Paper Reading: Resampling strategies for imbalanced regression: a survey and empirical analysis
Paper Reading 是从个人角度进行的一些总结分享,受到个人关注点的侧重和实力所限,可能有理解不到位的地方。具体的细节还需要以原文的内容为准,博客中的图表若未另外说明则均来自原文。
| 论文概况 | 详细 |
|---|---|
| 标题 | 《Resampling strategies for imbalanced regression: a survey and empirical analysis》 |
| 作者 | Juscimara G.Avelino, George D.C.Cavalcanti, Rafael M.O.Cruz |
| 发表期刊 | Artificial Intelligence Review |
| 发表年份 | 2024 |
| 期刊等级 | 中国科学院SCI期刊分区(2025年3月最新升级版)大类 1 区,小类 2 区 TOP |
| 论文代码 | https://github.com/JusciAvelino/imbalancedRegression |
作者单位:
- Centro de Informática, Universidade Federal de Pernambuco, Cidade Universitária, Recife, PE 50740-560, Brazil
- École de technologie supérieure, Université du Québec, 1100 Notre Dame St. W., Montreal, QC H3C 1K3, Canada
不平衡回归问题
Branco 等人(Smogn: a pre-processing approach for imbalanced regression.)基于两个因素定义了不平衡问题:用户在目标变量域的不成比例偏好;在与用户最相关的实例中可用数据的代表性不足。在回归问题中目标值是连续的,因为目标值不限于有限的离散值集,所以回归问题的不平衡的定义非常复杂。下图显示了目标值范围为 2.7~17.3 的不平衡数据集 FuelCons 中实例分布和频率,本文采用了约 0.2 的区间宽度,从而得到总共 74 个区间。图表边缘的值显示的频率很低,被认为是罕见的实例。

Ribeiro(Utility-based regression.)提出了相关性函数的概念,该函数确定了连续目标值的相关性,将某些实例定义为罕见实例。标准回归任务假设域的所有值都具有同等重要性,并且通常基于最频繁值的性能进行评估。这种情况给算法带来了特殊的困难,算法往往遵循较大数量的值的区间,而忽略分布中的稀有值,导致不能获得良好的预测性能。
与分类问题相关的研究相比,不平衡回归问题的研究相对较少(Learning from class-imbalanced data: review of methods and applications.)。最常见方法是通过平衡训练数据来修改实例的分布,例如随机欠采样、随机过采样、基于加权相关性的组合策略 WERCS。此外,一些现实世界中的不平衡回归问题使用恢复策略来正确处理罕见和极端的情况,软件缺陷预测、酶最适温度预测、卫星图像协助检测土壤中的砷浓度。
不平衡回归的另一个困难在于,传统的性能指标(如 MSE 和 MAE)不能充分捕获用户定义的标准(Pre-processing approaches for imbalanced distributions in regression.)。该问题通常使用针对回归任务的 Precision、Recall 和 F1(Precision and recall for regression.)以及Ribeiro and Moniz(Imbalanced regression and extreme value prediction.)提出的平方误差相关面积 SERA 指标。然而,在这些性能指标下的不同不平衡回归之间的比较,以及它们在评估模型性能的方法上的差异,仍然是一个悬而未决的问题。
本文目标和贡献
本文的主要目的是从不同的角度来分析重采样策略在处理不平衡回归问题的效果,采用了不同的重采样策略和学习算法进行了广泛的实验研究,还使用了不同的不平衡回归任务的性能指标。
本文从以下研究问题进行切入:
- 是否值得使用重采样策略?
- 哪些重采样策略对预测性能的影响最大?
- 最佳策略的选择是否取决于问题、学习模式和使用的指标?
- 每种策略产生的训练实例的数量是否会影响结果?
- 数据的特征(罕见实例的百分比、罕见实例的数量、数据集大小、特征的数量和不平衡率)是否影响模型的预测性能?
实验分析表明:
- 重采样策略对绝大多数回归模型都是有益的,最好的策略包括 GN、RO 和 WERCS;
- 最佳策略的选择取决于数据集、回归模型和评估性能时使用的度量;
- 数据集大小、罕见实例数、特征数和不平衡率对结果有显著影响,最小的数据集和罕见实例最少的数据集是最具挑战性的;
- 不平衡率越高,回归模型遇到的挑战就越大。
本文的主要贡献如下:
- 根据回归模型、学习策略和指标提出了一种新的不平衡回归任务分类方法;
- 回顾了不平衡回归任务的主要策略;
- 进行了一项广泛的实验研究,比较了最先进的重新采样策略的性能及其对多种学习算法和新性能指标的影响;
- 分析了数据集特征对模型预测性能的影响。
基本概念和分类方法
相关性函数
Ribeiro 提出相关性函数(φ:Y→[0,1])确定数据集中实例相关性,通过相关性值确定正常和罕见实例。Ribeiro 和 Moniz 使用分段三次埃尔米特插值多项式 pchip 和三次样条方法展示了相关函数,然而三次样条插值不能提供对函数的精确控制,它不能将关联函数限制在指定的 [0,1] 区间尺度内。pchip 方法纠正了这一限制,在控制点上使用合适的导数,从而确保了正性、单调性和凸性等特性。
相关性函数 φ 是使用分段立方 Hermite 插值多项式 pchip 在一组控制点上计算的,如下伪代码所示。算法接收控制点 S 及其各自的相关值 ψ(yk) 和导数 ψ'(yk) 作为输入,条件 y1<y2<…<ys 确保数据点按其 y 值升序排列。因此该算法为每个区间 [yk, yk+1] 生成一个单独的 ψ(y) 多项式,其中变量 k 表示输入集 S 个控制点的指数。

