Paper Reading: ProtoGate: Prototype-based Neural Networks with Global-to-local Feature Selection for Tabular Biomedical Data
Paper Reading 是从个人角度进行的一些总结分享,受到个人关注点的侧重和实力所限,可能有理解不到位的地方。具体的细节还需要以原文的内容为准,博客中的图表若未另外说明则均来自原文。
| 论文概况 | 详细 |
|---|---|
| 标题 | 《ProtoGate: Prototype-based Neural Networks with Global-to-local Feature Selection for Tabular Biomedical Data》 |
| 作者 | Xiangjian Jiang, Andrei Margeloiu, Nikola Simidjievski, Mateja Jamnik |
| 发表会议 | The 41st International Conference on Machine Learning (ICML 2024) |
| 发表年份 | 2024 |
| 会议等级 | CCF-A |
| 论文代码 | https://github.com/SilenceX12138/ProtoGate |
作者单位:
- Department of Computer Science and Technology, University of Cambridge, UK
- Department of Oncology, University of Cambridge, UK.
研究动机
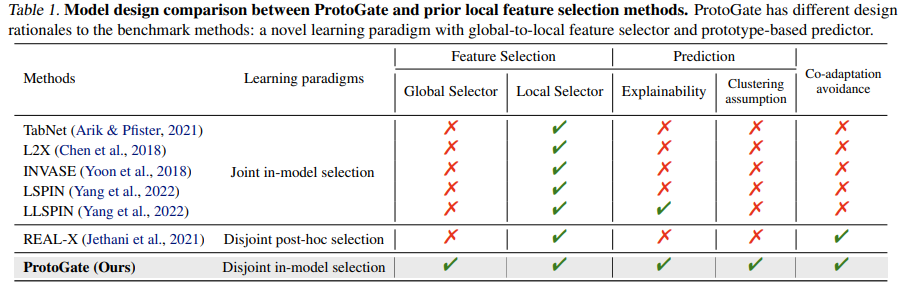
在生物医学的研究中经常基于表格数据进行分析,该领域下生成的表格数据集通常是高维、低样本的(HDLSS)。同时鉴于生物医学的数据具有异质性,重要特征通常因样本而异。先前工作大多都基于局部特征选择,即不是选择所有样本上的特征的一般子集,而是为每个样本选择特征的特定子集。现有的方法仍然具有三个主要的局限性:
- 忽略全局重要特征:很多主流方法仅执行局部特征选择,可能完全忽略了对大多数或所有样本都重要的全局性特征,导致有时这些方法的性能比 MLP、Lasso 等简单方法差;
- 共适应问题导致低保真度特征选择:可训练的特征选择器和预测器是共同学习的,这会导致共适应。预测器可能会学会过度拟合特征选择器选出的、甚至可能是无意义或带有欺骗性的特征,从而在训练集上表现出高精度。例如 L2X 模型可以用单个像素在 MNIST 数据集上达到 96% 的准确率,但单个特征对理解模型决策毫无意义。
