
在.Net v1.1 时代, 应该使用Dataset还是应该使用自定义容器(Custom Classes)的争论一直没消停过. 撇开开发效率而仅就developer关心的性能而言, Dataset其性能低下Xml序列化方式一直备受责难.(我自己参与的项目中也遇到过因为xml序列化而产生的问题: 由于要序列化的Dataset过于庞大,直接导致Application Server Out of Memory)
Jimmy Nilsson 先生在www.informit.com网站上发表一组文章<<Choosing Data Containers for .NET>> (1, 2, 3, 4 and 5) 详细对比了.Net 1.1下面各个容器的性能.(如果你还没有看过,请阅读后再继续本文). 从最后的比较结果可以看出, 在常见的分布式系统中,使用Custom Class容器能获得最好的性能(大约是Untyped Dataset的2.8倍)
于是, 很多人针对1.1下Dataset的序列化问题 提出了很多改进意见.
不过这些改进方法大多需要开发人员编写更多的代码, 在项目进度紧张的时候往往无法投入更多的精力.
还好,Microsoft也意识到了他们心爱的Dataset存在的问题,于是在.Net 2.0中好好的加强了一把Dataset的功能.
其中最吸引人眼球的就是: Dataset能支持真正意义上的Binary序列化了, 而我们需要做的工作呢,只用写一句话:
 ds.RemotingFormat = SerializationFormat.Binary
ds.RemotingFormat = SerializationFormat.Binary我们先来对比测试一下(代码略): 对一个包含3个column, 大约10000条数据的Dataset, 采用binary序列化生成的文件大小是采用xml序列化的28% (457kb : 1.6MB), 花费的时间只是xml的35%. 看上去真好极了.
那么来试试实际的分布式系统下, binary序列化Dataset和CustomClasses比起来如何呢?
我首先想到复用Jimmy Nilsson先生在他文章中使用的测试代码. 不过遗憾的是, Jimmy Nilsson 先生的代码是VB写的,而且很多Method签名是以"_"开头的, VB2005老是报告说这种签名不是CLS-compliant. 无奈之下,我只好动手写自己的测试代码(复用了Jimmy Nilsson 先生代码中数据库访问代码和他的数据), 得出如下结果: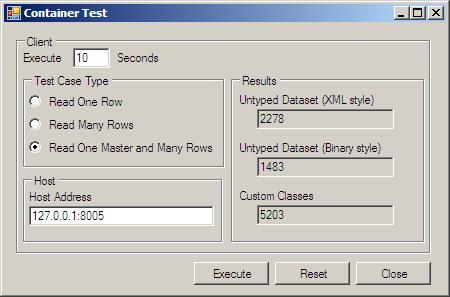
(图中显示的数字是在单元时间内(这个是10秒) 连续访问Server请求数据的次数,该数字越大,说明有越好吞吐量)
结果大大出乎我的意料:采用binary序列化方式居然是最慢的,比传统xml方式还慢!
起初我怀疑是binary序列化没有起作用, 顺带还发现了这个问题 .
但后来分析了一下,应该考虑返回数据量的问题,于是去查了下Jimmy Nilsson 先生代码使用的数据, 发现返回多条数据时, 一次查询只返回了10条记录! 这说明前面的测试仅仅是针对_高频率小数据量_的查询. 在这种情况下, 采用binary序列化性能非但不能得到提升,反而会有所下降.
既然binary序列化的优势在于处理包含大量数据的Dataset,那么我们继续改进测试代码,以检验大数据量下binary序列化的性能.
