
4.10.0 头文件
import hashlib
import os
import tarfile
import zipfile
import requests
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
4.10.1 设置要下载的数据集信息
# 创建一个空字典,用来存放要下载数据集的信息,格式为:(数据集名:(下载地址,加密签名))
DATA_HUB = dict()
# 数据集下载的基地址
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
# 训练集kaggle_house_train的下载地址和加密签名
DATA_HUB['kaggle_house_train'] = (DATA_URL + 'kaggle_house_pred_train.csv','585e9cc93e70b39160e7921475f9bcd7d31219ce')
# 测试集kaggle_house_test的下载地址和加密签名
DATA_HUB['kaggle_house_test'] = (DATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
4.10.2 下载数据集,并将数据集存放到指定路径加下的csv文件中,然后读入训练集和测试集到内存中
# 下载指定的数据集(name)保存到data文件夹下,文件格式为csv,并返回数据集文件路径
def download(name, cache_dir=os.path.join('..', 'data')):
# 判断请求的数据集(name)是否在数据集字典(DATA_HUB)中,如果不在,就抛出异常,并且异常信息为:name 不存在于 DATA_HUB字典
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
# 所请求文件的下载地址,所请求文件的加密签名
url, sha1_hash = DATA_HUB[name]
# 创建data文件夹,用来存放数据集
os.makedirs(cache_dir, exist_ok=True)
# 用来存放数据集的文件相对路径(..\data\kaggle_house_pred_train.csv)
fname = os.path.join(cache_dir, url.split('/')[-1])
# 如果data文件夹下已经存在数据集文件,对文件进行加密签名计算,如果计算出的加密签名和提供的加密签名一致,则返回文件相对地址
if os.path.exists(fname):
# hashlib.sha1:实例化1个sha1对象
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
# sha1.update传入需要加密的信息
sha1.update(data)
# sha1.hexdigest:得到计算出的加密签名
if sha1.hexdigest() == sha1_hash:
return fname # 命中缓存
# 如果计算出的加密签名和提供的加密签名不一致,或者数据集文件不存在,则下载数据集,并创建一个csv文件来存放数据集
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
# 返回数据集文件路径(..\data\kaggle_house_pred_train.csv)
return fname
# 下载指定的数据集(name)保存到data文件夹下,并对其进行解压,返回数据集文件路径
def download_extract(name, folder=None):
# 下载指定的数据集(name)保存到data文件夹下,文件格式为csv,并返回数据集文件路径
fname = download(name) # (..\data\kaggle_house_pred_train.csv)
# 将数据集文件(以".zip"、".tar"、".gz"结尾)进行解压
base_dir = os.path.dirname(fname) # (..\data)
data_dir, ext = os.path.splitext(fname) # (..\data\kaggle_house_pred_train) (.csv)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩'
fp.extractall(base_dir)
# 返回文件路径(不包含后缀名)(..\data\kaggle_house_pred_train)
return os.path.join(base_dir, folder) if folder else data_dir
# 下载数据集字典中的所有数据集文件
def download_all():
"""下载DATA_HUB中的所有文件"""
for name in DATA_HUB:
download(name)
# 下载并读入kaggle_house_train训练集
train_data = pd.read_csv(download('kaggle_house_train'))
# 下载并读入kaggle_house_test测试集
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape)
# 输出:
# (1460, 81) 训练集有1460个样本,每个样本有80个特征,第一列为序号,后面80列为特征
print(test_data.shape)
# 输出:
# (1459, 80) 测试集有1459个样本,每个样本有79个特征,第一列为序号,后面79列为特征,比训练集少了售价这一列
# 取出训练集中前4个样本的前4列和后3列(序号,Id,MSSubClass,MSZoning,LotFrontage,SaleType,SaleCondition,SalePrice)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
# 输出:
# Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
# 0 1 60 RL 65.0 WD Normal 208500
# 1 2 20 RL 80.0 WD Normal 181500
# 2 3 60 RL 68.0 WD Normal 223500
# 3 4 70 RL 60.0 WD Abnorml 140000
4.10.3 对训练集和测试集进行预处理
# 将训练集和测试集合并,其中训练集和测试集都去掉第一列序号,另外训练集再去掉最后一列售价
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
print(all_features)