- 可解释性不足和不适当的归纳偏差:一些方法可能引入了不恰当的归纳偏差,例如 LSPIN 强制要求原始输入空间中相似的样本具有相似的特征掩码,但假设“原始特征的相似性等价于重要特征的相似性”在复杂高维数据中可能并不成立,甚至会损害性能。
文章贡献
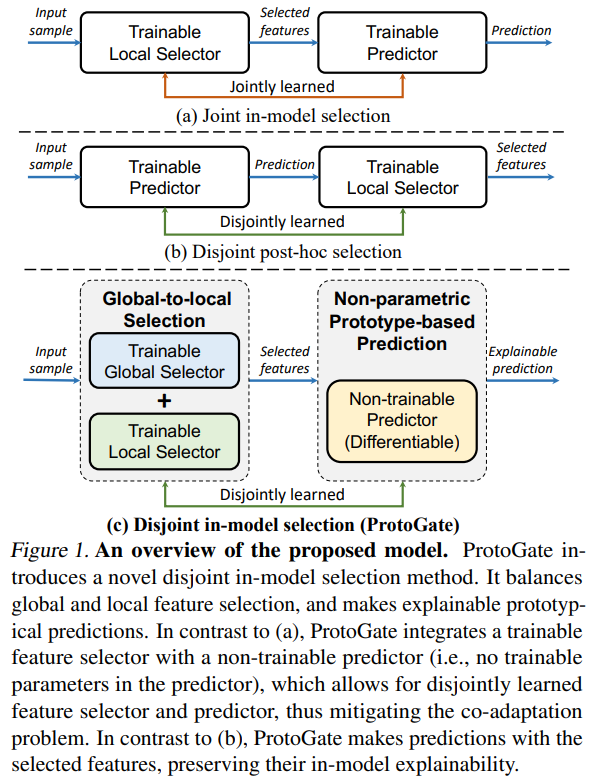
ProtoGate 是一个针对高维低样本量(HDLSS)生物医学表格数据设计的创新型特征选择与分类框架,其核心在于通过一种解耦的、原型驱动的架构来同时实现高预测精度、高特征选择保真度以及内在的可解释性。首先使用全局到局部的特征选择器自适应地识别重要特征,它采用两阶段策略:先通过门控网络第一层的 L1 正则化进行“软全局选择”,快速筛选出所有样本共享的潜在重要特征集;再通过后续层的 L0 正则化进行“局部选择”,为每个样本生成个性化的稀疏特征掩码。接着使用非参数的原型预测器进行预测,该预测器将特征选择后的查询样本与训练阶段构建的“原型库”中的原型样本进行相似度比较,基于 K 个最近邻原型的多数投票得出预测结果。模型中仅特征选择器的参数是可训练的,训练损失函数由预测损失和特征选择正则化项加权构成,并通过可微排序技术使梯度能从原型预测损失顺畅地反向传播至特征选择器。
预备知识
在传统编程中,排序(例如快速排序)是一个明确的、离散的操作:给定一个数组 [3, 1, 2],排序后得到 [1, 2, 3] 或其索引 [1, 2, 0]。这个操作本身是不可微的,在深度学习中使用会带来梯度断裂的问题。可微排序的目的是解决梯度断裂问题,为排序这个离散过程提供一个连续的、可微的近似。
可微排序的的核心思想是软排序,它将输出一个确定的、离散的排列顺序,也就是输出一个连续的、概率性的“软”排列。它不直接表示“第一个元素排第三”,而是描述为“第一个元素有很高的概率排第三,也有很小的概率排第二或第四”。这个输出通常是一个双随机矩阵(每行、每列的和都为1),矩阵中的每个值 P[i, j] 可以理解为输入中第 i 个元素被排在第 j 个位置的概率。
有多种方法可以实现可微排序,本文使用的是基于松弛的 NeuralSort 方法。该方法通过引入噪声或特定的变换,将离散的排序操作转化为一个连续的优化问题。NeuralSort 利用了一个数学结论:排序操作可以表示为线性规划问题,该问题的解可以在单纯形上通过某种变换得到。NeuralSort 的公式如下,softmax 函数中的分子部分计算了所有元素对之间的差值,其绝对值反映了元素间的相对次序关系;分子部分为温度参数 τ 用于控制松弛程度,当 τ→0 时 P 趋近于硬的排列矩阵,当 τ→∞ 时 P 趋近于均匀分布。
