第一次博客作业-答题判题程序1-3 blog-1
一、前言:
在学习面向对象程序设计的过程中,我完成了三次PTA题目集的作业,在此过程中我感受颇多。
上半学期学习C语言过程中有些错误的习惯对我学习面向对象造成了很大的影响,比如喜欢将代码全写入主函数当中,而不放入函数中分块。 各种问题的积累导致我在初见nchu-software-oop-2024-上-1中的最后一题答题判题程序-1时有些棘手,平时关于类间关系的思考和训练也比较少,因此我花了大量的时间在编写类和设计类上,尽管设计的还是不理想,但还是收获了不少。答题判题程序-1除去类设计的模块,剩下的就是对字符串的解析、各种字符串的储存等,因此它在答题判题程序这个系列中是最基础的一道题。
在第二次题目集nchu-software-oop-2024-上-2中,答题判题程序-2相较于第一次难度略有提升,同时也增加了一些要求,这些要求都使我们对类的设计,类之间的关系的理解进一步提升。如第二次题目集新增加的“#T”所对应的试卷字符串,“#S”所对应的答卷字符串,都需要我们对其进行解析并储存入对应的类中,并将这些类建立依赖或关联关系,调用从而解决问题。
第三次题目集nchu-software-oop-2024-上-3中的答题判题程序-3相较于前两次变动不大,但是加入了很多出错判断,加强了对代码的质量的要求,因此程序复杂度提高较大。并且在题目集3中,新增了学生类Student与删除信息对应的类Delete,如果对类间关系不熟,并且不能熟练应用面向对象的基本原则(尤其是单一职责原则),很容易将代码越写越乱,最后自己写的代码自己都看不懂。
二、设计与分析及踩坑心得:
以下对三次题目集的答题判题程序进行代码分析:
要求:设计实现答题程序,模拟一个小型的测试,要求输入题目信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、题目内容
一行为一道题,可以输入多行数据。
格式:"#N:"+题号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
3、答题信息
答题信息按行输入,每一行为一组答案,每组答案包含第2部分所有题目的解题答案,答案的顺序号与题目题号相对应。
格式:"#A:"+答案内容
格式约束:答案数量与第2部分题目的数量相同,答案之间以英文空格分隔。
样例:#A:2 #A:78
2是题号为1的题目的答案
78是题号为2的题目的答案答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、答题信息
一行为一道题的答题信息,根据题目的数量输出多行数据。
格式:题目内容+" ~"+答案
样例:1+1=~2
2+2= ~4
3、判题信息
判题信息为一行数据,一条答题记录每个答案的判断结果,答案的先后顺序与题目题号相对应。
格式:判题结果+" "+判题结果
格式约束:
1、判题结果输出只能是true或者false,
2、判题信息的顺序与输入答题信息中的顺序相同样例:true false true
设计分析以及踩坑心得:
在题目集1中的答题判断程序-1中,我用到了三个类。以下是对这三个类的设计分析:
1、Question类:
储存题目的题号、题目内容、标准答案等信息,并可以对这些信息进行储存和返回。
Question类中还有方法isStardard(),它可以判断答卷中的答案是否符合标准答案standardAnswer。
