
python 数据可视化———电子商务销售分析
一、选题背景
随着互联网和移动互联网技术的不断发展,电子商务已经成为了一个全球性的发展趋势。越来越多的商家和消费者都开始使用电子商务平台进行线上交易,这在一定程度上改变了传统商业模式,并且对于消费者而言,电子商务平台也提供了更为便捷的购物体验,因此,我们将亚马逊等一部分平台的数据进行可视化及分析,这种数据可视化的分析对于电商从业者和市场研究人员来说具有重要的意义。首先,通过分析亚马逊等平台的数据,可以了解市场需求和产品趋势,从而为企业的产品研发和市场推广提供有力的支持。其次,分析亚马逊等平台的数据可以帮助企业优化销售策略和提高销售和盈利能力,比如优化产品定价、提高产品质量、改善客户服务等。此外,通过分析亚马逊等平台的数据还可以发现一些市场机会和潜在的竞争对手,为企业制定更加有效的竞争策略提供帮助。商家可以更好地理解消费者的需求和购买行为,并且根据这些数据进行产品调整和市场营销策略的优化,从而提高销售额和客户满意度。
二、数据可视化分析方案
1、研究思路:
(1)首先需要从亚马逊等平台上获取所需的数据,如销售数据、评论数据、搜索数据等。然后对这些数据进行清洗和处理,去除无用信息和异常值,将不同来源的数据进行整合和统一格式化。
(2)在清洗和处理好数据之后,需要对数据进行分析和筛选,以确定需要可视化的指标和变量。例如,可以对销售数据进行分析,确定最畅销的产品种类、最受欢迎的品牌和区域等。也可以对评论数据进行分析,确定消费者的偏好和评价等。
(3)在确定需要可视化的指标和变量之后,需要进行可视化设计和开发。这包括选择合适的图表类型、颜色和字体等,以及确定数据的呈现方式和交互方式。例如,可以使用柱状图、折线图、散点图、地图等不同类型的图表,通过颜色和字体的搭配来突出重点信息。
(4)在开发完成后,需要对可视化效果进行评估和改进。这包括对可视化结果的准确性、清晰度和易读性进行评估,以及根据用户反馈和需求进行改进和优化。
2、从网址中下载数据后,在python环境中导入pandas、missingno等第三方库进行数据处理,经过数据清洗、检查数据等,再进行数据可视化处理。
3、数据集:www.data.world.com
4、参考:刘志攀.亚马逊对于电子商务公司的启示、王艳.商家利用亚马逊平台销售商品的几种选品方法
三、数据可视化步骤
首先下载好数据集到电脑里。

步骤
(1)
1 #导入库 2 import numpy as np 3 import pandas as pd 4 5 import os 6 for dirname, _, filenames in os.walk('C:\\Users\\Lenovo\\Desktop\\python'): 7 for filename in filenames: 8 print(os.path.join(dirname, filename))

(2)
安装库
1 pip install missingno
(3)
1 #导入库 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import missingno as msno
(4)
#读取下载好的数据集
1 df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 2 df.info()

(5)
1 df.set_index('index', inplace = True) #数据处理
(6)
1 msno.matrix(df) #显示结果
这段代码使用了Missingno库,目的是生成一个缺失值矩阵图,帮助可视化中每列的分布,更具体地说,msno.matrix(df)将每列缺失值的分布情况可视化为一个矩阵图,其中每一列代表中的一列数据,而每一行代表数据的每一行观察记录。如果一个单元格是白色的,表示该单元格对应的数据是非缺失的,否则,如果该单元格是深色的,则表示该单元格对应的数据是缺失的。
##生成一个缺失值矩阵图,帮助可视化中每列缺失值的分布情况

(7)
1 msno.bar(df)
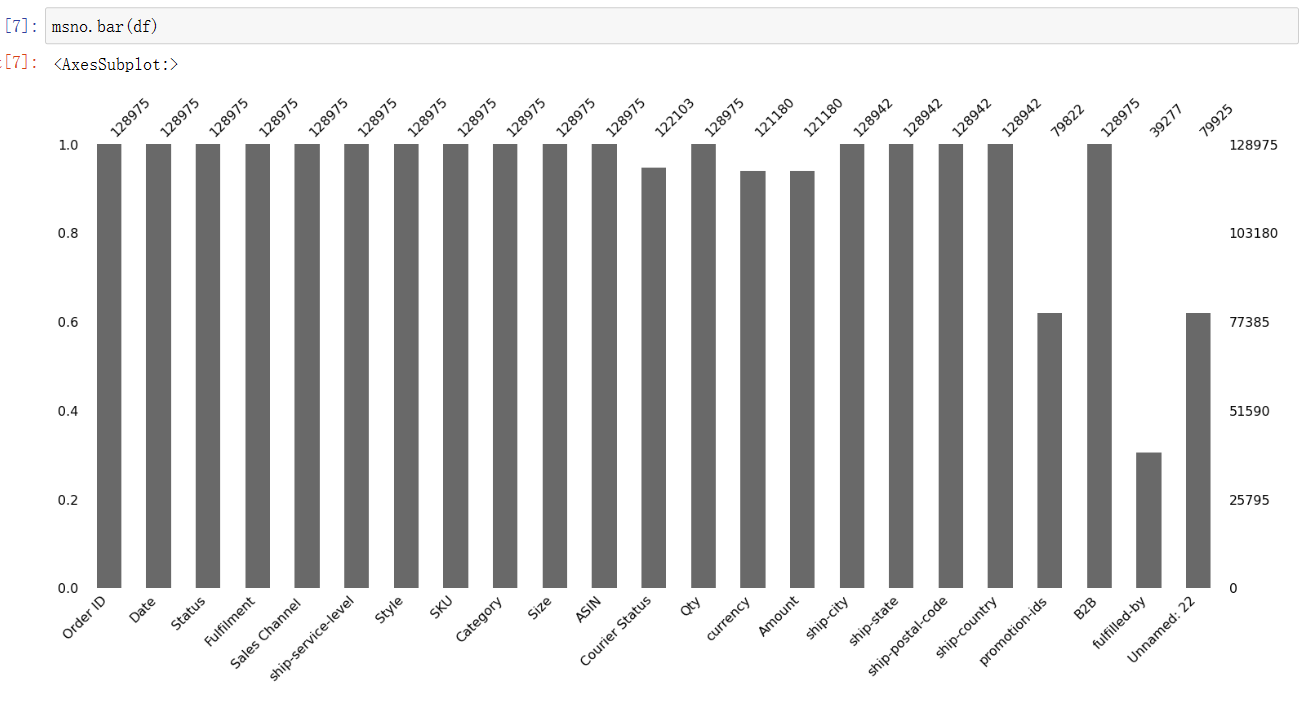
(8)
#用于获取每列的唯一值数量
1 df.nunique()