控制点可以根据领域知识定义或由自动化的方法提供。根据领域知识定义的方法依赖于专业的先验知识,然而这些知识往往是不可用的或不存在的,因此有必要采用一种自动确定控制点的方法。
本文采用 Ribeiro 提出的方法来自动定义控制点,方法基于 Tukey 的箱线图,用于通过其五个汇总统计数据显示数据集的分布:相邻限值 adjL 和 adjH、第一个四分位数 Q1、第三个四分位数 Q3 和中位数 Y~。对相邻值(adjL, adjH)赋予最大相关性 1,并且赋予中位数的相关性值等于 0,所有控制点初始化为导数 ψ'(yk) 等于0。

下图展示了 fuelCons 数据集的 pchip 算法产生的相关性函数,接近中位数的点的相关性可以忽略不计,远离中位数并接近 adjL 或 adjH 的点具有最大的相关性。
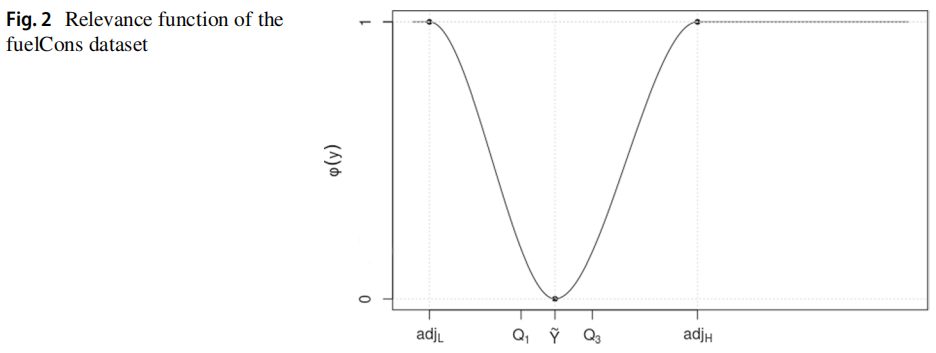
插值生成一个穿过控制点的函数,其中一个主要目标是学习数据点的正确斜率,使得插值是单调的。check_slopes 方法确保当控制点为最大值或最小值时导数为零,如下伪代码所示。

