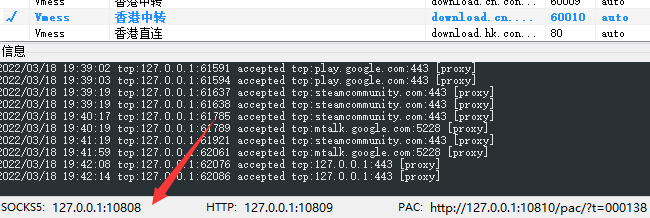
命令行输入 pip install pysocks
import requests
# ^ SOCKS5 代理
proxies = {
"http": "socks5://127.0.0.1:10808",
"https": "socks5://127.0.0.1:10808"
}
res = requests.get("https://www.google.com/", proxies=proxies)
print(res.text)
# ^ HTTPS 代理
# proxies = {
# "http": "http://127.0.0.1:10809",
# "https": "https://127.0.0.1:10809"
# }
# ^ 带密码
# proxies={
# "http":"http://uesr:password@127.0.0.1:9743/",
# } 
你也可以通过环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理
# Linux terminal:
# export HTTP_PROXY="http://10.10.1.10:3128"
# export HTTPS_PROXY="http://10.10.1.10:1080"
import requests
requests.get("http://example.org")要为某个特定的连接方式或者主机设置代理, 使用 scheme://hostname作为 key,它会针对指定的主机和连接方式进行匹配
proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}
超时设置
为防止服务器不能及时响应,大部分发至外部服务器的请求都应该带着 timeout 参数。在默认情况下,除非显式指定了 timeout 值,requests 是不会自动进行超时处理的。如果没有 timeout,你的代码可能会挂起若干分钟甚至更长时间。
连接超时指的是在你的客户端实现到远端机器端口的连接时(对应的是connect()),Request 会等待的秒数。一个很好的实践方法是把连接超时设为比 3 的倍数略大的一个数值,因为 TCP 数据包重传窗口 (TCP packet retransmission window) 的默认大小是 3。
一旦你的客户端连接到了服务器并且发送了 HTTP 请求,读取超时指的就是客户端等待服务器发送请求的时间。(特定地,它指的是客户端要等待服务器发送字节之间的时间。在 99.9% 的情况下这指的是服务器发送第一个字节之前的时间)。
可以告诉 requests 在经过以 timeout 参数设定的秒数时间之后停止等待响应。
timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在 timeout 秒内没有从基础套接字上接收到任何字节的数据时)If no timeout is specified explicitly, requests do not time out.
import requests
response = requests.get("https://www.baidu.com", timeout=0.1)
# ^ 设置一个时间限制,必须在0.1秒内得到应答
print(response.status_code)捕捉超时异常
import requests
# ^ 捕捉超时异常
try:
response = requests.get("https://httpbin.org/get", timeout=0.1)
print(response.status_code)
except requests.exceptions.Timeout:
print('Timeout')
自定义身份验证
Requests 允许你使用自己指定的身份验证机制。
任何传递给请求方法的 auth 参数的可调用对象,在请求发出之前都有机会修改请求。
自定义的身份验证机制是作为 requests.auth.AuthBase 的子类来实现的,也非常容易定义。Requests 在 requests.auth 中提供了两种常见的的身份验证方案: HTTPBasicAuth 和 HTTPDigestAuth。
若要显示此页面,你必须登录到 "xxx.xxx.xxx.xxx"
在访问时需要输入用户名和密码,输入之后才能看到网站的内容。我们可以通过auth参数,把用户名和密码传入
import requests
from requests.auth import HTTPBasicAuth
r = requests.get("网页地址", auth=HTTPBasicAuth('123456', '123456'))
print(r.status_code)
假设我们有一个web服务,仅在 X-Pizza 头被设置为一个密码值的情况下才会有响应。虽然这不太可能,但就以它为例好了。
from requests.auth import AuthBase
class PizzaAuth(AuthBase):
"""Attaches HTTP Pizza Authentication to the given Request object."""
