
13.1.0 头文件
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
d2l.set_figsize()
13.1.1 读入原始图像
# 读入并显示原始图像
img = d2l.Image.open('../img/dog_cat.jpg')
d2l.plt.imshow(img);
plt.show()

13.1.2 对图像执行某种变换并显示
# 对图像执行某种操作并显示
# img:原始图像
# aug:对图像进行的操作
# num_rows:显示的行数
# num_cols:显示的列数
def apply(img, aug, num_rows=2, num_cols=4, scale=3):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# torchvision.transforms.RandomHorizontalFlip():以一定的概率对图像进行水平反转
apply(img, torchvision.transforms.RandomHorizontalFlip())
plt.show()
# torchvision.transforms.RandomVerticalFlip():以一定的概率对图像进行垂直反转
apply(img, torchvision.transforms.RandomVerticalFlip())
plt.show()
# 对图像进行随即裁剪
# (200, 200):输出的图像尺寸
# scale=(0.1, 1):随机采样这张图像时,最少要覆盖这个图像的10%,最多保持图像不变
# ratio=(0.5, 2):随即采样得到的图像的宽高比为0.5:2
shape_aug = torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
plt.show()
# 随机改变图像的亮度(在±50%区间内变化)
apply(img, torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0))
plt.show()
# 随机改变图像的色相(在±50%区间内变化)
apply(img, torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5))
plt.show()
# 随机改变图像的亮度、对比度、饱和度、色相(在±50%区间内变化)
color_aug = torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
plt.show()
# 随机地对图像进行水平翻转、亮度、对比度、饱和度、色相、裁剪
augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
plt.show()

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------------------------------

13.1.3 下载并显示CIFAR10数据集
# 下载CIFAR10训练集,并保存在data目录下
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",download=True)
# 显示CIFAR10训练集中的前32张图像,不显示标签
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
plt.show()