用户自定义的相关性阈值 tR 将数据划分为稀有 DR 值和正常 DN 值。给定一个数据集 D,集合 DR 和 DN 被定义为:DR={⟨x, y⟩∈D∶φ(y)≥tR} 和 DN={⟨x, y⟩∈D:φ(y)<tR}。
分类方法
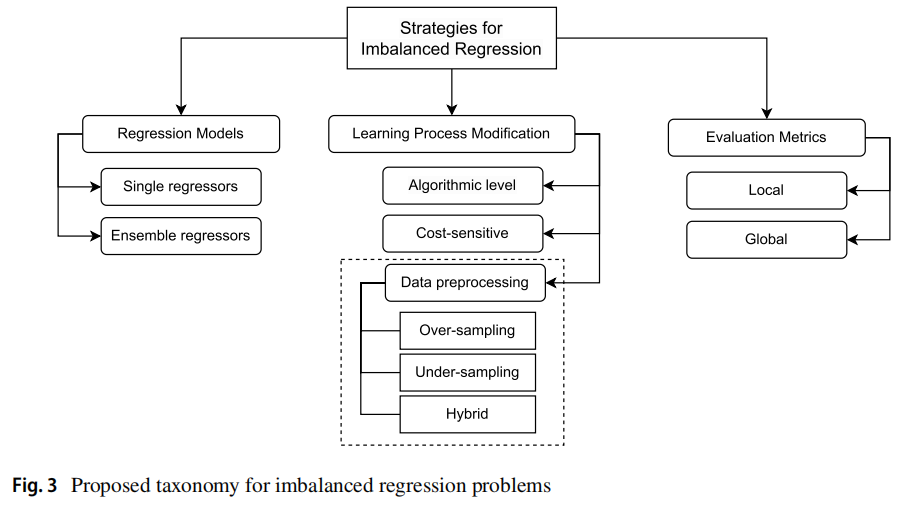
本文将不平衡回归的相关工作分为三组。第一组策略包括回归模型,第二组描述了辅助不平衡回归学习的额外策略。第三组由评估指标组成,分为局部组和全局组:
- 局部指标需要一个相关性阈值来区分极值并进行局部评估,相关性评分低于阈值的情况将被忽略。
- 全局指标不需要相关性阈值,可以在考虑所有示例的情况下进行全局评估。
分类的情况如下图所示,数据预处理是本文的重点。
不平衡回归算法
MLPRegressor、SVR 和 CART 等回归模型可能由于不平衡数据集上表现不佳,此时需要利用其他技术如数据预处理、代价敏感学习、集成学习,或修改算法以解决问题。不平衡回归集成算法的相关研究包括:
| 论文 | 发表年份 | 核心思想 |
|---|---|---|
| Rebagg: Resampled bagging for imbalanced regression. | 2018 | 将多种不平衡回归的数据重采样策略(随机欠采样、随机过采样、SmoteR)与 BAGGing 相结合 |
| Smoteboost for regression: Improving the prediction of extreme values. | 2018 | 在 boosting 算法中包括 SmoteR 重采样步骤 |
| Evaluation of ensemble methods in imbalanced regression tasks. | 2017 | 对现有集成方法在不平衡数据集的回归任务中的性能进行研究 |
在算法层面的改进,有如下相关工作:
| 论文 | 发表年份 | 核心思想 |
|---|---|---|
| Delving into deep imbalanced regression. | 2021 | 通过核分布来软化特征在目标和空间中的分布,从而有利于近目标之间的相似性。 |
| Utility-based regression. | 2011 | 基于代价敏感学习设计了一组从不同回归树中提取的规则的方法。 |
| Density-based weighting for imbalanced regression. | 2021 | 在代价敏感方法的基础上提出了一种基于密度的加权方法,为罕见实例分配更高的权重 |
处理不平衡回归问题的最常用方法之一是重采样,它的一个优点是可以结合任何模型,不会影响其可解释性(Pre-processing approaches for imbalanced distributions in regression.)。不平衡回归重采样算法的相关研究如下,各种重采样策略都基于同样的原则:减少常见的实例和/或增加罕见的实例。
| 论文 | 发表年份 | 核心思想 |
|---|---|---|
| Smote for regression. | 2013 | SmoteR 在回归问题的基础上进行了:罕见实例的定义、合成实例的生成、合成实例的目标值的定义。 |
| Geometric smote for regression. | 2022 | Geometric SMOTE 沿着连接两个现有实例点的线生成合成数据点。 |
| Pre-processing approaches for imbalanced distributions in regression. | 2019 | 提出随机过采样、引入高斯噪声、加权相关度组合策略 WERCS。 |
| Distsmogn: Distributed smogn for imbalanced regression problems. | 2022 | 提出了一个分布式版本的 SMOGN,称为 DistSMOGN。 |
| Chebyshev approaches for imbalanced data streams regression models. | 2021 | 引入了基于 Chebyshev 不等式的两种采样策略 ChebyUS 和 ChebyOS |
评估指标
当需要关注目标变量的罕见值的准确性时,一些指标(如 MSE)可能会有误导性(Resampling approaches to improve news importance prediction.)。本文给出一个例子展示 MSE 的局限性,如下表所示。对于 FuelCons 数据集中的 10 个示例,给出 M1 和 M2 两个模型的假设预测,True 行表示实例的真实目标,φ 行是实例的相关性值。可见 M1 对不太相关的实例产生更准确的预测,而 M2 对更相关的示例产生更好的预测,但如果使用 MSE 进行评估则它们之间的差异不明显。
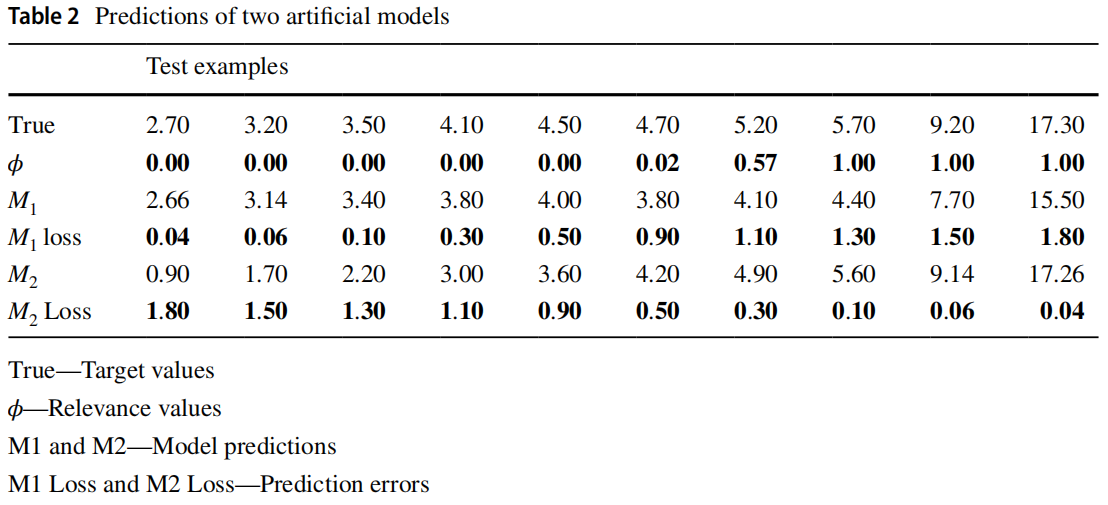
其他指标认为每个实例都有一个特定的相关分数,例如回归问题的 Precision、Recall 和 F1。Ribeiro 和 Moniz(Imbalanced regression and extreme value prediction.)提出了专门为不平衡回归设计的的平方误差相关面积 SERA 指标,该指标旨在评估模型对极端值预测的性能,同时对模型偏差具有鲁棒性。下表给出了上述例子的 MSE、F1 和 SERA,综合来看 M2 是最好的模型。

不平衡回归的 Precision、Recall 和 F1 需要定义一个相关性阈值来确定极端值,低于阈值的实例将被忽略。这些指标使用了基于效用程序框架的概念,预测值 y^ 的效用值根据数值预测的成本和收益的概念计算,效用函数的公式如下,其中 y^ 为预测值,y 是实际值。

效用由 y^ 的预测收益 Bφ(y^, y) 与成本 Cpφ(y^, y))之差给出,收益定义为实际值相关性的比例:φ(y)⋅(1−ΓB(y^, y)),其中 ΓB(y^, y) 为有界损失函数,如公式 5 所示。预测值的损失的形式如公式 6 所示,公式 5 的方程定义的损失函数的取值范围为 0~1。
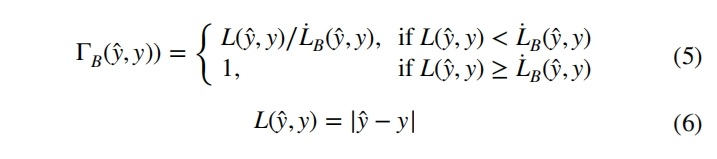
如公式 6 所示的 L 是标准损失函数,公式 7 定义的 L`B 是效益阈值函数,它用于标识预测值不再提供效益的点。

