大数据分析--淘宝美食产品数据分析
大数据分析--淘宝美食产品数据分析
一、选题背景
随着网络技术的不断发展,大数据技术影响着人们生活的方方面面,人们可以利用大数据技术从海量的数据中提取有价值的信息。并且现在是一个信息爆炸的时代,我们可以通过电商购物平台网站购买商品,所以说电商平台对商品信息传播的作用不可忽视。各大电商平台商品评论中携带大量信息,如果浏览大量评论会浪费很多时间,所以对评论文本关键信息整合变得尤为重要。为了选择出自己喜欢的商品,消费者需要全面的了解各个品牌、各个种类,这样会导致浪费大量的时间。若不全面的了解商品的相关信息,又会导致选择不出自己喜欢的商品。
二、大数据分析设计方案
1.主要介绍了本次设计选题的研究背景
2.主要介绍了数据挖掘的整体概述以及定义,其中包括数据挖掘的概念以及数据挖掘的主要任务。
3.主要介绍了数据采集的含义概念、方法以及在本次设计中淘宝网美食数据获取的操作过程。
4.主要介绍的是数据的预处理技术以及本次设计中的预处理过程。
5.主要介绍了在本次设计中对爬取、清洗后的数据进行可视化分析的过程。
6.主要介绍了本次设计中,运用算法模型对数据实现聚类的过程。
三、数据分析步骤
1.数据源
本设计所选取的数据来源于淘宝网站,这里我们通过数据筛选确定所要采集的数据。搜索框内输入美食后获取到相应的商品列表,爬取其商品的信息及其评论数据。
2.数据清洗
2.1商品数据预处理
读取数据
在文本采集过程中,我们利用Python爬虫技术采集到淘宝网中商品数据,并且已经把数据集命名为淘宝美食.csv,在接下来的数据预处过程中只需要从本地读取文件
![]()
数据规约
数据规约是指在不影响数据的四大特性的前提下,尽可能的精简数据,方便分析时调用数据,减少后续工作。

数据清洗
数据清洗一般是指处理数据集中的脏数据,比如一些无效值和缺失值、数据中有不需要的字符、数据不一致等。通过观察所爬取的数据,发现数据中有一些无效值和缺失值,并且有些数据中含有不需要的字符,所以可以对读取的数据进行数据清洗,根据不同的属性采取不同的数据清洗方法。

2.2商品评论数据预处理
读取数据
在文本采集过程中,我们利用Python爬虫技术采集到淘宝网中商品评论数据,并且已经把数据集命名为淘宝.csv,在接下来的数据预处过程中只需要从本地读取文件
![]()
过滤符号
利用正则表达式中的compile方法匹配商品评论数据中的特殊符号,并用sub方法去除文档中的特殊符号,只保留标题中英文、数字与汉字,以便于写入文件

去除空格和去除空值
去除空格是指去除商品评论数据文件属性article数据里的空格,即文本文档内部的空格,这里用到正则表达式sub方法对商品评论数据的空格进行替换

去除空值主要是去除当文本属性article里的值为空时,相当于删除改条记录,这里用到dropna对商品评论数据的空值进行删除

本次设计由于文本过滤、空格和空值功能写在方法clean_news_sign()、clean_news_blank()和clean_news_null()里,这需要用主函数main调用这些方法,这里把处理好的商品评论数据保存在excel里

文本分词
为了更好地处理自然语言,需要把句子转换成词语,在这里用到jieba里的cut方法实现对中文文本进行分词

去除停用词
在去除停用词之前,本地必须要有停用词词典,整理了下载了停用词词典。逐行读取停用词词典stopwords-zh,接着读取jieba分词后的商品评论数据,并把商品评论数据中的词与停用词典中的词进行比对,如果商品评论数据中的词存在本地停用词词典中,则该词为停用词,并删除该词,若不存在停用词词典,保留该词,以此循环,直到分词后的商品评论数据逐个对比完

3.大数据分析过程及采用的算法
1.word2vec模型
这里用到skip-gram下的word2vec模型,利用model.bulit_vocab()第一遍遍历语料库建立模型,利用modle.train()第二遍遍历语料库建立神经网络模型。由于建立模型的过程中需要时间,可以利用save()方法,把模型直接保留在本地

进行分类建模
建立K-means聚类模型,这里利用参数n_clusters把文本数据聚成四类;利用fit()方法把进行word2vec词向量处理的数据进行训练,并得到k-means训练模型里的数据标签。因为训练的为文本数据,这里要得到文本分类结果,从而对商品进行分析

显示分类数据
获取K-means模型里词向量所属类别,根据其类别并利用字典的形式保存分类结果,并截取分类结果的前十个词语对商品进行分析。
输出结果:

4.数据可视化
4.1商品数据可视化
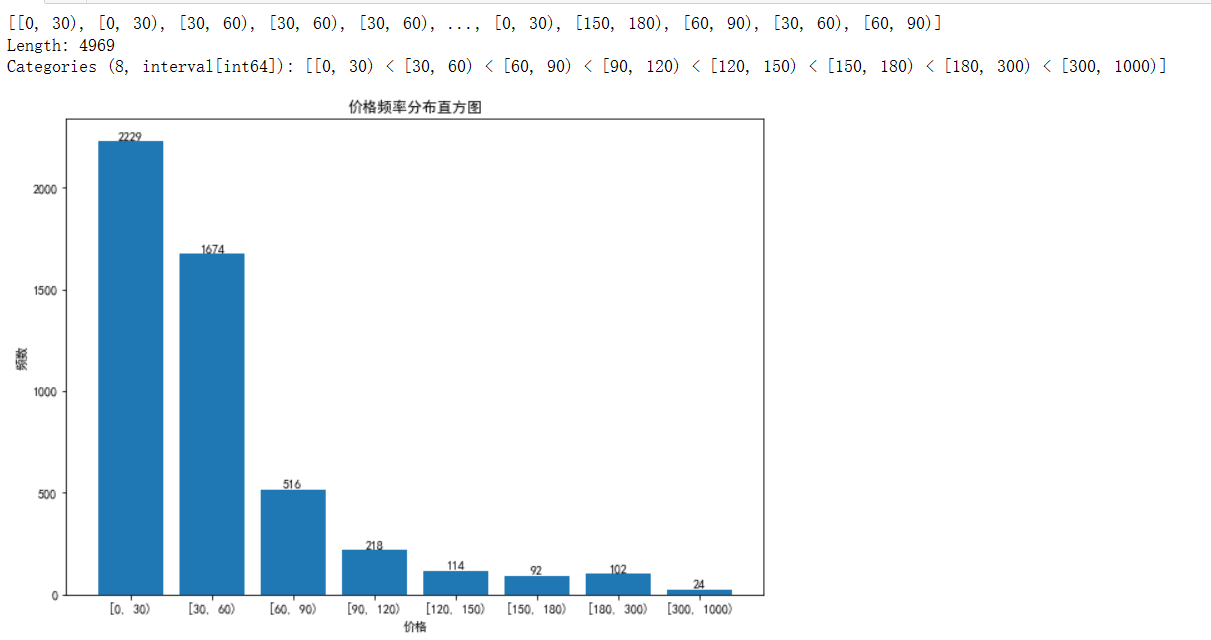
4.1.1商品价格数据分析
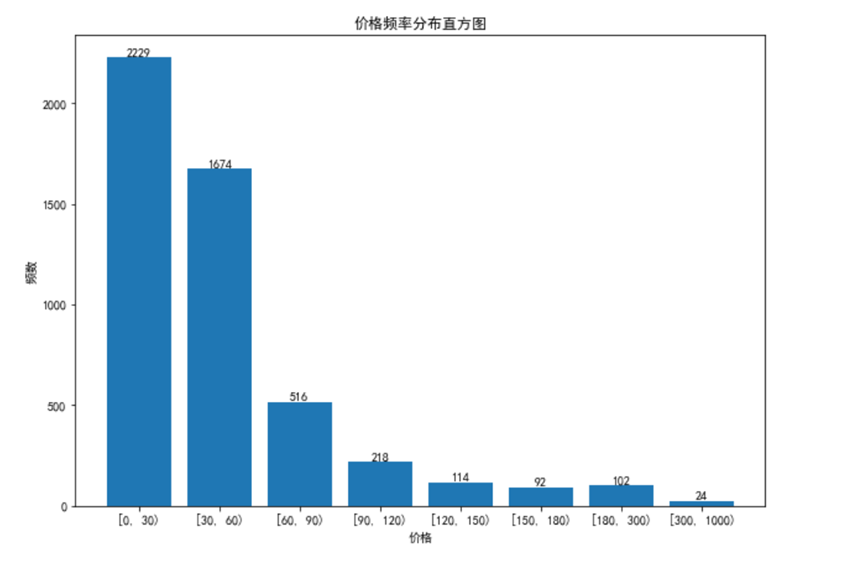
美食商品在0-30元的价格区间占比最大,说明消费者选择美食产品大部分是想选择产品价格低的,多选几种款式。美食商品在300-1000元的价格区间占比较最低,这个价格段的产品大部分是消费者买来作为礼品,并不是自己吃。
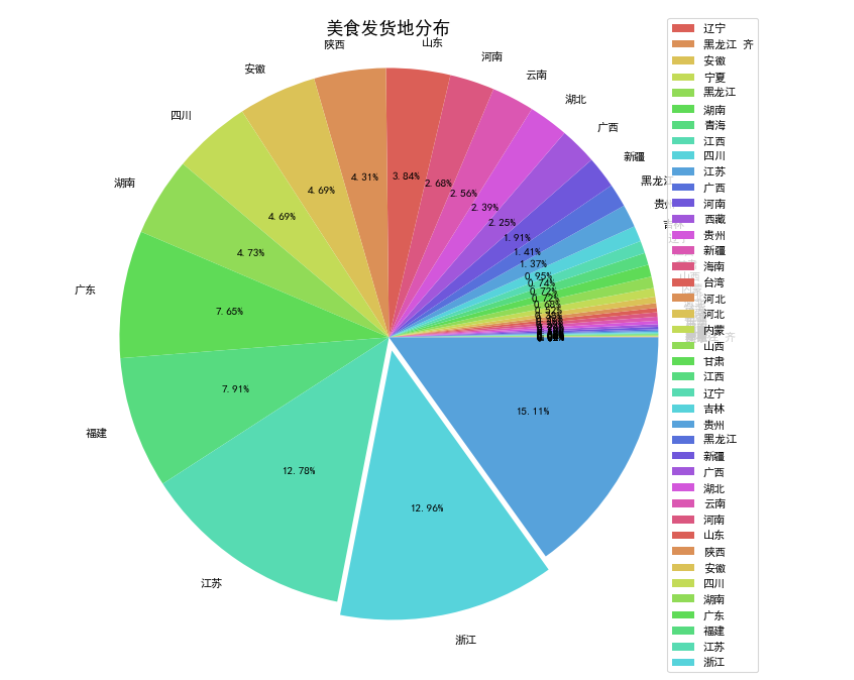
4.1.2商品货源地数据分析
美食商品在江苏发货的占比最大为15.11%,说明江苏是美食产品的主要销售地之一,其次是浙江、福建、广东等地。因为美食特产在这些地方较多,这些地方的电商经济发展也较迅速。因此这些地方是美食商品主要货源地。

