xml
1.1概述【理解】
-
万维网联盟(W3C)
万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。 建立者: Tim Berners-Lee (蒂姆·伯纳斯·李)。 是Web技术领域最具权威和影响力的国际中立性技术标准机构。 到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,
-
如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)、
-
可扩展标记语言XML(标准通用标记语言下的一个子集)
-
以及帮助残障人士有效获得Web信息的无障碍指南(WCAG)等
![]()
-
-
xml概述
XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言 标记语言: 通过标签来描述数据的一门语言(标签有时我们也将其称之为元素) 可扩展:标签的名字是可以自定义的,XML文件是由很多标签组成的,而标签名是可以自定义的
-
作用
-
用于进行存储数据和传输数据
-
作为软件的配置文件
-
-
作为配置文件的优势
-
可读性好
-
可维护性高
-

1.2标签的规则【应用】
-
标签由一对尖括号和合法标识符组成
<student> -
标签必须成对出现
<student> </student>
前边的是开始标签,后边的是结束标签 -
特殊的标签可以不成对,但是必须有结束标记
<address/> -
标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来
<student id="1"> </student> -
标签需要正确的嵌套
这是正确的: <student id="1"> <name>张三</name> </student>
这是错误的: <student id="1"><name>张三</student></name>
1.3语法规则【应用】
-
语法规则
-
XML文件的后缀名为:xml
-
文档声明必须是第一行第一列
<?xml version="1.0" encoding="UTF-8" standalone="yes”?> version:该属性是必须存在的 encoding:该属性不是必须的
打开当前xml文件的时候应该是使用什么字符编码表(一般取值都是UTF-8)
standalone: 该属性不是必须的,描述XML文件是否依赖其他的xml文件,取值为yes/no
-
必须存在一个根标签,有且只能有一个
-
XML文件中可以定义注释信息
-
XML文件中可以存在以下特殊字符
< < 小于
> > 大于
& & 和号
' ' 单引号
" " 引号 -
XML文件中可以存在CDATA区
<![CDATA[ …内容… ]]>
-
-
示例代码
1.4xml解析【应用】
-
概述
xml解析就是从xml中获取到数据
-
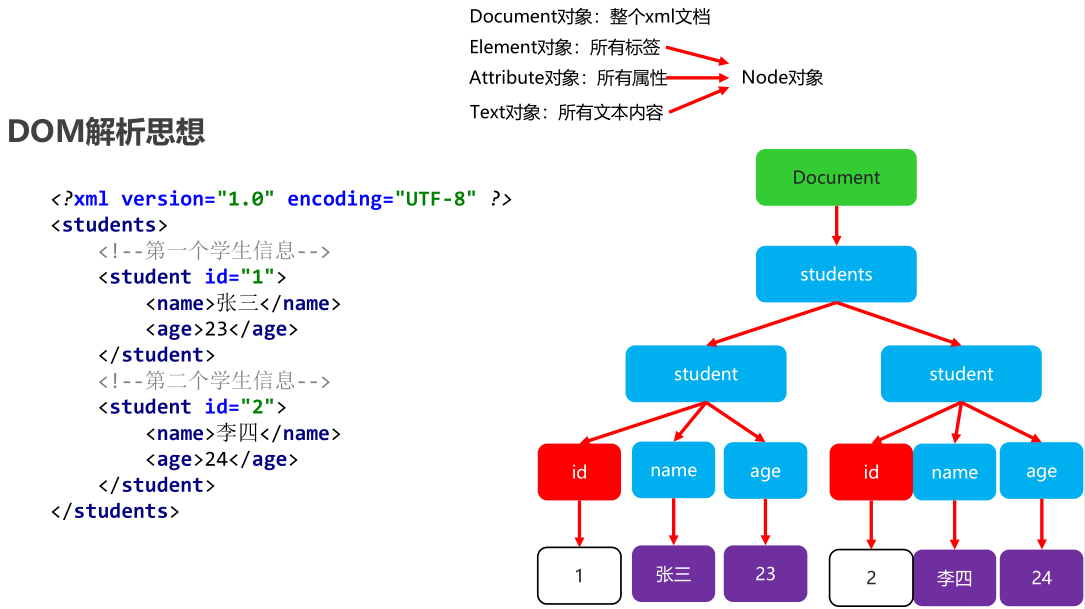
常见的解析思想
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。 会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值
![]()
-
常见的解析工具
-
JAXP: SUN公司提供的一套XML的解析的API
-
JDOM: 开源组织提供了一套XML的解析的API-jdom
-
DOM4J: 开源组织提供了一套XML的解析的API-dom4j,全称:Dom For Java
-
pull: 主要应用在Android手机端解析XML
-
-
解析的准备工作
-
我们可以通过网站:https://dom4j.github.io/ 去下载dom4j
今天的资料中已经提供,我们不用再单独下载了,直接使用即可
-
将提供好的dom4j-1.6.1.zip解压,找到里面的dom4j-1.6.1.jar
-
在idea中当前模块下新建一个libs文件夹,将jar包复制到文件夹中
-
选中jar包 -> 右键 -> 选择add as library即可
-
-
需求
-
解析提供好的xml文件
-
将解析到的数据封装到学生对象中
-
并将学生对象存储到ArrayList集合中
-
遍历集合
-
-
代码实现
<?xml version="1.0" encoding="UTF-8" ?>
<!--注释的内容-->
<!--本xml文件用来描述多个学生信息-->
<students>
<!--第一个学生信息-->
<student id="1">
<name>张三</name>
<age>23</age>
</student>
<!--第二个学生信息-->
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
// 上边是已经准备好的student.xml文件
public class Student {
private String id;
private String name;
private int age;
public Student() {
}
public Student(String id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}