

机器学习——识别是否可回收物品
(一)选题背景
现在大家丢垃圾都是乱丢垃圾,可回收不可回收有害垃圾都堆叠在一起,做识别可回收垃圾就是为了工厂方便识别可再利用的垃圾。
可回收垃圾(Recyclable garbage)是一种可以再生循环的垃圾,是生活垃圾分类的主要工作和影响垃圾减量的重要因素;
不可回收垃圾(Non-recyclable garbage)大致分为三种:1.厨余垃圾 2.有毒有害垃圾 3.其他垃圾 ;不可回收垃圾生的危害主要体现在以下几个方面:1.侵占地表 2.污染大气 3.有毒
(二)机器学习案例设计方案
从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件打上标签,对数据进行预处理,利用keras,构建网络,训练模型,导入图片测试模型
参考来源:Python程序设计与应用教程
(三)机器学习的学习步骤
1、数据集

2、检查一下每个分组(训练 / 测试)中分别包含多少张图像
1 import os 2 3 # 训练集 4 train_path = "C:/Users/LinJX/Downloads/archive/DATASET/TRAIN/" 5 print('训练集 可回收图片:', len(os.listdir(train_path+"R"))) 6 print('训练集 非可回收图片:', len(os.listdir(train_path+"O"))) 7 # 验证集 8 VALIDATION_path = "C:/Users/LinJX/Downloads/archive/DATASET/VALIDATION/" 9 print('验证集 可回收图片:', len(os.listdir(VALIDATION_path+"R"))) 10 print('验证集 非可回收图片:', len(os.listdir(VALIDATION_path+"O")))

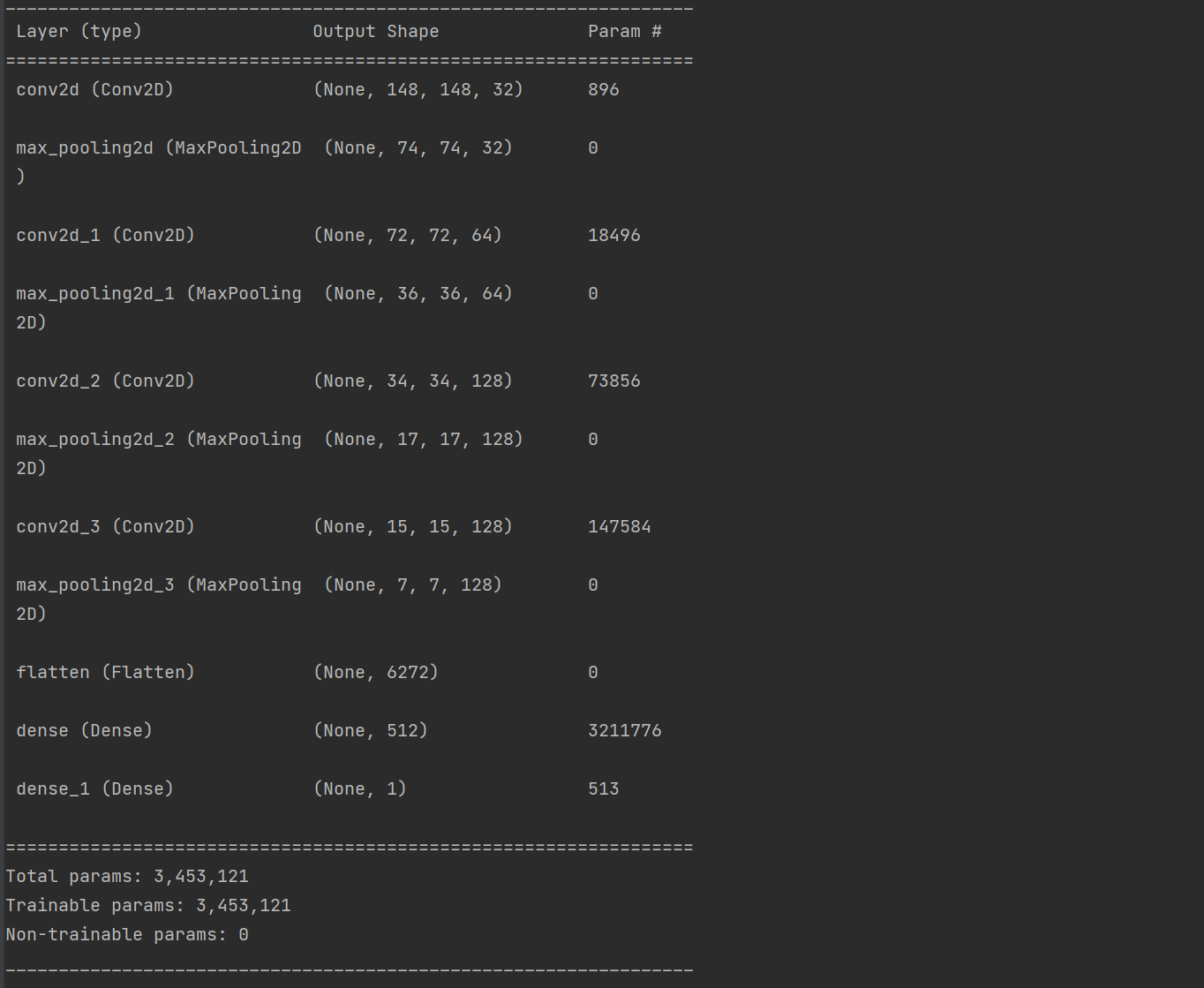
3、输出特征图的维度
1 from keras import layers 2 from keras import models 3 4 # 搭建网络 5 model = models.Sequential() 6 # Output shape计算公式:(输入尺寸-卷积核尺寸/步长+1 7 # 对CNN模型,Param的计算方法如下: 8 # 卷积核长度*卷积核宽度*通道数+1)*卷积核个数 9 # 输出图片尺寸:150-3+1=148*148 (输入尺寸-卷积核尺寸/步长+1 10 # 第一个卷积层作为输入层,32个3*3卷积核,输入形状input_shape = (150,150,3) 11 12 # 输出图片尺寸:150-3+1=148*148,参数数量:32*3*3*3+32=896 13 model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3))) 14 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:148/2=74*74 15 16 # 输出图片尺寸:74-3+1=72*72,参数数量:64*3*3*32+64=18496 17 model.add(layers.Conv2D(64,(3,3),activation = 'relu')) 18 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:72/2=36*36 19 20 # 输出图片尺寸:36-3+1=34*34,参数数量:128*3*3*64+128=73856 21 model.add(layers.Conv2D(128,(3,3),activation = 'relu')) 22 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:34/2=17*17 23 24 25 model.add(layers.Conv2D(128,(3,3),activation = 'relu')) 26 model.add(layers.MaxPooling2D((2,2))) 27 28 model.add(layers.Flatten()) 29 model.add(layers.Dense(512,activation = 'relu')) 30 model.add(layers.Dense(1,activation = 'sigmoid')) # sigmoid分类,输出是两类别 31 32 # 看一下特征图的维度如何随着每层变化 33 model.summary()
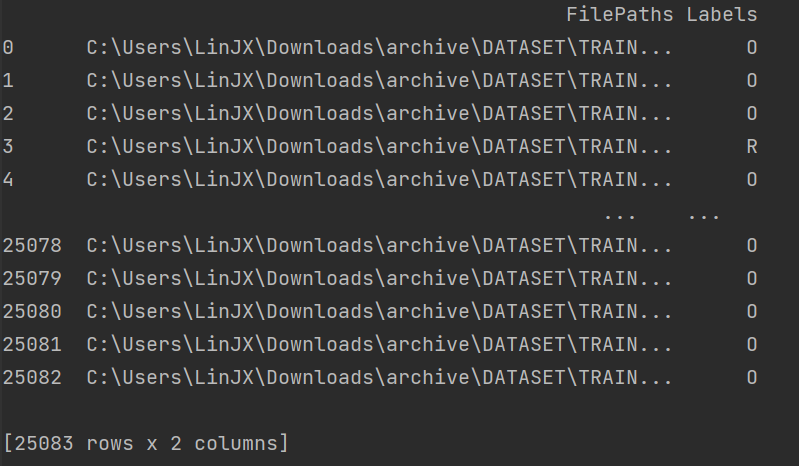
4、遍历数据集中的文件,将路径数据和标签数据生成DataFrame