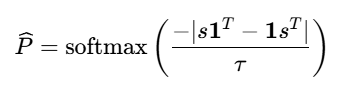
下表总结了两种排序方法的不同:
| 排序方法 | 硬排序 | 可微排序 |
|---|---|---|
| 输出 | 确定的、离散的排列顺序或索引 | 连续的、概率性的软排列矩阵 |
| 可微性 | 不可微,导致梯度断裂 | 可微,支持梯度反向传播 |
| 目的 | 快速、精确地得到结果,用于最终预测 | 在训练过程中提供有意义的梯度信号,以优化模型参数 |
| 计算 | 高效(如 QuickSort) | 相对耗时,涉及矩阵运算 |
本文方法
考虑具有 Y 类的表格生物医学数据的分类任务,令 X 是由具有 D 个特征的 N 个样本 x(i)∈RD 组成的数据矩阵,Y 是相应的标签。将 x(i)d 表示为第 i 个样本的第 d 个特征,本文的研究主要考虑 HDLSS 数据集,该类数据集的特征的数量远远大于样本的数量。ProtoGate 的模型框架如下图所示,它包括 3 个核心组件:全局到局部特征选择、基于原型的非参数预测、不相交的目标函数。
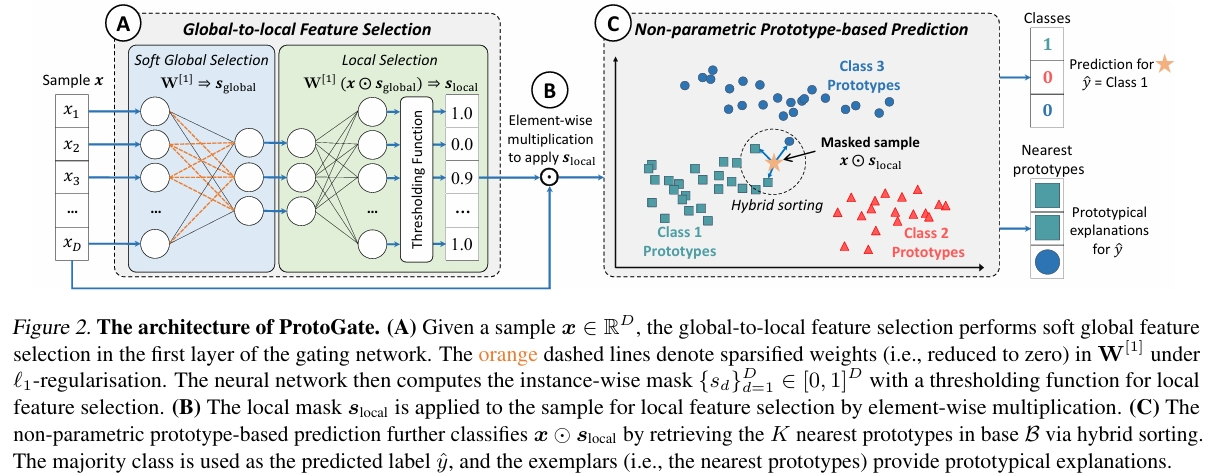
全局到局部特征选择
在生物医学等 HDLSS 数据中,重要特征通常呈现出两种特性:
- 全局重要性:某些特征在所有或大多数样本中都具有判别力;
- 局部重要性:在特定样本上在特定样本上,某些特征具有更高的重要性。
全局到局部特征选择(Global-to-local Feature Selection)是一种分阶段、自适应的特征选择策略,旨在同时捕获数据中的全局模式和局部特异性。它先通过全局选择建立一个稳健的基础,再通过局部选择对特定样本的特征集合进行精细调整,该机制通过一个可训练的门控网络(Gating Network)SW 实现。
软全局选择
在阶段一执行软全局选择(Soft Global Selection),旨在高效地识别出对全体样本普遍重要的特征。实现方式是在门控网络的第一层权重 W[1] 上施加 L1 正则化(Lasso正则化),该操作会倾向于将权重向量中的某些值压缩至零。在数学上,第一层的计算变换如下公式所示,其中 ⊙ 表示逐元素乘法,s(i)global∈{0, 1}D 为二元掩码。
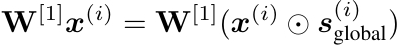
