Java面试专题课 · 基础篇
二分查找
目标:手写代码、掌握细节
细节:
1. 避免整数溢出:L+R可能超出Integer.MAX_VALUE。
方法一:改成 L/2+R/2 → L + (R-L)/2
方法二:改成位计算(无符号右移) (L+R) >>> 1
2. 变体 (详见leetcode)
排序
目标:掌握思路,手写代码,了解特性(时间复杂度、是否稳定)
冒泡排序
(升序)每轮 依次比较相邻两个元素的大小,若a[j]>a[j+1]则交换位置,使得最大的元素排到最后
优化:
1. 减少比较次数(每轮冒泡的比较次数递减)
2. 减少冒泡次数(发现本轮没有进行交换,说明数组整个都有序了不用再排序了),
3. 进一步优化:记录每轮的最后一次进行交换的索引,来得到下轮的比较次数。若为0这说明全排完了(相当于优化2)
选择排序
(升序)每轮选择出数组后部分中最小的元素,移到数组前部分
i代表每轮选择最小元素要交换到的目标索引
选择排序vs冒泡排序

稳定:相同元素不会打乱位置
插入排序
数组开头保持为有序的。把后面的元素一个一个插入到开头的有序组中。
性质:稳定的

缺点:很大的元素位于前面的话,要移动很多次位置才能到达目标位置希尔排序
改进了插入排序。把整个数组按一定间隔分组,分别进行插入排序插入和选择—推导第n轮后的结果
快速排序
1.每一轮排序选择一个基准点(pivot)进行分区
1.让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区2.当分区完成时,基准点元素的位置就是其最终位置
2.在子分区内重复以上过程,直至子分区元素个数少于等于1,这体现的是分而治之的思想(divide-and-conquer)
快排的实现
-
单边循环快排(Lomuto):
- pivot:最右元素
- j指针负责找到比pivot小的元素,一旦找到则与i进行交换;i指针维护小于pivot的边界,即每次交换的目标索引
- 最后pivot和i交换,i即为分区位置

-
双边循环快排:
- pivot:最左元素
- j指针负责从右向左找比pivot小的元素,i指针负责从左向右找比基准点大的元素,一旦找到则两者交换,直到i、j相交
- 最后pivot和i交换,i即为分区位置
- 霍尔
快排的特点数据量特别大的时候用快排,其中分区长度比较小的时候用插排
集合—ArrayList
扩容机制
初始化:
- ArrayList() 长度为0
- ArrayList(int initialCapacity) 使用指定容量的数组
- public ArrayList(Collection<? extends E> c)使用c的大小作为容量
添加元素超出容量时会扩容。
- 添加一个元素 L.add 每次扩容成1.5倍
- 添加一个集合的全部元素 L1.addAll(L2) ① L1是空list 扩容成max(10,实际元素个数) ② L1非空 扩容成max(L1的1.5倍,实际元素个数)Iterator
遍历
-
fail-fast 遍历的同时不能修改,尽快失败
一旦发现遍历时其他人来修改,则抛异常
ArrayList用modCount记录修改次数,遍历中检查发现modCount与预期不符则说明被修改过了,终止遍历 -
fail-safe 遍历的同时可以修改,原理是读写分离
允许修改,牺牲一致性(以老数据为准)让遍历完成
CopyOnWriteArrayList用Object[] snapshot记录了快照用于遍历。添加和遍历的数组互不干扰 -
Vector是fail-fast的
LinkedList与ArrayList
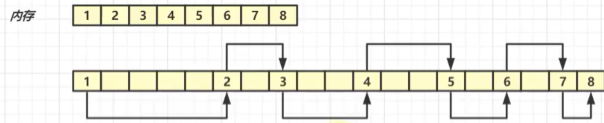
- ArrayList
- 基于数组,需要连续内存
- 随机访问快(根据下标访问,可以根据索引得到任意元素的地址)
- 尾部插入、删除性能好,其他部分插入、删除会移动数据,因此性能低
- 可以利用cpu缓存,局部性原理
- LinkedList
- 基于双向链表,无需连续内存
- 随机访问慢(要沿着链表遍历)
- 头尾插入删除性能高
- 占用内存多
HashMap
Hash可以进行快速查找。
-
1.7与1.8的不同?
1.7 数组+链表, 1.8 数组+(链表|红黑树)树化阈值是8 -
为什么要树化
很多元素的桶下标相同,链表过长且扩容无法缩短链表长度。
(正常情况下不会出现这种现象,一般是恶意行为如DoS攻击者刻意输入了很多Hash值相同的对象)
形成红黑树可以减小检索次数,解决链表性能过低的问题
hash表的查找、更新时间复杂度是O(1),红黑树的查找、更新时间复杂度是O(\(log_2(n)\)),TreeNode占用空间也比普通Node大。若非必要,尽量还是使用链表。 -
树化的条件
两个条件:链表长度>树化阈值8 ②数组容量>=64
hash值如果足够随机,则在hash表内按泊松分布。选择8是为了让树化几率足够小 -
树退化成链表的情况
情况1:在扩容时如果拆分树时,树元素<=6则会退化成链表。
情况2:remove树节点时root、root.left、root.right、root.left.left有一个为null -
索引的计算
keys→hashCode→二次hash→取余数(&容量-1)得到索引
二次hash()是为了综合高位数据,让哈希分布更均匀
以上都是为了配合2的n次幂时的优化手段,例如Hashtable的容量不是2的n次幂,并不能说哪种设计更有,应该说是综合葛总因素选择了2的n次幂作为容量 -
为什么需要二次hash
让哈希分布更均匀,防止超长链表产生

