
一、MongoDB的基本语法使用
1)对库的增删查


show dbs # 显示所有的库 use admin # 切换到管理员库 # db是默认的全局变量 在哪个库下,db的值就是当前库 mongo中没有创建库,和表的概念 直接切换库 use db1 (无论有没有该库) 空库,空表不显示 =================================== help 数据库 增 use db1 # 有则切换,无则新增 查 show dbs # 查看所有 db # 当前 删 db.dropDatabase()
2)对集合(表)的增删查
增 db.user db.user.info db.user.auth 查看(显示所有的表) show collections show tables 删除 db.user.drop() # 删除user表
3.1)对文档(表中的一条数据)的增加
db.user.insert({"_id":1,"name":"dasb"})
示例(唯一id)
> db.user.insert({"a":1})
WriteResult({ "nInserted" : 1 })
> db.user.find()
{ "_id" : ObjectId("5c05deda76533a68c742cb54"), "a" : 1 }
> db.user2.find()
3.2)对文档的单条数据和多条数据的增加(赋予变量的形式)
数据准备
#1、没有指定_id则默认ObjectId,_id不能重复,且在插入后不可变 #2、插入单条 user0={ "name":"egon", "age":10, 'hobbies':['music','read','dancing'], 'addr':{ 'country':'China', 'city':'BJ' } } db.test.insert(user0) db.test.find() #3、插入多条 user1={ "_id":1, "name":"alex", "age":10, 'hobbies':['music','read','dancing'], 'addr':{ 'country':'China', 'city':'weifang' } } user2={ "_id":2, "name":"wupeiqi", "age":20, 'hobbies':['music','read','run'], 'addr':{ 'country':'China', 'city':'hebei' } } user3={ "_id":3, "name":"yuanhao", "age":30, 'hobbies':['music','drink'], 'addr':{ 'country':'China', 'city':'heibei' } } user4={ "_id":4, "name":"jingliyang", "age":40, 'hobbies':['music','read','dancing','tea'], 'addr':{ 'country':'China', 'city':'BJ' } } user5={ "_id":5, "name":"jinxin", "age":50, 'hobbies':['music','read',], 'addr':{ 'country':'China', 'city':'henan' } } db.user.insertMany([user1,user2,user3,user4,user5])
二、对文档(表中的一条数据)的查看
1)最基本的查看
db.user.find() db.user.find().pretty() # 格式化查看 db.user.findOne() # 查看一条(第一条) db.user.find().count() # 获取数量 db.user.find({"_id":2}) # 指定条件查看id=2的。 db.user.find({"b":null}) # b的值为null和没有b的都会被查找到
2)比较运算的查看
db.user.find({"_id":{"$ne":2}}) # 指定条件查看id不等于2的
db.user.find({"_id":{"$gt":2}}) # 大于2
db.user.find({"_id":{"$lt":2}}) # 小于2
db.user.find({"_id":{"$gte":2}}) # 大于等于2
db.user.find({"_id":{"$lte":2}}) # 小于等于2
db.user.find({"_id":{"$mod":[2,1]}}) # 找到id除以2,余数为1的
3)逻辑运算的查看 $and,$or, $not
db.user.find({"_id":{"$gte":3,"$lte":4}}) # 找id大于等于3并且小于等于4的
多个条件的第一种写法
db.user.find({ # 找到id大于等于3并且小于等于4的,并且年纪大于等于40的
"_id":{"$gte":3,"$lte":4},
"age":{"$gte":40}
})
多个条件的第二种写法
db.user.find({"$and":[ # $and 去进行条件连接
{"_id":{"$gte":3,"$lte":4}}, # 条件一
{"age":{"$gte":40}} # 条件二
]})
--------$or
db.user.find({"$or":[ # $or 去进行条件连接
{"_id":{"$lte":1,"$gte":0}}, # 条件一
{"age":{"$gte":40}} # 条件二
]})
--------$not 取反
db.user.find({
"_id":{"$not":{"$mod":[2,1]}}
})
4)成员运算,$in,$nin
db.user.find({"name":{"$in":["dasb","sb"]}}) # 找到名字有这些的条件
db.user.find({"name":{"$nin":["dasb","sb"]}}) # 找到名字没有这些的条件