1 import pandas as pd 2 import os 3 import matplotlib.pyplot as plt 4 from pathlib import Path 5 dir = Path('C:/Users/LinJX/Downloads/archive/DATASET') 6 7 # 用glob遍历在dir路径中所有jpg格式的文件,并将所有的文件名添加到filepaths列表中 8 filepaths = list(dir.glob(r'**/*.jpg')) 9 10 # 将文件中的分好的小文件名(种类名)分离并添加到labels的列表中 11 labels = list(map(lambda l: os.path.split(os.path.split(l)[0])[1], filepaths)) 12 13 # 将filepaths通过pandas转换为Series数据类型 14 filepaths = pd.Series(filepaths, name='FilePaths').astype(str) 15 16 # 将labels通过pandas转换为Series数据类型 17 labels = pd.Series(labels, name='Labels').astype(str) 18 19 # 将filepaths和Series两个Series的数据类型合成DataFrame数据类型 20 df = pd.merge(filepaths, labels, right_index=True, left_index=True) 21 df = df[df['Labels'].apply(lambda l: l[-2:] != 'GT')] 22 df = df.sample(frac=1).reset_index(drop=True) 23 # 查看形成的DataFrame的数据 24 print(df)
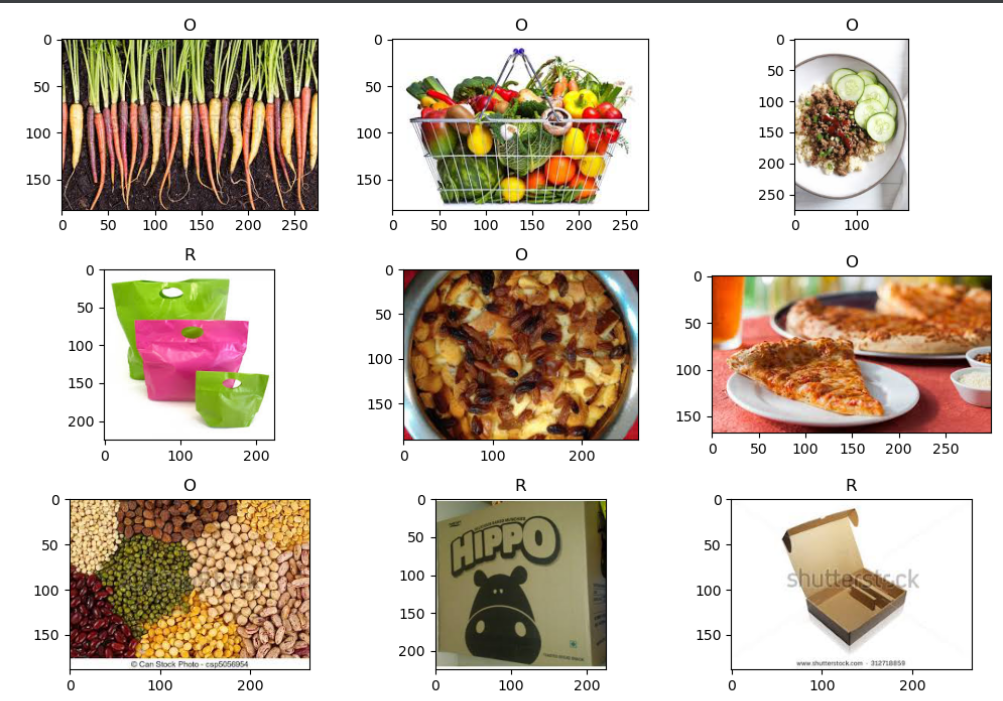
5、查看图像以及对应的标签
1 # 查看图像以及对应的标签 2 fit, ax = plt.subplots(nrows=3, ncols=3, figsize=(10, 7)) 3 4 for i, a in enumerate(ax.flat): 5 a.imshow(plt.imread(df.FilePaths[i])) 6 a.set_title(df.Labels[i]) 7 8 plt.tight_layout() 9 plt.show() 10 11 # 查看各个标签的图片张数 12 df['Labels'].value_counts(ascending=True)
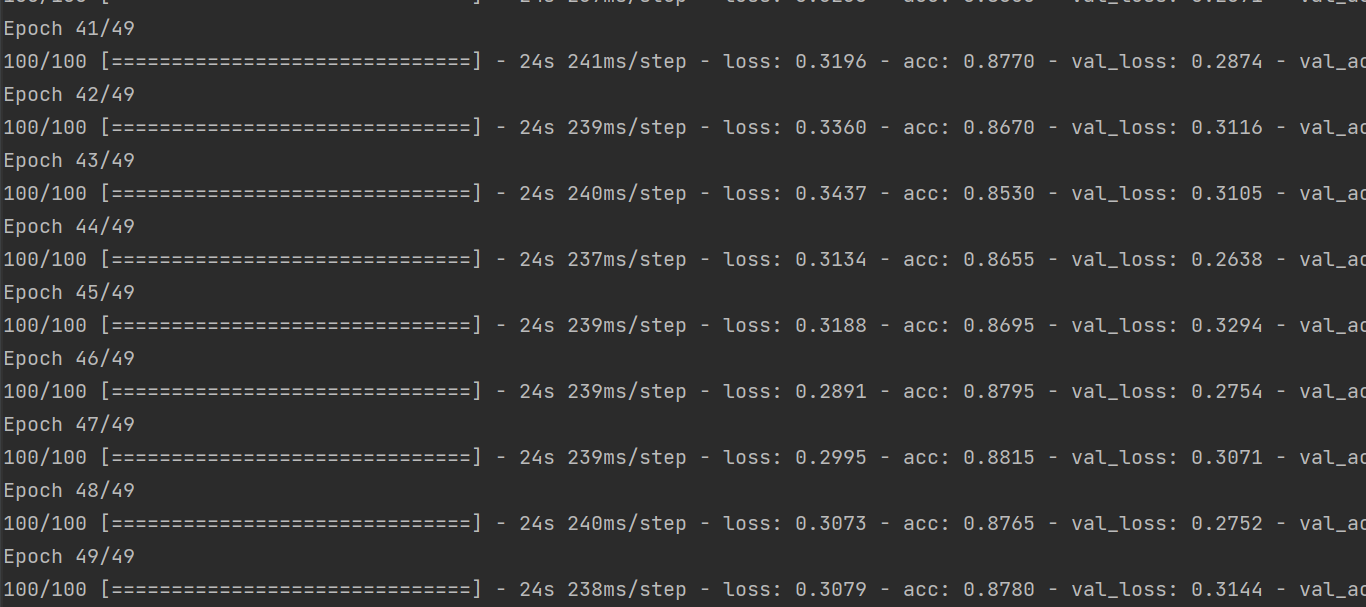
6、将训练过程产生的数据保存为h5文件
1 # 训练模型49轮次 2 history = model.fit( 3 train_generator, 4 steps_per_epoch = 100, 5 epochs = 49, 6 validation_data = validation_generator, 7 validation_steps = 50) 8 9 # 将训练过程产生的数据保存为h5文件 10 model.save('C:/Users/LinJX/Downloads/archive/DATASET/2103840249.h5')
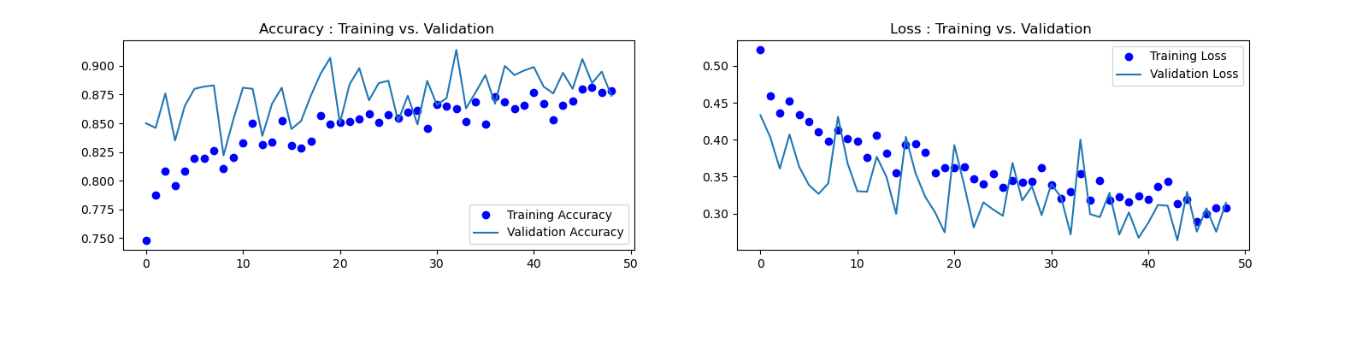
7、分别绘制训练过程中模型在训练数据和验证数据上的损失和精度
1 # 分别绘制训练过程中模型在训练数据和验证数据上的损失和精度 2 import os 3 import matplotlib.pyplot as plt 4 5 accuracy = history.history['acc'] 6 loss = history.history['loss'] 7 val_loss = history.history['val_loss'] 8 val_accuracy = history.history['val_acc'] 9 plt.figure(figsize=(17, 7)) 10 plt.subplot(2, 2, 1) 11 plt.plot(range(49), accuracy,'bo', label='Training Accuracy') 12 plt.plot(range(49), val_accuracy, label='Validation Accuracy') 13 plt.legend(loc='lower right') 14 plt.title('Accuracy : Training vs. Validation ') 15 plt.subplot(2, 2, 2) 16 plt.plot(range(49), loss,'bo' ,label='Training Loss') 17 plt.plot(range(49), val_loss, label='Validation Loss') 18 plt.title('Loss : Training vs. Validation ') 19 plt.legend(loc='upper right') 20 plt.show()