(9)
1 df.apply(pd.unique) #用于每列执行函数 pd.unique(),即获取每列的唯一值

(10)
1 l = len(df)
(11)
df.drop_duplicates(inplace = True)
(12)
1 a_l = len(df)
(13)
1 difference_len = l - a_l #数据清洗 2 3 print(f"{difference_len} rows have been removed! \n remaining rows {a_l} rows.")
#比较两个变量 l 和 a_l 的值,并输出差异的值 difference_len,以及输出一条消息,指出有多少行被删除,剩余多少行

(14)
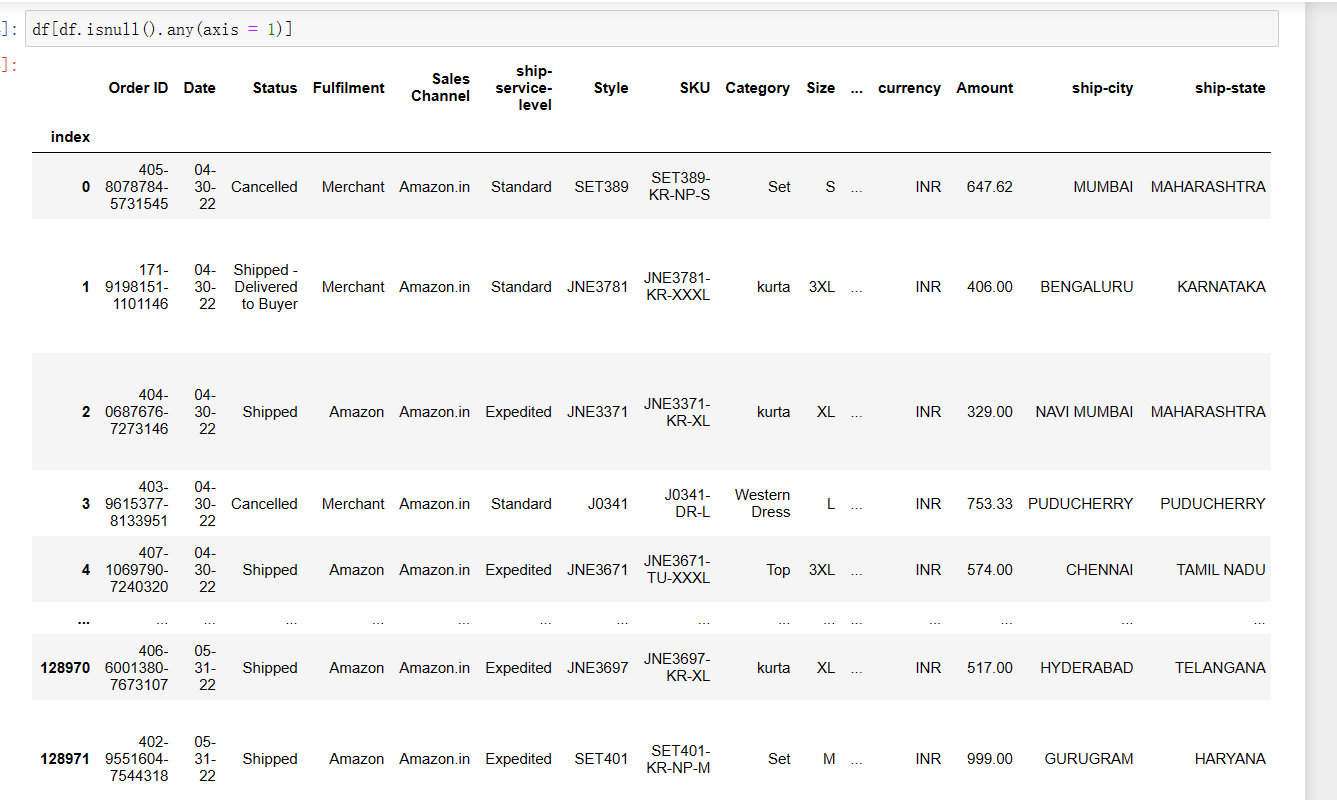
1 df[df.isnull().any(axis = 1)] #选择所有至少有一个空值的行,并将结果作为新的值返回
(15)
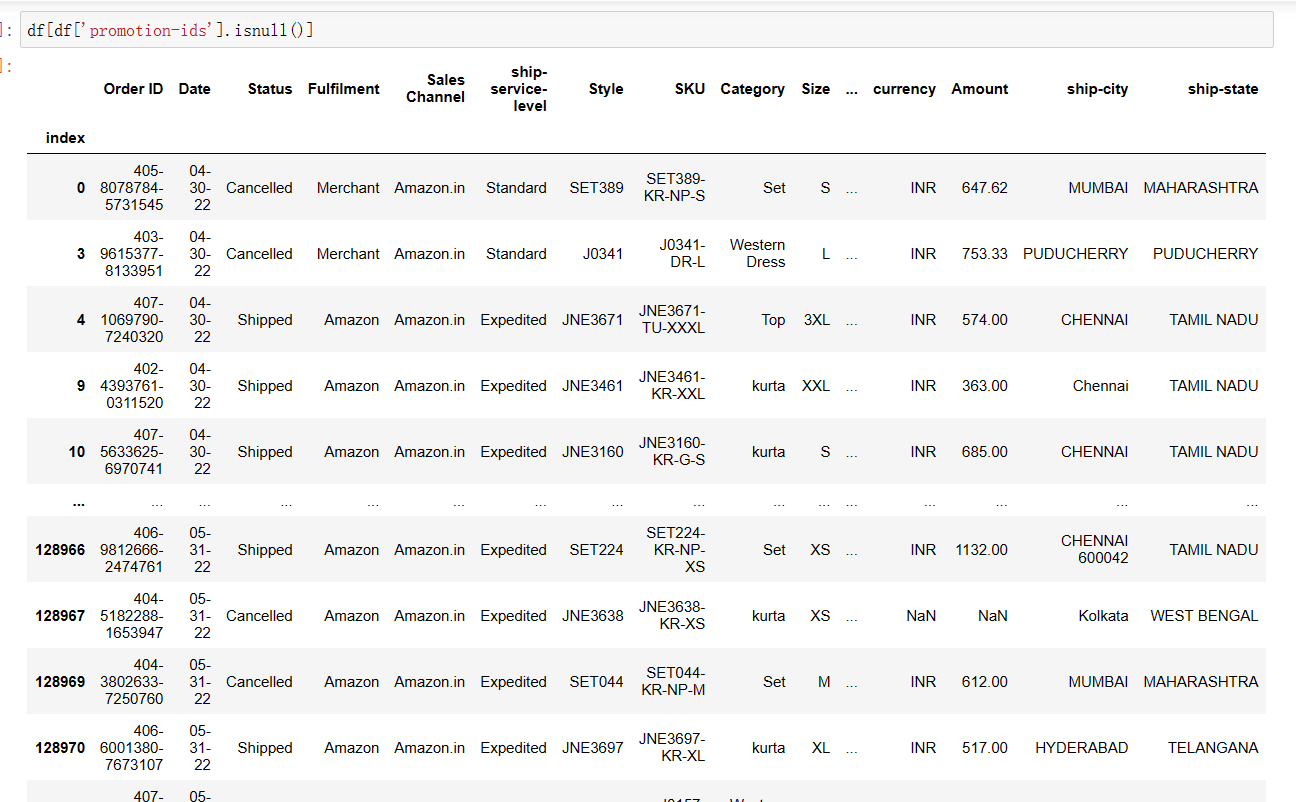
1 df[df['promotion-ids'].isnull()] #选取'promotion-ids'列为空值的行
(16)
1 df['promotion-ids'].fillna('no promotion', inplace = True)
(17)
1 df['Courier Status'].fillna('unknown', inplace = True)
(18)
1 df[df['Amount'].isnull()] #选取'Amount'列为空值的行

