

ng机器学习视频笔记(四) ——logistic回归
ng机器学习视频笔记(四)
——logistic回归
(转载请附上本文链接——linhxx)
一、概述
1、基本概念
logistic回归(logistic regression),是一个分类(classification)算法(注意不是回归算法,虽然有“回归”二字),用于处理分类问题,即结果是离散的。另外,由于有固定的结果,其是监督学习算法。
例如,预测天气、预测是否通过考试等,结果是离散的值,而预测房价这种就属于“回归”算法要解决的问题,而不是分类算法解决的问题。
2、公式
现在考虑只有两种结果情况下的logistic回归,结果只有0和1两种,即预测事件是否发生,1表示发送,0表示不发生。其h函数公式如下图所示:
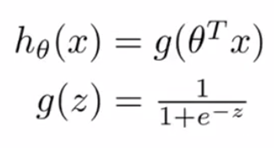
其中,g函数又层S型函数(sigmoid function)。易知g函数范围:0<=g(z)<=1。
函数图像如下:
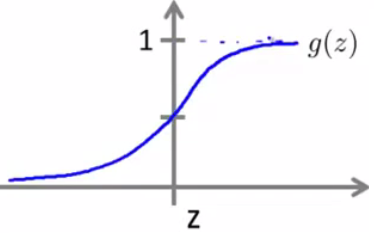
h(x)=g(z)的值,表示y=1的概率。即h(x)=p(y=1|x; θ)。y=1表示事件发生。因此h函数的结果即为事件发生的概率。
由于事件只有发生和不发生两种状态,因此,事件发生+事件不发生的概率为1,即如下公式:
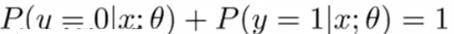
二、决策边界
决策边界(decision boundary)表示h(x)=0时的x的表达式。
由于h函数是表示事件发生的概率,但是事件只有发生和不发生两种情况,因此需要将预测计算的概率和最终的结果联系起来。由于概率在0~1分布,因此,可以认为当h(x)>=0.5时,y=1。即h(x)>=0.5时,预测事件发生。同理,h(x)<0.5时,预测结果是y=0,即事件不会发生。即,只有两个结果的情况下,一个结果发生的概率超过一半,则认为其会发生。
另外,由上面g(z)函数的图,可以知道,当z>=0时g(z)>=0.5,因此,z>=0时y=1。根据样本集的分布,决策边界可以分为线性的和非线性的。
三、代价函数
1、不能使用线性回归的代价函数公式
根据下图所示线性回归的代价函数,把h(x)用上面的1/(1+e-z)带入,求出来的结果,会是一个存在非常多极小值的函数,这样的代价函数称为非凸函数(non-convex)。

非凸函数的缺点在于,其极小值很多。根据梯度下降法,可以知道梯度下降只能求得极小值,因此对于非凸函数而言,最终得到的很可能是一个非最优化的代价函数,即预测结果可能很差,因此,需要对此公式进行变换。
2、公式

变换后的公式如上述所示。
3、公式分析
1)y=1
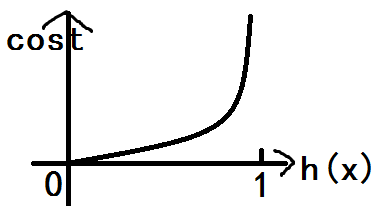
y=1时代价函数cost(h(x),y)=-log(h(x)),此时的函数图如下:
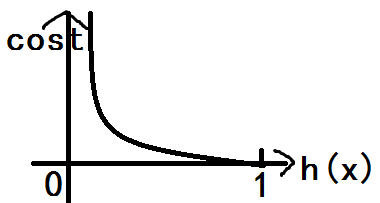
即,当y=1且预测结果h(x)=1时,代价是0;当h(x)=0时代价是正无穷大。
这个很好理解,因为事件只有发生和不发生,y=1表示真实情况下事件是发生的,此时如果预测也是发生则没有代价,如果预测是不发生则完全错误,代价非常大。由于h(x)>=0.5时结果都会当作发生,因此当h(x)<0.5时代价会陡增。
2)y=0
y=0时代价函数cost(h(x),y)=-log(1-h(x)),函数图如下:
分析过程同y=1。
4、简化代价函数
由于y只有0、1两种情况,此时代价函数可以简化,如下:
这个就是把上面的情况整合进来,把y=0、y=1带入则还是原来的式子。
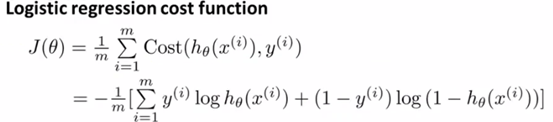
四、梯度下降算法
方式同线性回归,不断迭代下面的式子,需要注意的是,当有多个特征,要一次性计算出所有的θ,同时带入。

另外,当特征值很大时,需要考虑特征缩放。
此外,除了梯度下降算法,还可以使用共轭梯度法(conjugate gradient)、变尺度法(BFGS)、限制变尺度法(L-BFGS)等,这些算法的共同点是不需要认为的选择α、收敛速度快,但是缺点是过程非常复杂。
五、一对多分类
当分类的结果有多种,而不仅仅是事件发生和不发生,例如预测天气,有晴、阴、雨等多种情况,此时称为一对多分类 (one-vs-all、one-vs-rest)。
这种情况下,采用的方法是,把结果拆成多种,每种的事件发生是1、不发生是0。分类图如下:
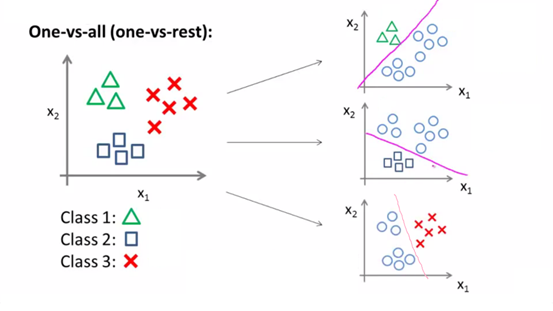
例如,预测明天的天气,把y=1、2、3(三角形、红叉、正方形)分别表示晴、阴、雨三种天气,则逐个进行预测,当预测是否晴天,y=1看作一类,y=2、3看作一类进行讨论。
其他情况类推。
此时,分别计算出h(x)=p(y=i|x; θ) (i=1,2,3)的概率,并得出最大概率是分到哪类。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号