其中 bΔγ(y) 是最大容许损失,由公式 8 定义。计算每个凸点 i 的最大容许损失。凸点是指域的间隔,表示为 B∈Y。b- 是目标变量在达到其最大值之前达到最小相关性时的平均值,b 是目标变量达到最大相关性时的平均值。这样定义的原因是:当从一个凸点 bi 内最相关的值过渡到另一个凸点时,该函数取决于关于目标变量的最小差异。
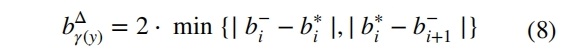
目标变量的最小差异可能对模型性能产生两种影响:
- 积极方面:它可以通过关注预测必须非常接近实际值的区域来使模型更加准确,当您需要数据特定部分实现高的精度时有益。
- 消极方面:模型可能会过于关注训练数据,使其对异常数据点敏感,从而导致过拟合。
这意味着当处理“窄”颠簸时,对预测误差的敏感性会提高。对于更大的颠簸将更倾向于认为实际值和预测值之间的较大差异是可以接受的。下图展示了针对相关函数获得的凸点分区和每个凸点的最大容许损失,定义的相关函数有四个完全不同的凸起。
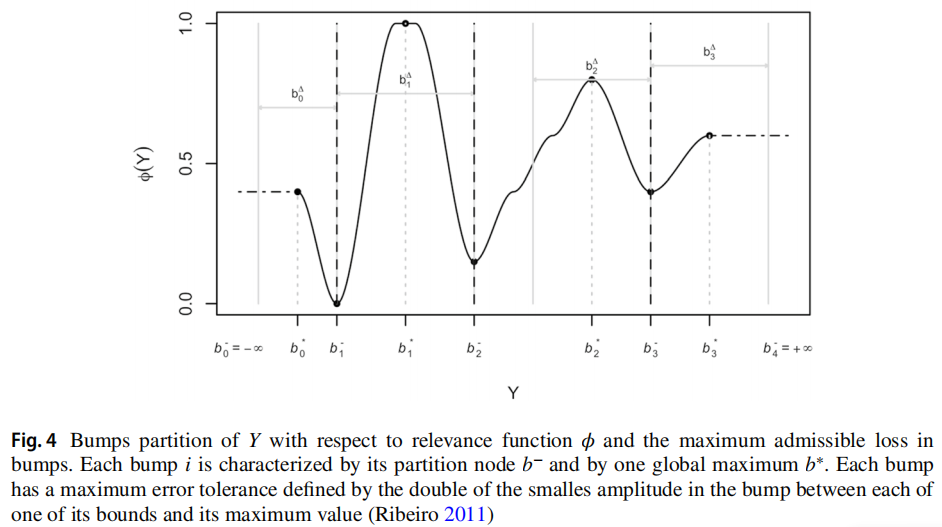
L``B(̂y, y) 的定义如公式 9 所示:
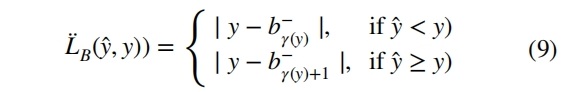
代价由加权相关性 φp(y^, y) 的均值给出,如公式 10 所示。其中参数 p 用于定义两个相关性之间的权重,ΓC(y^, y) 是尺度 [0, 1] 中的有界损失函数。此处的直觉是平衡预测值的重要性和效用函数的实际值。

使用效用函数计算的 Precision、Recall、F1 指标分别由公式 14、15、16 定义。实际值 yi 的相关性系数由 φ(yi) 定义,φ(y^i) 是预测值的相关性系数,tR 是定义的相关性阈值,Upi(y^i, yi) 是效用函数。