(19)
1 df['Amount'].fillna(0, inplace = True)
(20)
1 msno.matrix(df)

(21)
1 df.drop(columns = ['currency'], inplace = True)
(22)
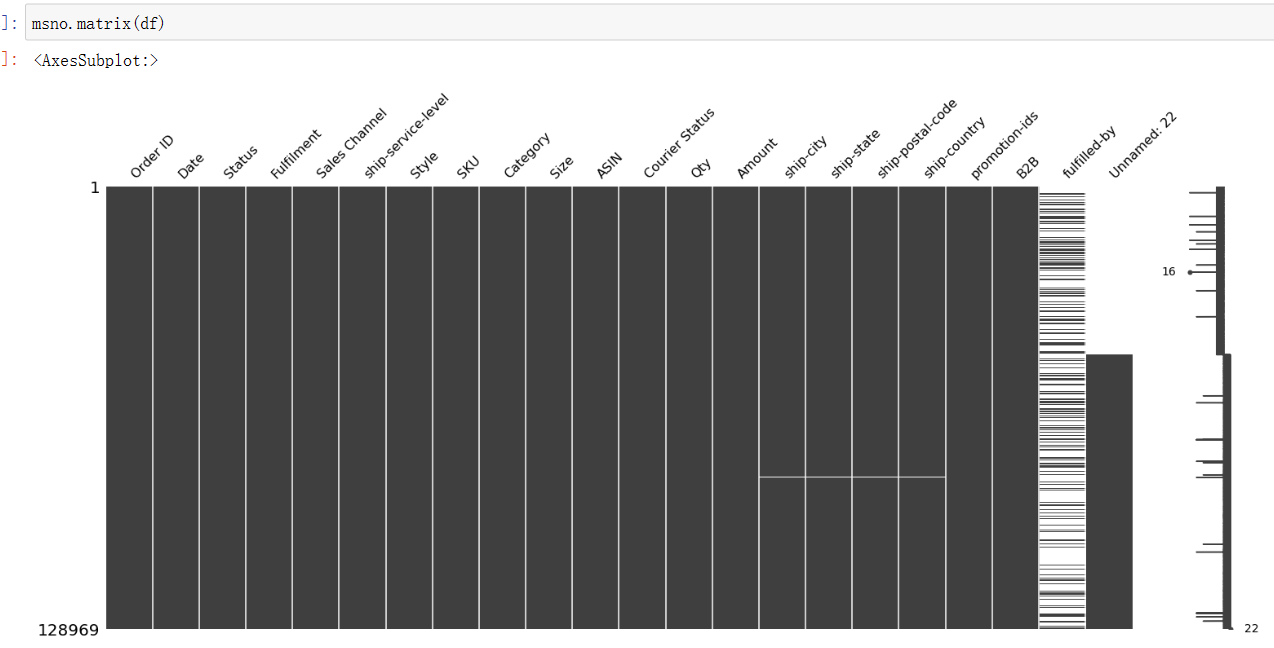
1 msno.matrix(df)
(23)
1 df.drop(columns = ['fulfilled-by'], inplace = True)
(24)
1 msno.matrix(df)

(25)
1 df.drop(columns = ['Unnamed: 22'], inplace = True)
(26)
1 msno.matrix(df)