4.1.4商品名称数据分析
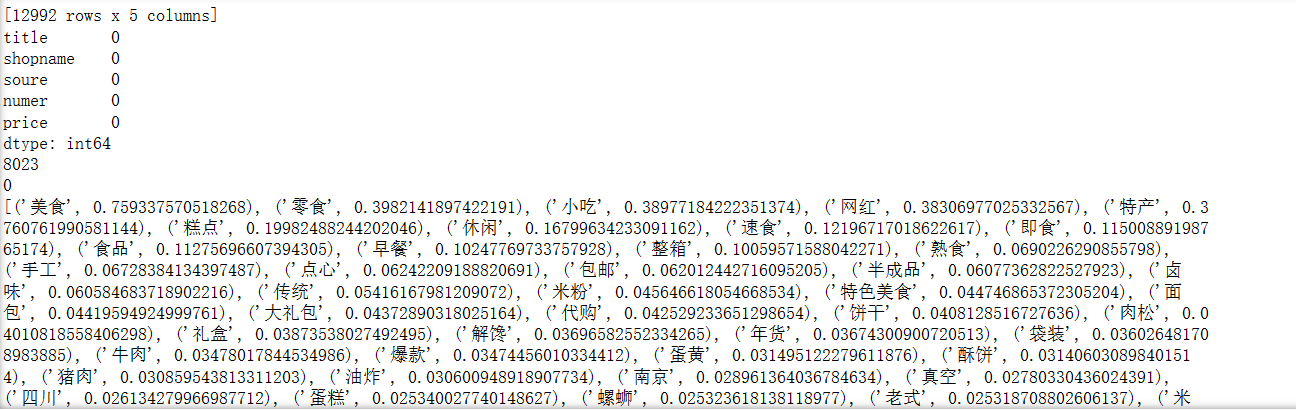
淘宝美食商品名称的关键字中休闲、零食,美食,特产、网红最大。说明重要性最高,其次是即食,速食,特产。由此,我们可以知道,目前人们网购的美食最喜欢休闲零食,糕点。比较倾向于方便的,可以开袋即食的食品。也比较喜欢网红食品。

商品评论词云
出现次数最多的字体越大,出现词语出现频率较小的字体也相应变小,从中我们可以看出,美食产品的味道、便宜、口感等词关注度较高。从这张词云中我们可以更清晰的看到更多出现次数较多的词,像服务、包装、品质、分量、回购等