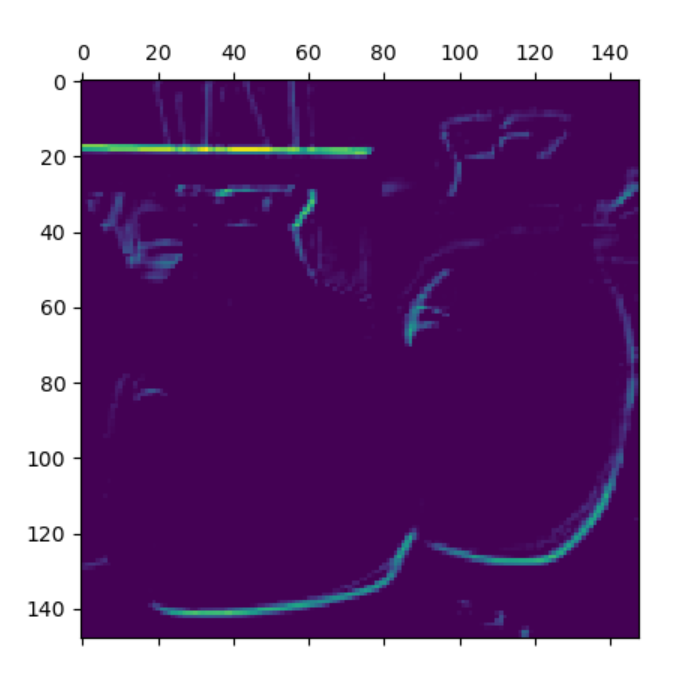
8、获取样本并输出特征图
1 # 从测试集中读取一条样本 2 img_path = "C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg" 3 4 from keras.preprocessing import image 5 import numpy as np 6 from keras.utils import image_utils 7 8 img = image_utils.load_img(img_path, target_size=(150,150)) 9 img_tensor = image_utils.img_to_array(img) 10 img_tensor = np.expand_dims(img_tensor, axis=0) 11 img_tensor /= 255. 12 print(img_tensor.shape) 13 14 # 显示样本 15 import matplotlib.pyplot as plt 16 plt.imshow(img_tensor[0]) 17 plt.show() 18 19 # 建立模型,输入为原图像,输出为原模型的前8层的激活输出的特征图 20 from keras import models 21 22 layer_outputs = [layer.output for layer in model.layers[:8]] 23 activation_model = models.Model(inputs=model.input, outputs=layer_outputs) 24 # 获得改样本的特征图 25 activations = activation_model.predict(img_tensor) 26 27 # 显示第一层激活输出特的第一个滤波器的特征图 28 import matplotlib.pyplot as plt 29 first_layer_activation = activations[0] 30 plt.matshow(first_layer_activation[0,:,:,1], cmap="viridis")

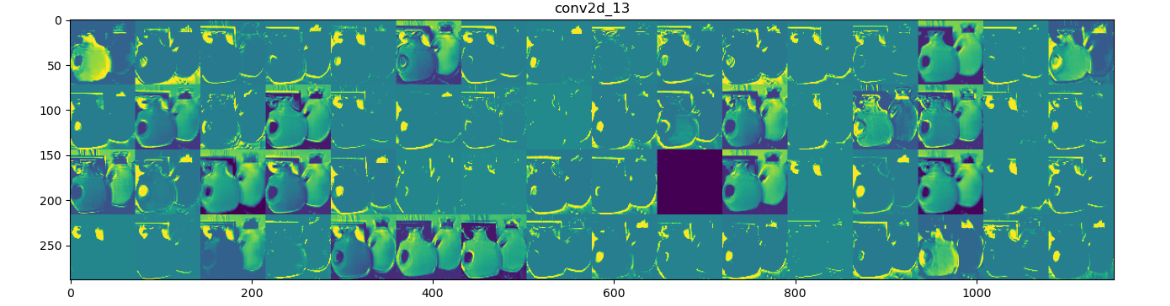
9、输出全部特征图
1 # 存储层的名称 2 layer_names = [] 3 for layer in model.layers[:4]: 4 layer_names.append(layer.name) 5 # 每行显示16个特征图 6 images_pre_row = 16 # 每行显示的特征图数 7 # 循环8次显示8层的全部特征图 8 for layer_name, layer_activation in zip(layer_names, activations): 9 n_features = layer_activation.shape[-1] # 保存当前层的特征图个数 10 size = layer_activation.shape[1] # 保存当前层特征图的宽高 11 n_col = n_features // images_pre_row # 计算当前层显示多少行 12 # 生成显示图像的矩阵 13 display_grid = np.zeros((size * n_col, images_pre_row * size)) 14 # 遍历将每个特张图的数据写入到显示图像的矩阵中 15 for col in range(n_col): 16 for row in range(images_pre_row): 17 # 保存该张特征图的矩阵(size,size,1) 18 channel_image = layer_activation[0, :, :, col * images_pre_row + row] 19 # 为使图像显示更鲜明,作一些特征处理 20 channel_image -= channel_image.mean() 21 channel_image /= channel_image.std() 22 channel_image *= 64 23 channel_image += 128 24 # 把该特征图矩阵中不在0-255的元素值修改至0-255 25 channel_image = np.clip(channel_image, 0, 255).astype("uint8") 26 # 该特征图矩阵填充至显示图像的矩阵中 27 display_grid[col * size:(col + 1) * size, row * size:(row + 1) * size] = channel_image 28 29 scale = 1. / size 30 # 设置该层显示图像的宽高 