# 输出:
# MSSubClass MSZoning LotFrontage ... YrSold SaleType SaleCondition
# 0 60 RL 65.0 ... 2008 WD Normal
# 1 20 RL 80.0 ... 2007 WD Normal
# 2 60 RL 68.0 ... 2008 WD Normal
# 3 70 RL 60.0 ... 2006 WD Abnorml
# 4 60 RL 84.0 ... 2008 WD Normal
# ... ... ... ... ... ... ... ...
# 1454 160 RM 21.0 ... 2006 WD Normal
# 1455 160 RM 21.0 ... 2006 WD Abnorml
# 1456 20 RL 160.0 ... 2006 WD Abnorml
# 1457 85 RL 62.0 ... 2006 WD Normal
# 1458 60 RL 74.0 ... 2006 WD Normal
# [2919 rows x 79 columns]
# 对数值类型的列进行预处理
# all_features.dtypes 获取每一列的数据类型,其中字符串的数据类型为object
# all_features.dtypes != 'object':获取每一列的数据类型,如果类型为object,就返回False,为object就返回True
# all_features.dtypes[all_features.dtypes != 'object']:
# all_features.dtypes[all_features.dtypes != 'object']:将类型为object的列去掉
# all_features.dtypes[all_features.dtypes != 'object'].index:得到所有类型为数值类型的列的列名
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
print(numeric_features)
# 输出:
# Index(['MSSubClass', 'LotFrontage', 'LotArea', 'OverallQual', 'OverallCond',
# 'YearBuilt', 'YearRemodAdd', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2',
# 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF',
# 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath',
# 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces',
# 'GarageYrBlt', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF',
# 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal',
# 'MoSold', 'YrSold'],
# dtype='object')
# 为了将所有特征都放在一个共同的维度上,通过将特征重新缩放到零均值和单位方差来标准化数据,即对每一列,令(x-均值)/方差
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))# all_features[numeric_features]:所有样本的数据类型为数值的所有列
# 将数值类型列的所有缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 对字符串类型的列进行预处理
# 采用独热编码来替换字符串类型的列,并且将“na”(缺失值)视为有效的特征值
all_features = pd.get_dummies(all_features, dummy_na=True)
print(all_features.shape)
# 输出:
# (2919, 331)
# 将训练集和测试集分开
# n_train:训练集的样本数
n_train = train_data.shape[0]
# train_features:训练集中的特征集合
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
# test_features:测试集中的特征集合
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
# train_labels:训练集中的标签集合
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
# in_features:每个样本的输入特征维度
in_features = train_features.shape[1]
print(in_features)
# 输出:
# 331
4.10.4 定义网络模型
# 定义网络模型
def get_net():
net = nn.Sequential(nn.Linear(in_features,1)) #网络模型只有1个全连接层,输入维度为331,输出维度为1
return net
4.10.5 定义损失函数
# 定义模型的损失函数
# 定义均方损失函数
loss = nn.MSELoss()
def log_rmse(net, features, labels):
# 将模型的预测标签中小于1的值统一设置为1,clipped_preds为模型的预测标签
clipped_preds = torch.clamp(net(features), 1, float('inf'))
# 预测价格与真实价格之间的损失,表示预测价格与真实价格之间的接近程度
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()
4.10.6 定义训练过程