如果连接到某个输入特征的所有权重(即 W[1] 中的某一列)都被压缩至零,则该特征被视为“全局不重要”,并在后续计算中被屏蔽。这相当于产生了一个二值的、样本无关的全局掩码 s(i)global,其中 0 表示该特征被全局丢弃。第一层权重是跨样本共享的,因此掩码对于所有样本是一致的,如以下公式所示。
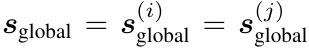
该步骤称之为“软”特征选择是因为这个阶段只是一个初步筛选,被全局丢弃的特征并未被永久删除,它们仍有机会在后续的局部阶段被“恢复”。
局部选择
在全局选择的基础上进一步进入局部选择(Local Selection)阶段,这一阶段为每个样本生成独一无二的特征重要性权重。该阶段将经过全局掩码筛选后的特征表示输入门控网络的后续层,如下公式所示,为每个样本计算出一个中间向量 u(i)。
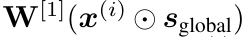
为了获得稀疏的、实例级的掩码,模型采用如下公式,其中 ε(i) 是高斯噪声,并施加 L0 正则化来鼓励掩码中出现更多的精确零值。
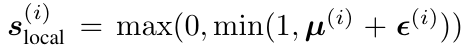
门控网络为每个样本输出一个连续值的、实例级的掩码 s(i)local∈[0, 1]D。该掩码可以做出三种决策:
- 保留:认可全局选择,保留全局认为重要的特征。
- 丢弃:认为某个全局重要的特征对当前样本不重要,将其权重置零。
- 恢复:认为某个被全局丢弃的特征对当前样本至关重要,重新激活它。
这两个阶段的集成封装在 ProtoGate 的加权稀疏正则化中,如下公式所示。其中(λglocal,λlocal)是一对超参数,用于平衡全局和局部特征选择之间的正则化强度。
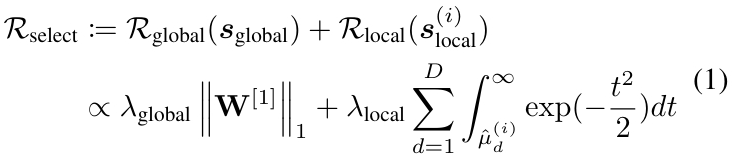
互补规则
ProtoGate 在其两阶段选择过程中使用不同的规则来解决不同的目标。首先,软全局选择专注于有效地识别全局重要的低维特征集,因此 ProtoGate 通过更快的 L1 正则化来提升 sglobal 中的稀疏性。其次,局部选择的目的是识别局部重要特征,以实现准确的预测和较高的可解释性,因此该阶段选择 L0 正则化进行局部选择。全局阶段通过 L1 正则化快速降低问题维度,为计算开销更大的局部选择提供一个更小、更相关的特征子集,提升了整体效率。局部阶段则在此基础上进行调整,保证了选择的精度。全局选择提供了一个所有样本共享的归纳偏差,有助于稳定训练,防止在极低样本量的情况下因过度局部化而导致的过拟合。
下图用 colon 数据集对软全局选择和局部选择之间的相互作用进行可视化,可以看到四种不同的特征选择行为:
- 两者都被选择:第 61 个特征被全局和局部同时选择;
- 局部丢弃:第 828 个特征被全局选择,但是对于该样本它被局部丢弃;
- 局部恢复:第 1355 个特征被全局丢弃,但是对于该样本它被局部恢复;
- 两者都被丢弃。

非参数原型预测
在传统的“联合式”局部特征选择模型中,可训练的特征选择器和可训练的预测器容易发生“共适应”,也就是预测器会过度拟合选择器可能选出的无意义特征,从而在训练集上表现出高精度。针对这个问题,通过全局到局部特征选择后将进入非参数原型预测(Non-parametric Prototype-based Prediction)模块,它基于可微的 KNN 实现。该模块是一个非参数化的预测器,它不依赖于传统的、带有可训练权重的神经网络层(如全连接层)进行分类,而是通过直接比较新样本与训练集中有代表性的“原型”样本来进行预测。具体含义为:
- 非参数化:该预测器本身没有可训练的参数(如权重矩阵、偏置向量;
- 基于原型:预测基于数据本身的原型或典型代表,预测结果通过找到与输入样本最相似的几个训练样本(原型),并以它们的标签为依据来决定。
在训练过程中,每当一个训练样本通过特征选择器得到其局部掩码后,模型会创建一个原型,如下公式所示。所有训练样本对应的原型 p(i) 构成了原型库 B,它在训练期间会不断更新,并在训练完成后固定下来,用于后续的推理。
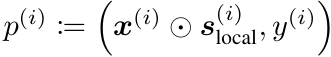
ProtoGate 提出了混合排序策略来平衡训练的有效性和推理的效率。在训练时,模型需要将预测损失(预测错误)的梯度反向传播给特征选择器,因此 ProtoGate 使用可微排序(NeuralSort)实现端到端训练。首先将查询样本与所有原型的负欧氏距离作为输入向量 s,使用负距离是因为排序通常按降序找最大值,需要距离最小(负值最大)的原型排名靠前。接着使用 NeuralSort 输出一个行随机矩阵 P,其中 P[n, m] 表示第 m 个原型是第 n 个最近邻的概率。因此,每个查询样本的预测损失由下式给出:
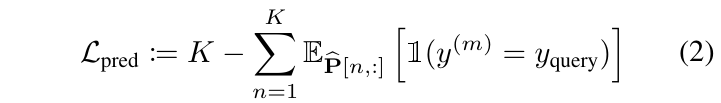
ProtoGate 的训练过程的伪代码如下所示:

在预测时将切换为不可微但高效的排序(QuickSort)来提升推理速度。由于推理时不再需要计算梯度,可以转而使用经典的、计算效率极高的排序算法。因此直接使用快速排序等算法找出精确的 K 个最近邻,这种混合策略能将推理时间减少近一半,且不损失任何预测精度。