def __init__(self, username):
# setup any auth-related data here
self.username = username
def __call__(self, r):
# modify and return the request
r.headers['X-Pizza'] = self.username
return r
# 然后就可以使用我们的PizzaAuth来进行网络请求
requests.get('http://pizzabin.org/admin', auth=PizzaAuth('kenneth'))
异常处理
http://www.python-requests.org/en/master/api/#exceptions
为保证爬虫的正常运转,需要对异常进行妥善处理
- 遇到网络问题(如:DNS 查询失败、拒绝连接等)时,Requests 会抛出一个 ConnectionError 异常。
- 如果 HTTP 请求返回了不成功的状态码, Response.raise_for_status() 会抛出一个 HTTPError 异常。
- 若请求超时,则抛出一个 Timeout 异常。
- 若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects 异常。
- 所有Requests显式抛出的异常都继承自 requests.exceptions.RequestException 。
import requests
from requests.exceptions import ReadTimeout, HTTPError, RequestException
try:
response = requests.get('http://httpbin.org/get', timeout=0.5)
print(response.status_code)
except ReadTimeout: # @ 捕获超时异常
print('Timeout')
except HTTPError: # @ 捕获HTTP异常
print('Http error')
except ConnectionError: # @ 捕获连接异常
print('Connection error')
except RequestException: # @ 捕获父类异常
print('Error')转换成JSON
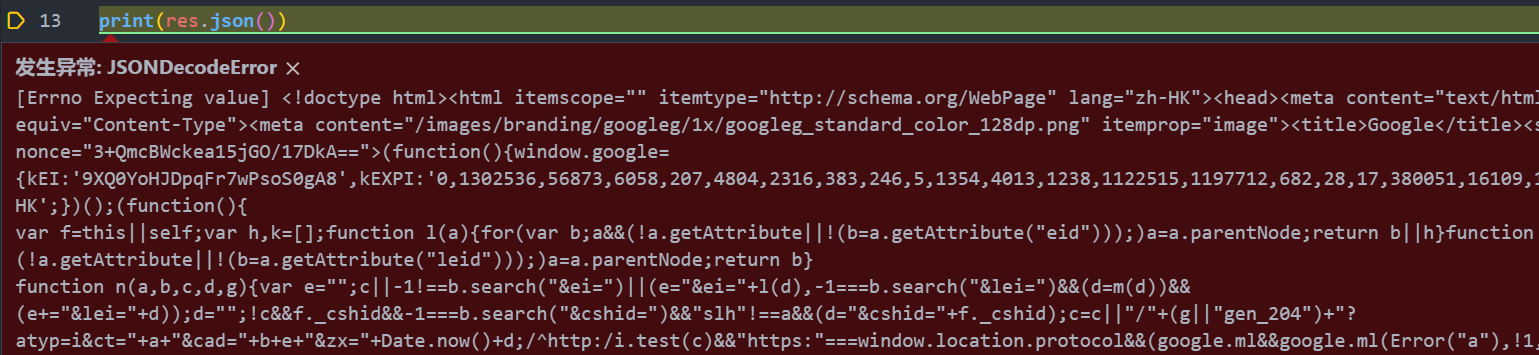
调用res.json()方法,就可以将返回结果是JSON格式的字符串转化为字典。
如果返回的结果不是JSON 格式,便会出现解析错误,抛出json.decoder.JSONDecoderError异常
Url编码
只有字母和数字[0-9a-zA-Z]、一些特殊符号"$-_.+!*'(),"[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL
import requests
from urllib.parse import urlencode
wd = "春节"
wd = urlencode({"wd": wd}, encoding="utf-8")
print(wd)
响应体内容工作流
默认情况下,当进行网络请求后,响应体会立即被下载。可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master'
r = requests.get(tarball_url, stream=True)with requests.get('http://httpbin.org/get', stream=True) as r:
# 在此处理响应。
只有所有的响应体数据被读取完毕连接才会被释放为连接池;所以确保将 stream 设置为 False 或读取 Response 对象的 content 属性。
块编码请求
背景
- 持续连接的问题:对于非持续连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界;而对于持续连接,这种方法显然不奏效。有时,尽管我已经发送完所有数据,但浏览器并不知道这一点,它无法得知这个打开的连接上是否还会有新数据进来,只能傻傻地等了。
- 用Content-length解决:计算实体长度,并通过头部告诉对方。浏览器可以通过 Content-Length 的长度信息,判断出响应实体已结束
- Content-length引入的新问题:由于 Content-Length 字段必须真实反映实体长度,但是对于动态生成的内容来说,在内容创建完之前,长度是不可知的。这时候要想准确获取长度,只能开一个足够大的 buffer,等内容全部生成好再计算。但这样做一方面需要更大的内存开销,另一方面也会让客户端等更久。
- 我们需要一个新的机制:不依赖头部的长度信息,也能知道实体的边界——分块编码(Transfer-Encoding: chunked)
分块编码(Transfer-Encoding: chunked)
