消息中间件
三大经典且成熟的MQ产品:RabbitMQ、RocketMQ、Kafka 之间的差别基本已经被网文对比烂了,但基本对选型没有指导意义,本文尝试从核心层面厘清主流MQ产品各自异同。
编程语言
RocketMQ是java编写,群众基础深厚。编码风格可以说和(ye)蔼(wu)可(dai)亲(ma),不用太担心看不懂改废了,中文资源丰富,需要改写直接干。
Kafka采用scala,scala就是个双倍糖版本的Java,用的都是同样的虚拟机相同代码性能肯定没差别,但据说kafka最初是scala的练手项目(可能是谣言我不确定),所以早先的代码还是java style的。
RabbitMQ采用Erlang,我猜大部分人连Erlang的hello world都看不懂,但Erlang可以从编程层面轻松完成集群内节点数据同步这种分布式工作,这就意味着有了Erlang的支持,集群可以是无主的,省去了其他中间件要额外引入注册中心的问题。
数据权限安全
Kafka 0.9,RocketMQ 4.2以后,已经和RabbitMQ对齐了,都有topic级别的权限控制。
但Rocket和Rabbit是支持多租户的,有需要可以重点考虑。
架构和高可用
MQ设计的核心目标一是解耦生产者和消费者,二是处理好数据的存储模型。在对以上宏观目标的实现上,三者有一定差异。
Kafka
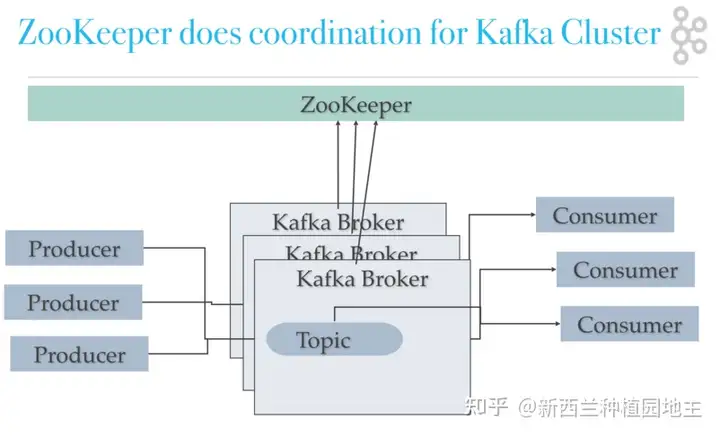
Kafka采用ZooKeeper作为节点保活并选举控制器节点(controller)操作主从副本切换,为了支持海量数据,topic数据可以按分片(partition,可以理解为queue)存储到不同节点,且支持分片级主从副本(Leader、follower),并由controller根据ISR列表做fail-over。[1]
RocketMQ
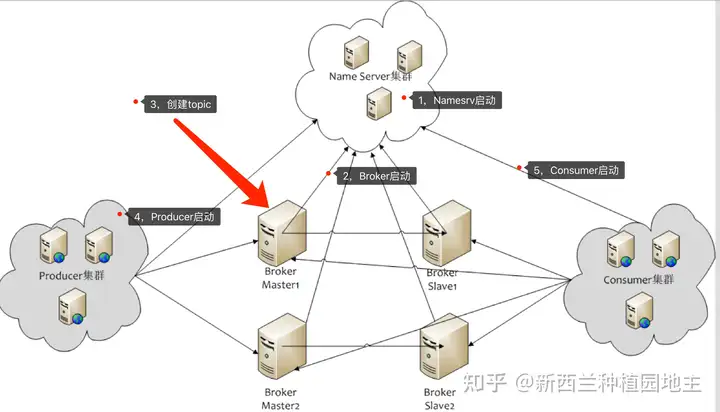
都说RocketMQ抄袭Kafka,但Rocket抛弃了ZK,一方面因为ZK较强的一致性不适合注册中心的业务,另一方面考虑到外部依赖问题和KPI,Rocket自己实现了一个注册中心服务NameServer。NameServer和broker集群架构不同,没有主从节点之分,任何Broker、producer和consumer都要去所有NameSer注册自己的地址,注册信息的一致性则由心跳保证,一旦某个服务一段时间(如120s)没有对某个NameServ发起心跳,该NameServ则对其剔除,所以仅能满足最终一致性,但一般内网使用问题不大。在数据存储上,Rocket单节点所有topic的数据都存储在一个文件commitLog中,难以做主从分片,甚至主从切换也需要人工处理修改配置文件master0,后续的版本引入DLedger托管CommitLog之后,基于其Raft协议本质才可以实现自动的主从切换的。
RocketMQ核心内容可参考[2]:
新西兰种植园地主:RocketMQ原理一波带走:启动、发送、落盘、消费主流程
RabbitMQ
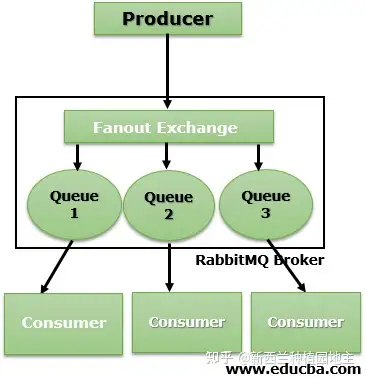
RabbitMQ为无主架构且完全遵循amqp协议,而且消息被消费后就真的消费了,不要想通过设置消费位置对某一批消息重新消费,但是因为存在内存和磁盘节点的角色划分,使用得当也不会丢消息(实际上三者在最新的版本都可以保证不丢消息)。Rocket或Kafka的broker概念和Rabbit中的虚拟主机(vhost)对标,vhost可细化为Exchange交换机和Queue队列,Exchange设定消息投送模式,并且保存了路由键(routing key)和队列(queue)之间的绑定关系(binding),其和队列参数等信息统称为元数据。集群工[3]作可分为普通模式和镜像模式,普通模式下集群中每个节点的绑定元数据都在Erlang语言层面上实现同步,同时消息数据可分布式存储,所以连接集群每个节点都可以工作,数据不在本机则做请求转发。镜像模式则非常暴力,节点间任何内容包括消息数据都完全一致。
性能
RocketMQ和Kafka性能指标在一个级别,RabbitMQ消息堆积后性能不好。
-- 网络传言
背一句传言是很简单的,但实际的原因我们还是要了解一下,其实它们的性能差异实际在底层存储结构上。
RocketMQ
RocketMQ所有消息都会写入到broker的最新commitLog中,也就是同一个broker的消息不管哪个topic都会把数据写到同一个commitLog文件中,写入后异步生成索引文件ConsumeQueue(commitLog offset, size, tag hash),ConsumeQueue是以Topic下的queueId为维度的。