-
容量为何是2的n次幂
好处:数组容量是2的n次幂,可以使用位与运算代替取模,效率更高;扩容时hash&oldCap==0的元素留在原来位置,否则新位置=旧位置+oldCap
问题:分布性不是很均匀。选择大质数更好(扩容时容量翻倍然后找下一个质数作为新容量)
总结:2的n次幂→更高效率,大质数→更好的分布性
Put方法
- HashMap是懒惰创建数组的,首次使用才创建数组
- 计算索引(桶下标)
- 如果桶下标还没被占用,创建Node占位返回
- 如果桶下标被占用:
- TreeNode 走红黑树的添加或更新逻辑
- 普通Node 走链表的添加或更新逻辑;若链表长度超过树化阈值,走树化逻辑
- 返回前检查容量是否超过阈值,超过则进行扩容逻辑 (添加完新元素才进行扩容)
版本不同:
- 链表插入节点时,1.7是头插法,1.8是尾插法
- 新加的元素在链表头部/尾部
- 1.7在大于等于阈值且没有空位时扩容,1.8是大于阈值就扩容
- 1.8在扩容计算Node索引时会优化
扩容因子
在用了75%的容量的时候就要进行扩容。
扩容因子为何默认是0.75f?
- 在空间占用和查询时间之间取得较好的平衡
- 大于这个值:节省空间,但链表比较长,影响性能
- 小于这个值:减少冲突,但扩容更频繁,占用空间多
多线程下的HashMap
并发容易出现丢失数据的现象
问题:
- 死链 (1.7) a→b→a→...
头插法导致扩容死链 - 数据错乱 (1.7, 1.8)
key相关
- 能否为null?
HashMap的可以为null。其他Map的实现不能 - 作为key的对象有什么要求?
必须实现hashCode和equals,并且key的内容不能修改(应该不可变。否则之后用此key找不到值了)
String对象的hashCode()
每个字符\(S_i\),字符串\(S\) → \(S_0*31^{n-1}+S_1*31^{n-2}+\cdots+S_{n-1}*31^0\)
- 为什么乘31?
31代入公式具有较好的散列特性,且31*h可简化为\(32*h-h = h<<5 - h\) 方便位运算
设计模式
单例模式
一个类只有一个实例
目标:
- 五种实现方式
- JDK中哪些地方体现了单例模式
实现方式
1. 饿汉式
- 构造私有
- 静态成员变量
- 公共的静态方法
三种破坏手段及预防方式
-
反射破坏单例
reflection(Singleton1.class);通过反射创建了一个对象。一个类有两个对象,不再是单例了

