单机安装hdfs
服务器规划
正常的Hadoop集群环境最少需要3台以上的服务器组合,而且要保持一半以上的服务器存活量。
而目前客户方只提供了一台服务器,那就只能安装伪分布式集群环境,即namenode、datanode和secondarynamenode均存放在一台机器上。
服务器信息:
地址:10.36.161.153
用户:root
JDK安装目录:/ZIP_HDFS_DATAS/jdk1.7.0_80
HDFS安装目录:/ZIP_HDFS_DATAS/hadoop-2.7.3
HDFS数据目录:/ZIP_HDFS_DATAS/hadoop-2.7.3/data
配置hosts--这步好像不是必须的
在/etc/hosts配置文件中配置服务器IP和主机名之间的映射关系;
如:10.36.161.153 hdfs iZ88rvassw1Z
其中中间的hdfs是一个伪主机名,因为hadoop对主机的命名很挑剔,不能太长或有一些特殊字符,因此在真正的主机名之前添加一个简单的、短的主机名骗一骗hadoop。
创建用户
hadoop可以以root用户安装和运行,也可以使用普通用户安装和运行。我这里使用root用户安装
本次安装没有特殊要求使用普通用户安装,则在root用户下执行。
如果需要在普通用户下安装及运行则使用如下命令创建用户和修改密码:
useradd -m vHADOOP-1
passwd vHADOOP-1
上传安装介质
通过SFTP等工具将JDK和Hadoop的安装介质上传至服务器;
本次安装使用的版本如下:
jdk-7u80-linux-x64.tar.gz
hadoop-2.7.3.tar.gz
JDK下载地址:
http://www.oracle.com/technetwork/java/javase/archive-139210.html
Hadoop下载地址(是不是很贴心?):
http://hadoop.apache.org/releases.html
安装JDK并配置环境变量
在用户根目录(如:/root/)下执行如下命令:
vi .bash_profile
添加如下内容:
export JAVA_HOME=/ZIP_HDFS_DATAS/jdk1.7.0_80
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存退出。
之后执行如下命令生效最新环境变量配置:
source .bash_profile
安装HDFS
Hadoop HDFS单机安装比较简单,解压安装介质即可完成安装。
解压命令:tar zxvf hadoop-2.7.3.tar.gz
备注:按照服务器规划章节中本次解压在/ZIP_HDFS_DATAS/hadoop-2.7.3目录。
因为数据目录和hadoop安装在同一个目录中,需要手动创建数据文件夹:
cd /ZIP_HDFS_DATAS/hadoop-2.7.3
mkdir -p data/tmp
修改HDFS配置
Hadoop的配置文件统一放置在<HADOOP_HOME>/etc/hadoop/目录下。

这里面包含了很多配置文件,跟HDFS相关的配置文件包括:
- core-site.xml
- slaves
另外还需要配置Hadoop的启动脚本,引入JDK变量:
- hadoop-env.sh
- core-site.xml
core-site.xml配置文件是对HDFS的基本配置。--如果启动的时候报错:10.200.12.187的22端口连不上 把ip改成localhost
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.200.12.187:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/middleware/hdfs/hadoop-2.10.1/data/tmp</value>
</property>
</property>

使用了默认的“fs.defaultFS”方式存储文件,其中IP为HDFS所在服务器的IP地址;
数据目录存储在指定的目录中;
- slaves
slaves指定了集群有哪些节点,目前只有一台只指向本机IP即可。
![]()
- hadoop-env.sh

配置SSH免密登录--需要处理 否则会上传失败
为避免每次启动或停止Hadoop都需要输入密码,执行如下命令进行SSH免密登录:
ssh-keygen -t rsa
一路回车即可。
格式化NameNode
就像新买的硬盘需要格式化一样,新建好的HDFS也需要对NameNode进行格式化。
目录:<HADOOP_HOME>/bin
命令:./hdfs namenode -format

一长串的日志输出后,在最后找到如下内容:

当看到“... has been successfully formatted.”字样时代表格式化成功,如果格式化错误,请详细查看输出日志。
启动HDFS
命令目录:<HADOOP_HOME>/sbin/
执行命令:./start-dfs.sh

因为配置了SSH免密登录,因此不需要再次输入密码,另外,启动过程中输出了相关角色的日志路径,如果启动时发生错误,请查阅日志内容。
如果这里报了 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).的错误。
则进行下面处理
一、创建公钥/私钥
ssh-keygen -t rsa,然后yes加一路回车
cd ~/.ssh
touch authorized_keys
chmod 600 authorized_keys
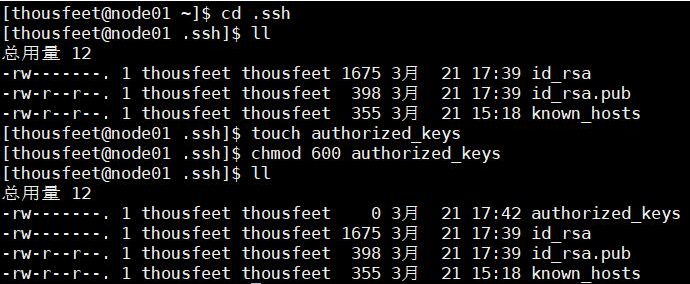
将公钥追加到authorized_keys文件中去
cat id_rsa.pub >> authorized_keys这样就可以了。可以重新启动 也可以用 ssh localhost 看是否可以
验证HDFS
启动完成后,通过执行jps命令查看所有角色的进程是否都存在。
执行命令:jps
输出结果:应当包含NameNode、DataNode、SecondaryNameNode三个进程。

访问Hadoop控制台
Hadoop提供了一个Web控制台用于查看Hadoop的管理,访问地址如下:
HDFS启停命令
HDFS服务器启停命令目录:<HADOOP_HOME>/sbin
启动HDFS:./start-dfs.sh

停止HDFS:./stop-dfs.sh

HDFS日志查看

HDFS的日志文件文件位于<Hadoop_Home>/logs/目录下;
日志文件按照不同namenode、datanode和secondarynamenode角色进行了文件区分。每种角色的日志包括了out和log结尾的文件,查看日志时请查看以log结尾的日志文件。
查看namenode日志:
tail -300f hadoop-root-namenode-iZ88rvassw1Z.log
查看datanode日志:
tail -300f hadoop-root-datanode-iZ88rvassw1Z.log
查看secondarynamenode日志:
tail -300f hadoop-root-secondarynamenode-iZ88rvassw1Z.log
HDFS基本操作
HDFS基本操作命令的目录在<HADOOP_HOME>/bin
主要通过hdfs命令进行操作;

基本语法
./hdfs dfs -命令 目录或者文件名
eg: ./hdfs dfs -ls /datas
以上命令是列出HDFS中“/datas”目录下的所有文件。
eg: ./hdfs dfs -mkdir /lhw
以上命令是创建/lhw这个文件夹。
命令说明
直接在命令行输入:./hdfs dfs即可打印命令帮助。
可以看到,对HDFS的操作和Linux环境下对文件的操作命令基本相同。

基本操作
查看目录
./hdfs dfs -ls 目录名称
上传文件
./hdfs dfs -put 本地文件路名 HDFS文件路径
下载文件
./hdfs dfs -get HDFS文件路径 本地文件路名
移动文件
./hdfs dfs -mv 原路径 目标路径
删除文件
./hdfs dfs -rm 文件路径
删除目录
./hdfs dfs -rmdir 目录路径
修改权限
./hdfs dfs -chmod 权限 文件或目录路径
参考自:https://www.cnblogs.com/xusweeter/p/8386404.html
报错处理:
File /ymall/7ca07b4cd3474dbd9fa10fe65865fc4e.jpeg could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
1.排查是否是空间不够的问题
./hadoop fs -du -h / 查看使用空间
2.关闭保护模式(我就是因为这个问题)
hadoop dfsadmin -safemode leave

 浙公网安备 33010602011771号
浙公网安备 33010602011771号