public boolean isStardard(){ if(this.questionThing.equals(stardardThing)){ return true; } else{ return false; }
}
2、Paper类:
用于封装试卷信息,Paper类中有题目类的对象集合——题目列表,与之相对应,Paper类中有方法saveQuestion(),它可以保存题目,并将其置于题目列表中。
Paper中还有判题方法isCorrect(),它可以判断答案answer是否符合对应题号的题目标准答案standardAnswer。
3、Answer类:
Answer类中所具有的属性:paper(试卷类的对象),[]answerList(保存每一题的答案)
Answer类中所具有的方法:判题方法isRight(),它能够判断答案列表中的结果是否符合试卷中其对应题号的题目标准答案;输出方法toStringanswer(),它能够根据题目所要求的输出格式进行答案的输出,具体的方法代码见下:
public void toStringanswer(int num){ System.out.println(paper.question2[num].getquestionThing()+"~"+answerList[num]); }
记得当时第一次接触类的设计,对于类的方法的构造还是有点困难,比如本题中的Paper类和Question类中究竟是依赖关系还是关联关系,就把我难住了有一会……在网上查找了一些资料,比如下面这个网址:关联和依赖的区别-CSDN博客,最后我才发现用关联比较合适。搞懂了这个之后,我也差不多摸清了这三个类间的关系,以下是题目集1的类图:
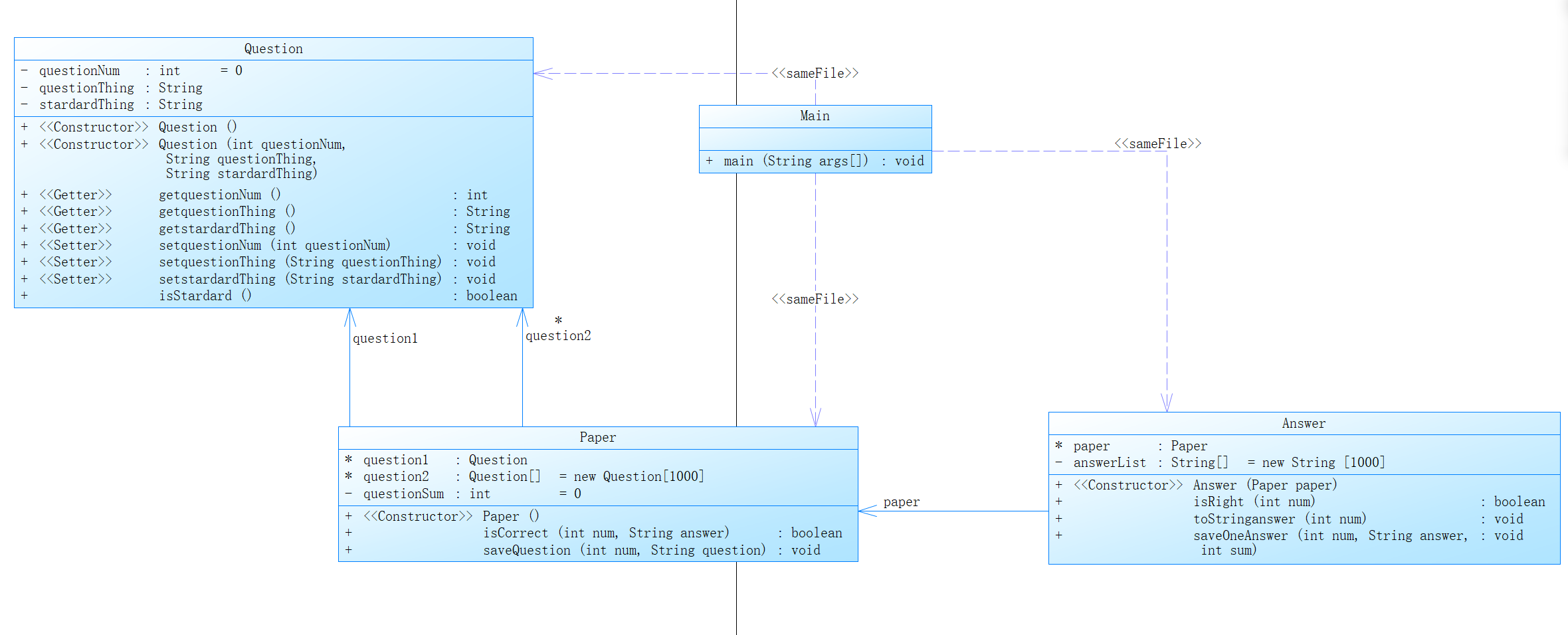
要求:输入题目信息、试卷信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分三种,三种信息可能会打乱顺序混合输入:
1、题目信息:
一行为一道题,可输入多行数据(多道题)。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
2、试卷信息:
一行为一张试卷,可输入多行数据(多张卷)。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。
样例:#T:1 3-5 4-8 5-2
3、答卷信息:
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序与试卷信息中的题目顺序相对应。
格式:"#S:"+试卷号+" "+"#A:"+答案内容
格式约束:答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案
22是1号试卷的顺序第2题的题目答案
答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示:
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+"~"+答案++"~"+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:3+2=~5~true
4+6=~22~false.