上述指标需要定义一个特定的相关性阈值,并且不考虑低于模型评估阈值的实例。为了解决这个问题,Ribeiro 和 Moniz(Imbalanced regression and extreme value prediction.)提出了 SERA 指标,该指标不仅能评估模型的有效性,还能用于优化模型以提高对罕见和极端实例的预测。此度量不需要定义相关性阈值,执行的是全局评估。根据相关函数 φ∶Y→[0,1]得到与切割 t 相关的平方误差相关性,考虑一个基于切割 t 形成的子集 Dt={⟨x, y⟩∈D∶φ(y)≥t},如公式 17 所示:
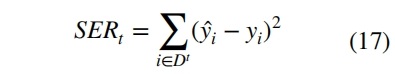
平方误差相关面积 SERA 表示曲线 SERt 下的面积,由公式 18 的积分得到。SERt 曲线提供了在不同相关性截止值下域内预测误差的广泛视图,曲线下面积 SERA 越小说明模型越好。
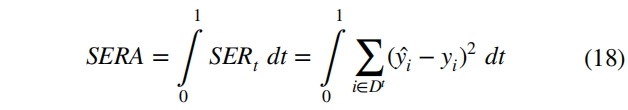
重采样算法
处理不平衡数据集的最常见方法是通过重采样改变数据分布以平衡目标值,主要包括欠采样、过采样和混合采样。本文忽略了没有公开源码、没有良好的可复现性、不频繁使用的研究,对广泛使用的不平衡回归重采样算法进行了归纳和分析。
SmoteR
SmoteR 算法如下伪代码所示,和其他解决不平衡回归问题的方法一样,它需要一个相关函数 φ(y) 和一个相关阈值 tR。该算法首先删除被认为是正常的不相关的实例,然后基于最相关的实例生成合成实例。生成过程基本上遵循 SMOTE 的思想,对于用户确定的过采样比确定合成实例的数量,然后对每个罕见实例计算 K 个最近邻居。然后执行多次迭代随机挑选集合中的一个实例,通过插值来产生多个合成实例。如果特征为是数值型,则计算两个实例的特征差值,将此差值乘以 0~1 之间的随机数与原始数值相加。如果不是数值型特征,则在实例的特征值之间随机选择。
- Torgo L, Ribeiro R P, Pfahringer B, et al. Smote for regression[C]//Portuguese conference on artificial intelligence. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013: 378-389.
随机过采样
随机过采样首先选择高于相关性阈值 tR 的实例作为待过采样的候选实例,并分为多个 Bin。然后将 Bin 中的罕见实例根据生成的实例的数量进行随机采样,并将重复的实例添加到新构造的数据集。该算法不需要通过特殊处理来生成目标值,生成的实例与现有的罕见实例相同。
- Branco P, Torgo L, Ribeiro R P. Pre-processing approaches for imbalanced distributions in regression[J]. Neurocomputing, 2019, 343: 76-99.
随机欠采样
随机欠采样首先使用相关性函数和相关性阈值 tR 来定义数据集中的罕见实例,低于 tR 的实例是作为被删除的候选。接着根据用户设置的欠采样率,对于常见实例集的每个 Bin 基于其基数和欠采比计算从中移除的样本的数量,得到用于组成最终数据集。
- Torgo L, Ribeiro R P, Pfahringer B, et al. Smote for regression[C]//Portuguese conference on artificial intelligence. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013: 378-389.
- Branco P, Torgo L, Ribeiro R P. A survey of predictive modeling on imbalanced domains[J]. ACM computing surveys (CSUR), 2016, 49(2): 1-50.
引入高斯噪声
引入高斯噪声方法首先根据相关性函数 φ(y) 和相关性阈值 tR 将数据集划分为常见实例集和罕见实例集。常见实例集使用随机欠采样处理,罕见实例集使用随机过采样处理,过采样过程将对被选择的实例的特征和目标变量值引入一个小的扰动来生成新实例。如果特征是数值型,则对其添加基于正态分布的随机扰动,如果是非数值型的特征,则以其值的频率成比例的概率进行生成。
- Lee S S. Regularization in skewed binary classification[J]. Computational Statistics, 1999, 14: 277-292.
- Lee S S. Noisy replication in skewed binary classification[J]. Computational statistics & data analysis, 2000, 34(2): 165-191.
引入高斯噪声的 SmoteR
SMOGN 将随机欠采样与 SmoteR、引入高斯噪声方法相结合,目的是通过使用更保守的策略,只引入高斯噪声来生成新的案例,从而避免 SmoteR 中罕见实例和邻居不够接近时生成异常实例的潜在风险。同时 SMOGN-SG 还希望为数据集增加多样性,仅使用高斯噪声方法实现不了这个目的。因此 SMOGN 中当罕见实例和所选邻居足够接近(即距离低于设置的阈值),SMOGN 使用 SmoteR 生成新实例,反之则使用引入高斯噪声方法生成新实例。
- Branco P, Torgo L, Ribeiro R P. SMOGN: a pre-processing approach for imbalanced regression[C]//First international workshop on learning with imbalanced domains: Theory and applications. PMLR, 2017: 36-50.
基于加权相关性的组合策略
基于加权相关性的组合策略 WERCS 结合了欠采样和过采样,该方法取决于相关性函数,不需要设置相关性阈值。实例的相关性越高,其被选择用于生成新实例的概率就越高,同理与欠采样的权重与相关性值成反比。常见与较低的相关性值相关联的实例被移除的概率更高,基于其生成实例的概率更低。该算法的优点是不需要先验设置相关性阈值,因此每个示例都有可能参与过采样或欠采样过程,同时该方法消除了对相关性阈值 tR 的依赖。
- Branco P, Torgo L, Ribeiro R P. Pre-processing approaches for imbalanced distributions in regression[J]. Neurocomputing, 2019, 343: 76-99.
上述方法的运行效果
下图展示了对 FuelCons 数据集使用不同重采样方法结果,可视化时使用了目标值 Y 和特征 X30。所有算法都将数据集采样至平衡,除了 WERCS 算法都将 tR 设置为 0.8,其余参数采用默认值。各个算法的效果如下:
- SmoteR 选择最近邻实例来生成新实例,当时仍然存在实例距离太远以及生成的实例与原始实例不太对应的风险,如图 5b 的左下方所示。生成的样例与原始样例相差甚远。
- 高采样比的随机过采样可能会导致过拟合,该方法生成的数据集并没有表现出多样性,没有很好地覆盖特征空间。同时还可能在数据集中添加许多重复的实例,导致训练时间显著增加。
- 随机欠采样由于去除训练数据,可能会丢失部分有意义的信息。
- 引入高斯噪声通过添加正态分布的噪声进行过采样,生成了与原始数据集不同的实例,能提高多样性并有助于减轻过拟合。
- 虽然 SMOGN 的目标之一是生成和原始示例不同的实例来规避 SmoteR 的缺点,但图 5f 中的效果与 SmoteR 的分布仍然存在相似性。相比引入高斯噪声方法,SMOGN 的实例的多样性明显更高。
- WERCS 方法欠采样后的绿色数据点被分成两组,此时会导致模型的学习过程更为复杂,WERCS 的过采样效果与随机过采样类似。

