Python数据分析-用户对于购买商品的行为分析案例
用户对于购买商品的行为分析案例
import pandas as pd from pandas import DataFrame,Series import numpy as np import matplotlib.pyplot as plt %matplotlib inline #数据量级达到一亿,考虑到电脑性能问题,故随机抽样其中的100万左右数据作为本次分析的原始数据. df = pd.read_csv('./UserBehavior.csv',header=None,names=['user_id','item_id','category_id','behavior_type','time_stamp']) #header=None 让第一行不做列索引,让name后的做
data = df.take(indices=np.random.permutation(df.shape[0]),axis=0)[0:1000000] #随机抽取100W条数据
data.to_csv('./UserBehavior_new.csv') #保存到本地
df = pd.read_csv('./UserBehavior_new.csv') #读取本地的100W数据
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
df.head()
#查看是否存在重复的行数据 (df.duplicated()).sum() #duplicated 是看有没有重复值 返回的是一组布尔值,再将之累加 看有多少个true(true 为1 false 为0)
0
#查看列中是否存在缺失数据 df.isnull().any(axis=0) user_id False item_id False category_id False behavior_type False time_stamp False dtype: bool
#将时间戳转换为时间序列类型 #time.strftime("%Y-%m-%d", time.localtime(1511572885)) import time #方式1: pd.to_datetime(df['time_stamp'],unit='s')
#方式2:
#用运算工具apply 或者map map速度较慢 这里使用apply 用time.strftime将时间戳转换为字符串类型 然后再转成时间序列类型
def get_str_dt(d): return time.strftime('%Y-%m-%d',time.localtime(d)) df['time_stamp'] = df['time_stamp'].apply(get_str_dt) df['time_stamp'] = pd.to_datetime(df['time_stamp']) df.head().info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5 entries, 0 to 4 Data columns (total 5 columns): user_id 5 non-null int64 item_id 5 non-null int64 category_id 5 non-null int64 behavior_type 5 non-null object time_stamp 5 non-null datetime64[ns] dtypes: datetime64[ns](1), int64(3), object(1) memory usage: 280.0+ bytes
#添加一列为月份 df['month'] = df['time_stamp'].astype('datetime64[M]')
#查看数据的时间范围,如有异常值将其删除 #发现极大部分数据都是17年,其他都是2025年 1927年等离谱数据 这里只保留17年的数据即可 df['time_stamp'].value_counts()
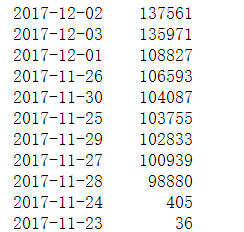
ex = (df['time_stamp'] >= '2017-01-01') & (df['time_stamp'] <= '2017-12-31') #筛选出17年的数据 df = df.loc[ex] #将17年的数据取出 赋值给原数据 df['time_stamp'].max(),df['time_stamp'].min() #看一下 最大最小日期是否符合要求 (Timestamp('2017-12-27 00:00:00'), Timestamp('2017-04-13 00:00:00'))
#对所有用户的不同购买行为进行数量统计且求得不同购买行为的百分比,以柱状图进行展示
#针对同一用户多次PV 这里使用nunique 进行去重
s_persent = df.groupby(by='behavior_type')['user_id'].nunique() / df.groupby(by='behavior_type')['user_id'].nunique().sum() * 100 plt.bar(s_persent.index,s_persent.values)
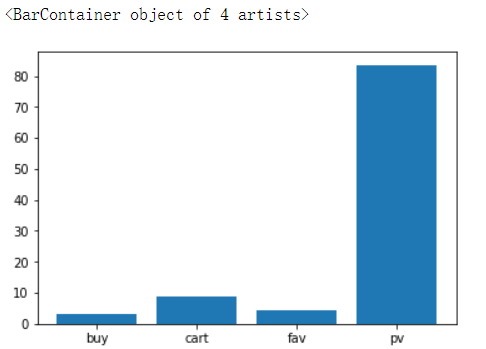
#发现用户点击量占据83%,而购买量仅占所有数据的3.3%,,用户从浏览到购买的转化#率只有2%,那是什么原因导致的转化率低呢? #分析出每个用户对商品的不同行为 df.head()
one_hot_df = pd.get_dummies(df['behavior_type']) #one_hot编码 针对某些不是数值型的数据 进行数据汇总使用get_dummies 将之转换成数据型数据 0 和1 然后以行索引 确定0/1 所代表的的信息
user_item_behavior_df = pd.concat((df[['user_id','item_id']],one_hot_df),axis=1) #将用户ID和商品ID和one_hot_df 横向拼接
user_item_behavior_df.head()
![]()
#分析出每个用户对商品的不同行为次数的汇总 pv_sum = user_item_behavior_df.groupby(by='user_id')['pv'].sum() buy_sum = user_item_behavior_df.groupby(by='user_id')['buy'].sum() cart_sum = user_item_behavior_df.groupby(by='user_id')['cart'].sum() fav_sum = user_item_behavior_df.groupby(by='user_id')['fav'].sum() user_behavior_total_df = DataFrame(data=[pv_sum,buy_sum,cart_sum,fav_sum]).T # T转置让行变列 列变行 user_behavior_total_df.head()