改进后的测试界面:
(一次请求300条记录)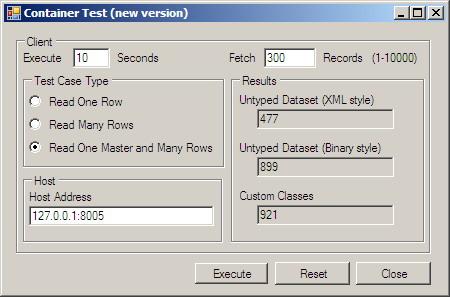
(一次请求3000条记录)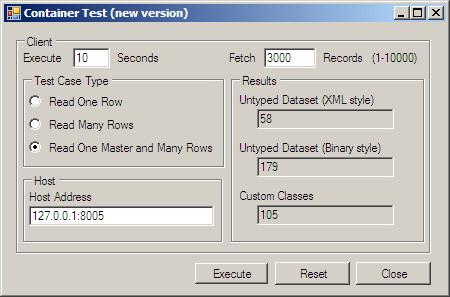
以下是不同数据量的测试结果(呼, 累死我了 :) )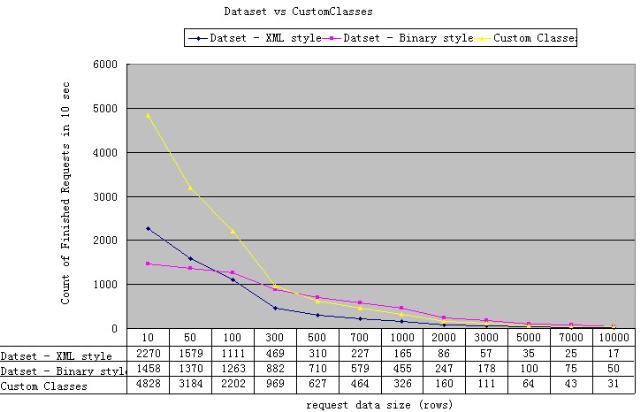
分析结果:
(注意, 这个测试结果和DB scheme有关. 本测试用的数据库表包含3个int,1个decimal和一个string类型的column)
如果一次请求返回的数据量在70条以下时, CustomClass性能遥遥领先, binary序列化的DataSet却是最差.原因估计是小数据量的dataset进行binary序列化得不偿失.
在数据量在70到350条之间时, CustomClass仍然是最快的, binary取代xml取得第二的位置, 优势慢慢展现出来了.
当数据量大于350条以后,binary序列化Dataset的潜力完全发挥出来了, 一举夺得了第一的位置. CustomClass变成了第二. (在测试返回10000条数据这种最极端的测试时, binary序列化dataset能够完成50次请求,而custom class只能完成31次) 至于xml序列化的Dataset,呃,我们就不用管他啦:)
最后结论:
.Net 2.0为Dataset提供的binary序列化的确能大大提供Dataset的使用性. 在获取大数据的时候甚至可以超过custom class. 但如果您的应用每次请求都只是返回少量数据, Custom Class仍然是您最好的选择.
个人推荐:
返回少量数据时: 使用custom classes
返回大量数据时: 别...,别直接使用binary untyped dataset, 为了兼顾性能和代码的维护性(以及OO的纯洁),请使用wrapped binray dataset. 个人认为最可怕的项目就是在系统到处都能看到处理dataset的代码.
进一步思考:
在我自己的测试中, 我没有考虑dataReader (跨应用程序域性能太差), Typed Dataset (Typed Dataset性能大约是Untyped Dataset的90%左右(推测)). 对于Custom Classes, 我也是只是简单的使用了[Serializable], 不知道如果自己实现ISerializable,性能是否能有所提高. 如果读者您有兴趣, 可以自己扩展测试代码,不过别忘记告诉我您的测试结果哦.
测试代码在这里.
linkcd
2005/09/01
20:01
Updated:
很多朋友在看了本文之后都说performace不是考虑选择business entity的主要考虑因素, 其实我也是很倾向于使用自定义的entity. 写本文的初衷来自于我和leader的对话:
I: 在咱们的项目里面为何要用Dataset呢? 好恶心.
Leader: 用dataset开发很快啊, 你看我们的日程很紧, 做project不得不快,快,快. (做外包的悲哀)
I: 但是dataset不是pure OO呀
Leader: 然则OO的思想也不是每个developer都掌握的很好的呀
I: (看从OO的方面说服leader失败, 决定从preformance入手) Dataset序列化慢到死!
Leader: .Net 2.0就好了, dataset支持binary序列化了.
I: 那具体性能能提高多少呢?
Leader: 不知道,应该还不错吧.
于是我就实际测试了一下. 在测试之初,我以为binary dataset性能再好也最多和custom class持平,但是结果表明在特定情况下binary dataset的性能甚至超过了custom classes.
So, 天下没有绝对好的东西,也没有绝对坏的东西,只有在某种情况下最适合的东西. 我们要完整的了解它的正反面,根据当前的具体情况,才能作出正确的选择. :)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号