31 plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) 32 plt.title(layer_name) 33 plt.grid(False) 34 # 显示图像 35 plt.imshow(display_grid, aspect="auto", cmap="viridis") 36 37 # 读取图像样本,改变其尺寸 38 from keras.preprocessing import image 39 import numpy as np 40 41 img = image_utils.load_img(img_path, target_size=(150,150)) 42 img_tensor = image_utils.img_to_array(img) # 转换成数组 43 img_tensor = np.expand_dims(img_tensor, axis=0) 44 img_tensor /= 255. 45 print(img_tensor.shape) 46 plt.imshow(img_tensor[0]) 47 plt.show()
10、导入图像并修改保存
1 # 读取用户自定义图像文件,改尺寸后保存 2 3 import matplotlib.pyplot as plt 4 from PIL import Image 5 import os.path 6 7 def convertjpg(jpgfile, outdir, width=150, height=150): # 将图片缩小到(150,150)的大小 8 img = Image.open(jpgfile) 9 try: 10 new_img = img.resize((width, height), Image.BILINEAR) 11 new_img.save(os.path.join(outdir, os.path.basename(jpgfile))) 12 except Exception as e: 13 print(e) 14 15 jpgfile = 'C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg' # 读取原图像 16 convertjpg(jpgfile, "C:/Users/LinJX/Downloads/archive/DATASET/TEST") # 图像大小改变到(150,150) 17 18 img_scale = plt.imread('C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg') 19 plt.imshow(img_scale) # 显示改变图像大小后的图片确实变到了(150,150)大小 20 plt.show()

11、导入h5模型对图像进行测试
1 # 导入h5模型 2 from keras.models import load_model 3 model = load_model('C:/Users/LinJX/Downloads/archive/DATASET/2103840249.h5') 4 5 img_scale = img_scale.reshape(1,150,150,3).astype('float32') 6 img_scale = img_scale/255 # 归一化到0-1之间 7 8 result = model.predict(img_scale) # 取图片信息 9 # print(result) 10 if result>0.5: 11 print('该物品是可回收的概率为:',result) 12 else: 13 print('该物品是不可回收的概率为:',1-result)

全部代码附上:
1 import os 2 3 # 检查一下每个分组(训练 / 测试)中分别包含多少张图像 4 5 # 训练集 6 train_path = "C:/Users/LinJX/Downloads/archive/DATASET/TRAIN/" 7 print('训练集 可回收图片:', len(os.listdir(train_path+"R"))) 8 print('训练集 非可回收图片:', len(os.listdir(train_path+"O"))) 9 # 验证集 10 VALIDATION_path = "C:/Users/LinJX/Downloads/archive/DATASET/VALIDATION/" 11 print('验证集 可回收图片:', len(os.listdir(VALIDATION_path+"R"))) 12 print('验证集 非可回收图片:', len(os.listdir(VALIDATION_path+"O"))) 13 14 #%% 15 16 import pandas as pd 17 import os 18 import matplotlib.pyplot as