
用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫。
操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化
1.数据爬取
1 job = "通信工程师" #以爬取通信工程师职业为例 2 leibie = '1' 3 url_job = [] 4 5 for page in range(99): 6 x = str(page) #爬取的页码 7 p = str(page+1) 8 print("正在抓取第一"+p+"页...\n") #提示 9 url = "http://sou.zhaopin.com/jobs/searchresult.ashx?in=210500%3B160400%3B160000%3B160500%3B160200%3B300100%3B160100%3B160600&jl=上海%2B杭州%2B北京%2B广州%2B深圳&kw="+job+"&p="+x+"&isadv=0" #url地址,此处为示例,可更据实际情况更改 10 r = requests.post(url) #发送请求 11 data = r.text 12 pattern=re.compile('ssidkey=y&ss=201&ff=03" href="(.*?)" target="_blank"',re.S) #正则匹配出招聘信息的URL地址 13 tmp_job = re.findall(pattern,data) 14 url_job.extend(tmp_job) #加入队列
上面代码以上海、杭州、北京、广州、深圳的“通信工程师”为例实现爬取了智联招聘上每一则招聘信息的URL地址。
(示例)在智联招聘上如下图所示的招聘地址:

2.数据结构化
获得URL之后,就通过URL,发送get请求,爬取每一则招聘的数据,然后使用Xpath或者正则表达式把所有数据结构化,代码如下:
1 for x in url_job: 2 print(x) 3 d = requests.post(x) #发送post请求 4 zhiwei = d.text 5 selector = etree.HTML(zhiwei) #获得招聘页面源码 6 name = selector.xpath('//div[@class="inner-left fl"]/h1/text()') #匹配到的职业名称 7 mone = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[1]/strong/text()') #匹配到该职位的月薪 8 adress = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[2]/strong/a/text()') #匹配工作的地址 9 exp = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[5]/strong/text()') #匹配要求的工作经验 10 education = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[6]/strong/text()') #匹配最低学历 11 zhiweileibie = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[8]/strong/a/text()') #匹配职位类别 12 13 match = re.compile('<!-- SWSStringCutStart -->(.*?)<!-- SWSStringCutEnd -->',re.S)#此处为匹配对职位的描述,并且对其结构化处理 14 description = re.findall(match,zhiwei) 15 des = description[0] 16 des = filter_tags(des) #filter_tags此函数下面会讲到 17 des = des.strip() 18 des = des.replace(' ','') 19 des = des.rstrip('\n') 20 des = des.strip(' \t\n') 21 try: #尝试判断是否为最后一则 22 name = to_str(name[0]) 23 mone = to_str(mone[0]) 24 adress = to_str(adress[0]) 25 exp = to_str(exp[0]) 26 education = to_str(education[0]) 27 zhiweileibie = to_str(zhiweileibie[0]) 28 des = to_str(des) 29 except Exception as e: 30 continue
上面代码中使用了filter_tags函数,此函数的目的在于把HTML代码替换实体,并且去掉各种标签、注释和换行空行等,该函数代码如下:
1 def filter_tags(htmlstr): 2 #先过滤CDATA 3 re_cdata=re.compile('//<!\[CDATA\[[^>]*//\]\]>',re.I) #匹配CDATA 4 re_script=re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>',re.I)#Script 5 re_style=re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>',re.I)#style 6 re_br=re.compile('<br\s*?/?>')#处理换行 7 re_h=re.compile('</?\w+[^>]*>')#HTML标签 8 re_comment=re.compile('<!--[^>]*-->')#HTML注释 9 s=re_cdata.sub('',htmlstr)#去掉CDATA 10 s=re_script.sub('',s) #去掉SCRIPT 11 s=re_style.sub('',s)#去掉style 12 #s=re_br.sub('\n',s)#将br转换为换行 13 s=re_h.sub('',s) #去掉HTML 标签 14 s=re_comment.sub('',s)#去掉HTML注释 15 #去掉多余的空行 16 blank_line=re.compile('\n+') 17 s=blank_line.sub('\n',s) 18 # s=replaceCharEntity(s)#替换实体 19 return s
3.存入数据库
上面的代码已经帮我们实现根据数据表中设置的字段清洗好杂乱无章的数据了,之后只要在循环中把结构化的数据存入数据库即可。
具体代码如下:
1 conn = pymysql.connect(host='127.0.0.1',user='root',passwd='××××××',db='zhiye_data',port=3306,charset='utf8') 2 cursor=conn.cursor() 3 4 sql='INSERT INTO `main_data_3` (`name`,`mone`,`adress`,`exp`,`education`,`zhiweileibie`,`description`,`leibie`,`company_range`,`company_kind`) VALUES(\''+name+'\',\''+mone+'\',\''+adress+'\',\''+exp+'\',\''+education+'\',\''+zhiweileibie+'\',\''+des+'\',\''+leibie+'\',\'a\',\'b\');'#%(name,mone,adress,exp,education,zhiweileibie,des,leibie) 5 6 #print(sql) 7 try: 8 cursor.execute(sql) 9 conn.commit() 10 print (cursor.rowcount) 11 except Exception as e: 12 print (e) 13 cursor.close() 14 conn.close()
存入数据库中的具体数据示例如下图:
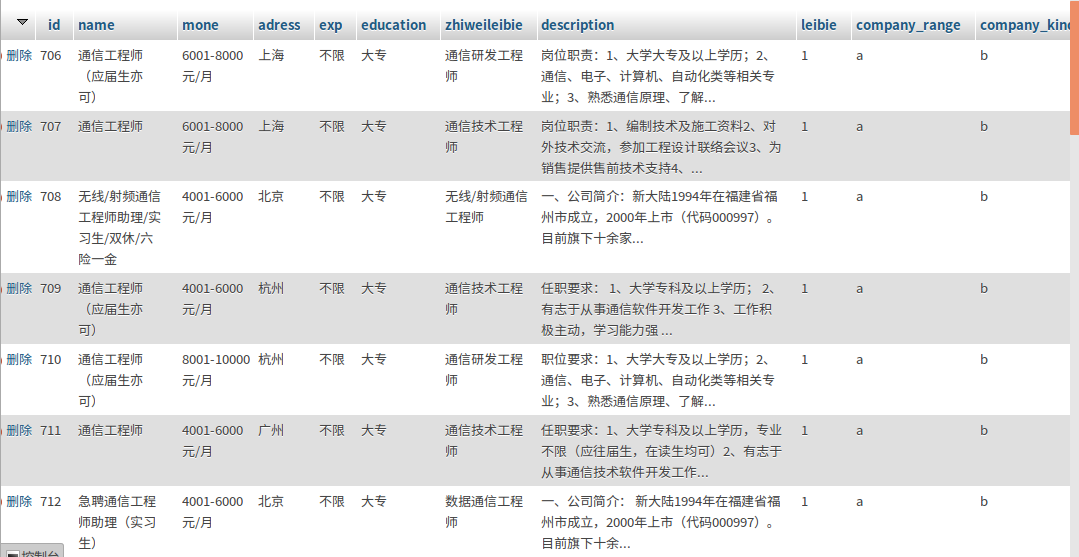
4.数据统计
首先对职位的描述进行分词统计,以便分析出该职业所需要的技能。
对职位描述进行分词我先使用的是SAE的分词服务,示例代码(PHP)如下(仅供参考):
1 public function get() 2 { 3 $h = D('hotword'); 4 $data = $h->get_des(); 5 6 foreach ($data as $k => $v) { 7 $content = POST("http://segment.sae.sina.com.cn/urlclient.php?encoding=UTF-8&word_tag=1","context=".$v['description']); 8 $text = json_decode($content,true); 9 if (empty($text[0]['word_tag'])) { 10 exit; 11 } 12 $sta = $h->hotword_save($text); 13 dump($sta); 14 } 15 }
向服务地址发送post请求,会以JSON格式返回具体的分析结果。存入数据库(如下图):

