
ELK日志处理部署笔记-1.部署elasticsearch集群
ELK概念简介
ELK建立在三个服务上即
Elasticsearch :: 日志检索和储存
Logstash :: 日志收集分析处理
Kibana :: 日志可视化
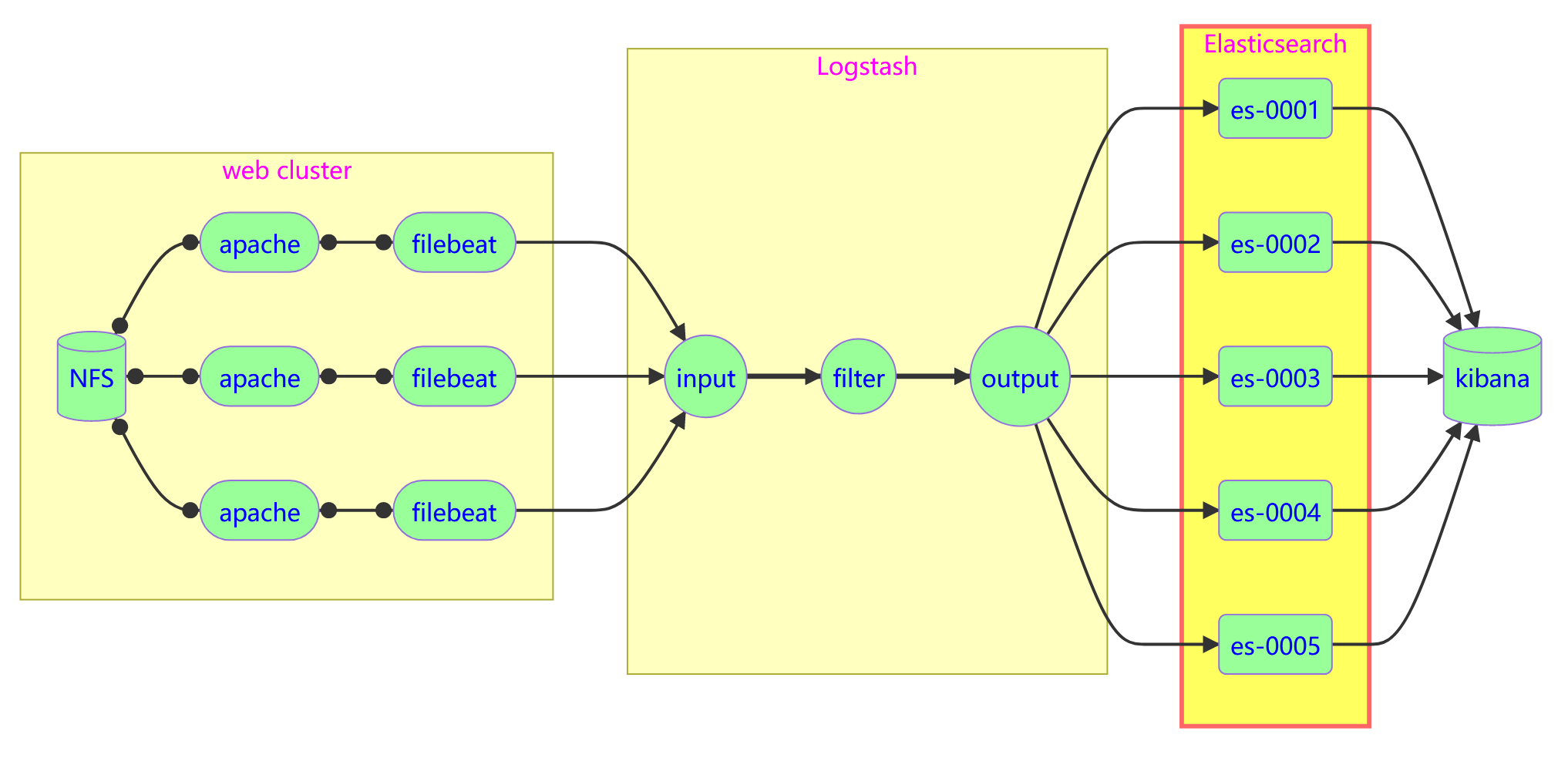
Elasticsearch
Elasticsearch 属于NoSQL数据库类型,更具体地说,它是一个文档型数据库(Document-Oriented Database)。在Elasticsearch中,数据以JSON格式的文档形式存储,并且支持动态模式,即无需预先定义数据结构。同时,Elasticsearch因其强大的全文搜索、实时分析和分布式特性
数据类型
Index 拥有相似特征的文档集合
Type 索引定义的类型
Document 一行具体数据
Filed 字段一个存储单元
集群模式
Elasticsearch采用了经典的raft模式,推荐将一部分专门配置为候选主节点(master-eligible nodes),而另一部分节点则仅作为数据节点(data nodes)。这样可以避免存储大量索引数据的节点同时承担集群管理任务,减轻单个节点的压力,提高整个集群的稳定性。
主节点(Master Node)是通过选举产生的,其主要作用是负责集群级别的元数据管理和变更操作,监控等作用,它是集群架构中的协调中心,负责控制集群的状态和结构变化,但并不直接处理搜索请求或存储数据。
Elasticsearch端口
9200/tcp -> 数据输出
9300/tcp -> 集群通信
配置方式
Redhat系列Linux中,配置文件通常位于/etc/elasticsearch/elasticsearch.yml
#集群名称
17: cluster.name: my-es
#本节点名称,需要是唯一的
23: node.name: es-0001
#允许来自任何IP地址的连接。这意味着该节点准备接受集群内其他节点以及客户端的连接请求。
56: network.host: 0.0.0.0
#广播节点,新节点启动时将其加入到集群中,至少两台,防止单点故障
70: discovery.seed_hosts: ["es-0001", "es-0002", "es-0003"]
#候选节点,至少三台,从其中选取管理的主节点
74: cluster.initial_master_nodes: ["es-0001", "es-0002", "es-0003"]
HEAD插件
head插件是将elasticsearch管理可视化的工具,收集9200端口信息,将其转发到网页端
# 在某个节点比如es-0001上安装 web 服务,并部署插件
dnf install -y nginx
#将插件解压到网页目录,通过 ELB 的 8080 端口,发布服务到互联网
tar -zxf head.tar.gz -C /usr/share/nginx/html/
systemctl enable --now nginx
设置proxy的nginx监听80端口,前端端口可自定义,这里我设置成8080
此时访问【proxyIP】:8080/es-head是互动管理页面,但是没有本机数据
【proxyIP】:8080/es是原始json页面,有本机数据
还需要nginx做转发