5.附完整程序源代码
# 导入
import re
import jieba
import numpy as np
import pandas as pd
def clean_news_sign(text):
# keep English, digital and Chinese
comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
return comp.sub('', text)
def clean_news_blank(text):
content = re.sub(r' ','',text)
return content
def clean_news_null(news_ar):
news_ar_1 = news_ar.dropna(how='any')
return news_ar_1
if __name__ == '__main__':
info_news = pd.read_csv("D:/淘宝.csv")
news_ar = info_news.loc[:, "标题"]
news_article = []
print(news_ar.isnull().sum())
print(news_ar.isnull().sum().sum())
info_news = clean_news_null(info_news)
for i in news_ar:
str(i)
try:
i = clean_news_sign(i)
i = clean_news_blank(i)
news_article.append(i)
except:
continue
info_news[:][ "标题"] = news_article
info_news.to_excel("D:/淘宝1.xlsx")
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('D:/stopwords-zh.txt')
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
info_news = pd.read_excel("D:/淘宝1.xlsx", engine='openpyxl')
news_ar = info_news.loc[:, "标题"]
print(type(news_ar))
news_article = []
for i in news_ar:
i = seg_sentence(i)
news_article.append(i)
info_news[:][ "标题"] = news_article
info_news.to_excel("D:/淘宝2.xlsx")
from nltk.stem.wordnet import WordNetLemmatizer
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
corpus = []
info_news = pd.read_excel("D:/淘宝2.xlsx", engine='openpyxl')
info_news = clean_news_null(info_news)
news_ar = info_news.loc[:, "标题"]
print(news_ar.isnull().sum())
print(news_ar.isnull().sum().sum())
for i in news_ar:
corpus.append(i.strip())
print(len(corpus))
n_features = 200
#
tf_vectorizer = TfidfVectorizer(strip_accents='unicode',
max_features=n_features,
max_df=0.99,
min_df=0.002) # 去除文档内出现几率过大或过小的词汇
tf = tf_vectorizer.fit_transform(corpus)
from gensim.models import word2vec, Word2Vec
from sklearn.cluster import KMeans
import gensim
import numpy
import pandas as pd
info_news = pd.read_excel("D:/淘宝2.xlsx", engine='openpyxl')
info_news = clean_news_null(info_news)
news_ar = info_news.loc[:, "标题"]
sss=[]
for i in news_ar:
ss = i.strip()
s1 = ss.split(" ")
sss.append(s1)
model = Word2Vec(size=200, workers=10,sg=1)
model.build_vocab(sss)
model.train(sss,total_examples = model.corpus_count,epochs = model.iter)
model.save('w2v_model')
new_model = Word2Vec.load('w2v_model')
# 获取model里面的所有关键词
keys = model.wv.vocab.keys()
# 获取model里面的所有关键词
keys = model.wv.vocab.keys()
# 获取词对于的词向量
wordvector = []
for key in keys:
wordvector.append(model[key])
print(wordvector)
classCount=4
clf = KMeans(n_clusters=classCount)
s = clf.fit(wordvector)
labels=clf.labels_
print('类别:',labels)
classCollects={}
for i in range(len(keys)):
if labels[i] in list(classCollects.keys()):
classCollects[labels[i]].append(list(keys)[i])
else:
classCollects={0:[],1:[],2:[],3:[]}
print('1类:',classCollects[0][:10])
print('2类:',classCollects[1][:10])
print('3类:',classCollects[2][:10])
print('4类:',classCollects[3][:10])
from wordcloud import WordCloud
import pandas as pd
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, STOPWORDS
info_news = pd.read_excel("D:/淘宝2.xlsx", engine='openpyxl')
info_news = clean_news_null(info_news)
news_ar = info_news.loc[:, "标题"]
news_article = ""
for i in news_ar:
news_article = news_article+i
stopwords = set(STOPWORDS)
stopwords.add("said")
alice_mask = np.array(Image.open("D:/py/aixin.png"))
# 绘制词云
wc = WordCloud(
background_color='white', # 设置背景颜色 默认是black
font_path='simhei.ttf', # 设置字体 显示中文
mask=alice_mask,
max_words=100, # 设置子图最小值
stopwords=stopwords)
wc.generate(news_article)
# 展示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
输出部分截图:
![]()