对每个词的出现频率进行统计,去掉一些无关的和通用的词之后就是所需职业技能的关键词。
然后我也对各个地区各个职业的月薪、数量等也进行栏统计。
下面放几张结果的示例图(不清晰的截图,,,见谅哈):
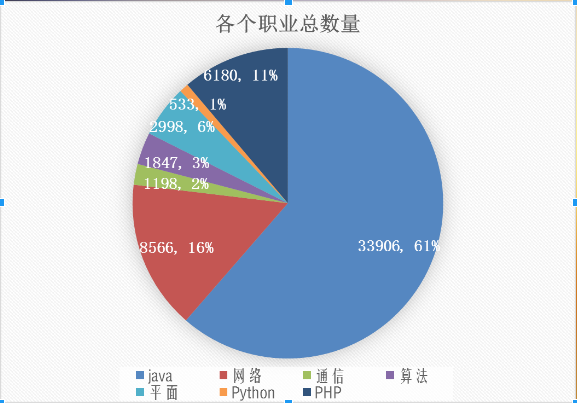

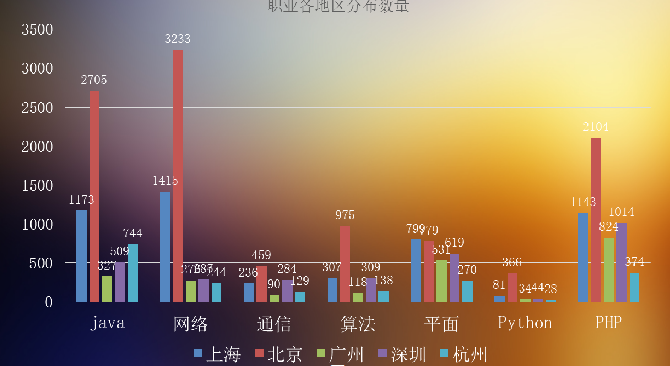
下图为不同职业对学历要求的统计图

下图为Python开发出现最多的技能词

下图为C开发出现最多的技能词
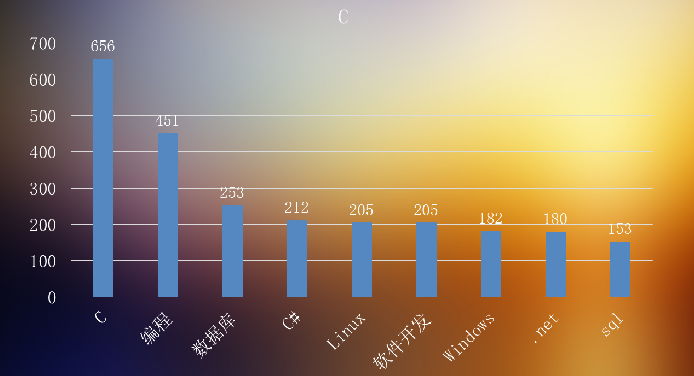
最后的分析我这里就不多说了,聪明的人看图都应该能看懂了哈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号