answer is null
3、判分信息:
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目计0分
2、判题信息的顺序与输入答题信息中的顺序相同
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。
4、提示错误的试卷号:
如果答案信息中试卷的编号找不到,则输出”the test paper number does not exist”,参见样例9。
设计分析以及踩坑心得:
题目集2中的答题判断程序-2相较于答题判断程序-1,增加了下面几种需求:
1.程序信息输入由一种变为三种,并且三种信息可能会打乱混合输入。
2.新增输入的试卷信息(以“#T”开头的字符串):一行为一张试卷,可输入多行数据(多张卷)。格式为:"#T:"+试卷号+" "+题目编号+"-"+题目分值。
3.新增输入的答案信息(以“#S”开头的字符串):每组答案包含某个试卷信息中的题目的解题答案,答案的顺序与试卷信息中的题目顺序相对应。格式约束:答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略。
4.新增试卷总分警示:当试卷的总分不足100分时,输出提示语句:格式为"alert: full score of test paper"+试卷号+" is not 100 points"。
5.新增提示:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null" 。
对于以上5种新增的需求,我对上次的代码进行了以下几点修改:
1.新增Grades类,由于在上次的代码中,我在Question类中标准答案的存储方式为数组,对于这道题某些测试点所存在的答案覆盖问题不能解决,因此我将标准答案建立一个新类Grades,并将其置于Grades类中进行储存和返回。
2.在Question类中我添加了新的属性questionGrades,即每道题的分数。
3.在解析并切割新增的字符串时,我在代码中添加了多种正则表达式和切割方式,之后再将信息存入对应的类中,从而实现题目,试卷,答卷等各数据的存储。
以下是题目集二的类图:
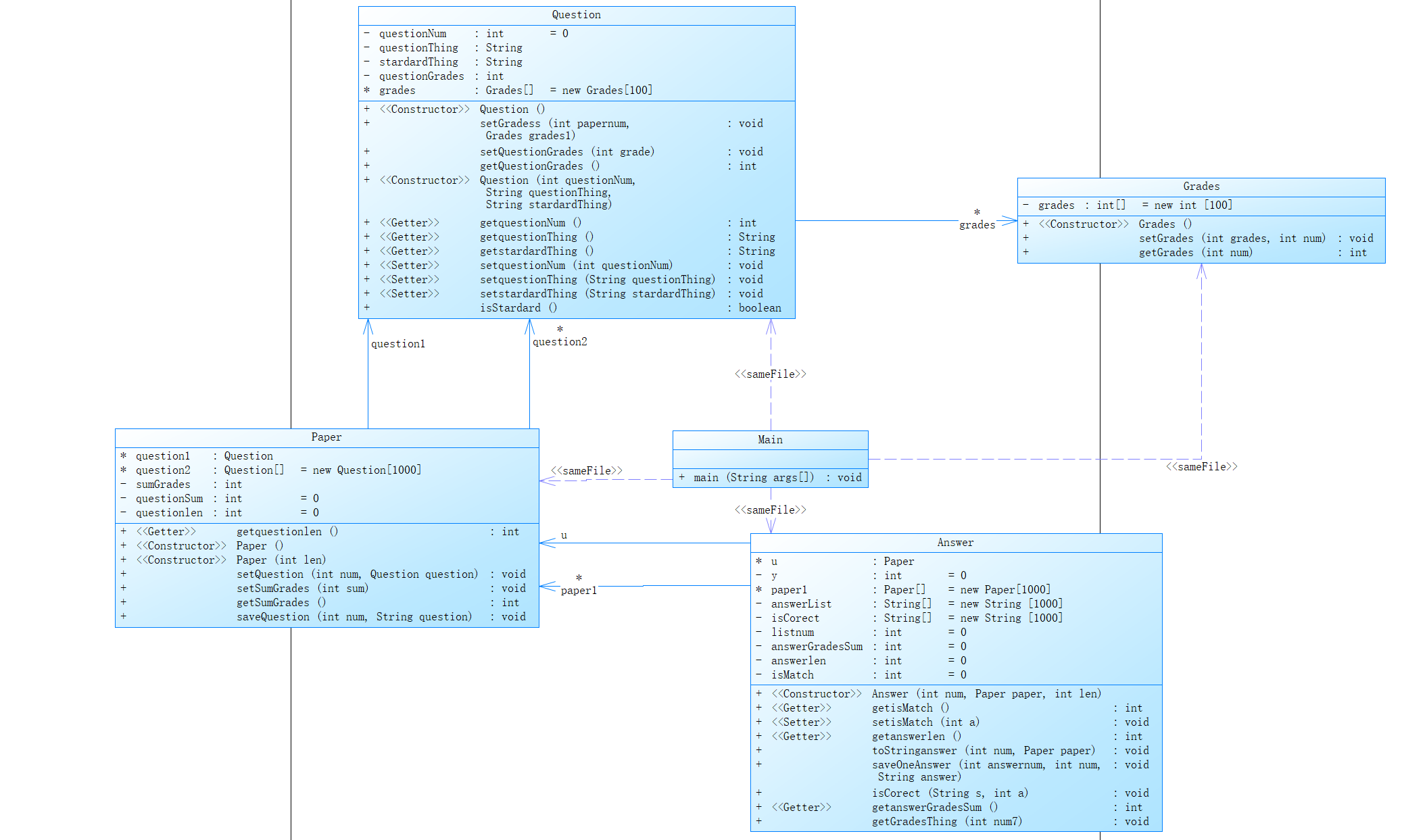
要求:输入题目信息、试卷信息、答题信息、学生信息、删除题目信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分五种,信息可能会打乱顺序混合输入。
1、题目信息
题目信息为独行输入,一行为一道题,多道题可分多行输入。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
2、试卷信息
试卷信息为独行输入,一行为一张试卷,多张卷可分多行输入数据。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值+" "+题目编号+"-"+题目分值+...
