递归、模块、包day14
今日学习总结:
一、函数递归:是指重复直接或间接调用函数本身。这是一种函数嵌套调用的表现形式。
直接调用:是指在函数内,直接调用函数本身
python中有递归默认深度998: 限制递归次数:1000
num=1 def func(): global num print('form word',num) num+=1 func() func() 结果: form word 1
。。。。。
form word 994 form word 995 form word 996 form word 997 form word 998Traceback (most recent call last): File "G:/正课/day13/13.py", line 166, in <module> func() File "G:/正课/day13/13.py", line 165, in func func
间接调用:是指两个函数之间相互调用,间接造成递归
num1=1 num2=1 def foo(): global num1 print('from foo',num1) num1+=1 goo() def goo(): global num2 print('from goo',num2) num2+=1 foo() 结果:
from foo 1
from goo 1
。。。。。。。 from foo 499 from goo 499Traceback (most recent call last): File "G:/正课/day13/13.py", line 183, in <module> foo() File "G:/正课/day13/13.py", line 175, in foo goo
ps:单纯的调递归用时候,没有任何意义
要想递归有意义,必须遵循两个条件:
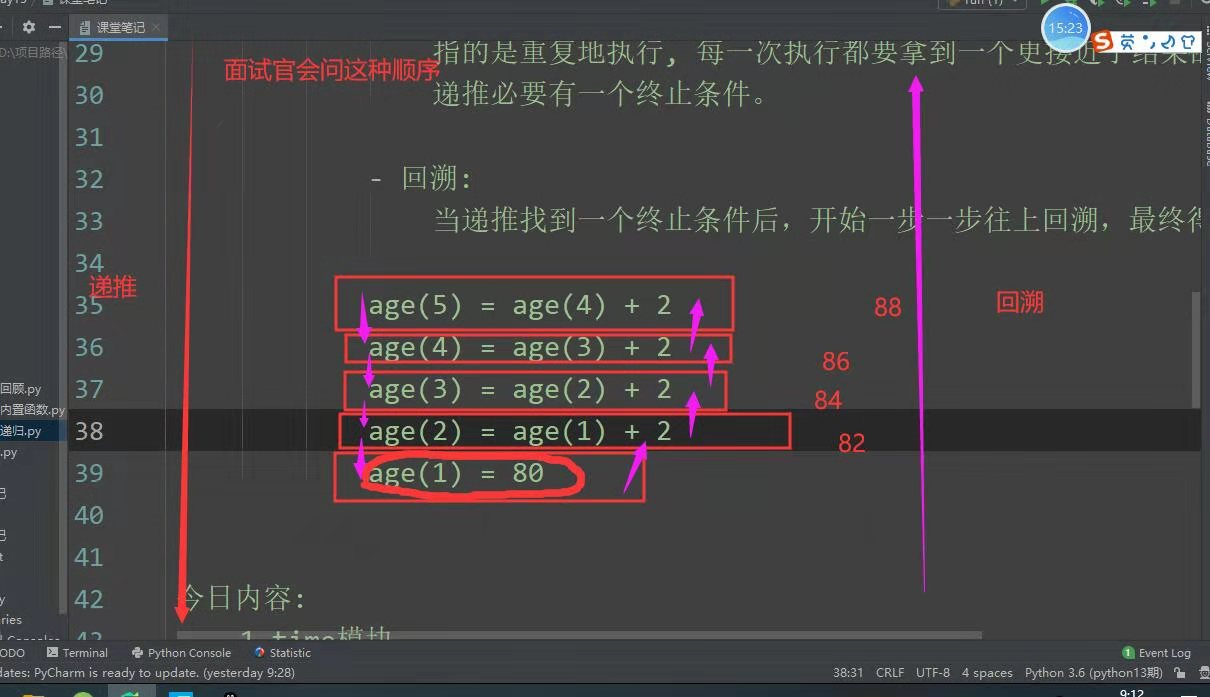
1.递推:指的是重复的执行,每一次执行都要拿到一个更接近于结果的结果,递推必需有一个终止的条件。
2.回溯:当递推找到一个终止条件后,开始一步一步往上回溯
例子:
''' 分析: age5 == age4 + 2 age4 == age3 + 2 age3 == age2 + 2 age2 == age1 + 2 age1 == 18 # 回溯终止的结果 result = age(n - 1) + 2 ''' def age(n): if n == 1: return 18 return age(n - 1) + 2 # 这里写return才能实现递推 res = age(5) print(res) #结果:26
PS: 但是在每一台操作系统中都会根据硬盘来设置默认递归深度。
获取递归深度:
sys.getrecursionlimit()
import sys print(sys.getrecursionlimit())
结果:1000
设置递归深度:
sys.setrecursionlimit(深度值)
import sys sys.setrecursionlimit(2000) print(sys.getrecursionlimit())
结果:2000
二、模块:是一系列功能代码的结合体,本质上是一个个.py文件
1.模块的来源:
01、python内置的模块。比如:sys time os tutle
02、第三方的模块。(别人写的)。比如:requests
03、自定义的模块。(自己写的)。比如:自己定义的demo.py文件
2.模块的表现形式:
01、使用python编写的py文件