- Transfer-Encoding,是一个 HTTP 头部字段(响应头域),字面意思是「传输编码」。最新的 HTTP 规范里,只定义了一种编码传输:分块编码(chunked)。
- 分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,允许HTTP由网页服务器发送给客户端的数据可以分成多个部分。分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供。
- 数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
-
具体方法
- 在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。
- 每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF。
- 最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
-
例:
HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25\r\n This is the data in the first chunk\r\n 1C\r\n and this is the second one\r\n 3\r\n con\r\n 8\r\n sequence\r\n 0\r\n \r\n - Content-Encoding 和 Transfer-Encoding 二者经常会结合来用,其实就是针对 Transfer-Encoding 的分块再进行 Content-Encoding压缩。
对于出去和进来的请求,Requests 也支持分块传输编码。要发送一个块编码的请求,仅需为你的请求体提供一个生成器
def gen():
yield 'hi'
yield 'there'
requests.post('http://some.url/chunked', data=gen())
Response.iter_content() 对其数据进行迭代。在理想情况下,你的 request 会设置 stream=True,这样你就可以通过调用 iter_content 并将分块大小参数设为 None,从而进行分块的迭代。如果你要设置分块的最大体积,你可以把分块大小参数设为任意整数。回调钩子
Requests有一个钩子系统,你可以用来操控部分请求过程,或信号事件处理。
callback_function会接受一个数据块作为它的第一个参数。def print_url(res, *args, **kwargs):
print(res.url)若执行你的回调函数期间发生错误,系统会给出一个警告。
若回调函数返回一个值,默认以该值替换传进来的数据。若函数未返回任何东西,也没有什么其他的影响。
从一个请求产生的响应,你可以通过传递一个 {hook_name: callback_function} 字典给 hooks 请求参数为每个请求分配一个钩子函数
requests.get('http://httpbin.org', hooks=dict(response=print_url))
# http://httpbin.org
流式请求
import json
import requests
res = requests.get('http://httpbin.org/stream/20', stream=True)
for line in res.iter_lines():
# filter out keep-alive new lines
if line:
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line))Response.iter_lines() 或 Response.iter_content() 中时,你需要提供一个回退编码方式,以防服务器没有提供默认回退编码,从而导致错误r = requests.get('http://httpbin.org/stream/20', stream=True)
if r.encoding is None:
r.encoding = 'utf-8'
for line in r.iter_lines(decode_unicode=True):
if line:
print(json.loads(line))iter_lines 不保证重进入时的安全性。多次调用该方法会导致部分收到的数据丢失。如果你要在多次调用它,就应该使用生成的迭代器对象
lines = r.iter_lines()
# 保存第一行以供后面使用,或者直接跳过
first_line = next(lines)
for line in lines:
print(line)
其他操作
# ^ 查看网页允许什么HTTP请求,有些网站并未实现options方法
res = requests.options('http://bilibili.com')
print(res.headers['allow'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号