(27)
1 df.head() #显示前五行数据

(28)
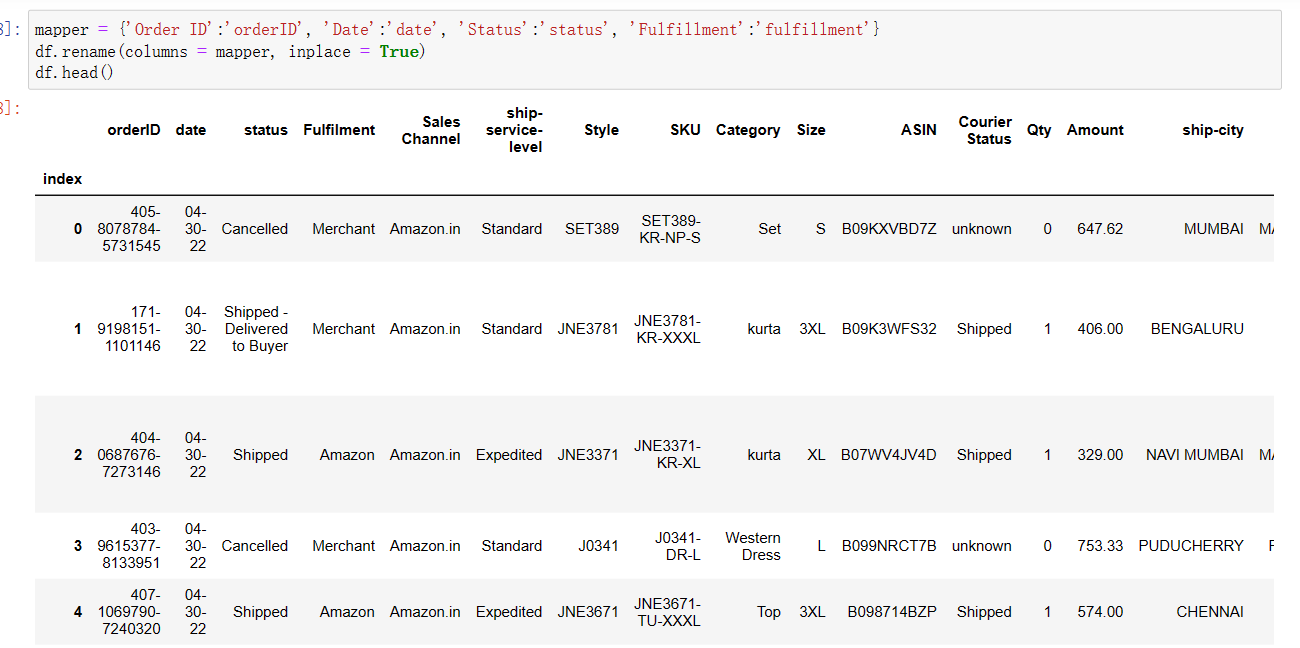
1 mapper = {'Order ID':'orderID', 'Date':'date', 'Status':'status', 'Fulfillment':'fulfillment'} #定义一个字典mapper,将四列重命名为‘orderID’、‘data’、‘status’、和‘fulfillment’ 2 df.rename(columns = mapper, inplace = True) #使用rename()方法,将列名按照定义的字典mapper进行重命名 3 df.head() #使用head()方法,返回前五行数据,显示重命名后的结果
(29)
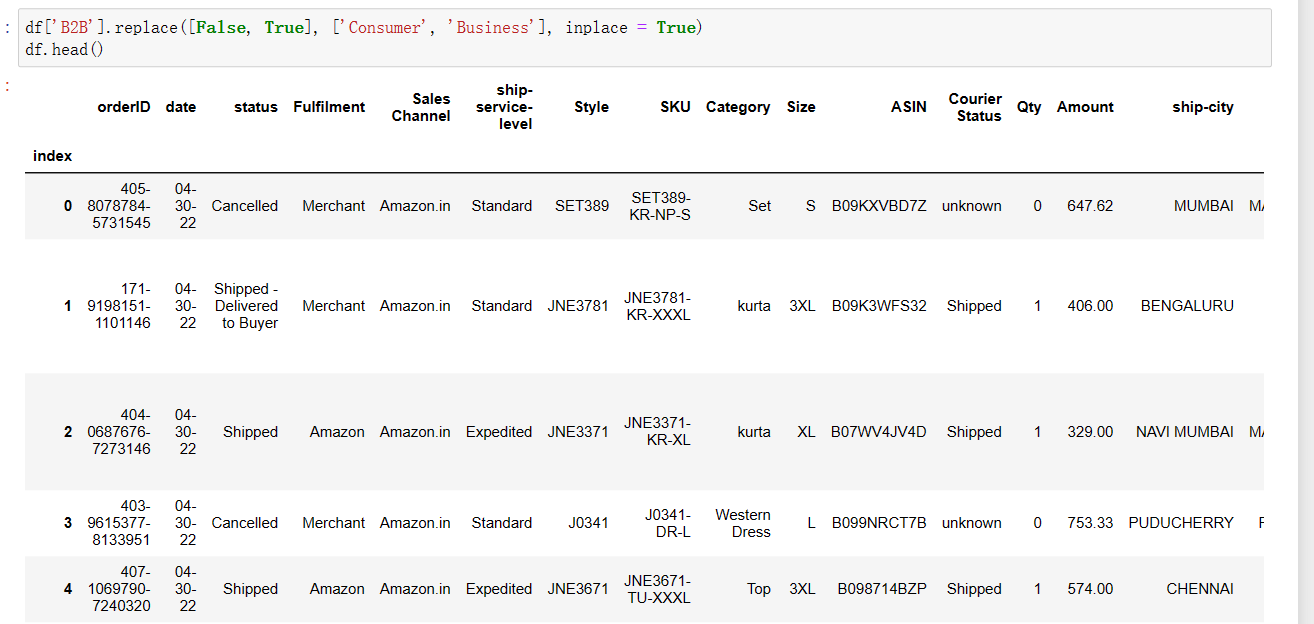
1 df['B2B'].replace([False, True], ['Consumer', 'Business'], inplace = True) #将数据中名为'B2B'的列中的False和True值替换为'Consumer'和'Business' 2 df.head() #读取前五行数据
(30)
(31)
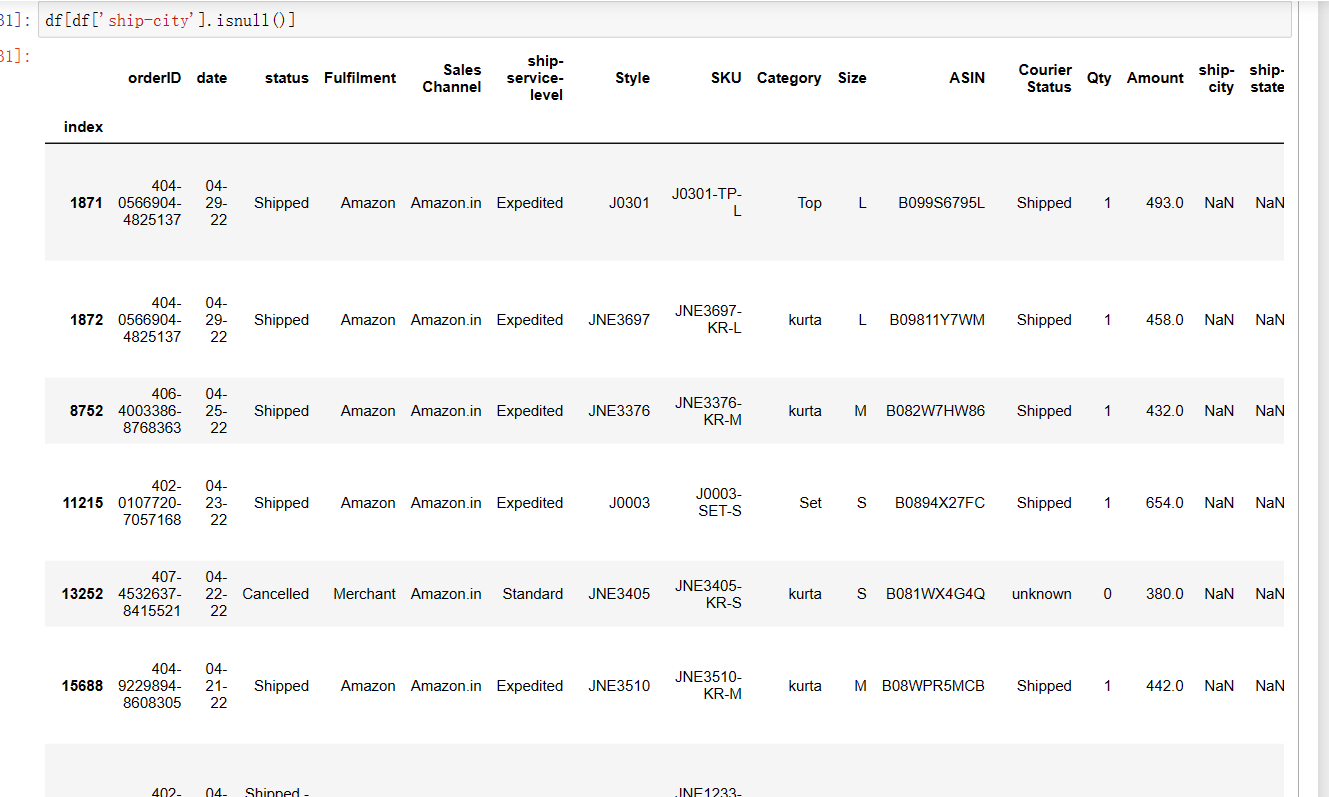
1 df[df['ship-city'].isnull()] #选取‘ship-city’为空值的行
(32)
1 df['ship-city'].fillna('unknown', inplace = True) 2 df['ship-state'].fillna('unknown', inplace = True) 3 df['ship-postal-code'].fillna('unknown', inplace = True) 4 df['ship-country'].fillna('unknown', inplace = True)
#填充缺失值
(33)
1 msno.matrix(df) #查看填充后的缺失值