02、编译后的共享库DLL或者C或者C++库
03、包 下面带有_init_.py的一组py文件
--包
-- _init_.py
--demo.py
--demo2.py
04、python解释器下的py文件
3.为什么使用模块
模块可以帮我们更好的管理功能代码。比如:函数
可以将项目拆分成一个个的功能,分别存放在不同的py文件(模块)中
4.怎样创建和编写模块
鼠标右键创建py文件,然后在py文件编写python代码
5、怎样使用模块
在一个文件中,通过import关键字导入模块。
ps:在使用模块时候,必须要注意的是,谁是执行文件,谁是被导入文件(被导入的模块)。模块在首次导入时,就已经固定好了,当前文件查找的顺序是先从内存中查找
6、模块在导入时发生的事情:
01.先执行当前执行文件,并产生执行文件中的名称空间。
02.当执行到导入模块的代码时,被导入的模块会产生一个模块的名称空间。
03.会将被导入模块的名称空间加载到内存中。
注意:在执行文件中导入多次相同的模块,只会加载首次导入的模块的名称空间
7、给模块起别名 用 as
import 模块 as 模块的别名
比如:import time as t
8、模块的导入方式:
01、import 模块
在执行文件中直接import导入
02、 from 包 import 模块
03、from 模块 import 函数名/变量名/类名
9、循环导入问题:
- model1.py
from model2 import name
name = 'jason'
- model2.py
from model1 import name
name = 'tank'
10、解决循环导入问题:
01.需要查找的名字放在导入模块的上方
02.在函数内部导入模块
三、包:指的是内部包含_init_.py的文件
包的作用:包是一系列模块的结合体,更好的管理模块
1.什么是包?
包是一个带有__init__.py的文件夹,包也可以被导入,
并且可以一并导入包下的所有模块。
2.为什么要使用包?
包可以帮我们管理模块,在包中有一个__init__.py, 由它来帮我们管理模块。
3.怎么使用包?
- import 包.模块名
包.模块.名字
- from 包 import 模块名
- from 包.模块名 import 模块中的名字
4.导入包时发生的事情:
1.当包被导入时,会以包中的__init__.py来产生一个名称空间。
2.然后执行__init__.py文件, 会将__init__.py中的所有名字添加到名称空间中。
3.接着会将包下所有的模块的名字加载到__init__.py产生的名称空间中。
4.导入的模块指向的名称空间其实就是__init__.py产生的名称空间中。
四、 软件开发目录规范:
注意: 每一次写项目时,都要新建一个文件夹与项目工程,必须让项目文件夹作为项目根目录。
- 项目的文件夹:
- conf:
- 用于存放配置文件的文件夹
- core:
- 核心业务代码 .py
- interface:
- 接口, 接口内写获取数据前的逻辑代码,通过后才能获取数据
- db:
- 用于存放数据文件
- lib:
- 存放公共功能文件
- log:
- 用于存放日志文件,日志用于记录用户的操作记录
- bin:
- 里面存放启动文件 / - 启动文件
-start.py
是指不在bin目录下的启动文件。
- readme.txt:
- 项目说明书, 用户告诉使用者项目的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号