-
反序列化破坏单例
实现Serializable时,serializable(Singleton1.class);反序列化造出了一个新对象。

-
Unsafe破坏单例
unsafe(Singleton1.class);目前没有预防方法
public class Singleton1 implements Serializable {
private Singelton1() {
// 防止反射破坏单例
if(INSTANCE !=null) {
throw new RuntimeException("单例对象不能重复创建");
}
System.out.println("private Singleton1()");
}
private static final Singleton1 INSTANCE = new Singleton1(); //静态成员变量
public static Singleton1 getInstance() {
return INSTANCE;
}
public static void otherMethos() {
}
// 防止反序列化破坏单例
public Object readResolve() {
return INSTANCE;
}
}
2.枚举饿汉式
- 不怕反射、反序列化破坏单例
- Unsafe可以破坏单例
// 枚举类
enum Sex {
MALE, FEMALE;
}
// 编译器最后还是会把enum编译成class。相当于
final class Sex extends Enum<Sex> {
public static final Sex MALE;
public static final Sex FEMALE;
private Sex(String name, int ordinal) {
super(name, ordinal);
}
static {
MALE = new Sex("MALE", 0);
FEMALE = new Sex("FEMALE", 1);
$VALUES = values();
}
private static final Sex[] $VALUES;
private static Sex[] $values() {
return new Sex[]{MALE, FEMALE};
}
public static Sex[] values() {
return $VALUES.clone();
}
public static Sex valueOf(String value) {
return Enum.valueof(Sex.class, value);
}
}
// 枚举饿汉式
public enum Singleton2 {
INSTANCE;
Singleton2() {
System.out.println("private Singleton2()");
}
}
3. 懒汉式
懒惰式创建:构造第一次时才会创建实例
需要考虑线程安全问题 解决:加上一个synchoronized
public class Singleton3 implements Serializable {
private Singleton3() { }
private static Singleton3 INSTANCE = null;
public static synchoronized Singleton3 getInstance() {
if(INSTANCE == null) {
INSTANCE = new Singleton3();
}
return INSTANCE;
}
}
4. DCL懒汉式
懒汉式的优化
Double Check Logic双检索:在加锁之前先判断
要加上volatile保证共享变量的可见性、有序性
new Singleton4 → Singleton4() → INSTANCE=对象
public class Singleton4 implements Serializable {
private Singleton4() { }
private static volatile Singleton4 INSTANCE = null;
public static synchoronized Singleton4 getInstance() {
if(INSTANCE == null) {
synchronized (Singleton4.class) {
if(INSTANCE == null) {
INSTANCE = new Singleton4();
}
}
}
return INSTANCE;
}
}
5. 内部类懒汉式
静态变量赋值一定是放在静态代码块中的,JVM保证了其线程安全性。
内部类既有懒汉式的特性,又保证了创建过程中的线程安全。
public class Singleton5 implements Serializable {
private Singleton5() {}
private static class Holder {
static Singleton5 INSTANCE = new Singleton5();
}
public static Singleton5 getInstance() {
return Holder.INSTANCE;
}
}
JDK中的体现
-
Runtime类:饿汉式
(System.exit 和 System.gc用到了Runtime) -
System类中的Console:双检索懒汉式单例
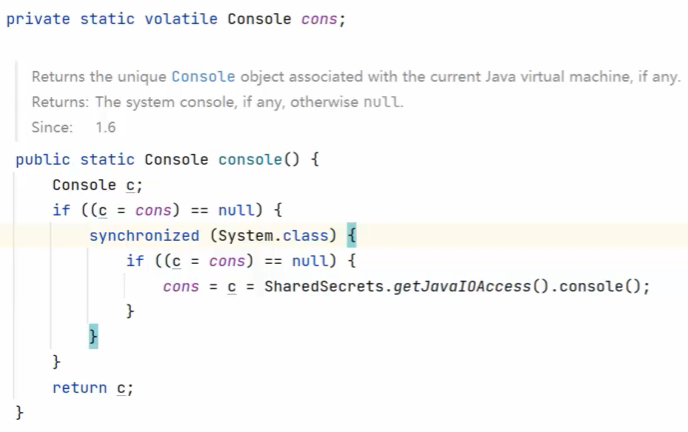
-
Collections类中:
内部类懒汉式
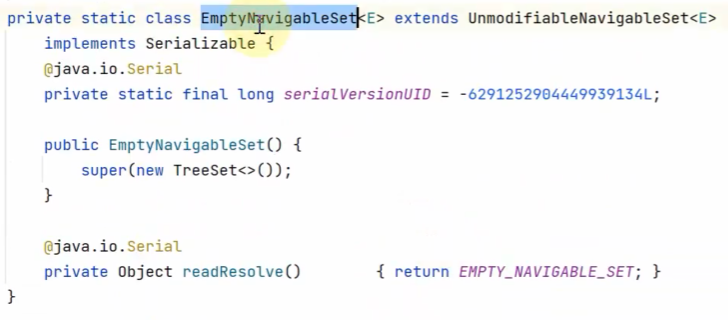
EMPTY_SET:饿汉


 浙公网安备 33010602011771号
浙公网安备 33010602011771号