plt 19 from pathlib import Path 20 dir = Path('C:/Users/LinJX/Downloads/archive/DATASET') 21 22 # 用glob遍历在dir路径中所有jpg格式的文件,并将所有的文件名添加到filepaths列表中 23 filepaths = list(dir.glob(r'**/*.jpg')) 24 25 # 将文件中的分好的小文件名(种类名)分离并添加到labels的列表中 26 labels = list(map(lambda l: os.path.split(os.path.split(l)[0])[1], filepaths)) 27 28 # 将filepaths通过pandas转换为Series数据类型 29 filepaths = pd.Series(filepaths, name='FilePaths').astype(str) 30 31 # 将labels通过pandas转换为Series数据类型 32 labels = pd.Series(labels, name='Labels').astype(str) 33 34 # 将filepaths和Series两个Series的数据类型合成DataFrame数据类型 35 df = pd.merge(filepaths, labels, right_index=True, left_index=True) 36 df = df[df['Labels'].apply(lambda l: l[-2:] != 'GT')] 37 df = df.sample(frac=1).reset_index(drop=True) 38 # 查看形成的DataFrame的数据 39 print(df) 40 41 # 查看图像以及对应的标签 42 fit, ax = plt.subplots(nrows=3, ncols=3, figsize=(10, 7)) 43 44 for i, a in enumerate(ax.flat): 45 a.imshow(plt.imread(df.FilePaths[i])) 46 a.set_title(df.Labels[i]) 47 48 plt.tight_layout() 49 plt.show() 50 51 # 查看各个标签的图片张数 52 df['Labels'].value_counts(ascending=True) 53 54 #%% 55 from keras import layers 56 from keras import models 57 58 # 搭建网络 59 model = models.Sequential() 60 # Output shape计算公式:(输入尺寸-卷积核尺寸/步长+1 61 # 对CNN模型,Param的计算方法如下: 62 # 卷积核长度*卷积核宽度*通道数+1)*卷积核个数 63 # 输出图片尺寸:150-3+1=148*148 (输入尺寸-卷积核尺寸/步长+1 64 # 第一个卷积层作为输入层,32个3*3卷积核,输入形状input_shape = (150,150,3) 65 66 # 输出图片尺寸:150-3+1=148*148,参数数量:32*3*3*3+32=896 67 model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3))) 68 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:148/2=74*74 69 70 # 输出图片尺寸:74-3+1=72*72,参数数量:64*3*3*32+64=18496 71 model.add(layers.Conv2D(64,(3,3),activation = 'relu')) 72 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:72/2=36*36 73 74 # 输出图片尺寸:36-3+1=34*34,参数数量:128*3*3*64+128=73856 75 model.add(layers.Conv2D(128,(3,3),activation = 'relu')) 76 model.add(layers.MaxPooling2D((2,2))) # 输出图片尺寸:34/2=17*17 77 78 79 model.add(layers.Conv2D(128,(3,3),activation = 'relu')) 80 model.add(layers.MaxPooling2D((2,2))) 81 82 model.add(layers.Flatten()) 83 model.add(layers.Dense(512,activation = 'relu')) 84 model.add(layers.Dense(1,activation = 'sigmoid')) # sigmoid分类,输出是两类别 85 86 # 看一下特征图的维度如何随着每层变化 87 model.summary() 88 89 #%% 90 91 # 编译模型 92 # RMSprop 优化器。