
13.2.0 头文件
# 通过微调在ImageNet数据集上预训练得到的ResNet模型,得到新的微调模型
# 利用新的微调模型在一个小型数据集上识别图像中是否包含热狗
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
13.2.1 下载hotdog数据集,并显示其中部分样本
# DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
# DATA_HUB是一个字典,其中键值对的key为数据集名称,value为数据集的下载地址和加密签名
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')
# 下载'hotdog'数据集保存到data文件夹下,并对其进行解压,返回数据集文件路径(..\data\hotdog)
data_dir = d2l.download_extract('hotdog')
# 加载训练集中的所有图像(一共2000张),组织形式为((图像数据,标签),(图像数据,标签),……,(图像数据,标签))
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
# 加载测试集中的所有图像(一共800张)((图像数据,标签),(图像数据,标签),……,(图像数据,标签))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 训练集的前8张图像(为包含热狗的图像)
hotdogs = [train_imgs[i][0] for i in range(8)]
# 训练集的后8张图像(为不包含热狗的图像)
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
# 显示图像
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
plt.show()

13.2.2 定义对训练集和测试集的预处理操作
# (0.485,0.229)分别为 ImageNet数据集第一个通道像素值的均值和方差
# (0.456,0.224)分别为 ImageNet数据集第二个通道像素值的均值和方差
# (0.406,0.225)分别为 ImageNet数据集第三个通道像素值的均值和方差
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 训练集的预处理操作:随即裁剪为224×224,随机水平翻转,转换成张量,将每个图像的三个通道分别进行标准化
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
# 测试集的预处理操作,将图像处理成224×224,并保持不变形,转换成张量,,将每个图像的三个通道分别进行标准化
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256), # 将图像的短边缩放至256,并保持长宽比不变
torchvision.transforms.CenterCrop(224), # 将图像从中心裁剪成224×224
torchvision.transforms.ToTensor(),
normalize])
13.2.3 预训练的resnet18模型
# 载入在ImageNet数据集上预训练的resnet18模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
print(pretrained_net)
# print(pretrained_net.fc)
# 输出:
# ResNet(
# (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
# (layer1): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# (1): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer2): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer3): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer4): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
# (fc): Linear(in_features=512, out_features=1000, bias=True)
# )
# 查看最后的全连接输出层
print(pretrained_net.fc)
# 输出:
# Linear(in_features=512, out_features=1000, bias=True)
13.2.4 载入在ImageNet数据集上预训练的resnet18模型,并将其改造成一个二分类模型
# 载入在ImageNet数据集上预训练的resnet18模型
finetune_net = torchvision.models.resnet18(pretrained=True)
# 将模型的输出层改为一个二分类输出
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
# 初始化全连接输出层的权重
nn.init.xavier_uniform_(finetune_net.fc.weight);
13.2.5 利用在imageNet数据集上预训练的resnet18模型在HotDog数据集上进行训练,其中非输出层采用小学习率,输出层采用大学习率
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):
# 加载HotDog训练集,对训练集进行相应的预处理操作,然后按照批量大小对训练集进行切割并封装
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)
# 加载HotDog测试集,对测试集进行相应的预处理操作然后按照批量大小对测试集进行切割并封装
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)
# 获取所有的GPU
devices = d2l.try_all_gpus()
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# 对输出层的权重和偏置用较高的学习率进行训练,对非输出层的权重用较低的学习率进行训练
if param_group:
params_1x = [param for name, param in net.named_parameters() if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)
# 对整个数据集进行多GPU训练
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
# 对输出层使用较大的学习率,非输出层使用较小的学习率,利用预训练模型(只有输出层权重进行了初始化,其他层权重利用预训练的结果)进行训练
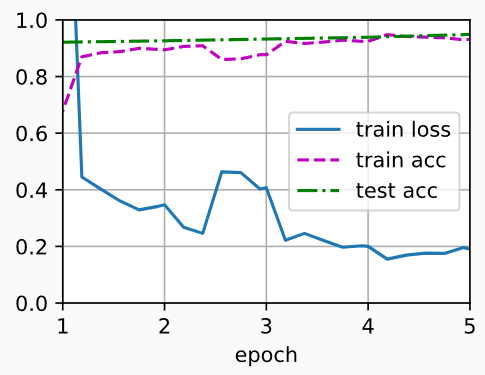
train_fine_tuning(finetune_net, 5e-5)
# 输出:
# loss 0.191, train acc 0.931, test acc 0.949
# 1086.6 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
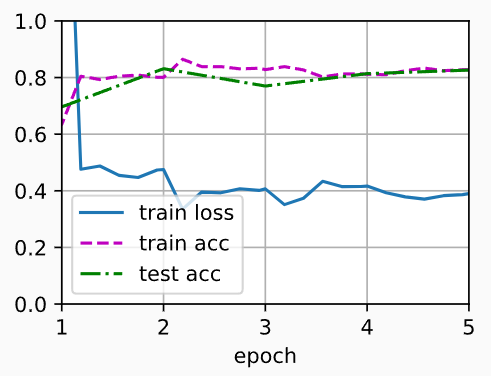
# 对输出层使用较大的学习率,非输出层也使用较大的学习率,不利用预训练模型(所有层权重都进行了初始化)进行训练
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)
# 输出:
# loss 0.390, train acc 0.828, test acc 0.826
# 1610.3 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
本小节完整代码如下
# 通过微调在ImageNet数据集上预训练得到的ResNet模型,得到新的微调模型
# 利用新的微调模型在一个小型数据集上识别图像中是否包含热狗
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
# ------------------------------下载hotdog数据集,并显示其中部分样本------------------------------------
# DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
# DATA_HUB是一个字典,其中键值对的key为数据集名称,value为数据集的下载地址和加密签名
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')
