

软工第三次作业--结对作业
廖永祺 3123004617
谭钧灏 3123004628
GitHub项目地址:https://github.com/LiaoYongQi6948/calculation.git
| 这个作业属于哪个课程 | <班级的链接> |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13470 |
| 这个作业的目标 | 熟悉小组合作的形式并在该形式中思考团队完成开发任务时需考虑的具体细节 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 45 | 30 |
| Development | 开发 | 685 | 825 |
| · Analysis | · 需求分析(包括学习新技术) | 60 | 75 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 60 | 70 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 25 | 20 |
| · Coding | · 具体编码 | 300 | 320 |
| · Code Review | · 代码复审 | 60 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 80 | 90 |
| · Test Report | · 测试报告 | 40 | 45 |
| · Size Measurement | · 计算工作量 | 20 | 35 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 20 | 10 |
效能分析和优化建议
函数性能消耗较多的函数如下:
| 序号 | 函数名 |
|---|---|
| 1 | AnswerValidator(答案验证模块) |
| 2 | ExpressionGenerator(表达式生成模块) |
| 3 | Fraction(分数运算模块) |
| 4 | FileHandler(文件操作模块) |
AnswerValidator(答案验证模块)
核心功能:
解析题目表达式、验证答案正确性。
性能表现:
时间复杂度:单题解析为 (O(n))((n) 为表达式长度),但递归处理括号和字符串操作可能导致实际耗时增加。
瓶颈点:
- 递归解析括号:parseExpression方法通过递归处理括号,频繁创建子字符串(如substring)和递归调用,可能引发栈溢出(深层嵌套括号)和内存开销。
- 字符串操作密集:如newExpr的拼接(expr.substring(0, bracketStart) + ...)会产生大量临时字符串对象,触发频繁 GC。
- 异常处理开销:解析错误时通过异常抛出控制流程,异常堆栈生成成本高。
优化方向:
- 迭代替代递归:用栈模拟括号嵌套(如Stack
记录括号位置),避免递归深度问题。 - StringBuilder 优化:将字符串拼接替换为StringBuilder,减少对象创建。