因为网络最后一层是单一sigmoid单元, 93 # 所以使用二元交叉熵作为损失函数 94 from keras import optimizers 95 96 model.compile(loss='binary_crossentropy', 97 optimizer=optimizers.RMSprop(lr=1e-4), 98 metrics=['acc']) 99 100 # 归一化 101 # 图像在输入神经网络之前进行数据处理,建立训练和验证数据 102 from keras.preprocessing.image import ImageDataGenerator 103 train_datagen = ImageDataGenerator(rescale = 1./255) 104 test_datagen = ImageDataGenerator(rescale = 1./255) 105 106 train_dir = 'C:/Users/LinJX/Downloads/archive/DATASET/TRAIN/' # 指向训练集图片目录路径 107 108 109 train_generator = train_datagen.flow_from_directory( 110 train_dir, 111 target_size = (150,150), # 输入训练图像尺寸 112 batch_size = 20, 113 class_mode = 'binary') # 114 115 validation_dir = 'C:/Users/LinJX/Downloads/archive/DATASET/validation/' # 指向验证集图片目录路径 116 117 validation_generator = test_datagen.flow_from_directory( 118 validation_dir, 119 target_size = (150,150), 120 batch_size = 20, 121 class_mode = 'binary') 122 123 124 for data_batch,labels_batch in train_generator: 125 print('data batch shape:',data_batch.shape) 126 print('data batch shape:',labels_batch.shape) 127 break # 生成器不会停止,会循环生成这些批量,所以我们就循环生成一次批量 128 129 # 训练模型49轮次 130 history = model.fit( 131 train_generator, 132 steps_per_epoch = 100, 133 epochs = 49, 134 validation_data = validation_generator, 135 validation_steps = 50) 136 137 # 将训练过程产生的数据保存为h5文件 138 model.save('C:/Users/LinJX/Downloads/archive/DATASET/2103840249.h5') 139 140 # 如何打开.h5文件 141 from keras.models import load_model 142 model=load_model('C:/Users/LinJX/Downloads/archive/DATASET/2103840249.h5') 143 144 #%% 145 # 分别绘制训练过程中模型在训练数据和验证数据上的损失和精度 146 import os 147 import matplotlib.pyplot as plt 148 149 accuracy = history.history['acc'] 150 loss = history.history['loss'] 151 val_loss = history.history['val_loss'] 152 val_accuracy = history.history['val_acc'] 153 plt.figure(figsize=(17, 7)) 154 plt.subplot(2, 2, 1) 155 plt.plot(range(49), accuracy,'bo', label='Training Accuracy') 156 plt.plot(range(49), val_accuracy, label='Validation Accuracy') 157 plt.legend(loc='lower right') 158 plt.title('Accuracy : Training vs. Validation ') 159 