Kafka
而Kafka是对于每个topic下的不同partition都有不同数据文件和稀疏哈希索引文件。
这就可以看出,kafka因为做了分拆,通常来说其写入性能肯定是要高于rocketMQ的(写一个文件和多线程写N个文件,都是IO操作,肯定写多个文件总吞吐量大),但是一旦partition过多,kafka就要在单位时间内同时写很多个不同partition的数据文件,出现性能瓶颈。当然kafka还有其他针对高吞吐量场景的nb优化:比如用提高一点点发送端延迟(linger.ms)的代价积攒消息就可以成批投递、这一波积攒的消息在生产者(ProducerBatch内)就可以完成消息的序列化,等发到broker时连解析都不用、正因为broker不需要解析,kafka可以充分发挥协处理器(DMA)优势,利用os的#sendfile直接完成消息的持久化。
RabbitMQ
说说RabbitMQ,为啥堆积性能不好呢?
在RabbitMQ中,不管是内存消息还是持久化消息,数据文件和索引文件都有可能存在磁盘或内存中,这具体取决于内存负载。具体存在什么位置不是一成不变的,这就造成消费时的复杂性,新的消息可能被挤压到很深的backing_queue中,造成消息查找处理时间更长,情况会继续恶化。另外就是集群模式上,如果采用镜像集群,写入存在放大风险,集群内节点越多,所需要同步的数据次数就越多,磁盘IO也会变高。所以追求性能最好采用普通集群模式,并且设置磁盘节点不要太多。
独家特性
看看各个mq都有什么独特杂技吧。
RabbitMQ
不是RabbitMQ拯救了AMQP,而是AMQP拯救了Rabbit。因为遵循规则,RabbitMQ支持多种协议多种语言,实时推送、mqtt协议、websocket等等,通过插件在html上用js就能接消息你敢信?在你家冰箱上就能接消息你敢信?所以在国外脚本语言及全栈盛行的环境下,RabbitMQ对RocketMQ有压倒性人气优势(2021年)。
另外,RabbitMQ支持多级优先级消息,这可不是Rocket所谓的VIP队列能比的,Rabbit通过队列设置就可以让消息的投递和消费有了二叉堆优先级的感觉,简直太强了(当然,考虑到性能,优先级范围最好是0-10之间)。这个功能对于Kafka和RocketMQ来说,只能是拒绝三连,其他MQ产品只能通过设置不同topic曲线实现。
RocketMQ/Kafka
用RocketMQ的事务消息搞分布式事务已经被列为最简单的八股文范畴了,原理也就是改变要投递的topic为内建半消息topic,等事务提交了又给你塞回原始topic然后回调。不过就这么点事另外两个MQ还真干不了。
kafka和rabbitMQ支持的事务消息更像是保证自己消息中间件的事务性,防止部分消息丢失的策略:
第一步,准备开启一个事务:
RocketMQ直接封装原始消息、改topic、半消息送入broker一气呵成。
kafka生产者直接向事务协调者发起请求,消息协调者记录到日志。但是。。。这里记录的是kafka开启事务的意愿,记录个状态,和原消息无关。
第二步,执行本地事务。
rocket producer端执行本地事务...
kafka生产者发送消息1、发送消息2...
第三步,MQ提交/回滚
RocketMQ生产者发送事务提交/回滚请求到Broker,记录到op topic(相当于标记half topic中消息已经处理),提交则把原消息发回到目标topic使得对消费者可见。
kafka的生产者向协调器发出 提交/回滚 请求,协调器去对应日志中标记。
对于一段时间没有commit/rollback的消息,Kafka没有类似RocketMQ的回查机制。
总结
日志采集、大数据用Kafka,没有非常海量的话,调优下RocketMQ也能用。
日常业务开发我直接RocketMQ,群众基础好、应用范围广、功能丰富,还能实现分布式事务,买1送2。
推送场景、协议复杂、IM领域、急需优先级消息就RabbitMQ,也很成熟。
参考
- ^cloudurable http://cloudurable.com/blog/kafka-architecture/index.html
- ^RocketMQ总结笔记 https://zhuanlan.zhihu.com/p/470873531
- ^阿里云Rocket https://developer.aliyun.com/article/135384

 浙公网安备 33010602011771号
浙公网安备 33010602011771号