创建/etc/nginx/default.d/esproxy.conf文件,设置转发并设置管理页面需要密码登录
location ~* ^/es/(.*)$ {
proxy_pass http://127.0.0.1:9200/$1;
auth_basic "Elasticsearch admin"
auth_basic_user_file /etc/nginx/auth-user;
}
此时访问的转发路径是
访问proxy节点8080端口 => 转到es节点80端口 => 转到es节点9200端口
用户名密码设置工具,重新启动nginx服务
dnf install -y httpd-tools
htpasswd -cm /etc/nginx/auth-user admin #互动设定密码
systemctl reload nginx
此时可以通过【proxyIP】:8080/es-head管理
API管理
#创建分片副本
curl -XPUT -H 'Content-Type: application/json' \
http://127.0.0.1:9200/_template/index_defaults -d '{
{
"index_patterns": ["*"], # 这个模板将应用于所有新创建的索引
"settings": {
"number_of_shards": 5, # 默认每个索引有5个主分片
"number_of_replicas": 1 # 每个主分片默认有一个副本分片
}
}'
{"acknowledged":true}
# 创建 test 索引
curl -XPUT http://127.0.0.1:9200/tedu?pretty
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test"
}
#增加数据
curl -XPUT -H "Content-Type: application/json" \
http://127.0.0.1:9200/tedu/teacher/1?pretty -d '{
"职业": "诗人","名字": "李白","称号": "诗仙","年代": "唐"
}'
#查询数据
curl -XGET http://127.0.0.1:9200/tedu/teacher/_search?pretty
curl -XGET http://127.0.0.1:9200/tedu/teacher/1?pretty
#修改数据
curl -XPOST -H "Content-Type: application/json" \
http://127.0.0.1:9200/tedu/teacher/1/_update -d '{
"doc": {"年代":"公元701"}
}'
#删除一条
curl -XDELETE http://127.0.0.1:9200/tedu/teacher/1
#删除索引
curl -XDELETE http://127.0.0.1:9200/tedu
附注
如果elasticcsearch因为集群启动顺序原因,没有被加入到节点,重启即可
设置默认分片的命令无法改变之前数据的分片情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号