(34)
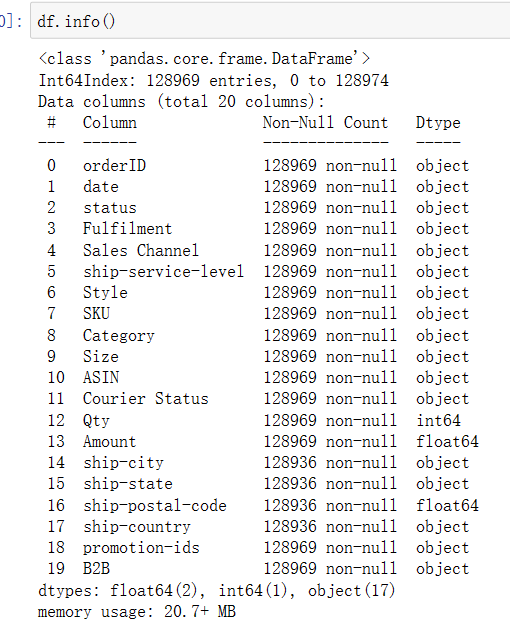
1 df.info()
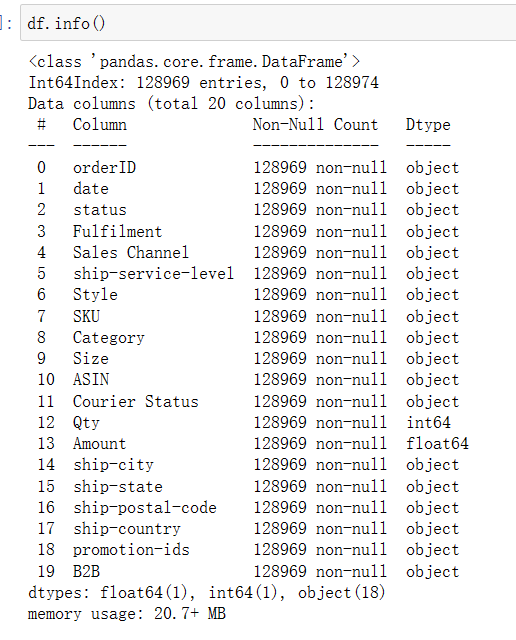
(35)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 加载数据集 5 df1 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') 6 df2 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\International sale Report.csv') 7 df3 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 8 df4 = df1 9 10 # 设置绘图网格 11 fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 15)) 12 13 # 绘制图表 14 sizes = df1['Size'].value_counts() 15 sizes['Else'] = sizes[['XXXL', '4XL', '5XL', '6XL', 'FREE']].sum() 16 sizes = sizes.drop(labels=['XXXL', '4XL', '5XL', '6XL', 'FREE']) 17 total_stock = sizes.sum() 18 sizes_percentage = sizes / total_stock * 100 19 axs[0, 0].pie(sizes, labels=sizes.index, autopct='%1.1f%%') 20 axs[0, 0].set_title('按规模划分的存量分布',fontsize=20, x=0.5, y=1.05, pad=10) 21 22 # 从 CSV 文件加载数据 23 data = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') 24 25 # 将大小映射到聚合大小 26 size_map = {'S': 'S', 'M': 'M', 'L': 'L', 'XL': 'XL', 'XXL': '2XL', 'XXXL': '3XL', '4XL': '4XL', '5XL': '5XL', '6XL': '6XL', 'FREE': 'FREE'} 27 data['AggregatedSize'] = data['Size'].map(size_map) 28 29 # 计算每个聚合大小的库存水平总和 30 data_by_aggregated_size = data.groupby('Size').sum().reset_index() 31 32 # 按库存水平降序对数据进行排序 33 data_by_aggregated_size = data_by_aggregated_size.sort_values('Stock', ascending=False) 34 35 # 突出显示前三个聚合大小 36 data_by_aggregated_size['Highlighted'] = False 37 data_by_aggregated_size.loc[0:2, 'Highlighted'] = True 38 39 # 创建条形图 40 bars = axs[0,1].bar(data_by_aggregated_size['Size'], data_by_aggregated_size['Stock']) 41 for i in range(len(bars)): 42 if i < 3: 43 bars[i].set_color('blue') 44 else: 45 bars[i].set_color('gray') 46 axs[0,1].set(xlabel='Size', ylabel='Stock') 47 axs[0,1].set_title('按规模划分的库存水平', fontsize=20, x=0.5, y=1.05, pad=10) 48 49 50 # 绘制图表 51 valid_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', 'XXXL', '4XL', '5XL', '6XL', 'FREE'] 52 df2 = df2[df2['Size'].isin(valid_sizes)] 53 df2['PCS'] = pd.to_numeric(df2['PCS'], errors='coerce') 54 size_counts = df2.groupby('Size').size().reset_index(name='count') 55 size_counts = size_counts.sort_values(by='count', ascending=False) 56 top_sizes = size_counts.head(3) 57 other_sizes_count = size_counts.iloc[3:]['count'].sum() 58 other_sizes = pd.DataFrame({'Size': ['Else'], 'count': [other_sizes_count]}) 59 top_sizes = pd.concat([top_sizes, other_sizes], ignore_index=True) 60 total_sales = df2['PCS'].sum() 61 top_sizes['percentage'] = top_sizes['count'] / total_sales * 100 62 axs[1, 0].pie(top_sizes['percentage'], labels=top_sizes['Size'], autopct='%1.1f%%', startangle=90) 63 axs[1, 0].set_title('国际销售规模分布',fontsize=20, x=0.5, y=1.05, pad=10) 64 65 # 绘制图表 66 sizes = df3['Size'] 67 allowed_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', '3XL', '4XL', '5XL', '6XL', 'FREE'] 68 sizes = sizes[sizes.isin(allowed_sizes)] 69 size_counts = sizes.value_counts() 70 total_sales = df3['Qty'].sum() 71 top_sizes = size_counts[:3].index.tolist() 72 top_sizes_count = size_counts[top_sizes].sum() 73 top_sizes_percentage = top_sizes_count / total_sales * 100 74 else_count = size_counts.drop(top_sizes).sum() 75 else_percentage = else_count / total_sales * 100 76 labels = top_sizes + ['Else'] 77 values = [top_sizes_percentage] * len(top_sizes) + [else_percentage] 78 axs[1, 1].pie(values, labels=labels, autopct='%1.1f%%') 79 axs[1, 1].set_title('亚马逊销售规模分布',fontsize=20, x=0.5, y=1.05, pad=10) 80 81 # 调整子图之间的间距 82 plt.subplots_adjust(hspace=0.4, wspace=0.4) 83 84 # 显示绘制 85 plt.show()