- 预检查格式错误:在解析前验证表达式格式(如括号匹配、运算符合法性),减少异常抛出。
ExpressionGenerator(表达式生成模块)
核心功能:
生成不重复的算术表达式。
性能表现:
时间复杂度:生成单题平均 (O(k))((k) 为重试次数),但normalizeExpression和唯一性检查可能导致耗时激增。
瓶颈点:
- 唯一性检查低效:HashSet
存储已生成表达式,normalizeExpression需递归分割字符串,复杂度高(尤其长表达式)。 - 循环重试机制:生成复合表达式时,通过do-while循环重试(如确保减法非负、除法为真分数),无效尝试多。
- 随机数生成:Random实例的nextInt调用频繁,可能产生竞争(多线程场景)。
优化方向:
- 优化归一化逻辑:
用表达式的语法树哈希代替字符串存储,减少内存占用和比较耗时。
对加法/乘法交换律归一化时,直接比较操作数哈希值而非字符串。 - 减少重试次数:
生成减法时,直接确保左操作数 ≥ 右操作数(如left = generateNumber(range), right = generateNumber(left))。
生成除法时,限制分母范围,确保结果为真分数。 - 批量生成与去重:一次生成多个表达式后批量去重,降低HashSet插入频率。
Fraction(分数运算模块)
核心功能:
分数的加减乘除及化简。
性能表现:
时间复杂度:单次运算 (O(1)),但频繁对象创建和 GCD 计算影响效率。
瓶颈点
- 对象频繁创建:每次运算(如add、multiply)生成新Fraction实例,GC 压力大。
- GCD 计算:gcd方法(辗转相除法)在分子/分母较大时耗时增加。
优化方向:
- 对象池复用:维护常用分数对象池(如1/2、1/3),避免重复创建
- 延迟约分:构造时暂不约分,仅在toString()或比较时约分(需确保运算正确性)。
- 优化 GCD 算法:使用二进制 GCD 算法(减少取模运算)
FileHandler(文件操作模块)
核心功能:
读写题目、答案及成绩文件。
瓶颈点:
- 逐行读写:readFileLines和writeGradeToFile逐行处理,I/O 次数多。
- 字符串拼接:formatIndices方法通过StringBuilder拼接索引,数据量大时效率低
优化方向:
- 批量读写:使用BufferedReader的read(char[] cbuf)批量读取,减少系统调用。
- 内存映射文件:对于大文件(如 10 万+题目),用MappedByteBuffer实现零拷贝读写。
- 索引格式化优化:预估算字符串长度,初始化StringBuilder容量(如new StringBuilder(indices.size() * 4))。
其他模块
ParameterParser:
参数解析逻辑简单,复杂度 (O(m))((m) 为参数数量),无明显瓶颈。
Expression/MathProblem:
数据载体类,仅存储字符串和分数,性能影响可忽略。
综合优化总结