预测阶段的伪代码如下所示,首先使用训练好的特征选择器为其生成掩码,得到掩码后的表示。接着计算该掩码后样本与原型库 B 中每一个原型之间的欧氏距离,距离越近则相似度越高。最后根据相似度(距离)对所有原型进行排序,找出最相似的 K 个原型,预测结果由这 K 个原型的标签通过多数投票决定。该步骤和 KNN 分类器相同。

以下为个人理解:
在 ProtoGate 中 KNN 并不是在“维度不同”的特征向量上运行的,而是所有样本在进行相似度计算前都被映射到了一个统一的、维度固定的“特征重要性空间”。ProtoGate 为每个样本的所有特征计算一个连续的重要性权重(即局部掩码 \(s_{\text{local}}^{(i)} \in [0,1]^D\)),该权重向量本身就是一个固定维度(D 维)的表示。样本 \(x^{(i)}\) 的原始特征向量(D 维)与其对应的局部掩码 \(s_{\text{local}}^{(i)}\)(也是 D 维)进行逐元素相乘,得到一个加权的特征向量 \(x^{(i)} \odot s_{\text{local}}^{(i)}\),这个操作后的向量维度仍然是 D,然后就可以使用 KNN 进行进一步处理了。
ProtoGate 的非参数预测器无法通过训练来适应选择器,仅是客观地评估所选特征是否真正使得查询样本与同类原型更接近,这迫使特征选择器必须选出真正有区分度的特征,从而保证了特征选择的高保真度。同时该模块的预测过程具有可解释性,模型可以直接给出其决策依据,即 K 个最相似的原型。
解耦训练损失
ProtoGate 的总训练损失函数 Ltotal由两部分构成,如下公式所示。其中,预测损失 Lpred 衡量的是模型预测结果与真实标签之间的差异,它来自于非参数的原型预测器。这个损失项迫使特征选择器 S 选择那些能够使样本在特征空间中与同类原型聚集、与异类原型分离的特征。选择正则化项 Rselect 负责控制特征选择的稀疏性,由 Rglobal 和 Rlobal 两部分加权求和得到。通过一个可调的加权和,模型可以同时追求这两个目标,避免在单一目标上过拟合。
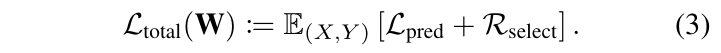
在 ProtoGate 的整个架构中,只有特征选择器 SW 的参数 W 是需要通过梯度下降来优化的。这种设计切断了共适应的反馈循环,预测器无法调整自身参数去适应选择器可能提供的低质量特征,它只能不断地评估所选特征是否真的能形成有区分度的数据簇,提升了特征选择的保真度。
实验结果
数据集和实验设置
本文实验使用的数据集包括真实数据集和合成数据集。真实数据集包括 7 个开源 HDLSS 表格生物医学数据集,基本信息如下表所示。