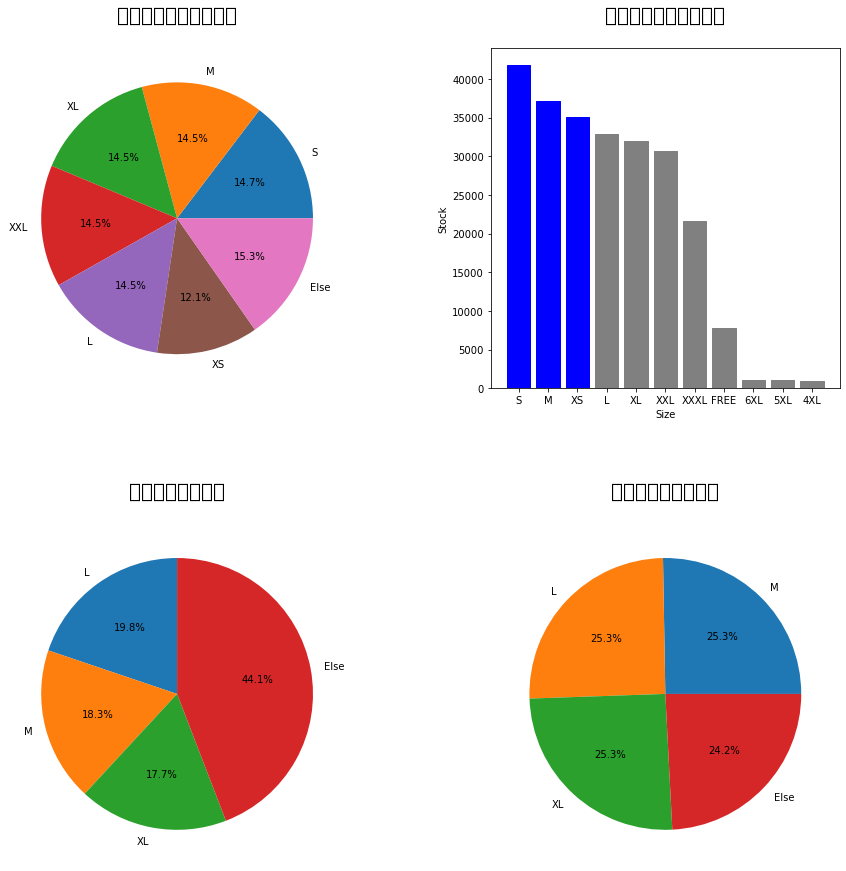
(36)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 将 CSV 文件读入pandas数据帧 5 df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 6 7 # 筛选数据框以仅包括已发货和已取消的销售 8 filtered_df = df[df['Status'].isin(['Shipped', 'Cancelled'])] 9 10 # 按状态对筛选的数据框进行分组并计算计数 11 by_status = filtered_df.groupby('Status').count()['SKU'] 12 13 # 创建一个名为“分组状态”的新列,以将所有其他状态类型分组到 “其他状态” 14 df['Grouped Status'] = df['Status'].apply(lambda x: x if x in ['Shipped', 'Cancelled'] else 'Else Status') 15 16 # 按新的“分组状态”列对原始数据帧进行分组并计算计数 17 by_grouped_status = df.groupby('Grouped Status').count()['SKU'] 18 19 # 创建包含 2 行和 2 列的图形 20 fig, axs = plt.subplots(2, 2, figsize=(15, 15)) 21 22 # 创建条形图以按配送方式显示已取消的销售 23 cancelled_df = filtered_df[filtered_df['Status'] == 'Cancelled'] 24 by_fulfilment = cancelled_df.groupby('Fulfilment').count()['SKU'] 25 axs[0, 0].bar(by_fulfilment.index, by_fulfilment.values) 26 axs[0, 0].set_title('按履行方式取消销售',fontsize=20, x=0.5, y=1.05, pad=10) 27 28 # 按产品类别对取消的销售额进行分组并计算计数 29 by_category = cancelled_df.groupby('Category').count()['SKU'] 30 31 # 按已取消销售的计数对类别进行排序 32 by_category = by_category.sort_values(ascending=False) 33 34 # 保留前 5 个类别 35 top_category = by_category[:5] 36 37 # 计算每个顶级类别的取消销售百分比 38 category_percentages = (top_category / cancelled_df.shape[0]) * 100 39 40 # 创建条形图以按前 5 个产品类别显示已取消的销售额 41 axs[0, 1].bar(top_category.index, top_category.values) 42 axs[0, 1].set_title('按产品类别划分的取消销售前五名',fontsize=20, x=0.5, y=1.05, pad=10) 43 44 # 将百分比标签添加到条形图 45 for i, v in enumerate(top_category.values): 46 axs[0, 1].text(i, v+5, f'{category_percentages.values[i]:.2f}%', ha='center') 47 48 49 50 # 创建条形图以按配送服务级别显示已取消的销售 51 by_shipping = cancelled_df.groupby('ship-service-level').count()['SKU'] 52 axs[1, 0].bar(by_shipping.index, by_shipping.values) 53 axs[1, 0].set_title('按运输服务水平划分的取消销售',fontsize=20, x=0.5, y=1.05, pad=10) 54 55 # 创建饼图以显示销售的总体状态 56 by_status = filtered_df.groupby('Status').count()['SKU'] 57 by_status['Else Status'] = df.groupby('Grouped Status').count()['SKU']['Else Status'] 58 axs[1, 1].pie(by_status.values, labels=by_status.index) 59 axs[1, 1].set_title('整体销售情况',fontsize=20, x=0.5, y=1.05, pad=10) 60 61 # 调整子图之间的间距 62 plt.subplots_adjust(hspace=0.4) 63 64 # 显示图表 65 plt.show()
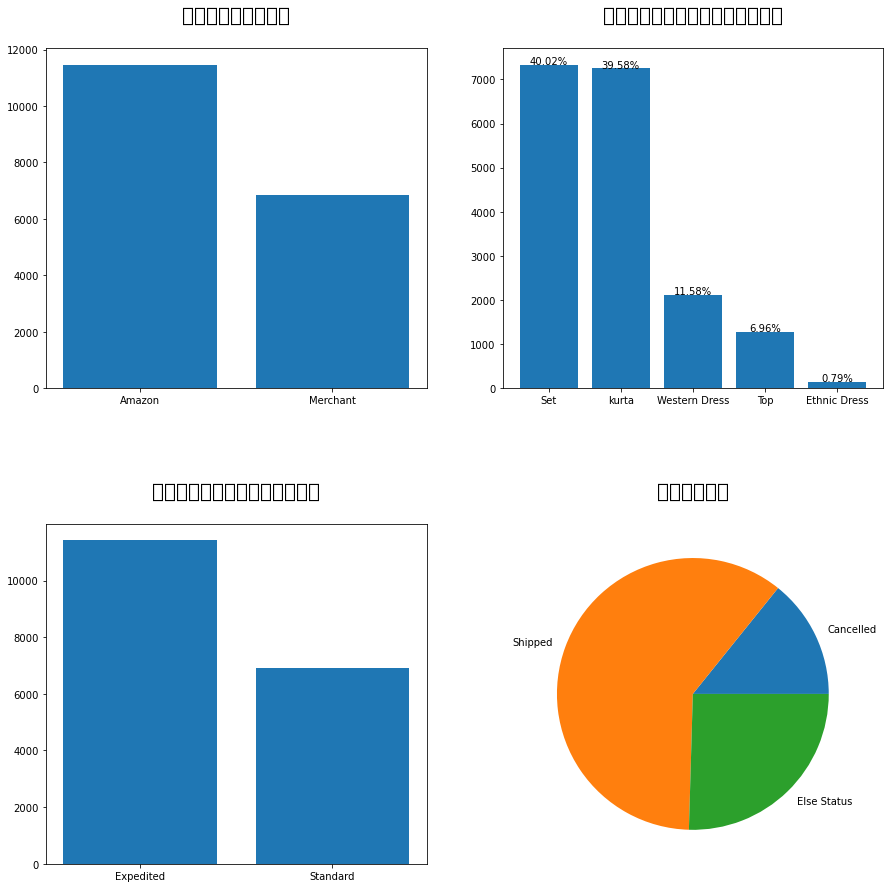
四、总结
如今电子商务的兴起对社会和经济产生了深刻的影响,它打破了传统商业模式在各方面的限制,使商家和消费者可以通过互联网直接进行交易,人们可以通过互联网购买到任何地方的商品,无需花费时间和金钱到实体店铺购买。这种商业模式的改变不仅提高了交易效率,降低了交易成本,带动了电子商务、物流、支付等相关行业的快速发展,还创造了更多的商业机会。在这次数据可视化的分析过程中我们可以看出,占比越大,销售盈利能力越强,通过产品的销量和利润等方面数据的对比,商户和消费者选择的渠道会更加丰富。
1、通过对亚马逊平台数据的分析得到的信息可用于以下几个方面:
(1)最畅销的产品种类:通过对销售数据的可视化分析,可以得出最畅销的产品种类,进而对企业的产品研发和市场推广提供支持。
(2)消费者的偏好和评价:通过对评论数据的可视化分析,可以得到消费者的偏好和评价,帮助企业优化产品和服务,提高用户满意度。
(3)市场趋势和变化:通过对搜索数据的可视化分析,可以了解市场趋势和变化,及时调整企业的销售策略和产品定位。
(4)市场机会和竞争对手:通过对销售数据和评论数据的可视化分析,可以发现市场机会和潜在的竞争对手,为企业制定更加有效的竞争策略提供帮助。
(5)地域差异和消费行为:通过对销售数据的可视化分析,可以了解不同地区的消费行为和偏好,为企业在不同地区的市场推广提供支持。
综上所述,对亚马逊等平台进行数据可视化可以得到各种有用的结论,可以帮助企业了解市场和客户需求,优化产品和服务,提高销售和盈利能力。
2、学习了数据可视化之后的感想:
学习数据可视化让我深刻认识到数据可视化的重要性和作用。通过合适的图形化展示数据,我们可以更容易地发现数据中的规律和趋势,从而做出更加准确和有意义的决策。同时,数据可视化也是沟通与传递信息的重要方式,可以帮助我们向别人更好地展示数据的含义和价值。 在学习过程中,我也意识到了数据准备的重要性。只有经过严格的数据处理和清洗,才能保证展示出来的数据准确无误。同时,选择合适的图表类型和颜色也是很重要的,可以让图表更加直观和易于理解。 最后,我也发现了数据可视化所需要的技能和工具都比较多,需要不断地学习和练习。不过,只要有耐心,通过不断地实践和反思,我相信可以逐渐提高自己的数据可视化能力。
3、不足之处:
绘制出的图表无法显示中文字符,第三方库安装不了,从CSND上找了方法也没有顺利解决。
查找到的方法:



运行出错的代码和结果:


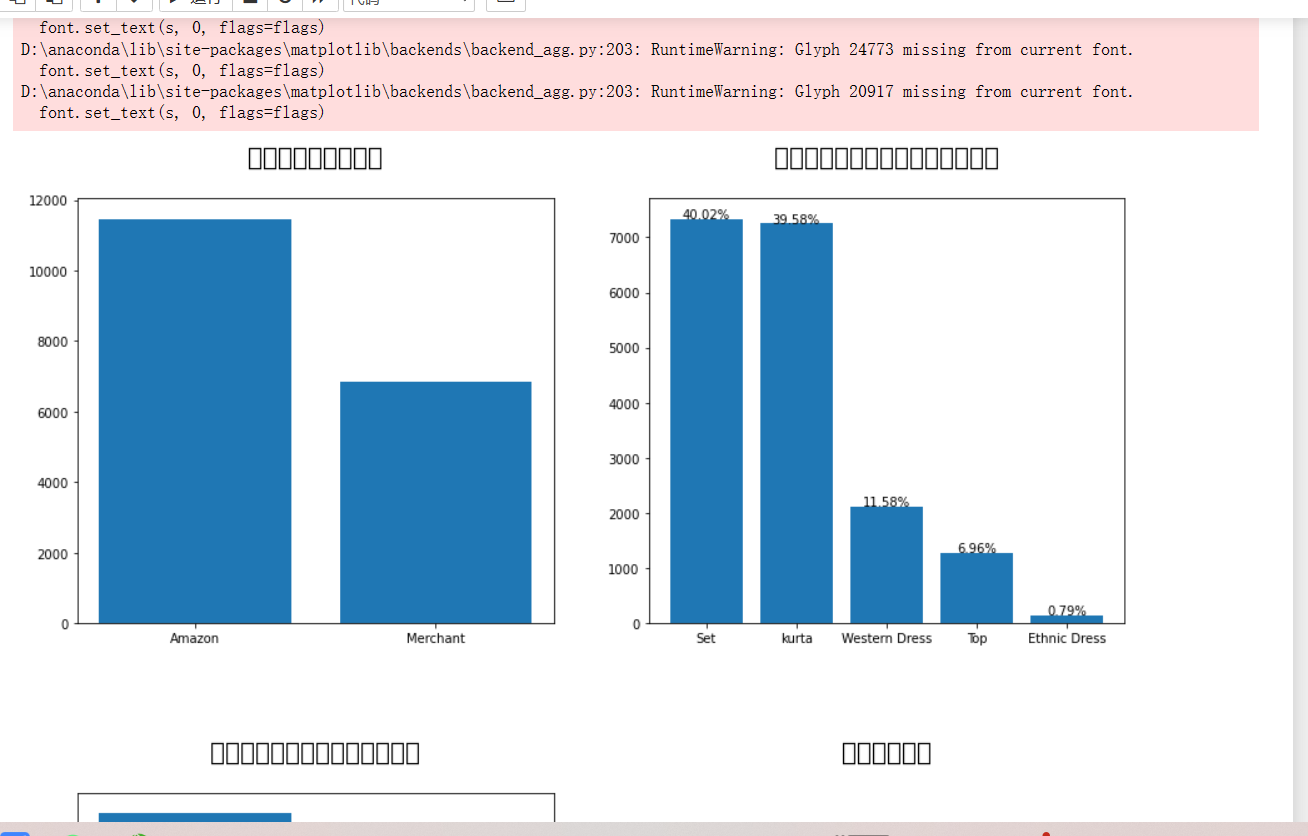
完整代码
import numpy as np import pandas as pd import os for dirname, _, filenames in os.walk('C:\\Users\\Lenovo\\Desktop\\python'): for filename in filenames: print(os.path.join(dirname, filename)) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import missingno as msno df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') df.info() df.set_index('index', inplace = True) msno.matrix(df) msno.bar(df) df.nunique() df.apply(pd.unique) l = len(df) df.drop_duplicates(inplace = True) a_l = len(df) difference_len = l - a_l print(f"{difference_len} rows have been removed! \n remaining rows {a_l} rows.") df[df.isnull().any(axis = 1)] df[df['promotion-ids'].isnull()] df['Amount'].fillna(0, inplace = True) msno.matrix(df) df.drop(columns = ['currency'], inplace = True) msno.matrix(df) df.drop(columns = ['fulfilled-by'], inplace = True) msno.matrix(df) df.drop(columns = ['Unnamed: 22'], inplace = True) msno.matrix(df) df.head() mapper = {'Order ID':'orderID', 'Date':'date', 'Status':'status', 'Fulfillment':'fulfillment'} df.rename(columns = mapper, inplace = True) df.head() df['B2B'].replace([False, True], ['Consumer', 'Business'], inplace = True) df.head() df.info() df[df['ship-city'].isnull()] df['ship-city'].fillna('unknown', inplace = True) df['ship-state'].fillna('unknown', inplace = True) df['ship-postal-code'].fillna('unknown', inplace = True) df['ship-country'].fillna('unknown', inplace = True) msno.matrix(df) df.info()
import pandas as pd import matplotlib.pyplot as plt df1 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') df2 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\International sale Report.csv') df3 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') df4 = df1 fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 15)) sizes = df1['Size'].value_counts() sizes['Else'] = sizes[['XXXL', '4XL', '5XL', '6XL', 'FREE']].sum() sizes = sizes.drop(labels=['XXXL', '4XL', '5XL', '6XL', 'FREE']) total_stock = sizes.sum() sizes_percentage = sizes / total_stock * 100 axs[0, 0].pie(sizes, labels=sizes.index, autopct='%1.1f%%') axs[0, 0].set_title('按规模划分的存量分布',fontsize=20, x=0.5, y=1.05, pad=10) data = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') size_map = {'S': 'S', 'M': 'M', 'L': 'L', 'XL': 'XL', 'XXL': '2XL', 'XXXL': '3XL', '4XL': '4XL', '5XL': '5XL', '6XL': '6XL', 'FREE': 'FREE'} data['AggregatedSize'] = data['Size'].map(size_map) data_by_aggregated_size = data.groupby('Size').sum().reset_index() data_by_aggregated_size = data_by_aggregated_size.sort_values('Stock', ascending=False) data_by_aggregated_size['Highlighted'] = False data_by_aggregated_size.loc[0:2, 'Highlighted'] = True bars = axs[0,1].bar(data_by_aggregated_size['Size'], data_by_aggregated_size['Stock']) for i in range(len(bars)): if i < 3: bars[i].set_color('blue') else: bars[i].set_color('gray') axs[0,1].set(xlabel='Size', ylabel='Stock') axs[0,1].set_title('按规模划分的库存水平', fontsize=20, x=0.5, y=1.05, pad=10) valid_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', 'XXXL', '4XL', '5XL', '6XL', 'FREE'] df2 = df2[df2['Size'].isin(valid_sizes)] df2['PCS'] = pd.to_numeric(df2['PCS'], errors='coerce') size_counts = df2.groupby('Size').size().reset_index(name='count') size_counts = size_counts.sort_values(by='count', ascending=False) top_sizes = size_counts.head(3) other_sizes_count = size_counts.iloc[3:]['count'].sum() other_sizes = pd.DataFrame({'Size': ['Else'], 'count': [other_sizes_count]}) top_sizes = pd.concat([top_sizes, other_sizes], ignore_index=True) total_sales = df2['PCS'].sum() top_sizes['percentage'] = top_sizes['count'] / total_sales * 100 axs[1, 0].pie(top_sizes['percentage'], labels=top_sizes['Size'], autopct='%1.1f%%', startangle=90) axs[1, 0].set_title('国际销售规模分布',fontsize=20, x=0.5, y=1.05, pad=10) sizes = df3['Size'] allowed_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', '3XL', '4XL', '5XL', '6XL', 'FREE'] sizes = sizes[sizes.isin(allowed_sizes)] size_counts = sizes.value_counts() total_sales = df3['Qty'].sum() top_sizes = size_counts[:3].index.tolist() top_sizes_count = size_counts[top_sizes].sum() top_sizes_percentage = top_sizes_count / total_sales * 100 else_count = size_counts.drop(top_sizes).sum() else_percentage = else_count / total_sales * 100 labels = top_sizes + ['Else'] values = [top_sizes_percentage] * len(top_sizes) + [else_percentage] axs[1, 1].pie(values, labels=labels, autopct='%1.1f%%') axs[1, 1].set_title('亚马逊销售规模分布',fontsize=20, x=0.5, y=1.05, pad=10) plt.subplots_adjust(hspace=0.4, wspace=0.4) plt.show()
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') filtered_df = df[df['Status'].isin(['Shipped', 'Cancelled'])] by_status = filtered_df.groupby('Status').count()['SKU'] df['Grouped Status'] = df['Status'].apply(lambda x: x if x in ['Shipped', 'Cancelled'] else 'Else Status') by_grouped_status = df.groupby('Grouped Status').count()['SKU'] fig, axs = plt.subplots(2, 2, figsize=(15, 15)) cancelled_df = filtered_df[filtered_df['Status'] == 'Cancelled'] by_fulfilment = cancelled_df.groupby('Fulfilment').count()['SKU'] axs[0, 0].bar(by_fulfilment.index, by_fulfilment.values) axs[0, 0].set_title('按履行方式取消销售',fontsize=20, x=0.5, y=1.05, pad=10) by_category = cancelled_df.groupby('Category').count()['SKU'] by_category = by_category.sort_values(ascending=False) top_category = by_category[:5] category_percentages = (top_category / cancelled_df.shape[0]) * 100 axs[0, 1].bar(top_category.index, top_category.values) axs[0, 1].set_title('按产品类别划分的取消销售前五名',fontsize=20, x=0.5, y=1.05, pad=10) for i, v in enumerate(top_category.values): axs[0, 1].text(i, v+5, f'{category_percentages.values[i]:.2f}%', ha='center') by_shipping = cancelled_df.groupby('ship-service-level').count()['SKU'] axs[1, 0].bar(by_shipping.index, by_shipping.values) axs[1, 0].set_title('按运输服务水平划分的取消销售',fontsize=20, x=0.5, y=1.05, pad=10) by_status = filtered_df.groupby('Status').count()['SKU'] by_status['Else Status'] = df.groupby('Grouped Status').count()['SKU']['Else Status'] axs[1, 1].pie(by_status.values, labels=by_status.index) axs[1, 1].set_title('整体销售情况',fontsize=20, x=0.5, y=1.05, pad=10) plt.subplots_adjust(hspace=0.4) plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号