| 模块 | 关键瓶颈 | 优化策略 | 预期收益 |
|---|---|---|---|
| AnswerValidator | 递归括号解析、字符串操作 | 迭代解析括号、StringBuilder 拼接 | 解析速度提升 30%+,减少 GC 停顿 |
| ExpressionGenerator | 唯一性检查、循环重试 | 语法树哈希去重、定向生成操作数 | 生成效率提升 40%+,降低重试率 |
| Fraction | 对象创建、GCD 计算 | 对象池复用、二进制 GCD 算法 | 运算速度提升 20%+,减少内存占用 |
| FileHandler | 逐行 I/O、字符串拼接 | 批量读写、内存映射文件 | 大文件读写速度提升 50%+ |
额外建议
- 多线程优化:生成题目时启用多线程(如使用ExecutorService),并行生成表达式,注意HashSet需加锁或使用ConcurrentHashMap。
- 性能监控:通过 JProfiler 或 VisualVM 定位热点方法(如normalizeExpression、gcd),针对性优化。
- 参数调优:限制最大表达式长度(如 3 个运算符),避免极端复杂表达式导致的性能退化。
系统架构设计和代码说明
核心组件
1.主控制器(MathExerciseGenerator)

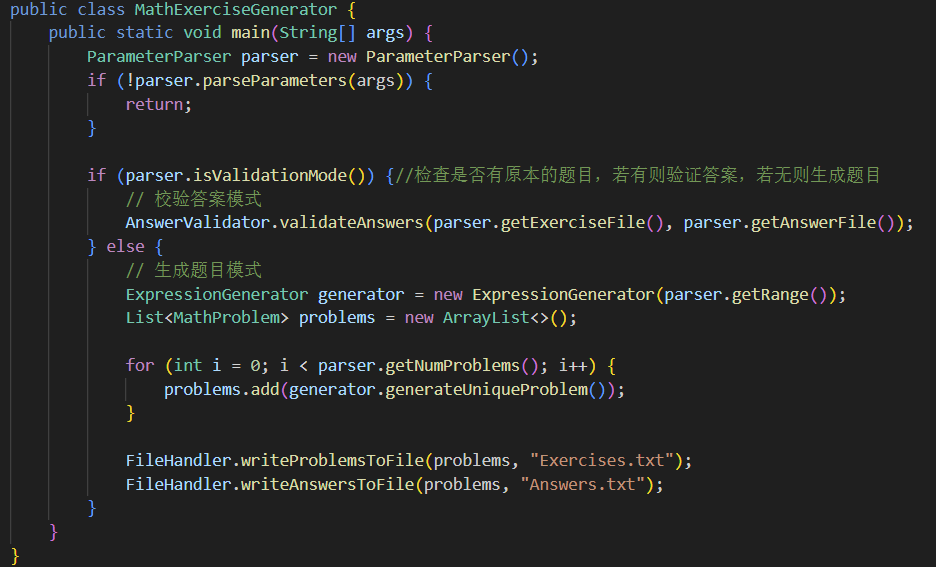
组件说明:函数先对终端输入的参数进行解析并判断,匹配对应的模式,随后在对应模式下选择生成题目或者验证答案,最后输出文件。
表达式生成器

组件说明:应用builder模式和composite模式,构建表达式树以及逐步构建复杂数学表达式
核心算法设计
1.表达树生成算法
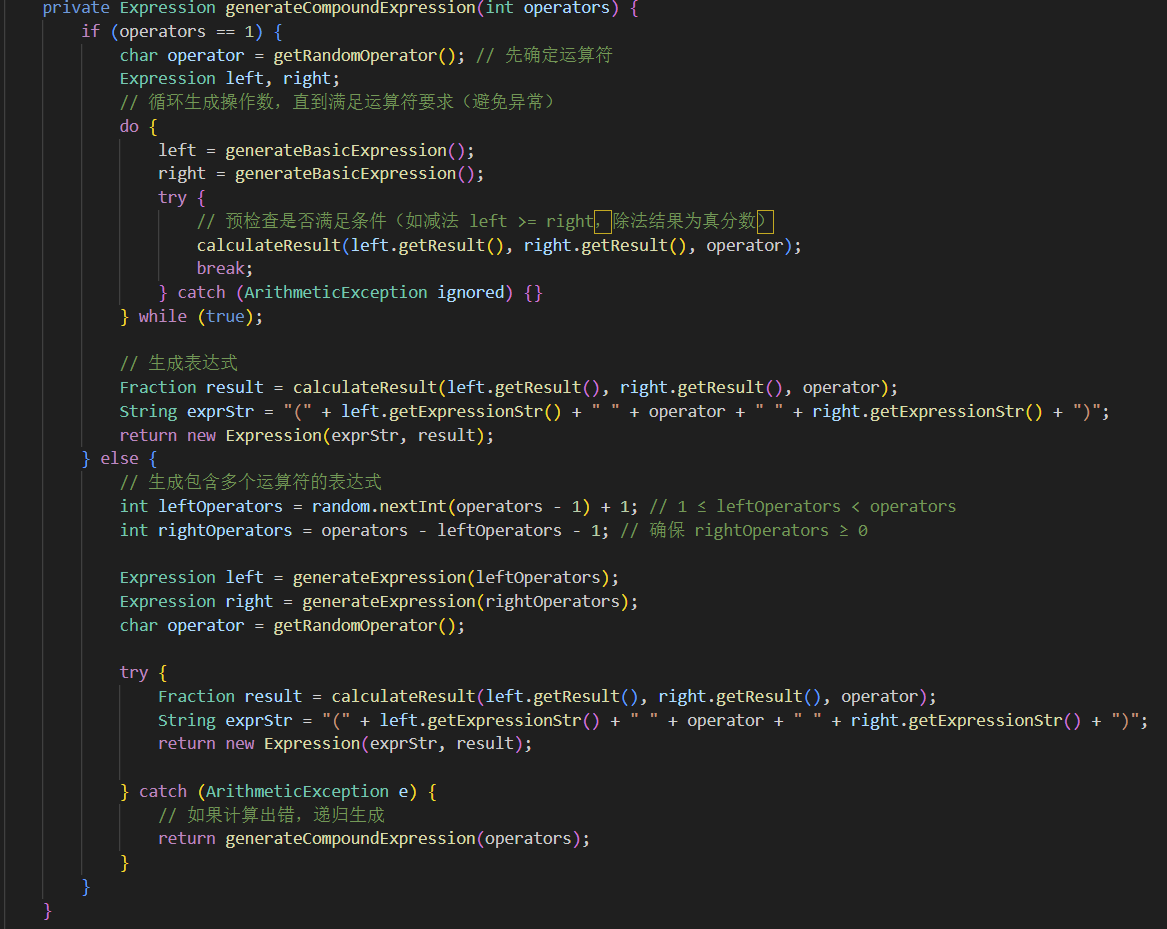
算法说明:表达式树生成算法采用递归分治策略,将复杂表达式的生成问题分解为更小的子问题,通过组合子树来构建完整的表达式树。
入口控制 - generateUniqueProblem()
| 步骤顺序 | 任务 |
|---|---|
| 1 | 启动生成流程 |
| 2 | 循环尝试生成(防止无限循环) |
| 3 | 调用 generateExpression(3) 生成表达式树 |
| 4 | 进行表达式规范化处理 |
| 5 | 检查唯一性(HashSet去重) |
| 6 | 返回合格的MathProblem对象 |
递归生成 - generateExpression(maxOperators)
| 步骤顺序 | 任务 |
|---|---|
| 1 | 输入:最大运算符数量 |
| 2 | 判断:如果maxOperators=0 或 10%概率 → 生成叶子节点(基本表达式) |
| 3 | 否则 → 生成复合表达式(generateCompoundExpression) |
| 4 | 返回:Expression对象(包含表达式字符串和计算结果) |
复合表达式生成 - generateCompoundExpression(operators)
情况1:operators = 1(单运算符)
