
12.5.0 头文件
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
12.5.1 创建网络模型并初始化模型参数
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义LeNet网络模型
def lenet(X, params):
# 卷积层
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
# ReLU激活函数层
h1_activation = F.relu(h1_conv)
# 平均池化层
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
# 卷积层
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
# ReLU激活函数层
h2_activation = F.relu(h2_conv)
# 平均池化层
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
# 展平层
h2 = h2.reshape(h2.shape[0], -1)
# 全连接隐藏层层
h3_linear = torch.mm(h2, params[4]) + params[5]
# ReLU激活函数层
h3 = F.relu(h3_linear)
# 全连接输出层
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
12.5.2 张量在多个GPU上转移的基础
# 把网络模型参数搬移到第0个GPU上
def get_params(params, device):
new_params = [p.to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
new_params = get_params(params, d2l.try_gpu(0))
print('b1 权重:', new_params[1])
print('b1 梯度:', new_params[1].grad)
# 输出:
# b1 权重: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
# device='cuda:0', requires_grad=True)
# b1 梯度: None
# 假设有多个张量分别分布在多个GPU上,这个函数的作用就是将所有张量进行相加,并将相加结果广播给所有GPU
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i][:] = data[0].to(data[i].device)
# 在两个GPU上分别创建两个张量,并输出张量聚合之前的值
data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('allreduce之前:\n', data[0], '\n', data[1])
# 输出:
# allreduce之前:
# tensor([[1., 1.]], device='cuda:0')
# tensor([[2., 2.]], device='cuda:1')
# 两个张量聚合
allreduce(data)
# 输出两个向量聚合之后的结果
print('allreduce之后:\n', data[0], '\n', data[1])
# 输出:
# allreduce之后:
# tensor([[3., 3.]], device='cuda:0')
# tensor([[3., 3.]])
# 把一批张量均匀地分布到多个GPU上
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)
# 输出:
# input : tensor([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
# load into [device(type='cuda', index=0), device(type='cuda', index=1)]
# output: (tensor([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]], device='cuda:0'),
# tensor([[10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]], device='cuda:1'))
12.5.3 把一个批量的样本和标签均匀地分布到多个GPU上
# 把一个批量的样本和标签均匀地分布到多个GPU上
def split_batch(X, y, devices):
"""将X和y拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))
12.5.4 小批量样本的多GPU训练
# 把一个批量的样本均匀地分布到多个GPU上同时进行训练,并更新网络模型参数
def train_batch(X, y, device_params, devices, lr):
# 把一个批量的特征X和标签Y均匀地分布到多个GPU上
X_shards, y_shards = split_batch(X, y, devices)
# 在每个GPU上分别计算损失
ls = [loss(lenet(X_shard, device_W), y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls: # 反向传播在每个GPU上分别执行
l.backward()
# 将每个GPU的所有梯度相加,并将其广播到所有GPU
with torch.no_grad():
for i in range(len(device_params[0])):
allreduce(
[device_params[c][i].grad for c in range(len(devices))])
# 在每个GPU上分别更新模型参数
for param in device_params:
d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
12.5.5 整个数据集的多GPU训练
def train(num_gpus, batch_size, lr):
# 下载fashion_mnist,并对数据集进行打乱和按批量大小进行切割的操作,得到可迭代的训练集和测试集(训练集和测试集的形式都为(特征数据集合,数字标签集合))
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 获取GPU
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 把网络模型参数搬移到每个GPU上
device_params = [get_params(params, d) for d in devices]
# 设置训练轮数
num_epochs = 10
# 定义动画,用来显示训练图像
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
# 定义定时器
timer = d2l.Timer()
for epoch in range(num_epochs):
# 开始一轮的训练过程
timer.start()
for X, y in train_iter:
# 开始一个批量的训练过程
# 把一个批量的样本均匀地分布到多个GPU上同时进行训练,并更新网络模型参数
train_batch(X, y, device_params, devices, lr)
# 等待GPU全部执行结束,再统计代码在cuda上运行的时间
torch.cuda.synchronize()
timer.stop()
# 经过议论的训练,记录下此时更新参数后的网络模型在测试集上的平均准确率
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
# 输出最终的模型在测试集上的准确率、每轮训练的平均时间以及用到的GPU
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')
12.5.6 使用单GPU和使用多GPU的训练结果对比
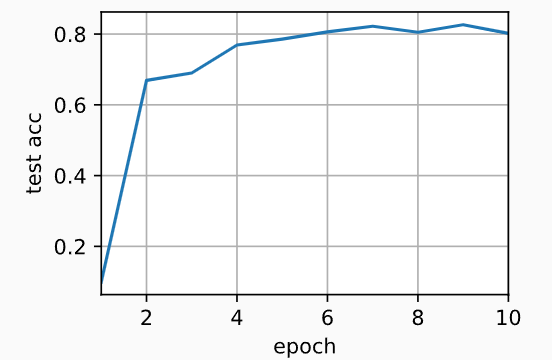
(1)单GPU:
# 设置GPU的个数为1,批量大小为256,学习率为0.2,开始训练
train(num_gpus=1, batch_size=256, lr=0.2)
# 输出:
# 测试精度:0.80,2.7秒/轮,在[device(type='cuda', index=0)]
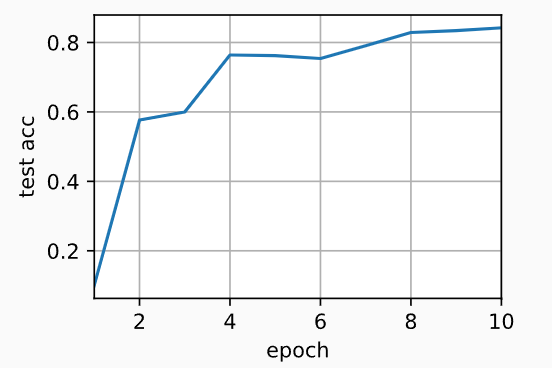
(2)双GPU:
# 设置GPU的个数为2,批量大小为256,学习率为0.2,开始训练
train(num_gpus=2, batch_size=256, lr=0.2)
# 输出:
# 测试精度:0.84,2.8秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]
本小节完整代码如下
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# ------------------------------创建网络模型并初始化模型参数------------------------------------
