word2Vec笔记2021
1.word2vec相关概念
- 单词转成词向量表示,便于神经网路模型的训练。单词转成数值表示后,更便于对单词做翻译、相似度计算、查找等。
- Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 词向量 形式的表示。如:
公 [ 0.5 0.125 0.5 0,25 0.35 0.45] #维度有200维度,各个维度表示词在对应语料库的特征
word2vec有2种训练模型:
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
1.1 词嵌入
假设现有若干篇文章,分词后,这些文章共有5万个词汇,如果用One-hot对单词编码,则每个单词维度很大。则个时候可以通过如下方法降维:
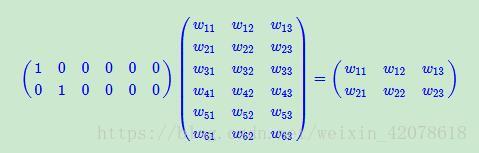
说明:假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。先不管它什么意思,这个过程,我们把一个12个元素的矩阵变成6个元素的矩阵,直观上,大小是不是缩小了一半?这就是词汇的embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。
- 2*6就是原始矩阵
- 6*3就是训练权重,神经网络模型各个层的权重
- 2*3就是最后的词嵌入层。原来每个词是6维向量表示,经过矩阵乘积后降维成3维向量。而中间权重参数是神经网络结合各种语料训练,能让最后降维后的向量表示更接近词汇本身特征描述。
所以:word2vec就是要把每个词汇放入神经网络模型训练,得到每个单词降维后的词嵌入即词向量表示。这里就要不断训练图中的权重矩阵。而每个句子中单词的上下文关系非常适合用于训练数据,最终得到每个词汇的特征向量。
1.2 word2vec模型原理
1.2.1 上下文语料库数据
语料测试数据。结合上下文语料训练,如图中not训练下一个单词
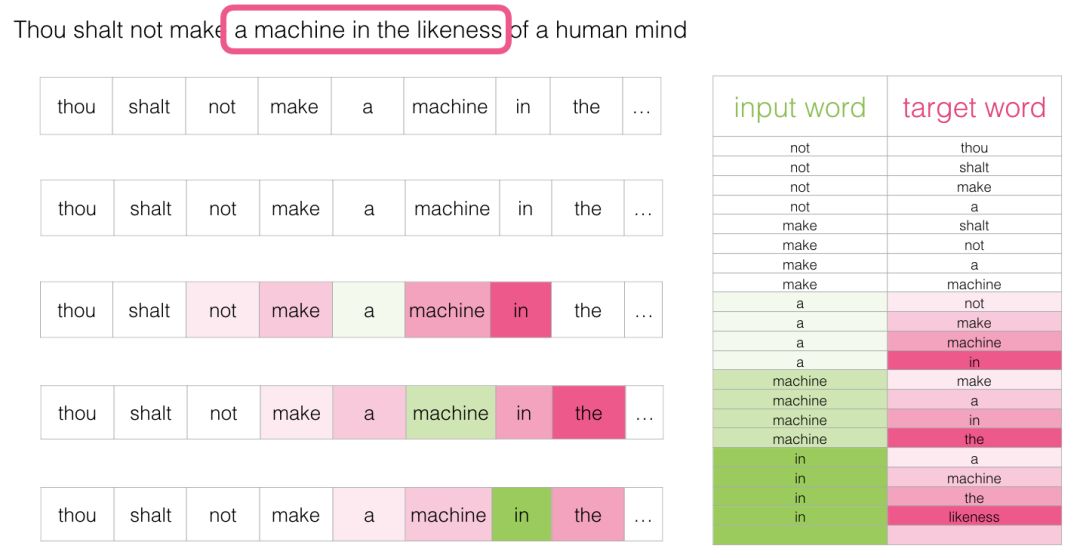
1.2.2 训练模型
-
(1)每个单词先在词嵌入表中查找其对应的词向量,并使用它们来计算预测下一个词出现的概率
![]()
-
(2)not单词进入训练模型,模型预测下一个单词,和真实样本比较,错误就反向训练模型。
图:“目标向量”的词(字)概率为1,其他词(字)的概率都是0。我们减去两个向量,得到一个误差向量:现在可以使用此误差向量来更新模型,以便下次当“not”作为输入时,模型更有可能猜测“thou”。这就是训练的第一步。我们继续使用数据集中的下一个样本进行相同的处理,然后是下一个样本,直到我们覆盖了数据集中的所有样本。这就结束了一个epcho的训练。我们继续训练多个epcho,然后我们就有了训练好的模型,我们可以从中提取嵌入矩阵并将其用于任何其他应用。
![]()


1.2.3 负采样