5)正则匹配
db.user.find({ "name":/^jin.*?(g|n)$/i #以jin开头,g和n结尾 ,i是忽略大小写 })
6)查看指定字段。显示条件,0为不显示,1为显示
db.user.find({ "name":/^jin.*?(g|n)$/i # 插定查询条件 }, { "_id":0, "name":1, "age":1 } )
7)对数据相关操作,value为列表,和嵌套字典等
db.user.find({"hobbies":"dancing"}) # 查询爱好有跳舞的
db.user.find({
"hobbies":{"$all":["dancing","tea"]} # 查询既有跳舞和喝茶爱好的
)
db.user.find({"hobbies.2":"dancing"}) # 查询第三个爱好是跳舞的
db.user.find(
{},
{
"_id":0,
"name":0,
"age":0,
"hobbies":{"$slice":-2} # 切片,查询爱好为后面2个的数据
}
)
db.user.find(
{},
{
"_id":0,
"name":0,
"age":0,
"hobbies":{"$slice":[1,2]} # 切片,查询第2个和第3个。数据,0,1,2
}
)
db.user.find(
{},
{
"_id":0,
"name":0,
"age":0,
"hobbies":{"$slice":2} # 切片,查询爱好为后前面2个的数据
}
db.user.find({"addr.country":"China"}) # 查询嵌入型文档
如:{"addr":{"country":"China","city":"BJ"}}
8)排序查找sort,限制查询limit,跳过查询skip
db.user.find() # 默认按照id排序(升序) db.user.find().sort({"_id":1}) # 1,按照id排序(升序) db.user.find().sort({"_id":-1}) # -1,按照id排序(降序) ------------------------------------------- db.user.find.limit(2) # 只查前面2条 db.user.find.limit(2).skip(0) # 跳过0个,取2个 db.user.find.limit(2).skip(2) # 跳过2个,取2个
二、对文档(表中的一条数据)的修改
1)save方法(有则覆盖,无则新增)
db.user.save({"_id":1,"z":6}) # 如果有相同id则覆盖,没有新增(sava方法,如果不指定id,系统则随意造id,新增)
2.1)文档改的语法
db.table.update(
条件,
其他字段,
其他参数
)
2.2)文档修改
db.table.update( {}, # 不指定条件指查询全部 {"age":11}, # 将年纪修改为11 { "multi":true, # 默认为falue,只修改第一条。true,修改所有 "upsert":true # 如果查询不到,则增加该条 } ) 错误示例 db.user.update( {"name":"dasb"}, # 查询到这个条件 {"age":23,"name":"xsb} # 将符合条件的原有的数据覆盖成了这个结果 ) 正确示例(局部修改) db.user.update( {"name":"dasb"}, {"$set":{"age":23,"name":"xsb}} )
db.cmdb_instance.updateMany({userName:"daxhxcmdb"}, {$set:{userName:"deaosi"}});
3)对字段中的value(整数)的加减。$inc方法
db.user.update( {}, {"$inc":"age":1} # 将第一条的年纪加1;"age":-5,则减5 )
4)$push 和$addToSet
4.1)$push ,类似于列表的append方法。$addToSet 避免添加重复的内容
db.user.update( {"name":"dasb"}, {"$push":{"hobbies":"tangtou"}}, {"multi":true} ) # $push+$each 可连续append多个值 db.user.update( {"name":"dasb"}, {"$push":{"hobbies":{"$each":["纹身","抽烟"}}}, {"multi":true} ) # $addToSet 避免添加重复的内容 db.user.update( {}, {"$addToSet":"numbers":{"$each":[1,2,3,2,3]}}, )
三、对文档(表中的数据)的删除
1)删除字段 $unset
db.user.update( {"name":"dasb"}, {"$unset":{"age":""}} # 删除该字段。$unset,字段为空 )
2) $pop 删除字段列表值,可模拟队列
db.user.update( {"name":"dasb"}, {"$pop":{"hobbies":-1}} # 删除该字段里面的列表的第一个,从头删-1,从尾删1 )
3)$pull ,按照条件删除
db.user.update( {"name":"yuaohao"}, {"$pull":{"hobbbies":"纹身"}}, {"multi":true} )
四、对文档删除(整体数据删除)
db.user.deleteOne({"_id":{"$gte":3}}) # 删除大于等于3的,找到的第一条
db.user.deleteMany({"_id":{"$gte":3}}) # 删除多条
db.user.deleteMany({}) # 删除全部
五、深入查询
数据准备阶段