import numpy as np
import pandas as pd
data1 = pd.read_csv('D:/淘宝美食.csv',encoding='gb18030')
print(data1)
data1['发货地']=data1['发货地'].apply(lambda x:x[:-3])
print(data1['发货地'])
data1.columns = ['title','shopname','soure','numer','price']
print(data1)
print(data1.isnull().sum())#检查缺失值
print(data1.duplicated().sum())#检查重复值
data1.drop_duplicates(inplace=True)#删除重复值
print(data1.duplicated().sum())#检查重复值
#
import collections
from wordcloud import WordCloud
import jieba
#引入停用词
infile = open("D:/stopwords-zh.txt",encoding='utf-8')
stopwords_lst = infile.readlines()
stopwords = [x.strip() for x in stopwords_lst]
#中文分词
def fenci(data):
words_df = data.apply(lambda x:' '.join(jieba.cut(x)))
return words_df
label = fenci(data1["title"])
def remove_characters(sentence): #去停用词
cleanwordlist=[word for word in sentence if word.lower() not in stopwords]
filtered_text=' '.join(cleanwordlist)
return filtered_text
label_good_word= remove_characters(label)
#
import os
import time
import pandas as pd
import numpy as np
import jieba
import jieba.analyse
import matplotlib.pyplot as plt
from PIL import Image
from datetime import datetime
from matplotlib.font_manager import FontProperties
#
keywords = jieba.analyse.extract_tags(label_good_word,
topK=50,
withWeight=True,
allowPOS=('a','e','n','nr','ns', 'v'))
#词性 形容词 叹词 名词 动词
print(keywords)
ss = pd.DataFrame(keywords,columns = ['词语','重要性']) # keyword本身包含两列数据
text = ss.词语[:50]
data=' '.join(text)
wc = WordCloud(font_path='simkai.ttf',max_font_size=72, min_font_size=15, background_color='white').generate(data)
fig = plt.figure(figsize=(10,7))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.imshow(wc)
plt.title("商品名称关键词词云",fontsize=20)
plt.axis('off')
plt.show()
![]()
![]()

import matplotlib.pyplot as plt
sl=data1.soure.value_counts().sort_values()
print(sl)
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(12,10),dpi=80)
explode={}
for i in sl.index:
if i in ['浙江']:
explode[i]=0.05
else:
explode[i]=0
plt.pie(sl,labels=sl.index,explode=explode.values(),autopct='%0.2f%%',colors=sns.color_palette('hls', n_colors=16))
plt.title('美食发货地分布',fontsize=16)
plt.axis('equal')
plt.legend(loc='right')
plt.show()

from pyecharts.charts import Map # 注意这里与老版本pyecharts调用的区别
from pyecharts import options as opts
import random
import os
data2 =data1['price'].apply(lambda x:x[2:5])
data2 = list(map(float,data2))
import pandas as pd
import matplotlib.pyplot as plt
# matplotlib中文显示
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,7))
# 分数
score = data2
# 设置分段
bins=[0,30,60,90,120,150,180,300,1000]
# 按分段离散化数据
segments=pd.cut(score,bins,right=False)
print(segments)
# 统计各分段人数
counts=pd.value_counts(segments,sort=False)
# 绘制柱状图
b=plt.bar(counts.index.astype(str),counts)
# 添加数据标签
plt.bar_label(b,counts)
plt.title('价格频率分布直方图')
plt.xlabel('价格')
plt.ylabel('频数')
plt.show()
四、总结
随着社会经济的不断进步与发展,美食几乎变成了不可缺少的日常生活。由于不同人群对于美食有不同的使用需求,美食商家就推出很多不同的美食产品类别来满足不同消费者对于美食产品的需求。但是对于消费者而言,市场上的美食产品种类玲琅满目,如果消费者想要挑选到自己想要的美食产品,就需要消耗大量的精力。美食产品聚类分析则可以帮助消费者根据自己的需求,快速的挑选出自己需要的美食产品。
基于上述背景,本文展开了对美食产品评论挖掘研究,旨在对美食进行不同方面的分析。主要工作如下:
(1)我们通过网络爬虫技术获取了淘宝网中有关美食的真实评论数据。
(2)对获取到的数据进行预处理,包括文本过滤、分词、去除停用词等;
(3)利用基于word2vec的K-means聚类算法进行建模,并进行聚类分析。
(4)通过一系列可视化分析之后,分析当今美食产业现状,并提出建设性建议。
但仍然存在很多不足之处。在以后的工作中需要不断的进行改进,主要有以下几点:
(1)受技术限制,本文获取的商品评论数据并不够全面,一些产品的评论通常是在评论区以图片中展示,图片中的信息以我现在的爬虫技术还无法爬取。
(2)模型评价方面有待加强,虽然使用了K-Means模型,但对模型总结不到位,没有在适用性方面对模型进行验证。
(3)我们需要使用更多的机器学习算法进行研究,改进和组合各种算法,最终选择具有最佳效果的算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号