13.1.4 加载CIFAR10数据集并随机增强
# 训练集的预处理操作,包括随机水平翻转,转换成张量
train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor()])
# 训练集的预处理操作,包括转换成张量
test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 加载cifar10训练集或测试集,对训练集或测试集进行相应的预处理操作,并打乱测试集,然后按照批量大小对训练集或测试集进行切割并封装
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
13.1.5 小批量样本的多GPU训练
# 小批量样本的多GPU训练
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需(稍后讨论)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
13.1.6 整个数据集的多GPU训练
# 整个数据集的多GPU训练
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):
# 定义定时器、训练集被划分为多少批次
timer, num_batches = d2l.Timer(), len(train_iter)
# 定义动画,用来显示训练图像
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])
# 把模型参数拷贝到每个GPU上,把样本和标签均分到多个GPU上
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 开始一轮的训练过程
# 4个维度:储存训练损失,训练准确度,实例数,特点数
# 定义一个累加器,累加器中累加了当前轮的训练损失之和、当前轮的训练准确率之和、当前轮的训练样本数、当前轮的训练样本数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
# i是批次编号,features是该批次样本的特征集合, labels该批次样本的标签集合
timer.start()
# 计算一个批次样本在模型上的损失之和以及准确率之和,并进行累加
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
# 记录在一轮的训练过程中,平均损失和平均准确率的变化
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3],None))
# 经过一轮训练,计算更新参数后的网络模型在测试集上的平均准确率
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
# 更新动画
animator.add(epoch + 1, (None, None, test_acc))
# 输出最后一轮训练时的平均损失、在训练集上的平均准确率、在测试集上的平均准测率
print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
# 输出每秒能够训练多少张图像
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')
13.1.7 定义网络模型并初始化模型权重
# 定义批量大小、获取所有的GPU、定义网络模型
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# 初始化全连接层和卷积层的权重
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
13.1.8 加载数据集进行增广并开始训练
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
# 加载cifar10训练集,对训练集进行相应的预处理操作,然后按照批量大小对训练集进行切割并封装
train_iter = load_cifar10(True, train_augs, batch_size)
# 加载cifar10测试集,对测试集进行相应的预处理操作,并打乱测试集,然后按照批量大小对测试集进行切割并封装
test_iter = load_cifar10(False, test_augs, batch_size)
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# 定义Adam优化器
trainer = torch.optim.Adam(net.parameters(), lr=lr)
# 开始训练
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
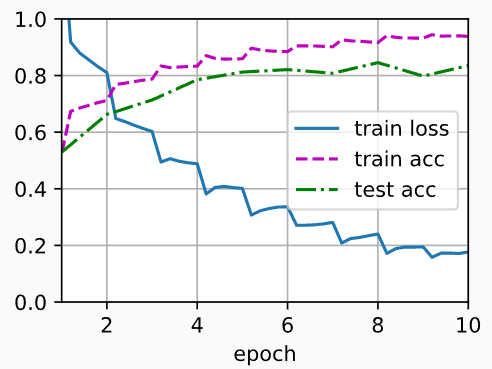
train_with_data_aug(train_augs, test_augs, net)
# 输出:
# loss 0.177, train acc 0.938, test acc 0.835
# 5616.3 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
本小节完整代码如下
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
d2l.set_figsize()
# ------------------------------读入原始图像------------------------------------
# 读入并显示原始图像
img = d2l.Image.open('../img/dog_cat.jpg')
d2l.plt.imshow(img);
plt.show()
# ------------------------------对图像执行某种变换并显示------------------------------------
# 对图像执行某种操作并显示
# img:原始图像
# aug:对图像进行的操作
# num_rows:显示的行数
# num_cols:显示的列数
def apply(img, aug, num_rows=2, num_cols=4, scale=3):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# torchvision.transforms.RandomHorizontalFlip():以一定的概率对图像进行水平反转
apply(img, torchvision.transforms.RandomHorizontalFlip())
plt.show()
# torchvision.transforms.RandomVerticalFlip():以一定的概率对图像进行垂直反转
apply(img, torchvision.transforms.RandomVerticalFlip())
plt.show()
# 对图像进行随即裁剪
# (200, 200):输出的图像尺寸
# scale=(0.1, 1):随机采样这张图像时,最少要覆盖这个图像的10%,最多保持图像不变
# ratio=(0.5, 2):随即采样得到的图像的宽高比为0.5:2
shape_aug = torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
plt.show()
# 随机改变图像的亮度(在±50%区间内变化)
apply(img, torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0))
plt.show()
# 随机改变图像的色相(在±50%区间内变化)
apply(img, torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5))
plt.show()
# 随机改变图像的亮度、对比度、饱和度、色相(在±50%区间内变化)
color_aug = torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
plt.show()
# 随机地对图像进行水平翻转、亮度、对比度、饱和度、色相、裁剪
augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
plt.show()
# ------------------------------下载并显示CIFAR10数据集------------------------------------
# 下载CIFAR10训练集,并保存在data目录下
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",download=True)
# 显示CIFAR10训练集中的前32张图像,不显示标签
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
plt.show()
# ------------------------------加载CIFAR10数据集并随机增强------------------------------------
# 训练集的预处理操作,包括随机水平翻转,转换成张量
train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor()])
# 训练集的预处理操作,包括转换成张量
test_augs = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
# 加载cifar10训练集或测试集,对训练集或测试集进行相应的预处理操作,并打乱测试集,然后按照批量大小对训练集或测试集进行切割并封装
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
# ------------------------------小批量样本的多GPU训练------------------------------------
# 小批量样本的多GPU训练
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需(稍后讨论)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
# ------------------------------整个数据集的多GPU训练------------------------------------
# 整个数据集的多GPU训练
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):
# 定义定时器、训练集被划分为多少批次
timer, num_batches = d2l.Timer(), len(train_iter)
# 定义动画,用来显示训练图像
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])
# 把模型参数拷贝到每个GPU上,把样本和标签均分到多个GPU上
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 开始一轮的训练过程
# 4个维度:储存训练损失,训练准确度,实例数,特点数
# 定义一个累加器,累加器中累加了当前轮的训练损失之和、当前轮的训练准确率之和、当前轮的训练样本数、当前轮的训练样本数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
# i是批次编号,features是该批次样本的特征集合, labels该批次样本的标签集合
timer.start()
# 计算一个批次样本在模型上的损失之和以及准确率之和,并进行累加
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
# 记录在一轮的训练过程中,平均损失和平均准确率的变化
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3],None))
# 经过一轮训练,计算更新参数后的网络模型在测试集上的平均准确率
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
# 更新动画
animator.add(epoch + 1, (None, None, test_acc))
# 输出最后一轮训练时的平均损失、在训练集上的平均准确率、在测试集上的平均准测率
print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
# 输出每秒能够训练多少张图像
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')
# ------------------------------定义网络模型并初始化模型权重------------------------------------
# 定义批量大小、获取所有的GPU、定义网络模型
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# 初始化全连接层和卷积层的权重
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
# ------------------------------加载数据集进行增广并开始训练------------------------------------
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
# 加载cifar10训练集,对训练集进行相应的预处理操作,然后按照批量大小对训练集进行切割并封装
train_iter = load_cifar10(True, train_augs, batch_size)
# 加载cifar10测试集,对测试集进行相应的预处理操作,并打乱测试集,然后按照批量大小对测试集进行切割并封装
test_iter = load_cifar10(False, test_augs, batch_size)
# 定义交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction="none")
# 定义Adam优化器
trainer = torch.optim.Adam(net.parameters(), lr=lr)
# 开始训练
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
train_with_data_aug(train_augs, test_augs, net)
# 输出:
# loss 0.177, train acc 0.938, test acc 0.835
# 5616.3 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号