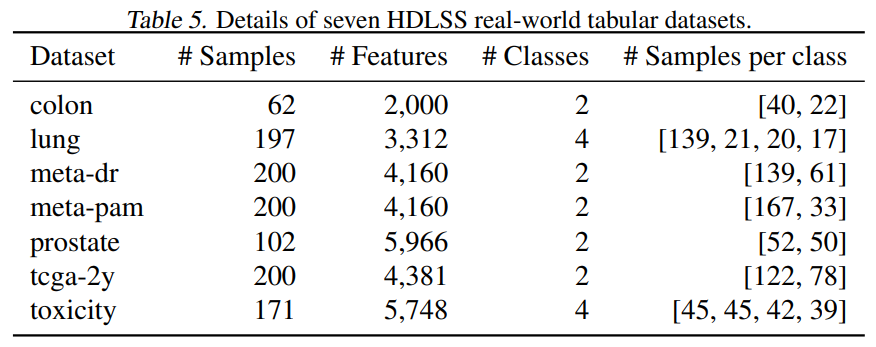
以及还有 4 个具有挑战性的非 HDLSS 和非生物医学表格数据集,基本信息如下表所示。
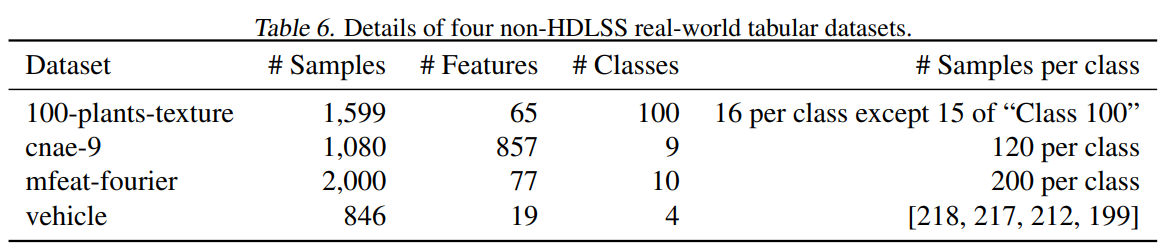
论文合成了 Syn1(+)、Syn2(+)、Syn3(-) 三个数据集,每个数据集均包含 200 个样本,每个样本有 100 个特征。特征值独立地从高斯分布 N(0,I) 中采样生成,每个数据集中两个类别的样本数分别为150 和 50 来体现不平衡性。数据生成的核心是为每个样本计算一个逻辑值(logit),并据此决定其类别标签。具体流程如下:

每个数据集使用 5 次五折交叉验证,随机选择 10% 的样本作为验证集,每个模型在每个数据集上使用验证集调整超参数。ProtoGate 与 16 个基准方法进行比较,baseline 方法包括岭回归、SVM、KNN、MLP,基于全局特征选择的方法包括 Lasso、Random Forest、XGBoost、CatBoost、LightGBM、STG(随机门特征选择)。基于局部特征选择的方法包括:
| 模型名称 | 核心描述 | 创新点 |
|---|---|---|
| TabNet | 序列注意力机制 | 实例级特征选择 |
| L2X | 互信息最大化 | 特征子集选择 |
| INVASE | 强化学习框架 | Actor-Critic 方法 |
| REAL-X | L2X 改进版 | 解耦训练 |
| LSPIN | 局部稀疏掩码 | 相似性约束 |
| LLSPIN | LSPIN 变体 | 线性预测器 |
真实数据集评估
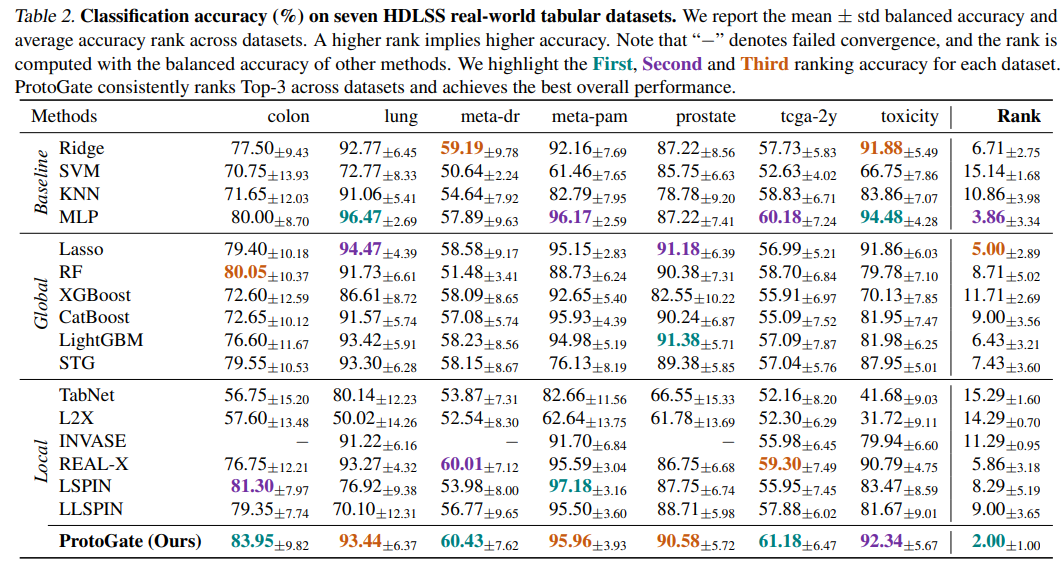
在 7 个 HDLSS 数据集上用使用平衡准确率评估所有方法并计算平均排名,可见 ProtoGate 表现最佳。ProtoGate 的平均排名第一(2.00),且在全部数据集中均位列前三。Lasso 和 MLP 等简单模型优于许多先进局部方法,突显了 HDLSS 任务的挑战性及现有局部方法的局限性。
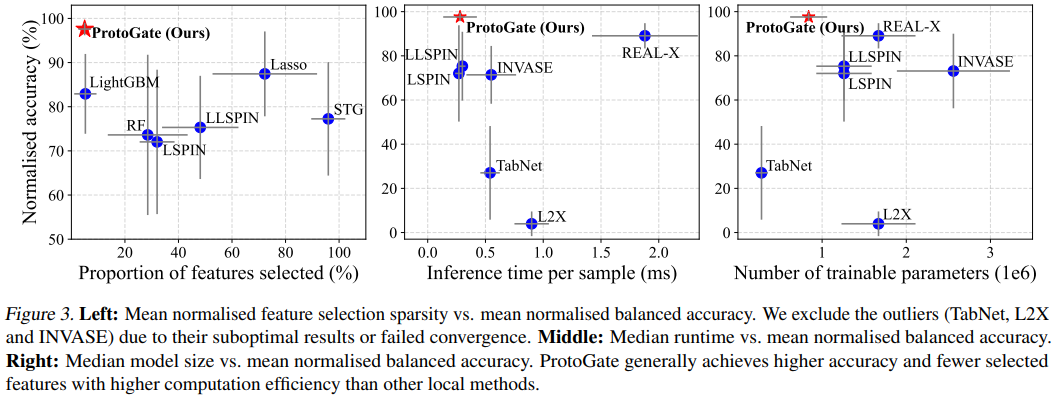
在特征选择的稀疏性方面,评估了每个样本所选特征的平均数量或比例。可见 ProtoGate 能够以更少的特征达到更高的分类准确率,表明其选择特征的信息密度和效率更高,有利于解释。在计算效率方面记录了模型推理时间、训练时间及参数量,ProtoGate 在保持高精度的同时具有更短的推理时间和更少的模型参数量。