格式约束:
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。
样例:#T:1 3-5 4-8 5-2
3、学生信息
学生信息只输入一行,一行中包括所有学生的信息,每个学生的信息包括学号和姓名,格式如下。
格式:"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:
#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案
4、答卷信息
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序号与试 卷信息中的题目顺序相对应。答卷中:
格式:"#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
答案内容可以为空,即””。
答案内容中如果首尾有多余的空格,应去除后再进行判断。
样例:
#T:1 1-5 3-2 2-5 6-9 4-10 7-3
#S:1 20201103 #A:2-5 #A:6-4
1是试卷号
20201103是学号
2-5中的2是试卷中顺序号,5是试卷第2题的答案,即T中3-2的答案
6-4中的6是试卷中顺序号,4是试卷第6题的答案,即T中7-3的答案
注意:不要混淆顺序号与题号
5、删除题目信息
删除题目信息为独行输入,每一行为一条删除信息,多条删除信息可分多行输入。该信息用于删除一道题目信息,题目被删除之后,引用该题目的试卷依然有效,但被删除的题目将以0分计,同时在输出答案时,题目内容与答案改为一条失效提示,例如:”the question 2 invalid~0”
格式:"#D:N-"+题目号
格式约束:
题目号与第一项”题目信息”中的题号相对应,不是试卷中的题目顺序号。
本题暂不考虑删除的题号不存在的情况。
样例:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack
#S:1 20201103 #A:1-5 #A:2-4
#D:N-2
end
输出
alert: full score of test paper1 is not 100 points
1+1=~5~false
the question 2 invalid~0
20201103 Tom: 0 0~0
答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示:
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100 分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息:
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+"~"+答案++"~"+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:
3+2=~5~true
4+6=~22~false.
answer is null 3、判分信息
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:**学号+" "+姓名+": "**+题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目、被删除的题目、答案错误的题目计0分
2、判题信息的顺序与输入答题信息中的顺序相同
样例:20201103 Tom: 0 0~0
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。
输入:
#N:1 #Q:1+1= #A:2
#T:1 3-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-4
end
输出:
alert: full score of test paper1 is not 100 points
non-existent question~0
20201103 Tom: 0~0
如果答案输出时,一道题目同时出现答案不存在、引用错误题号、题目被删除,只提示一种信息,答案不存在的优先级最高,例如:
输入:
#N:1 #Q:1+1= #A:2
#T:1 3-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103
end
输出:
alert: full score of test paper1 is not 100 points
answer is null
20201103 Tom: 0~0
6、格式错误提示信息
输入信息只要不符合格式要求,均输出”wrong format:”+信息内容。
例如:wrong format:2 #Q:2+2= #47、试卷号引用错误提示输出
如果答卷信息中试卷的编号找不到,则输出”the test paper number does not exist”,答卷中的答案不用输出,参见样例8。
8、学号引用错误提示信息
如果答卷中的学号信息不在学生列表中,答案照常输出,判分时提示错误。参见样例9。
本题暂不考虑出现多张答卷的信息的情况。
设计分析以及踩坑心得:
本次题目集在错误格式的判断上以及程序的复杂度上难度有明显的提高,以下是题目集3增加的几种需求:
1.程序输入信息由三种变为五种,信息可能会打乱顺序混合输入。
2.新增输入的学生信息(以“#X”开头的字符串):学生信息只输入一行,一行中包括所有学生的信息,每个学生的信息包括学号和姓名,格式:格式:"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
3.答卷信息的格式有所改变,格式更改为:格式:"#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...(新增学号)
4.新增删除题目信息,删除题目信息为独行输入,每一行为一条删除信息,多条删除信息可分多行输入。该信息用于删除一道题目信息,题目被删除之后,引用该题目的试卷依然有效,但被删除的题目将以0分计,同时在输出答案时,题目内容与答案改为一条失效提示,例如:”the question 2 invalid~0”,删除信息字符串的格式为:"#D:N-"+题目号。
5.判分信息的格式有所改变,需要在姓名前面加上学生的学号。
6.新增题目引用错误提示信息:当试卷错误地引用了一道不存在题号的试题,在输出学生答案时,提示”non-existent question~”加答案。
7.新增格式错误提示信息:输入信息只要不符合格式要求,均输出”wrong format:”+信息内容。(格式要求有前两次题目集以及这次题目集新加的格式所确定)
8.新增试卷号引用错误提示输出:如果答卷信息中试卷的编号找不到,则输出”the test paper number does not exist”,答卷中的答案不用输出.
