SQL 执行进展优化
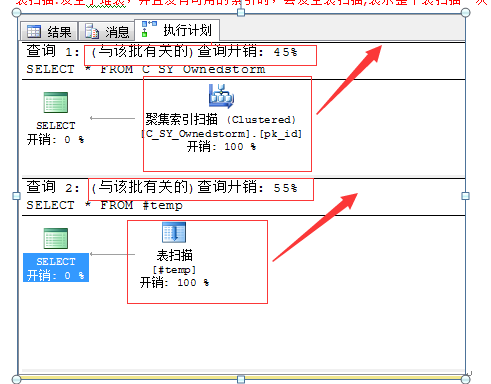
聚集索引扫描
SELECT * FROM C_SY_Ownedstorm
聚集索引扫描比表扫描快
聚集索引扫描:发生于聚集表,也相当于全表扫描操作,但在针对聚集列的条件等操作时,效率会较好。
表扫描
SELECT * FROM #temp
表扫描:发生于堆表,并且没有可用的索引时,会发生表扫描,表示整个表扫描一次。
测试SQL
CREATE TABLE t1(c1 INT, c2 VARCHAR (8000)); GO DECLARE @a INT; SELECT @a = 1; WHILE (@a <= 5000) BEGIN INSERT INTO t1 VALUES (@a, replicate('a', 5000)) SELECT @a = @a + 1 END GO
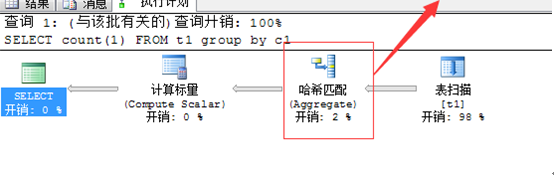
SELECT count(1) FROM t1 group by c1
哈希匹配:
哈希匹配的作用就是把它右侧的两个表中行数比较少的那个经过哈希算法形成一个哈希表,然后再有另一个数据行数比较大的表来之前形成的哈希表中匹配查找数据,大体上就是这个么流程。但是哈希匹配操作的出现一定要提高我们的警惕,当哈希匹配右侧的两个表中的数据有一个比另一个明显的少的时候,哈希匹配的效率会比较高,反之就会影响效率。出现哈希匹配大概有这么几个情况:
有缺失或者不正确的索引
缺少where字句
在where子句中有对列的类型转换或者数据操作,这样就不能使用索引了
虽说哈希匹配在某些情况下效率会比较高,但是这并不意味着没有更好的来提高这个查询的效率,比如添加适当的索引或者通过where语句来减少数据量等方法。换句话说,当出现哈希匹配这个操作的时候,我们要引起注意,看看是否还有别的方法来提高查询效率,如果没有的话,或许哈希匹配就是最好的选择了。
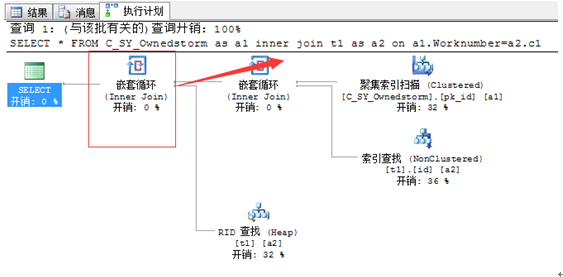
聚集索引查找:
CREATE UNIQUE CLUSTERED INDEX _Id ON t1(c1) select * from t1 where c1=3

排序:
排序是消耗性能的,sql server中排序是在数据找出来以后在进行排序的。
select * from t1 order by desc

循环嵌套
对于使用简单内连接的小数据量表,嵌套循环是最佳策略。最适合两个表的记录数差别非常大,并且在连接的列上都有索引的情况。嵌套循环连接所需的I/O和比较都是最少的。
嵌套循环在外表(往往是小数据量的表)中每次循环一个记录,然后在内表中查找所匹配的记录并输出。有很多关于嵌套循环策略的名字。例如,对整个表或索引进行查询,称为Naive(无知的)嵌套循环连接。使用正常索引或临时索引时,被称为索引嵌套循环连接或临时索引嵌套循环连接。
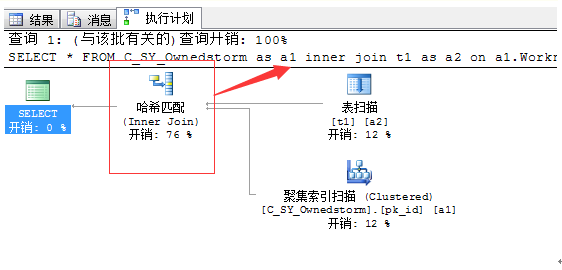
合并连接
合并连接也是在读的同时对两个存储输入的一行进行比较。在每个步骤中,比较每个输入的下一行。如果两行是相同,输出一个连接后的行并继续。如果行是不同的,舍弃两个输入行中较少的那个并继续。因为输入是存储,连接舍弃的任何行必须比两个输入中任何剩下的行要小,因此可以永不连接。合并连接不需要对两个输入中的每一行扫描。只要到了两个输入中的某一个的末尾,合并连接就会停止扫描。
嵌套循环连接总的消耗和在输入表中行的乘积成比例,不同于嵌套循环连接,合并连接的表最多读一次,总的消耗和输入行数的总数成正比例,因此何必连接对于大量的输入是较好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号