上图预测结果是多分类,非常消耗资源:尤其是我们将在数据集中为每个训练样本做一次(很可能数千万次)。我们需要做一些事情来提高效率。可以把预测结果改成二分类,降低复杂度。即输入数据改成2个单词,然后预测是否上下文。

但是现有的语料库都是正向数据,所以还要加入负向数据,才能保证模型的准确率。这就是负采样步骤。负采样做法:对于我们数据集中的每个样本,我们添加了负样本。它们具有相同的输入词和0标签。但是我们填写什么作为输出词?我们从词汇表中随机抽取单词。这个想法的灵感来自Noise-contrastive estimation。我们将实际信号(相邻单词的正例)与噪声(随机选择的不是邻居的单词)进行对比。这是计算量和统计效率的巨大折衷。
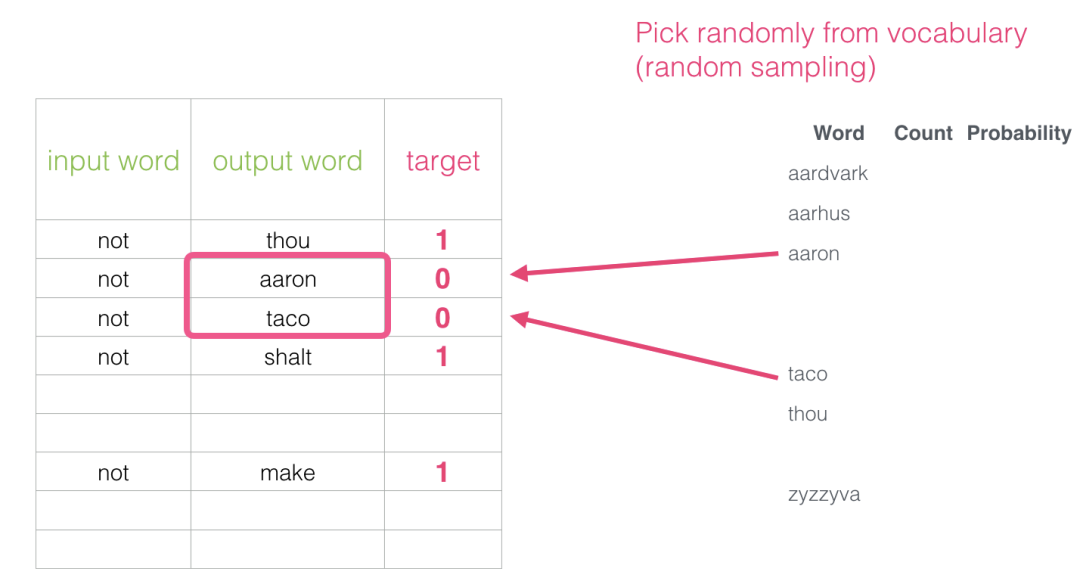
word2vec中的两个核心思想:skipgram和负采样。
1.3 word2vec训练过程
1.初始化词嵌入矩阵和上下文词嵌入矩阵
在训练过程开始之前,我们预先处理我们正在训练模型的文本。在这一步中,我们确定词汇量的大小(我们称之为vocab_size,比如说,将其视为10,000)以及哪些词属于它。在训练阶段的开始,我们创建两个矩阵 - Embedding矩阵和Context矩阵。这两个矩阵在我们的词汇表中嵌入了每个单词(这vocab_size是他们的维度之一)。第二个维度是我们希望每次嵌入的时间长度(embedding_size- 300是一个常见值)

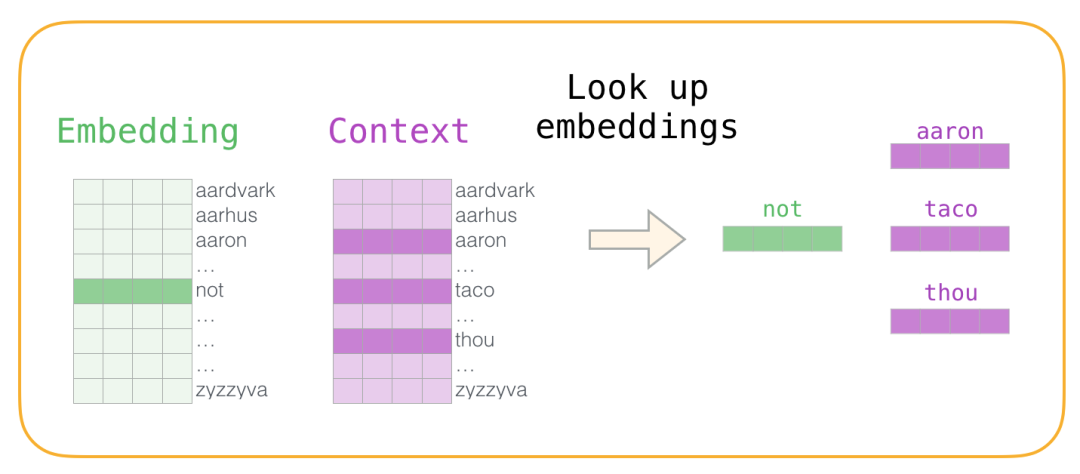
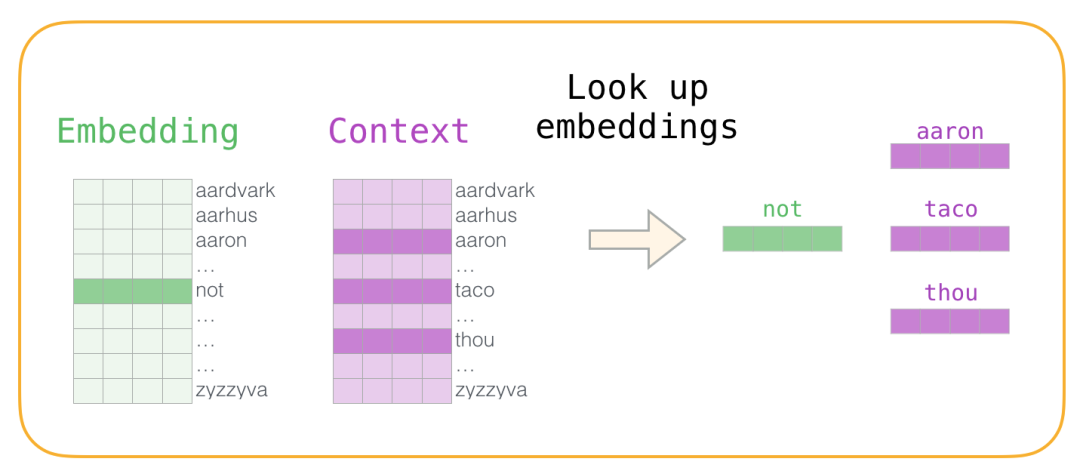
2.从正、负语料数据中查找上下文词的词嵌入向量
现在我们有四个单词:输入单词not和输出/上下文单词:( thou实际邻居),aaron,和taco(负样本)。我们继续查找它们的嵌入 - 对于输入词,我们查看Embedding矩阵。对于上下文单词,我们查看Context矩阵(即使两个矩阵都在我们的词汇表中嵌入了每个单词)。
3.计算输入词向量和上下午单词向量的点积。
我们计算输入嵌入与每个上下文嵌入的点积。。在每种情况下,会产生一个数字,该数字表示输入和上下文嵌入的相似性。需要一种方法将这些分数转化为看起来像概率的东西 :使用sigmoid函数把概率转换为0和1。
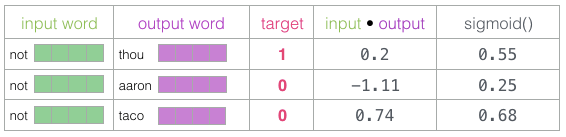
4.获取计算误差,反向传播训练模型(训练嵌入层向量)
现在我们可以将sigmoid操作的输出视为这些样本的模型输出。您可以看到taco得分最高aaron,并且在sigmoid操作之前和之后仍然具有最低分。既然未经训练的模型已做出预测,并且看到我们有一个实际的目标标签要比较,那么让我们计算模型预测中的误差。为此,我们只从目标标签中减去sigmoid分数。

5.利用误差,反复训练模型
