

数据挖掘 ID3
本文讲的是数据挖掘中的ID3,这个有很多人做了,我也没有说什么改善,只是要考试,用我考试记录的来写,具有很大主观性,如果看到有觉得不对或感觉不好,请关掉浏览器或和我说,请不要生气或发不良的言论。
决策树使用属性划分
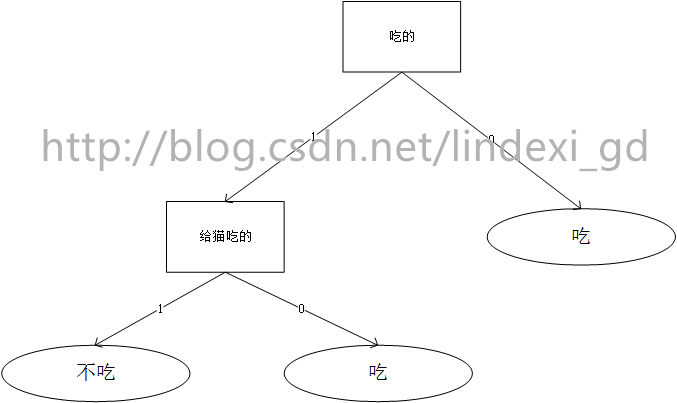
那么简单的,我有一只猫,不是吃的东西他就回去吃,吃的东西中,不给猫吃的,他就会吃。那么我们拿出一个东西,他就会根据构建的判断
ID3算法是由Quinlan首先提出的,该算法是以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。
ID3就是判断那个属性作为节点,例如上面说的,我们有属性 吃的、给猫吃的,两个属性,ID3判断那个属性作为第一个节点,选取完了第一个节点吃的,就从剩下的属性选取。
信息熵
ID3判断是用信息熵,信息熵就是主要是指信息的混乱程度,变量的不确定性越大,熵的值也就越大,这是香农提出,熵的公式可以表示为:
其中
信息不确定大,熵越大,所以把它分离作为节点得到信息多,如果一个熵为0,那么就不用分裂,表示确定,例如看到水100度,得到结果他沸在常温下
信息增益
信息增益(Information gain) 指的是划分前后熵的变化,可以用下面的公式表示:
其中,A表示样本的属性,
那么看到这觉得不知道我在说什么,简答例子
我们先用别的大神例子,假如还是我们那个用某人是否网球天气
| Day | Outlook | Temperature | Humidity | Wind | PlayTennis |
| D1 | Sunny | Hot | High | Weak | No |
| D2 | Sunny | Hot | High | Strong | No |
| D3 | Overcast | Hot | High | Weak | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | Normal | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Strong | Yes |
| D8 | Sunny | Mild | High | Weak | No |
| D9 | Sunny | Cool | Normal | Weak | Yes |
| D10 | Rain | Mild | Normal | Weak | Yes |
| D11 | Sunny | Mild | Normal | Strong | Yes |
| D12 | Overcast | Mild | High | Strong | Yes |
| D13 | Overcast | Hot | Normal | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
未知 Outlook=sunny, Temperature=cool,Humidity=high,Wind=strong
那么我们根据现在数据
计算信息熵
我们yes存在9,no存在4,根据
对每个属性计算,OUTLOOK属性中,有3个取值:Sunny、Overcast和Rainy,样本分布情况如下:
类别为Yes时,Sunny有2个样本;类别为No时,Sunny有3个样本。
类别为Yes时,Overcast有4个样本;类别为No时,Overcast有0个样本。
类别为Yes时,Rainy有3个样本;类别为No时,Rainy有2个样本。
接着对所有属性计算
信息增益
选出最大OutLook,然后把OutLook做节点,依靠不用属性分为多个集合,再对每个集合计算信息增益得到节点,直到不能再分。
我们得到决策树就可以把我们要分的属性依靠决策树来分,这个方法已经很老,现在比较少用
参考:http://shiyanjun.cn/archives/417.html

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。欢迎转载、使用、重新发布,但务必保留文章署名林德熙(包含链接:http://blog.csdn.net/lindexi_gd ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请与我联系。
博客园博客只做备份,博客发布就不再更新,如果想看最新博客,请访问 https://blog.lindexi.com/
如图片看不见,请在浏览器开启不安全http内容兼容

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。欢迎转载、使用、重新发布,但务必保留文章署名[林德熙](https://www.cnblogs.com/lindexi)(包含链接:https://www.cnblogs.com/lindexi ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请与我[联系](mailto:lindexi_gd@163.com)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号