实验研究
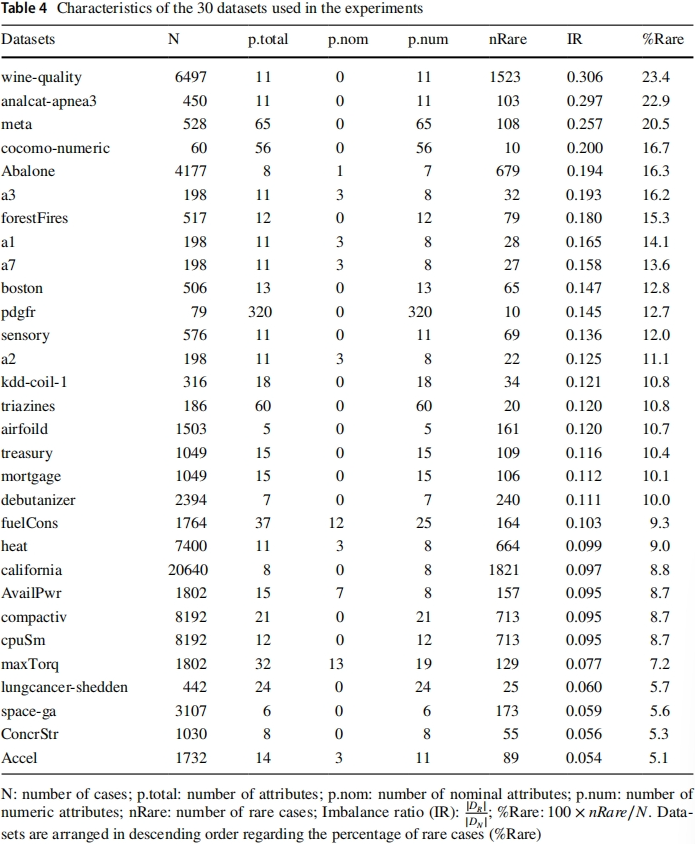
数据集和实验设置
实验使用如下表所示的 30 个不平衡回归数据集,这些数据集中的不平衡程度由相关性函数定义,本文参考现有研究将 tR 设置为 0.8。每个数据集使用两次 10 折交叉验证,对实验结果的计算平均值和标准差。采用 2 折嵌套交叉验证优化重采样的超参数,优化目标为 SERA 指标进行优化。
实验使用的模型包括:Bagging(BG)、Decision Tree(DT)、Multilayer Perceptron(MLP)、Random Forest(RF)、Support Vector Machine(SVM) 和 XGBoost(XG),模型使用默认超参数。使用的重采样技术包括:SmoteR(SMT)、随机过采样(RO)、随机欠采样(RU)、引入高斯噪声(GN)、SMOGN(SG) 和加权相关性组合策略 WERCS,如下表所示。

本文使用 F1 和 SERA来评估回归模型,F1 能根据相关性阈值的定义进行局部评估,SERA 指标能评估模型在预测极值方面的有效性,并能在不需要阈值的情况下进行全局评估。
实验结果
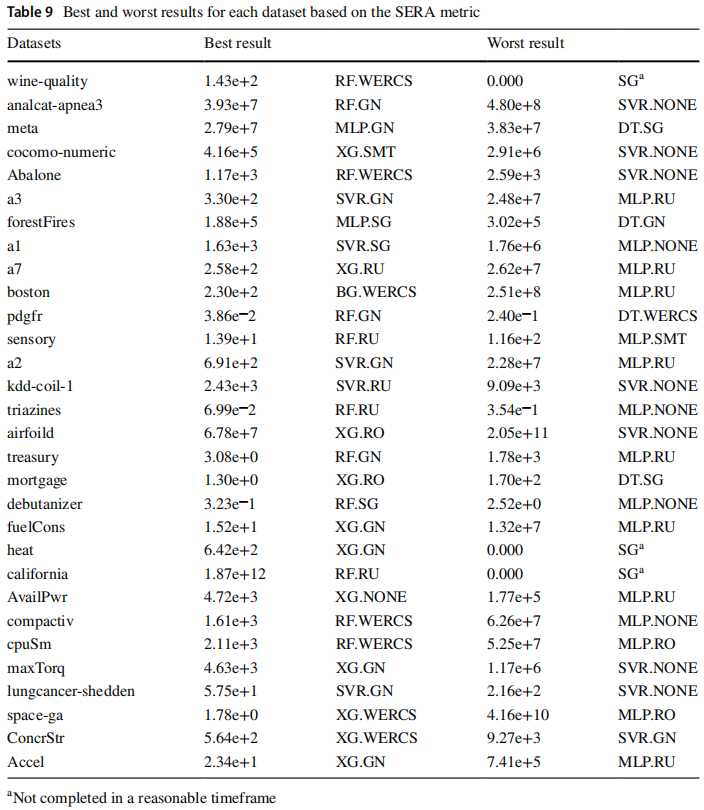
以下两张表展示了每种算法获得最高 F1 和 SERA 指标的次数。当出现平局时,n 个平局的方法将各自得到 1/n 分。表中的每一行加起来为 30,即数据集的数量。F1 指标上性能最好的是 RO 和 GN,SERA 指标上性能最好的是 GN 和 WERCS。最佳策略的选择还取决于所使用的回归模型,不同重采样策略在数据集之间没有普遍的一致性。

以下两张表分别展示了 F1 和 SERA 的最佳和最差结果,结果表明大多数数据集在最佳学习模型和重采样方法上具有不同的偏好。没有进行预处理的 SVR 和 MLP 是在这两个指标上性能最差的组合,因此应用这些模型之前对数据集进行平衡至关重要,同时获得良好的结果取决于重采样方法和模型的正确选择。SG 策略不能在规模较大的 california、heat、wine-quality 数据集上运行,这突出了超参数优化的在实践中的困难。