# pip install pymongo from pymongo import MongoClient import datetime client=MongoClient('mongodb://root:123@localhost:27017') table=client['db1']['emp'] # table.drop() l=[ ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ] for n,item in enumerate(l): d={ "_id":n, 'name':item[0], 'sex':item[1], 'age':item[2], 'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'), 'post':item[4], 'salary':item[5] } table.save(d)
1)聚合操作。聚合aggregate:过滤 $match,分组$group
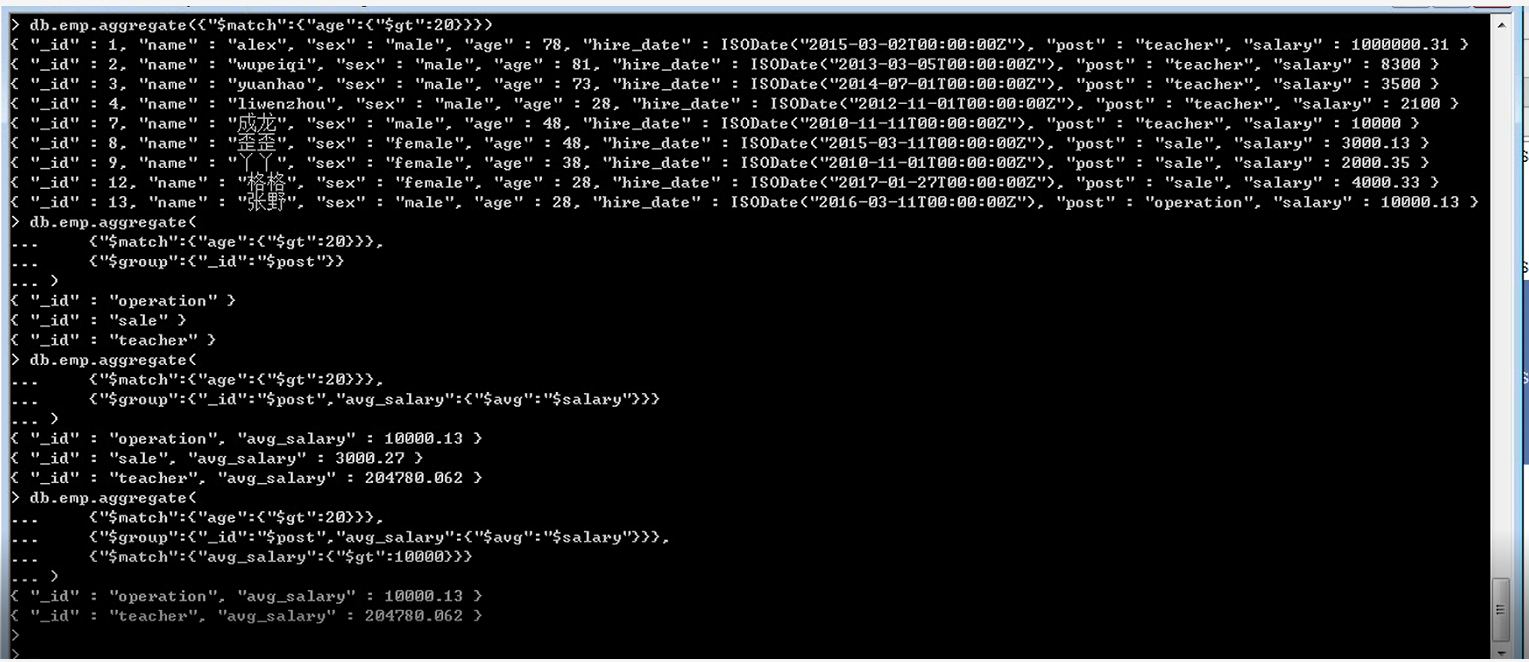
过滤 $match 在mysql中:select * from db1.emp where age > 20; db.emp.aggregate({"$match":{"age":{"$gt":20}}}) 分组 $group 在mysql中:select * from db1.emp where age > 20 group by post; db.emp.aggregate( {"$match":{"age":{"$gt":20}}}, {"$group":{"_id":"$post"}} # _id分组依据。注意不是默认的表的_id区分。$post,取post字段的value值 ) 再算出平均工资 db.emp.aggregate( {"$match":{"age":{"$gt":20}}}, {"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}} ) # 再过滤出平均工资大于10000的 db.emp.aggregate( {"$match":{"age":{"$gt":20}}}, {"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}}, {"$match":{"avg_salary":{"$gt":10000}}} )
2)投射操作 {"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}
# 显示需要的字段。mysql中,select age,salary from table; db.emp.aggregate( {"$project":{"_id":1,"name":1,"post":1,"salary":1}} ) # 映射,将月薪映射成年薪,$multiply 相乘 db.emp.aggregate( {"$project":{"_id":1,"name":1,"post":1,"annual_salary":{"$multiply":[12,"$salary"]}}} ) # 计算每个部门的平均年薪 db.emp.aggregate( {"$project":{"_id":1,"name":1,"post":1,"annual_salary":{"$multiply":[12,"$salary"]}}}, {"$group":{"_id":"$post","平均年薪":{"$avg":"$annual_salary"}}} ) # 过滤出部门平均年薪大于1000000的 db.emp.aggregate( {"$project":{"_id":1,"name":1,"post":1,"annual_salary":{"$multiply":[12,"$salary"]}}}, {"$group":{"_id":"$post","平均年薪":{"$avg":"$annual_salary"}}}, {"$match":{"平均年薪":{"$gt":1000000}}} ) # 再使用投射 db.emp.aggregate( {"$project":{"_id":1,"name":1,"post":1,"annual_salary":{"$multiply":[12,"$salary"]}}}, {"$group":{"_id":"$post","平均年薪":{"$avg":"$annual_salary"}}}, {"$match":{"平均年薪":{"$gt":1000000}}}, {"$project":{"部门名":"$_id","平均年薪":1,"_id":0}} )
3)时间操作。$subtract 相减,现在时间,new Date()
# 计算出工作时间,$subtract 相减,现在时间,new Date(), db.emp.aggregate( {"$project":{"_id":0,"name":1,"hire_period":{"$subtract":[new Date(),"$hire_date"]}}} ) # 时间中2017-10-12,过滤出年 db.emp.aggregate( {"$project":{"_id":0,"name":1,"hire_year":{"$year":"$hire_date"}}} )
4)将字符串变为大写,字符串加后缀,取字符串字节
# 将名字变为大写 db.emp.aggregate( {"$project":{"_id":0,"new_name":{"$toUpper":"$name"}}} ) # 过滤出除了egon的,其他的名字后缀都加 _SB db.emp.aggregate( {"$match":{"name":{"$ne":"egon"}}}, {"$project":{"_id":0,"new_name":{"$concat":["$name","_SB"]}}} ) # 取出名字的前3个字节,是以utf8做的编码。必须是以3的倍数取值 db.emp.aggregate( {"$match":{"name":{"$ne":"egon"}}}, {"$project":{"_id":0,"new_name":{"$substr":["$name",0,3]}}} )
5)排序 $sort 、限制$limit 、跳过$skip,随机 sample