训练步骤到此结束。我们从这一步骤中得到稍微好一点的嵌入(not,thou,aaron和taco)。我们现在进行下一步(下一个正样本及其相关的负样本),并再次执行相同的过程。当我们循环遍历整个数据集多次时,嵌入继续得到改进。然后我们可以停止训练过程,丢弃Context矩阵,并使用Embeddings矩阵作为下一个任务的预训练嵌入。
参考资料
2.怎么用word2vec
2.1 加载腾讯语料库代码
适合新闻文本数据
from gensim.models.word2vec import KeyedVectors
import jieba
import pandas as pd
import gensim
from gensim.models import word2vec
model = KeyedVectors.load_word2vec_format("45000-small.txt") #加载训练好的词向量
print(model.doesnt_match("性价比 好".split(" ")))
print(model.similarity('好',"超好"))
print(model.most_similar(positive=['设施', '好'], negative=['不好'], topn=1))
##其意义是计算一个词d(或者词表),使得该词的向量v(d)与v(a="设施")-v(c="不好")+v(b="好")最近
print(model.doesnt_match("上海 成都 广州 北京".split(" ")))
print(model.most_similar('不错',topn=10))
2.2 加载自定义的语料库--评论文本为例
适合特定环境的语料。如酒店评论文本
def divide_word(df,column='评论内容'): #分词
seg_list = jieba.cut(df[column], cut_all=False)
return " ".join(seg_list)
data_hotel=pd.read_csv("data/process_data/酒店评论.csv",encoding='gbk')
data_hotel['评论分词'] = data_hotel.apply(divide_word,axis = 1)
sentences=[]
for item in data_hotel['评论分词']: #改成二维列表保存,word2Vec识别
ls=item.split(" ")
sentences.append(ls)
for item in data_area['评论分词']:
ls=item.split(" ")
sentences.append(ls)
model = gensim.models.Word2Vec(sentences, vector_size=200) #加载自定义语料库
print(model.wv.most_similar('服务',topn=10))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号