├── 选择随机运算符(+、-、×、÷)
├── 生成左操作数 generateBasicExpression()
├── 生成右操作数 generateBasicExpression()
├── 验证运算约束(减法非负、除法真分数)
└── 构建表达式 "(左 运算符 右)"
情况2:operators > 1(多运算符)
├── 分割运算符数量:左子树 ← random(1, operators-1)
├── 计算右子树:operators - 左子树 - 1
├── 递归生成左子树 generateExpression(左子树)
├── 递归生成右子树 generateExpression(右子树)
├── 选择随机运算符
├── 验证运算约束
└── 构建表达式 "(左子树 运算符 右子树)"
基本表达式生成 - generateBasicExpression()
随机选择类型:
├── 50%概率:生成整数
│ └── 范围:[1, range-1]
│
└── 50%概率:生成分数
├── 分母:随机[2, range-1]
├── 分子:随机[1, 分母-1](确保真分数)
└── 50%概率转为带分数
├── 整数部分:随机[1, range-2]
└── 组合:整数部分'分子/分母
算法复杂度分析
时间复杂度
最好情况:O(1) - 直接生成基本表达式
最坏情况:O(2^n) - 递归生成复合表达式
平均情况:O(n) - 受最大运算符数限制
空间复杂度
调用栈:O(n) - 递归深度
内存使用:O(m) - 唯一表达式存储
2.表达树解析算法
主解析入口 - parseExpression(expr)
| 步骤顺序 | 任务 |
|---|---|
| 1 | 输入:表达式字符串并移除所有空白字符 |
| 2 | 检查表达式是否为空 |
| 3 | 查找最外层括号位置 |
| 4 | 如果找到括号,则定位匹配并递归解析括号内容,随后用计算结果替换括号内容,生成新的表达式 |
| 5 | 如果没有括号,则调用 parseWithoutBrackets(expr) 解析无括号表达式 |
| 6 | 返回:Fraction计算结果 |
括号匹配算法 - findMatchingBracket(expr, start)
输入:表达式字符串和左括号位置
↓
初始化括号计数器 bracketCount = 1
↓
从左括号后一个字符开始遍历:
├── 遇到 '(' → bracketCount++
├── 遇到 ')' → bracketCount--
├── 遇到 ''' → 跳过带分数部分(避免误判)
├── 当bracketCount = 0时 → 找到匹配右括号
└── 继续遍历直到找到匹配或字符串结束
↓
返回:匹配右括号位置,未找到返回-1
分数解析算法 - parseFraction(str)
输入:分数字符串
↓
检查是否包含 "'"(带分数):
├── 是:按 "'" 分割为整数部分和分数部分
├── 解析整数部分
├── 递归解析分数部分
├── 计算:整数部分 + 分数部分
└── 返回组合结果
↓