db.emp.aggregate( {"$match":{"name":{"$ne":"egon"}}}, {"$project":{"_id":1,"new_name":{"$substr":["$name",0,3]}}} {"$sort":{"age":1,"_id":-1}}, # 1,从小到大;-1,从大到小 {"$skip":5}, # 跳过5条 {"$limit":5} # 再查找5条 ) 补充,随机取3 db.emp.aggragate({"sample":{"size":3}})
6) 模糊查询
db.cmdb_instance.find({"instance_id":{"$regex": /ins/}})
db.cmdb_instance.find({"instance_id":{"$regex": /ins/,"$options":"ins"}})
db.cmdb_instance.find({"instance_id":{"$options": ins}})
7)综合练习
db.emp.aggregate( {"$group":{ "_id":"$post", "max_age":{"$max":"$age"}, "min_id":{"$min":"$_id"}, "avg_salary":{"$avg":"$salary"}, "sum_salary":{"$sum":"$salary"}, "count":{"$sum":1}, "names":{"$push":"$name"} }} )

7)解决查找慢的问题,索引
7.1)建立索引
rs1:PRIMARY> use mocker switched to db mocker rs1:PRIMARY> db.MockerTemplate.ensureIndex({mdmId:1, timestamp:1},{backgroud:true}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 2, "numIndexesAfter" : 2, "note" : "all indexes already exist", "ok" : 1 } rs1:PRIMARY>
7.2)查看索引
rs1:PRIMARY> db.MockerTemplate.getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "mocker.MockerTemplate" }, { "v" : 1, "key" : { "mdmId" : 1, "timestamp" : 1 }, "name" : "mdmId_1_timestamp_1", "ns" : "mocker.MockerTemplate", "backgroud" : true } ] rs1:PRIMARY>
7.3)mongo备份
#!/bin/bash #variable LOG='mongoback_monitor.log' LOG_TIME=$(date +%F-%H) BACKUP_PATH='/data1/mongo_backup' #PORT=(8082 27017) cornsun_list='iotansible0001:8082,api-gateway0001:8082,api-gateway0002:8082' mongo_hub='mongodb-hub-service0001:27017,mongodb-hub-service0002:27017' mongo_vd='mongodb-vd0001:27017,mongodb-vd0002:27017' #HOST=$(hostname) #hubvd_list=( # mongodb-hub-service0001:27017,mongodb-hub-service0002:27017 # mongodb-vd0001:27017,mongodb-vd0002:27017 #) #cornsun_mongo path MONGO_PATH=( /usr/local/bin/monitor/mongodb-linux-x86_64-rhel62-3.2.0/bin /home/envuser/monitor/mongodb-linux-x86_64-rhel62-3.2.0/bin ) start(){ echo "[${LOG_TIME}]=====cornsun backup start ========" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} for path in "${MONGO_PATH[@]}" do if [ -d "$path" ] then if "${path}"/mongodump --host "${cornsun_list}" --db cronsun --excludeCollection job_log --excludeCollection log_scan --gzip --archive=${BACKUP_PATH}/cornsun-"${LOG_TIME}".gz &>> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} then echo "cornsun ${cornsun_list} Backup successful, delete old files 3 days ago" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} find $BACKUP_PATH -type f -mtime +3 -name "cornsun*.gz" -exec rm -f {} \; find $BACKUP_PATH -type f -mtime +3 -name "*.log" -exec rm -f {} \; else echo "====cornsun ${cornsun_list} Backup failed!====" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi else echo "=====dir $path is not exist.=====" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi done } hubstart(){ echo "[${LOG_TIME}]=====hub-vd backup start ========" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} for dir in "${MONGO_PATH[@]}" do if [ -d "${dir}" ] then if "${dir}"/mongodump --host "${mongo_hub}" --gzip --archive=${BACKUP_PATH}/"${mongo_hub:0:12}"-"${LOG_TIME}".gz &>> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} then echo "${mongo_hub} Backup successful, delete old files 3 days ago" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} find $BACKUP_PATH -type f -mtime +3 -name "*.gz" -exec rm -f {} \; find $BACKUP_PATH -type f -mtime +3 -name "*.log" -exec rm -f {} \; else echo "====Backup failed, hostname: ${mongo_hub} " >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi else echo "=====dir $dir is not exist.=====" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi done } vdstart(){ echo "[${LOG_TIME}]=====hub-vd backup start ========" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} for dir in "${MONGO_PATH[@]}" do if [ -d "${dir}" ] then if "${dir}"/mongodump --host "${mongo_vd}" --gzip --archive=${BACKUP_PATH}/"${mongo_vd:0:12}"-"${LOG_TIME}".gz &>> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} then echo "${mongo_vd} Backup successful, delete old files 3 days ago" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} find $BACKUP_PATH -type f -mtime +3 -name "*.gz" -exec rm -f {} \; find $BACKUP_PATH -type f -mtime +3 -name "*.log" -exec rm -f {} \; else echo "====Backup failed, hostname: ${mongo_vd} " >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi else echo "=====dir $dir is not exist.=====" >> ${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} fi done } main(){ if [ -d "${BACKUP_PATH}" ] then start else mkdir $BACKUP_PATH &>>${BACKUP_PATH}/"$(date +%Y%m%d)"-${LOG} start fi } main
7.4)mongo的恢复
/usr/local/mongodb/bin/mongorestore --gzip --archive=cornsun-2019-07-18-13.gz
7.5) 手动备份
备份指定库(已测试) mongodump --port 27017 --username root --password 123456 --authenticationDatabase admin -d cmdb_data 导出特定集合的数据 mongodump --db mydatabase --collection mycollection 导出满足特定查询条件的数据 mongodump --db mydatabase --collection mycollection --query '{ "field": "value" }' 使用gzip压缩导出备份数据 mongodump --db mydatabase --gzip --out /path/to/backup

 浙公网安备 33010602011771号
浙公网安备 33010602011771号