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义LeNet网络模型
def lenet(X, params):
# 卷积层
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
# ReLU激活函数层
h1_activation = F.relu(h1_conv)
# 平均池化层
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
# 卷积层
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
# ReLU激活函数层
h2_activation = F.relu(h2_conv)
# 平均池化层
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
# 展平层
h2 = h2.reshape(h2.shape[0], -1)
# 全连接隐藏层层
h3_linear = torch.mm(h2, params[4]) + params[5]
# ReLU激活函数层
h3 = F.relu(h3_linear)
# 全连接输出层
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# ------------------------------张量在多个GPU上转移的基础------------------------------------
# 把网络模型参数搬移到第0个GPU上
def get_params(params, device):
new_params = [p.to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
new_params = get_params(params, d2l.try_gpu(0))
print('b1 权重:', new_params[1])
print('b1 梯度:', new_params[1].grad)
# 输出:
# b1 权重: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
# device='cuda:0', requires_grad=True)
# b1 梯度: None
# 假设有多个张量分别分布在多个GPU上,这个函数的作用就是将所有张量进行相加,并将相加结果广播给所有GPU
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i][:] = data[0].to(data[i].device)
# 在两个GPU上分别创建两个张量,并输出张量聚合之前的值
data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('allreduce之前:\n', data[0], '\n', data[1])
# 输出:
# allreduce之前:
# tensor([[1., 1.]], device='cuda:0')
# tensor([[2., 2.]], device='cuda:1')
# 两个张量聚合
allreduce(data)
# 输出两个向量聚合之后的结果
print('allreduce之后:\n', data[0], '\n', data[1])
# 输出:
# allreduce之后:
# tensor([[3., 3.]], device='cuda:0')
# tensor([[3., 3.]])
# 把一批张量均匀地分布到多个GPU上
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)
# 输出:
# input : tensor([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
# load into [device(type='cuda', index=0), device(type='cuda', index=1)]
# output: (tensor([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]], device='cuda:0'),
# tensor([[10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]], device='cuda:1'))
# ------------------------------把一个批量的样本和标签均匀地分布到多个GPU上------------------------------------
# 把一个批量的样本和标签均匀地分布到多个GPU上
def split_batch(X, y, devices):
"""将X和y拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))
# ------------------------------小批量样本的多GPU训练------------------------------------
# 把一个批量的样本均匀地分布到多个GPU上同时进行训练,并更新网络模型参数
def train_batch(X, y, device_params, devices, lr):
# 把一个批量的特征X和标签Y均匀地分布到多个GPU上
X_shards, y_shards = split_batch(X, y, devices)
# 在每个GPU上分别计算损失
ls = [loss(lenet(X_shard, device_W), y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls: # 反向传播在每个GPU上分别执行
l.backward()
# 将每个GPU的所有梯度相加,并将其广播到所有GPU
with torch.no_grad():
for i in range(len(device_params[0])):
allreduce(
[device_params[c][i].grad for c in range(len(devices))])
# 在每个GPU上分别更新模型参数
for param in device_params:
d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
# ------------------------------整个数据集的多GPU训练------------------------------------
def train(num_gpus, batch_size, lr):
# 下载fashion_mnist,并对数据集进行打乱和按批量大小进行切割的操作,得到可迭代的训练集和测试集(训练集和测试集的形式都为(特征数据集合,数字标签集合))
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 获取GPU
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 把网络模型参数搬移到每个GPU上
device_params = [get_params(params, d) for d in devices]
# 设置训练轮数
num_epochs = 10
# 定义动画,用来显示训练图像
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
# 定义定时器
timer = d2l.Timer()
for epoch in range(num_epochs):
# 开始一轮的训练过程
timer.start()
for X, y in train_iter:
# 开始一个批量的训练过程
# 把一个批量的样本均匀地分布到多个GPU上同时进行训练,并更新网络模型参数
train_batch(X, y, device_params, devices, lr)
# 等待GPU全部执行结束,再统计代码在cuda上运行的时间
torch.cuda.synchronize()
timer.stop()
# 经过议论的训练,记录下此时更新参数后的网络模型在测试集上的平均准确率
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
# 输出最终的模型在测试集上的准确率、每轮训练的平均时间以及用到的GPU
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')
# ------------------------------使用单GPU和使用多GPU的训练结果对比------------------------------------
# 设置GPU的个数为1,批量大小为256,学习率为0.2,开始训练
train(num_gpus=1, batch_size=256, lr=0.2)
# 输出:
# 测试精度:0.80,2.7秒/轮,在[device(type='cuda', index=0)]
# 设置GPU的个数为2,批量大小为256,学习率为0.2,开始训练
train(num_gpus=2, batch_size=256, lr=0.2)
# 输出:
# 测试精度:0.84,2.8秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号