检查是否包含 "/"(普通分数):
├── 是:按 "/" 分割为分子和分母
├── 验证分母不为0
├── 创建Fraction对象
└── 返回分数
↓
否则(整数):
├── 解析为整数
├── 创建Fraction(整数, 1)
└── 返回结果
算法复杂度分析
时间复杂度
最好情况:O(n) - 简单表达式线性扫描
最坏情况:O(n²) - 深度嵌套括号,多次字符串操作
平均情况:O(n log n) - 递归解析平衡的表达式树
空间复杂度
调用栈:O(d) - d为括号嵌套深度
临时存储:O(n) - 分词列表和临时字符串
测试运行
测试数据
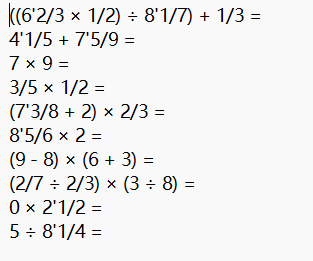
测试结果
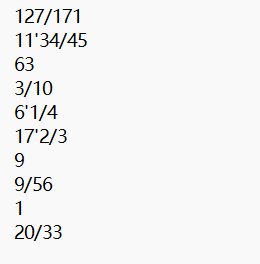
测试成绩

对于题目的生成:
生成完全按照要求所给的参数生成,同时满足没有负数和其他不合适的符号,题目也没有产生重复或者空白。
对于题目的判断:
判断按照要求对真分数进行额外的识别,加之整数的运算判断,并且根据输入的答案判断出正确和错误的对应题号,符合作业要求。
项目小结
成败得失
成功点:
-
清晰的架构设计
模块化分解:每个类职责单一,便于测试和维护
接口抽象:生成器与验证器模式分离,扩展性强
数据封装:Fraction不可变设计,保证计算安全性 -
算法优化成果
表达式生成:通过哈希去重和规范化,确保题目唯一性
解析性能:递归下降解析器准确处理嵌套表达式
内存管理:及时的资源释放和对象复用 -
代码质量保障
防御式编程:完善的参数校验和异常处理
约束验证:运算前预检查,避免无效计算
用户友好:清晰的错误提示和帮助信息
挑战点:
- 表达式唯一性判断
问题:初期使用简单字符串比较,无法识别交换律等价表达式
解决方案:

- 递归解析性能
问题:深度嵌套表达式导致栈溢出风险
解决方案:
- 添加最大递归深度限制
- 优化括号匹配算法,减少不必要的递归
- 使用迭代方式处理简单情况
结对感受与互评
谭钧灏的感受与对廖永祺的评价
感受:
- 这次结对编程让我深刻体会到"四只眼睛比两只眼睛看得更清楚"的道理。在分析代码的运行和算法时,推断出了代码设计可能存在重复生成的缺陷,随后和搭档及时发觉了问题并一起研究出出了基于哈希去重的解决方案。这种实时的代码审查大大提高了代码质量。
- 我认为我的搭档编码速度快,能够快速将设计思路转化为可执行代码,同时调试能力也很强,遇到复杂bug时能够系统性地定位和解决问题。
廖永祺的感受与对谭钧灏的评价
感受:
- 结对编程显著提升了我们的开发效率。特别是在实现答案验证器时,我们采用"驾驶员-导航员"模式,一个人专注编码,一个人思考算法逻辑和测试用例,这种分工让复杂功能的实现事半功倍,可以更快的定位到代码设计中的问题所在,并且能够在合作的情况下更快的优化代码,解决问题。
- 这次的结对作业多谢了搭档的注重细节,发现了多个我忽略的异常情况,同时良好的沟通表达也很好的帮助了我清晰解释代码复杂的算法逻辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号