plt.subplot(2, 2, 2) 160 plt.plot(range(49), loss,'bo' ,label='Training Loss') 161 plt.plot(range(49), val_loss, label='Validation Loss') 162 plt.title('Loss : Training vs. Validation ') 163 plt.legend(loc='upper right') 164 plt.show() 165 166 #%% 167 168 # 从测试集中读取一条样本 169 img_path = "C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg" 170 171 from keras.preprocessing import image 172 import numpy as np 173 from keras.utils import image_utils 174 175 img = image_utils.load_img(img_path, target_size=(150,150)) 176 img_tensor = image_utils.img_to_array(img) 177 img_tensor = np.expand_dims(img_tensor, axis=0) 178 img_tensor /= 255. 179 print(img_tensor.shape) 180 181 # 显示样本 182 import matplotlib.pyplot as plt 183 plt.imshow(img_tensor[0]) 184 plt.show() 185 186 # 建立模型,输入为原图像,输出为原模型的前8层的激活输出的特征图 187 from keras import models 188 189 layer_outputs = [layer.output for layer in model.layers[:8]] 190 activation_model = models.Model(inputs=model.input, outputs=layer_outputs) 191 # 获得改样本的特征图 192 activations = activation_model.predict(img_tensor) 193 194 # 显示第一层激活输出特的第一个滤波器的特征图 195 import matplotlib.pyplot as plt 196 first_layer_activation = activations[0] 197 plt.matshow(first_layer_activation[0,:,:,1], cmap="viridis") 198 199 # 存储层的名称 200 layer_names = [] 201 for layer in model.layers[:4]: 202 layer_names.append(layer.name) 203 # 每行显示16个特征图 204 images_pre_row = 16 # 每行显示的特征图数 205 # 循环8次显示8层的全部特征图 206 for layer_name, layer_activation in zip(layer_names, activations): 207 n_features = layer_activation.shape[-1] # 保存当前层的特征图个数 208 size = layer_activation.shape[1] # 保存当前层特征图的宽高 209 n_col = n_features // images_pre_row # 计算当前层显示多少行 210 # 生成显示图像的矩阵 211 display_grid = np.zeros((size * n_col, images_pre_row * size)) 212 # 遍历将每个特张图的数据写入到显示图像的矩阵中 213 for col in range(n_col): 214 for row in range(images_pre_row): 215 # 保存该张特征图的矩阵(size,size,1) 216 channel_image = layer_activation[0, :, :, col * images_pre_row + row] 217 # 为使图像显示更鲜明,作一些特征处理 218 channel_image -= channel_image.mean() 219 channel_image /= channel_image.std() 220 channel_image *= 64 221 channel_image += 128 222 # 把该特征图矩阵中不在0-255的元素值修改至0-255 223 channel_image = np.clip(channel_image, 0, 255).astype("uint8") 