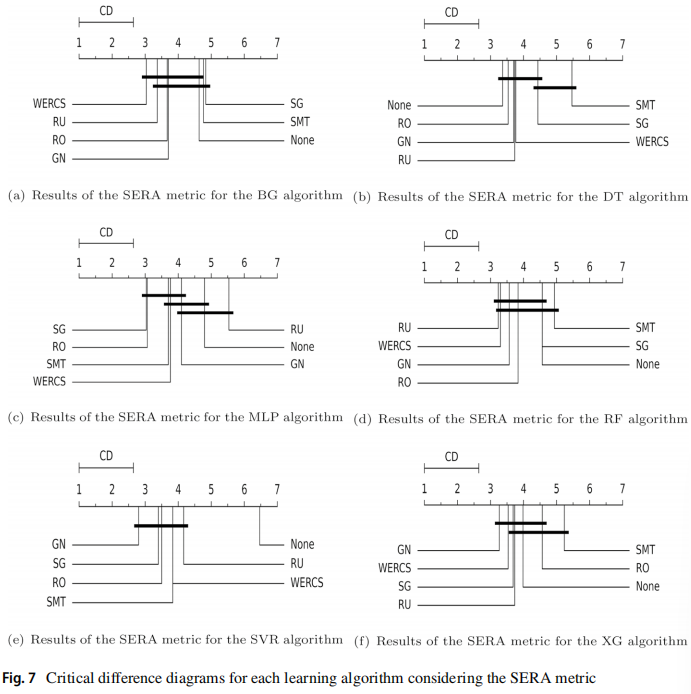
使用 Friedman 检验和 Nemenyi 后继检验,F1 指标的结果如下图所示,可见从全局来看重采样可以显著提高回归器的性能。RO 方法获得了最佳结果,并且相对于未经任何预处理的 F1 差异最显著,大多数情况下 SMT、SG、RU 的结果最差。
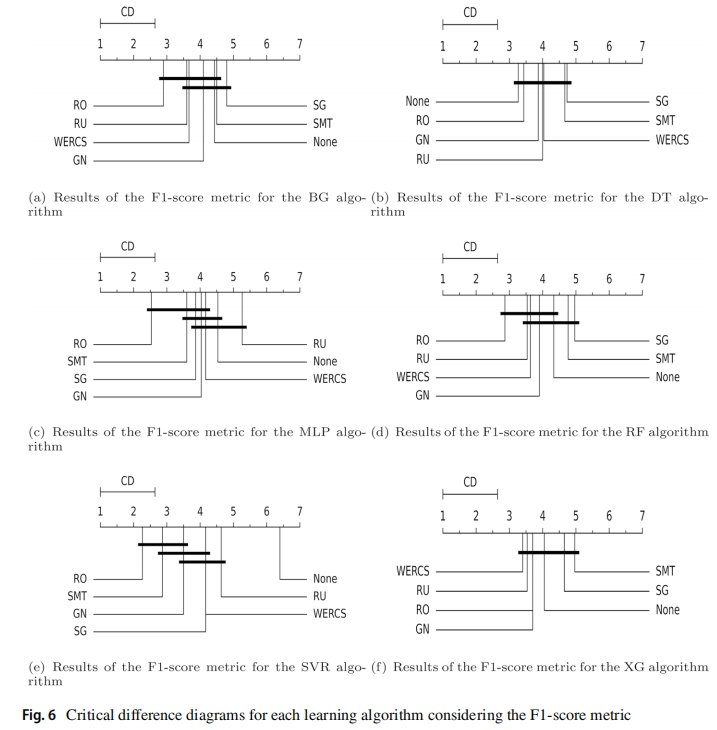
SERA 指标的结果如下图所示,可见使用 GN 方法获得的最佳结果最多,其次是 WERCS。当不使用重采样策略时,DT 在原始数据集上取得了更好的结果,RF 和 XGBoost 获得了比单一模型更好的结果。SVR 和 MLP 得到了最差的结果,特别是在没有使用预处理技术的情况下,可见学习模型受目标分布不平衡的影响很大。
下图展示了每种方法训练实例的增加/减少的百分比,RO、GN 和 WERCS 的性能较优效果。GN 和 WERCS 分别为 1.28% 和 2.83% 占比较小,相反 RO 增加了1421.1%。因此实例数量对结果的影响尚不清楚,但使用过采样方法将显著增加训练集规模,会对训练时间造成影响。

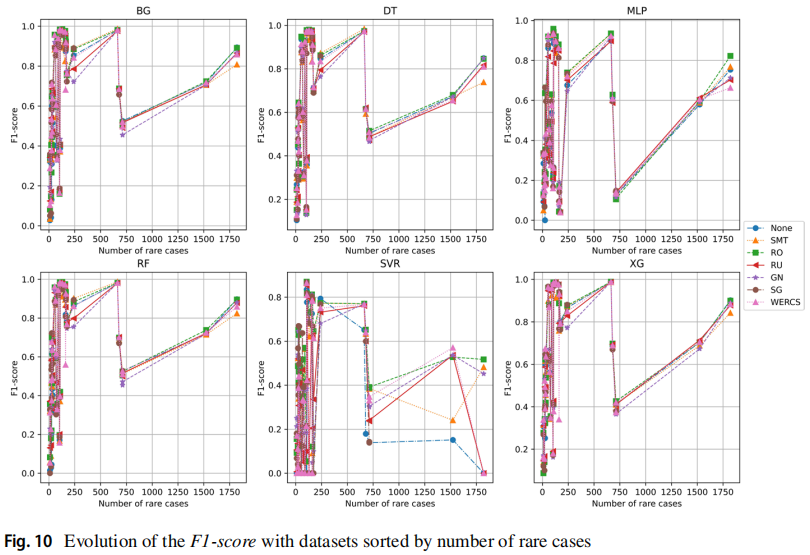
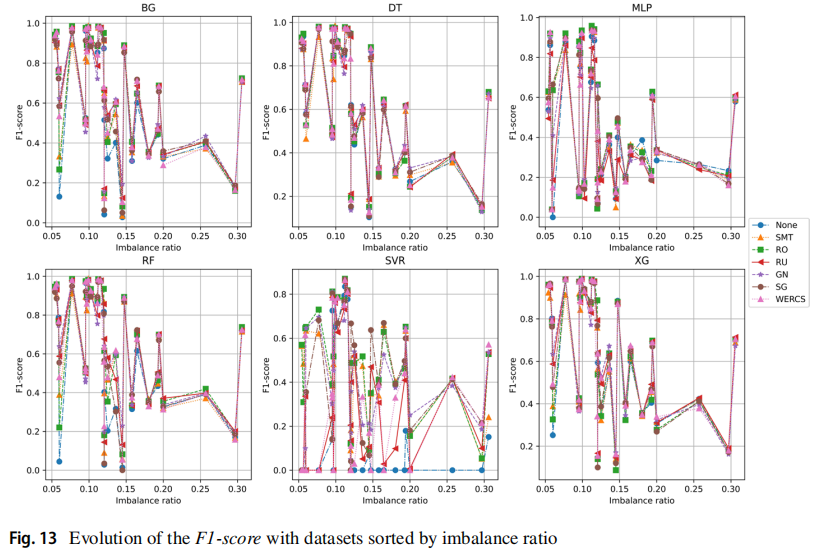
本文还评估了数据集的特性对模型性能的影响,包括:罕见实例百分比、罕见实例数量、数据集大小、特征数量和不平衡比。实验指标使用 F1,实验结果的可视化中的每个方框代表一个回归模型,每个点代表一个特定的数据集,每条线代表一个重采样方法。下图所示的结果按照罕见实例百分比递减的顺序排列,从结果可见罕见实例百分比与模型性能的关系尚不清楚。