# 下载'hotdog'数据集保存到data文件夹下,并对其进行解压,返回数据集文件路径(..\data\hotdog)
data_dir = d2l.download_extract('hotdog')
# 加载训练集中的所有图像(一共2000张),组织形式为((图像数据,标签),(图像数据,标签),……,(图像数据,标签))
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
# 加载测试集中的所有图像(一共800张)((图像数据,标签),(图像数据,标签),……,(图像数据,标签))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 训练集的前8张图像(为包含热狗的图像)
hotdogs = [train_imgs[i][0] for i in range(8)]
# 训练集的后8张图像(为不包含热狗的图像)
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
# 显示图像
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
plt.show()
# ------------------------------定义对训练集和测试集的预处理操作------------------------------------
# (0.485,0.229)分别为 ImageNet数据集第一个通道像素值的均值和方差
# (0.456,0.224)分别为 ImageNet数据集第二个通道像素值的均值和方差
# (0.406,0.225)分别为 ImageNet数据集第三个通道像素值的均值和方差
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 训练集的预处理操作:随即裁剪为224×224,随机水平翻转,转换成张量,将每个图像的三个通道分别进行标准化
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
# 测试集的预处理操作,将图像处理成224×224,并保持不变形,转换成张量,,将每个图像的三个通道分别进行标准化
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256), # 将图像的短边缩放至256,并保持长宽比不变
torchvision.transforms.CenterCrop(224), # 将图像从中心裁剪成224×224
torchvision.transforms.ToTensor(),
normalize])
# ------------------------------预训练的resnet18模型------------------------------------
# 载入在ImageNet数据集上预训练的resnet18模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
print(pretrained_net)
# print(pretrained_net.fc)
# 输出:
# ResNet(
# (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
# (layer1): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# (1): BasicBlock(
# (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer2): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer3): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (layer4): Sequential(
# (0): BasicBlock(
# (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (downsample): Sequential(
# (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
# (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (1): BasicBlock(
# (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (relu): ReLU(inplace=True)
# (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# )
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
# (fc): Linear(in_features=512, out_features=1000, bias=True)
# )
# 查看最后的全连接输出层
print(pretrained_net.fc)
# 输出:
# Linear(in_features=512, out_features=1000, bias=True)
# ------------------------------载入在ImageNet数据集上预训练的resnet18模型,并将其改造成一个二分类模型------------------------------------
# 载入在ImageNet数据集上预训练的resnet18模型
finetune_net = torchvision.models.resnet18(pretrained=True)
# 将模型的输出层改为一个二分类输出
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
# 初始化全连接输出层的权重
nn.init.xavier_uniform_(finetune_net.fc.weight);
# ------------------------------利用在imageNet数据集上预训练的resnet18模型在HotDog数据集上进行训练,其中非输出层采用小学习率,输出层采用大学习率------------------------------------
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):
# 加载HotDog训练集,对训练集进行相应的预处理操作,然后按照批量大小对训练集进行切割并封装
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)
# 加载HotDog测试集,对测试集进行相应的预处理操作然后按照批量大小对测试集进行切割并封装
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)
# 获取所有的GPU
devices = d2l.try_all_gpus()
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# 对输出层的权重和偏置用较高的学习率进行训练,对非输出层的权重用较低的学习率进行训练
if param_group:
params_1x = [param for name, param in net.named_parameters() if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)
# 对整个数据集进行多GPU训练
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
# 对输出层使用较大的学习率,非输出层使用较小的学习率,利用预训练模型(只有输出层权重进行了初始化,其他层权重利用预训练的结果)进行训练
train_fine_tuning(finetune_net, 5e-5)
# 输出:
# loss 0.191, train acc 0.931, test acc 0.949
# 1086.6 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
# 对输出层使用较大的学习率,非输出层也使用较大的学习率,不利用预训练模型(所有层权重都进行了初始化)进行训练
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)
# 输出:
# loss 0.390, train acc 0.828, test acc 0.826
# 1610.3 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号