224 # 该特征图矩阵填充至显示图像的矩阵中 225 display_grid[col * size:(col + 1) * size, row * size:(row + 1) * size] = channel_image 226 227 scale = 1. / size 228 # 设置该层显示图像的宽高 229 plt.figure(figsize=(scale * display_grid.shape[1], scale * display_grid.shape[0])) 230 plt.title(layer_name) 231 plt.grid(False) 232 # 显示图像 233 plt.imshow(display_grid, aspect="auto", cmap="viridis") 234 235 # 读取图像样本,改变其尺寸 236 from keras.preprocessing import image 237 import numpy as np 238 239 img = image_utils.load_img(img_path, target_size=(150,150)) 240 img_tensor = image_utils.img_to_array(img) # 转换成数组 241 img_tensor = np.expand_dims(img_tensor, axis=0) 242 img_tensor /= 255. 243 print(img_tensor.shape) 244 plt.imshow(img_tensor[0]) 245 plt.show() 246 247 #%% 248 # 读取用户自定义图像文件,改尺寸后保存 249 250 import matplotlib.pyplot as plt 251 from PIL import Image 252 import os.path 253 254 def convertjpg(jpgfile, outdir, width=150, height=150): # 将图片缩小到(150,150)的大小 255 img = Image.open(jpgfile) 256 try: 257 new_img = img.resize((width, height), Image.BILINEAR) 258 new_img.save(os.path.join(outdir, os.path.basename(jpgfile))) 259 except Exception as e: 260 print(e) 261 262 jpgfile = 'C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg' # 读取原图像 263 convertjpg(jpgfile, "C:/Users/LinJX/Downloads/archive/DATASET/TEST") # 图像大小改变到(150,150) 264 265 img_scale = plt.imread('C:/Users/LinJX/Downloads/archive/DATASET/TEST/xyy.jpg') 266 plt.imshow(img_scale) # 显示改变图像大小后的图片确实变到了(150,150)大小 267 plt.show() 268 269 #%% 270 271 # 导入h5模型 272 from keras.models import load_model 273 model = load_model('C:/Users/LinJX/Downloads/archive/DATASET/2103840249.h5') 274 275 img_scale = img_scale.reshape(1,150,150,3).astype('float32') 276 img_scale = img_scale/255 # 归一化到0-1之间 277 278 result = model.predict(img_scale) # 取图片信息 279 # print(result) 280 if result>0.5: 281 print('该物品是可回收的概率为:',result) 282 else: 283 print('该物品是不可回收的概率为:',1-result)
(四)总结
1、此次python课程设计,使我对机器学习有了进一步的了解,使往期学习的知识巩固和加深,是一次“温故知新”的过程,对现有知识又获得了新的认识,并深刻感受到Python简洁却强大、简单却专业的强大魅力
2、机器学习方法是计算机利用已有的数据(经验),得出了某种模型(规律),并利用此模型预测未来(结果)的一种方法。也是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。 事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号