消融实验
文中通过消融实验验证 ProtoGate 两个核心组件的必要性。对于全局与局部选择的互补性,对比了 完整 ProtoGate 与两个变体:
1. ProtoGate-global:仅保留全局选择(λlocal=0)。
2. ProtoGate-local:仅保留局部选择(λglobal=0)。
实验结果可见完整 ProtoGate 在所有数据集上的准确率均高于两个变体,说明软全局选择和局部选择是互补的,单独移除任一组件都会导致性能下降。

接着验证非参数原型预测的有效性,将原型预测器替换为线性层或 MLP。从实验数据可见使用原型预测器的版本性能最佳,证实了基于聚类假设的原型预测机制对提升性能的有效性。

可解释性评估
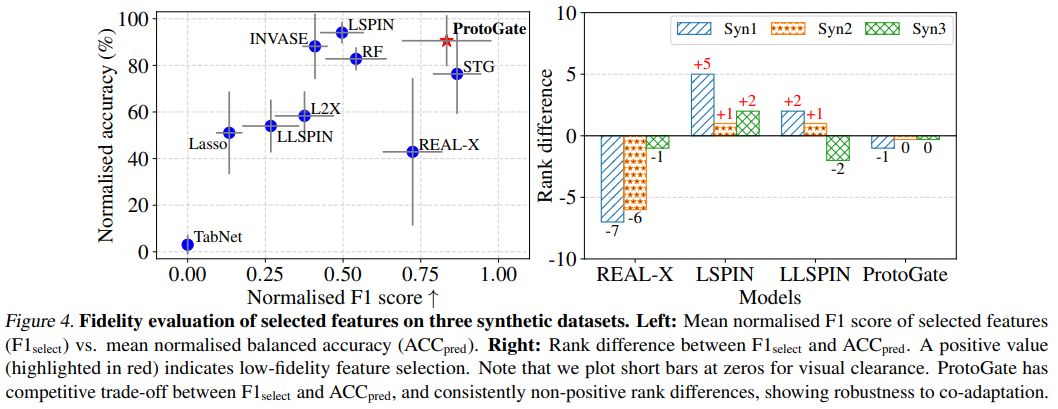
在特征选择保真度方面,实验在合成数据集上评估同时评估特征选择 F1 分数和分类准确率,并计算两者的排名差。结果可见 ProtoGate 是唯一一个始终保持非正排名差的模型,也就是特征选择质量排名不低于其准确率排名。这表明 ProtoGate 的高准确率是建立在正确选择特征的基础上,有效缓解了共适应问题,保证了特征选择的高保真度。
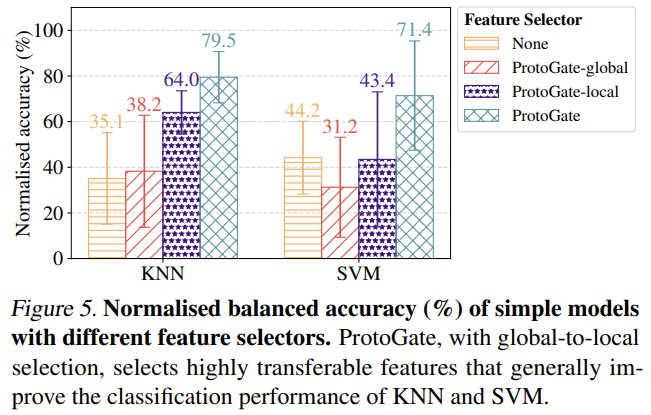
在特征可转移性方面,使用 ProtoGate 选出的特征来训练简单的下游模型(如 KNN、SVM),观察其性能变化来评估。可见由完整 ProtoGate 选择的特征能稳定提升简单模型的性能,而仅用全局或局部选择的变体选择的特征有时会导致性能下降。这表明完整 ProtoGate 所选特征具有高可转移性和高信息量。
在预测可解释性方面,ProtoGate 可提供实例级解释。例如在 colon 数据集上,模型不仅能给出诊断结果,还能指出作为决策依据的 K 个最相似的已确诊原型(病例),使其决策过程透明、可信。

优点和创新点
个人认为,本文有如下一些优点和创新点可供参考学习:
- 在 HDLSS 数据的特征选择方面,ProtoGate 将软全局与实例级局部特征选择结合,实现了对高维数据中全局重要性和局部特异性的自适应平衡;
- 通过将可训练的特征选择器与无参数的原型预测器解耦,有效解决了局部特征选择中的共适应问题,确保了特征选择的高保真度;
- 模型具有良好的可解释性,它利用原型预测机制提供案例式解释,并通过混合排序策略平衡训练效果与推理效率,兼具可解释性和实用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号