9.新增学号引用错误提示输出:如果答卷中的学号信息不在学生列表中,答案照常输出,判分时提示错误。
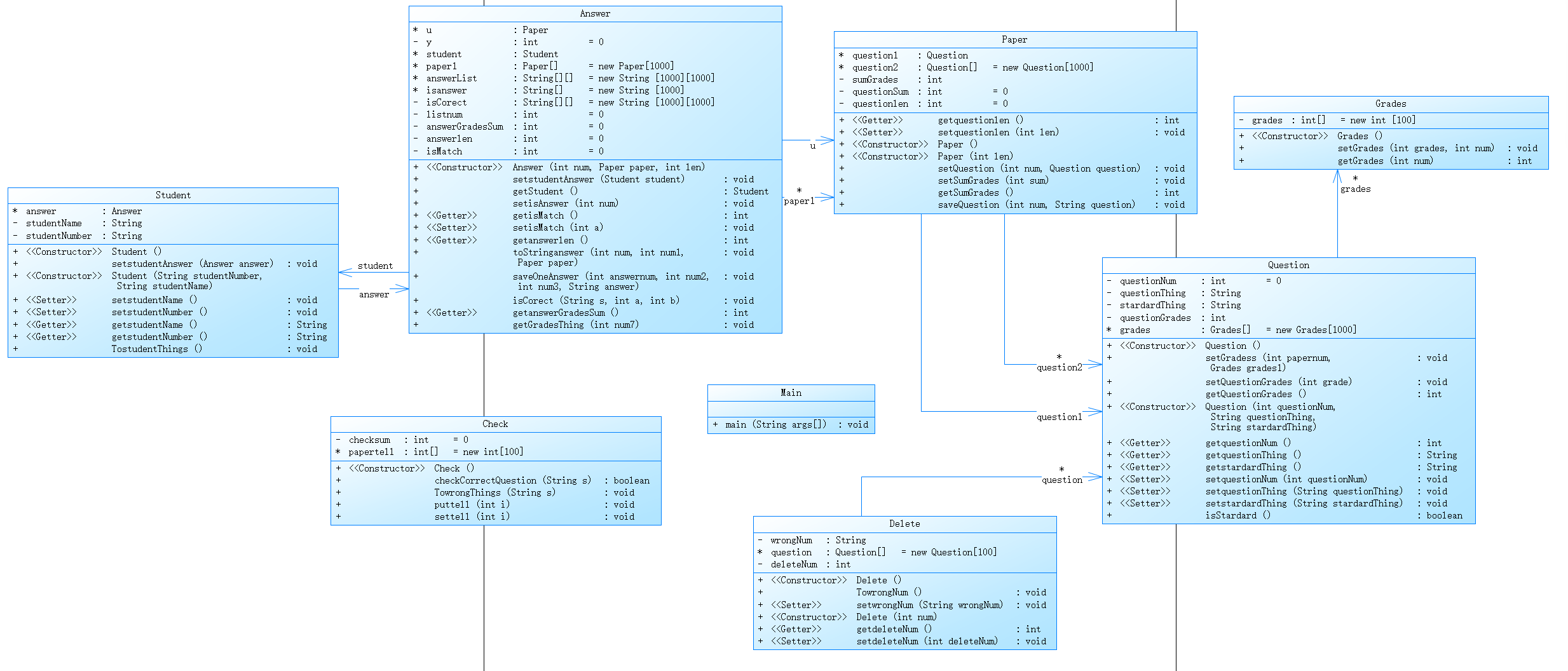
本次题目集3中最后一题的需求增加较多,所以本次代码上有较大程度的修改,以下是修改内容和实际分析:
1.由于输入的字符串类型由三种变成了五种,故本次由添加了两个字符串的正则解析方式。
2.新增Student类,用于储存和管理学生信息,代码如下:
class Student { Answer answer; private String studentName; private String studentNumber; public Student(){ } public void setstudentAnswer(Answer answer){ this.answer=answer; } public Student(String studentNumber,String studentName){ this.studentName=studentName; this.studentNumber=studentNumber; } public void setstudentName(){ this.studentName=studentName; } public void setstudentNumber(){ this.studentNumber=studentNumber; } public String getstudentName(){ return studentName; } public String getstudentNumber(){ return studentNumber; } public void TostudentThings(){ System.out.print(studentNumber+" "+studentName+": "); } }
在Student类中,添加属性学生的姓名与学生的学号(基本需求),并在属性中添加answer类进行关联,目的是便于将学生和学生的答卷进行绑定。
Student类中具有基本的get/set方法,其中方法TostudentThings()的作用是输出学生信息。
3.由于增加了删除信息的需求,故新增Delete类,用于进行删除操作等方面的管理。记得刚写到这里的时候,看错了题目信息,纠结了很久类的删除问题,再仔细读题才发现只需将被删除的题目分数以0分计即可。
4.本道题比较棘手的还是错误格式的判断问题,刚看题时一头雾水,仔细思考了一下,这不还是考正则表达式的匹配吗,只是这次的正则表达式相对复杂。因此我又添加了一个类Check下面是类中的具体内容:
class Check { private int checksum=0; int []papertell=new int[100]; public Check(){ } public boolean checkCorrectQuestion(String s){ String check1=new String(); String check2=new String(); String check3=new String(); String check4=new String(); String check5=new String(); check1="#N:\\s*(\\d+)\\s*#Q:\\s*(.*?)\\s*#A:\\s*(.*?)\\s*"; check2="^#T:( )*\\d+( )*((\\d+(( )*)-(( )*)\\d+( )*)+)$"; check3="^#X:\\s*\\w+\\s(\\w+)+(?:-\\d+\\s\\w+)*$"; check4="^#S:( )*\\d+( )*\\w+\\s*(.*?)$"; check5="^#D:\\s*N\\s*-\\s*\\d+( )*$"; if(s.matches(check1)){ return true; } if(s.matches(check2)){ return true; } if(s.matches(check3)){ return true; } if(s.matches(check4)){ return true; } if(s.matches(check5)){ return true; } return false; } public void TowrongThings(String s){ System.out.println("wrong format:"+s); } public void puttell(int i){ System.out.println("alert: full score of test paper"+i+" is not 100 points"); } public void settell(int i){ papertell[i]=i; } }
其中,Check类是对错误信息的管理,包括对错误信息的判断,错误信息的存储和输出。check1-check5是对五种不同字符串的判断格式的正则表达式。
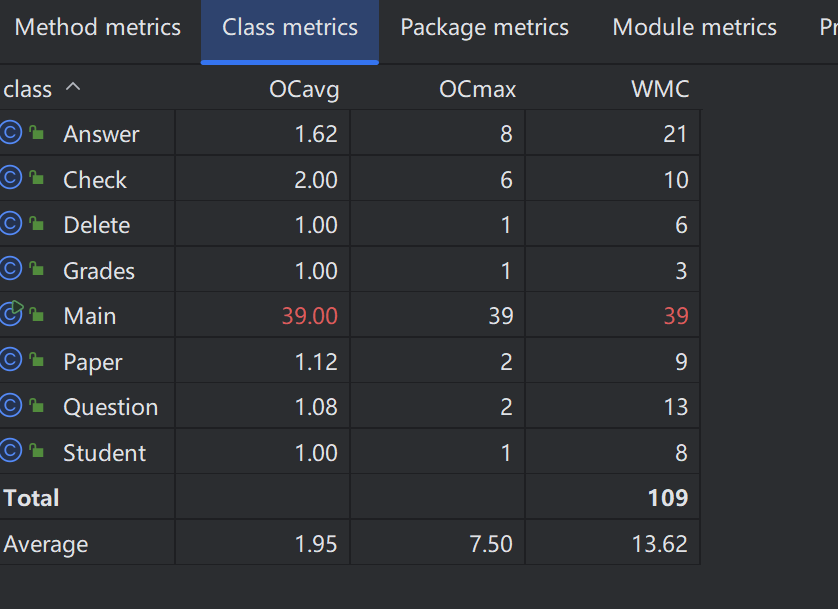
从代码中类的复杂度可得,代码中的Main类复杂度非常大,原因是我在main类中加入了对字符串的切割和解析,从而使我代码的平均复杂度也大大增加。因此,这也是我在之后类设计与代码改进的一个重要方向。
三、改进建议:
在完成了这三次题目集之后,我花了大概一个小时的时间回顾了从题目集1到题目集3学习的收获历程,也正是因为这次反思,我才发现我提交的三次代码还有巨大的改进空间……
1.代码规范性方面:虽然段老师在发布这三次题目集之前专门花了半节课带我们了解了阿里的编码规范,这在我的代码上也有所体现,但是有些变量的命名还是用“英文单词+数字”完成,如check1(有些是当时不清楚单词怎么拼写,偷懒没有查百度,为了图快就直接写在代码里了),这个编码规范的问题我也会在接下来的题目集里尽量落实。
2.类的设计方面:这一块可能就是目前我的代码(尤其是第三次)所存在的最大的问题。就比如下面这段代码:
if(s[i].startsWith("#N")){ String []ti=s[i].split(":"); ti[1]=ti[1].replaceAll(" ",""); ti[1]=ti[1].replaceAll("#Q",""); int num2=Integer.parseInt(ti[1]); ti[2]=ti[2].replaceAll("^\\s+",""); ti[2]=ti[2].replaceAll("#A",""); ti[2]=ti[2].replaceAll("\\s$",""); if(delete[num2].getdeleteNum()==num2){ delete[num2].setdeleteNum(0); question[num2].setquestionThing(ti[2]); question[num2].setstardardThing(ti[3]); }else{ if(ti.length==3){ question[num2]=new Question(num2,ti[2],""); } else{ ti[3]=ti[3].replaceAll("^\\s+",""); ti[3]=ti[3].replaceAll("\\s+$",""); question[num2]=new Question(num2,ti[2],ti[3]); } } judgeQuestion[num2]=1; }
这段代码乍一看也没什么,不就是一段切割以“#N”开头的字符串的过程吗。但是,这段字符串是出现在我的main主类中的,它不应该在这。它应该在单独的一个类中,不能在Question类,Paper类等其他实体类中,如果在,就严重违背了面向对象程序设计的单一职责原则,这些点都是应该在我写代码前应该考虑到的,这也体现了我的代码存在巨大的缺陷和改进空间。
3.数据储存的选择方面:在存入题目字符串蕴含的数据时,我从第一次题目集开始就毫不犹豫的选择了在c语言学习过程中经常打交道的数组。当然,在前几次题目集中,数组的运用还算比较轻松,但随着题目的迭代,如果要在数据中插入新数据,在数据中“挪动”或删除数据,数组的使用吃力程度指数级增长……而在完成题目集的过程中,我观察到许多同学都用了链表储存数据,这也是我的代码的重要改进方向。
四、总结:
这三次题目集是我第一次面向对象的阶段性训练,这三次题目集的总结其实前面已经讲了一些,总的来说收获最大的有几个方面,对正则表达式的应用,类间关系的判断,依赖、关联关系的具体使用等,收获这些知识的同时我也查阅了很多资料,在写程序时经常浏览下面几个网址:Java LinkedList | 菜鸟教程 (runoob.com)、Java常用正则表达式整理_java 正则表达式 空格-CSDN博客等。在得分,训练的同时,我有很多时刻都惊叹于Java类设计的妙处,听老师讲面向对象七大基本原则,只是把原则里的文字记在了脑袋里,而当我经过不断地训练(如实验的大象进冰箱,上课讲的雨刷系统等经典案例),我才慢慢领悟了这些原则的实用性和正确性。
而对于线上线下课堂的改进方面,我认为上课过程中和学生的互动是很有必要的,对于一些抽象难懂的知识,如果通过简单代码例子的方式实现,我们可能理解得更快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号