# 1.点击量:所有用户的总点击量 pv_count = user_behavior_total_df['pv'].sum() pv_count 896151 #2.点击--购买:用户点击后无加购和收藏的情况下直接参与购买的行为统计 pv_buy_count = user_behavior_total_df.query('pv > 0 & cart ==0 & fav == 0 & buy > 0').shape[0] 10069 #3.点击--加购:点击后,无收藏情况下的加购行为 pv_cart_count = user_behavior_total_df.query('pv > 0 & cart > 0 & fav == 0').shape[0] 31234 #4.点击--加购--购买:点击后无收藏情况下的加购和购买行为 pv_cart_buy_count = user_behavior_total_df.query('pv > 0 & cart > 0 & buy > 0 & fav ==0').shape[0] 966 #5.点击--收藏:点击后,无加购情况下的收藏行为 pv_fav_count = user_behavior_total_df.query('pv > 0 & fav > 0 & cart == 0').shape[0] 16450 #6.点击--收藏--购买:点击后,无加购情况下的收藏和购买行为 pv_fav_buy_count = user_behavior_total_df.query('pv > 0 & fav > 0 & buy > 0 & cart ==0').shape[0] 393 #7.点击--收藏+加购:点击后的收藏和加购行为 pv_fav_cart_count = user_behavior_total_df.query('pv > 0 & fav > 0 & cart > 0').shape[0] 1044 #8.点击--收藏+加购 -- 购买:点击后的收藏加购和购买的行为 pv_fav_cart_buy_count = user_behavior_total_df.query('pv > 0 & fav > 0 & cart > 0 & buy > 0').shape[0] 20
#9.点击--流失:点击后无购买无加购无收藏的行为 pv_loss_count = user_behavior_total_df.query('pv > 0 & buy ==0 & cart == 0 & fav ==0 ').shape[0] 434326
#1.直接购买转化率:点击–购买 / 点击量
pv_buy_count / pv_count
0.01123582967602558
#2.加购购买转换率:点击 => 加购 + 购买 / 点击 => 加购
pv_cart_buy_count / pv_cart_count
0.030927835051546393
#3.收藏购买转换率:点击 => 收藏 => 购买 / 点击 => 收藏
pv_fav_buy_count / pv_fav_count
0.02425531914893617
#4.加购收藏购买转换率:点击 => 加购 + 收藏 => 购买 / 点击 => 加购 + 收藏
pv_fav_cart_buy_count / pv_fav_cart_count
0.019157088122605363
#5.流失率:点击–流失 / 点击量
pv_loss_count / pv_count
0.48465716157210115
#直接购买转化率低于加购和收藏等行为之后的综合转换率,因此需要从产品交互界面、#营销机制等方面让用户去多加购,多收藏。 #转化率低的原因分析: #提出假设:推荐机制不合理,给用户推荐的都是不喜欢的商品,造成转化率低 #这里可以通过分析高浏览量商品与高购买量商品之间是否存在高度重合,如果是的,那#就说明推荐的商品是用户喜欢,假设就不成立,如果不是则证明假设成立。 #分析出点击量前10的商品 pv_sum_item_10_s = user_item_behavior_df.groupby(by='item_id')['pv'].sum().sort_values().tail(10) pv_sum_item_10_s item_id 3031354 172.0 987143 173.0 2338453 186.0 2331370 188.0 3371523 190.0 2032668 193.0 1535294 194.0 138964 211.0 3845720 258.0 812879 296.0 Name: pv, dtype: float64 #购买量前10的商品 buy_sum_item_10_s = user_item_behavior_df.groupby(by='item_id')['buy'].sum().sort_values().tail(10) buy_sum_item_10_s item_id 555181 7 4443059 7 793577 7 3189426 8 2560262 8 1168232 8 705557 9 3964583 13 3031354 13 3122135 18 Name: buy, dtype: uint8 #查看点击量高且购买量也高的商品类别个数 buy_sum_item_10_s.append(pv_sum_item_10_s).index.value_counts() #把两个series 拼一起 看那个商品出现在两个series里
3031354 2 1535294 1 812879 1 3371523 1 2560262 1 3964583 1 1168232 1 793577 1 2331370 1 555181 1 2338453 1 2032668 1 3189426 1 4443059 1 138964 1 705557 1 3122135 1 3845720 1 987143 1 Name: item_id, dtype: int64
#计算点击量前10的商品的购买量 pv_10_buy = [] for index in pv_sum_item_10_s.index: buy_count = user_item_behavior_df.loc[user_item_behavior_df['item_id'] == index]['buy'].sum() dic = { 'item_id':index, 'buy_count':buy_count } pv_10_buy.append(dic) pv_10_buy [{'item_id': 3031354, 'buy_count': 13}, {'item_id': 987143, 'buy_count': 2}, {'item_id': 2338453, 'buy_count': 1}, {'item_id': 2331370, 'buy_count': 0}, {'item_id': 3371523, 'buy_count': 0}, {'item_id': 2032668, 'buy_count': 0}, {'item_id': 1535294, 'buy_count': 1}, {'item_id': 138964, 'buy_count': 3}, {'item_id': 3845720, 'buy_count': 0}, {'item_id': 812879, 'buy_count': 1}] #计算购买量前10的点击量 pv_sum_list = [] for index in buy_sum_item_10_s.index: pv_sum = user_item_behavior_df.loc[user_item_behavior_df['item_id'] == index]['pv'].sum() dic = { 'item_id' : index, 'pv_sum':pv_sum } pv_sum_list.append(dic) pv_sum_list [{'item_id': 555181, 'pv_sum': 2}, {'item_id': 4443059, 'pv_sum': 140}, {'item_id': 793577, 'pv_sum': 20}, {'item_id': 3189426, 'pv_sum': 44}, {'item_id': 2560262, 'pv_sum': 103}, {'item_id': 1168232, 'pv_sum': 33}, {'item_id': 705557, 'pv_sum': 89}, {'item_id': 3964583, 'pv_sum': 54}, {'item_id': 3031354, 'pv_sum': 172}, {'item_id': 3122135, 'pv_sum': 25}] #总结:可以看出点击量高的购买量不一定高,推荐的商品顾客并不喜欢购买,由于高#浏览量并没有带来购买,所以转化率低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号