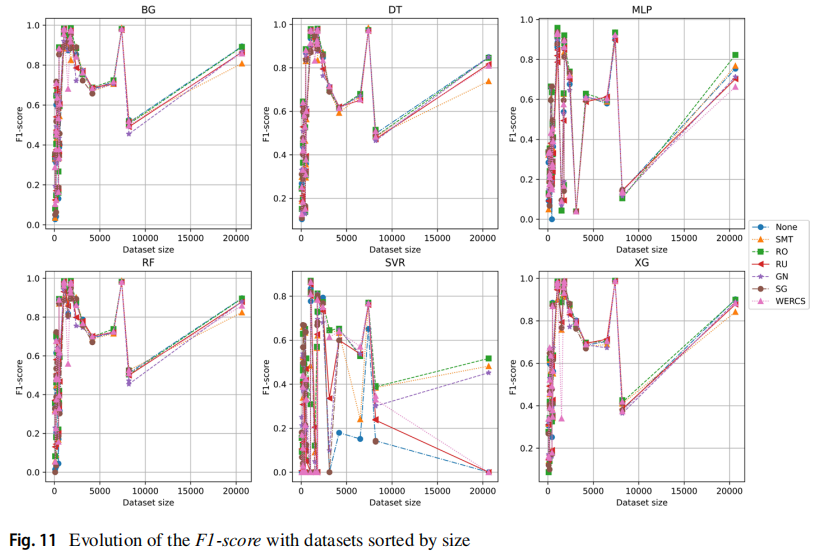
以下两张图分别按照罕见实例的数量和数据集的大小排列,可见罕见实例数量较少的、规模较小数据集非常困难。
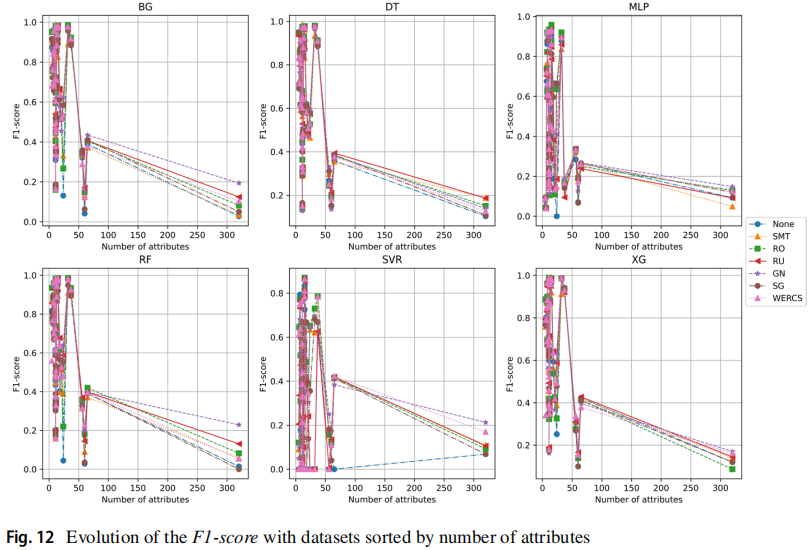
下图按照数据集的特征数量进行排列,在某些情况下特征较少的数据集表现出更好的性能。
下图按照不平衡比例进行排序,可见模型在具有较高不平衡比的数据集上的学习更为困难。
经验总结
- 是否值得使用重采样策略:对于使用的两个评估指标,使用的四种重采样方法比不使用重采样获得更优性能的次数更多,通过 Nemenyi 事后检验可见应用重采样方法在统计上性能更好,因此使用(某些)重采样策略是有利的。
- 哪种重采样方法对预测性能影响最大:在 F1 指标上 RO 和 GN 对模型起到了积极影响,SERA 指标上 GN 和 WERCS 的性能最佳。根据假设检验的结果 GN、RO 和 WERCS 的效果最好,SMT、SG、RU 的效果最差。
- 最佳策略的选择是否取决于数据集、学习模型和使用的指标:大多数数据集对于最佳回归模型和重采样方法的组合有不同的偏好,对于回归模型来说,使用不同的重采样方法可以达到更好的结果。在不同的评估指标方面,GN 是一个较好的重采样策略,但两种评估指标之间也存在分歧。
- 每个重采样方法产生的实例数量会影响结果吗:GN、RO 和 WERCS 在训练集中增加/减少的百分比不同,因此实例数量对结果的影响尚不清楚。但是从训练时间来看,使用过采样可能不是有利的。
- 数据的特征(罕见实例百分比、罕见实例数量、数据集大小、特征数量和不平衡比)是否影响模型的预测性能:罕见实例的百分比对结果没有明显的影响。罕见实例较少的数据集越小对应的难度越大。模型在特征较少的数据集中表现出优异的性能。不平衡比越大,回归模型面临的挑战就越显著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号