# net:网络模型
# train_features:训练集特征
# train_labels:训练集标签
# test_features:测试集特征
# test_labels:测试集标签
# num_epochs:训练轮数
# learning_rate:学习率
# weight_decay:L2正则项系数
# batch_size:批量大小
# 进行多轮训练,返回两个列表,一个列表中存放了每轮的训练损失,一个列表中存放了每轮的泛化损失
def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
# 将训练集打乱,然后按照批量大小进行切割和封装
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 定义Adam优化器,并且引入L2正则项
optimizer = torch.optim.Adam(net.parameters(),lr = learning_rate,weight_decay = weight_decay)
# 对于每一轮训练
for epoch in range(num_epochs):
# 对于一个批量的数据
for X, y in train_iter:
# 利用优化器来更新权重和形参
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
# 记录本轮的训练损失
train_ls.append(log_rmse(net, train_features, train_labels))
# 如果测试集存在真实标签,则记录本轮训练结果在测试集上的损失
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
4.10.7 定义K折交叉训练过程
# k:把训练集分为k块
# i:把第i块作为验证集
# X:训练集的输入特征集合
# y:训练集的输出标签
# 对训练集进行划分,将其中的第i块作为验证集,其余的作为训练集,并返回训练集特征、训练集标签、验证集特征,验证集标签
def get_k_fold_data(k, i, X, y):
assert k > 1 # 在k小于等于1时触发异常
fold_size = X.shape[0] // k #求每一块的样本数量
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
# K折交叉验证:
# 将训练分割成K块
# for i = 1,….k
# 使用第i块作为验证数据集,其余的作为训练数据集
# 报告k个验证集误差的平均值
# k:把训练集分为k块
# X_train:训练集的输入特征集合
# y_train:训练集的输出标签
# num_epochs:训练轮数
# learning_rate:学习率
# weight_decay:L2正则化系数
# batch_size:批量大小
# 将训练集划分为K块,分别令每块作为验证集,其余作为训练集进行模型训练,然后返回平均训练误差和平均泛化误差
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):
train_l_sum, valid_l_sum = 0, 0 # 模型的训练误差之和、模型的泛化误差之和
for i in range(k): #把第i块作为验证集
# 对训练集进行划分,将其中的第i块作为验证集,其余的作为训练集
data = get_k_fold_data(k, i, X_train, y_train) #data:(训练集特征、训练集标签、验证集特征,验证集标签)
# 定义网络模型
net = get_net()
# 按照当前的划分,对模型进行训练,并将得到的训练误差和泛化误差进行累加
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 'f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k # 返回平均训练误差和平均泛化误差
4.10.8 进行K折交叉训练
# 定义K、训练轮数、学习率、L2正则项系数、批量大小
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
# 进行K折交叉训练
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
# 输出K则交叉训练得到的平均训练误差和平均泛化误差
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')
# 输出:
# 折1,训练log rmse0.170761, 验证log rmse0.156945
# 折2,训练log rmse0.162245, 验证log rmse0.189869
# 折3,训练log rmse0.163735, 验证log rmse0.168194
# 折4,训练log rmse0.167888, 验证log rmse0.154507
# 折5,训练log rmse0.162521, 验证log rmse0.182383
# 5-折验证: 平均训练log rmse: 0.165430, 平均验证log rmse: 0.170379
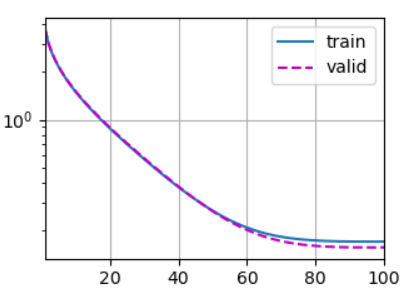
4.10.9 进行常规训练,并预测测试集的结果
# train_features:训练集+验证集特征集合
# test_features:测试集特征集合
# train_labels:训练集+验证集标签集合
# test_data:测试集特征集合(测试集没有标签)
# num_epochs:训练轮数
# lr:学习率
# weight_decay:L2正则项系数
# batch_size:批量大小
# 不进行交叉训练,直接在训练集上进行训练,然后用测试集在网络模型上进行预测,将预测结果写入submission.csv文件中
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):
# 定义网络模型
net = get_net()
# 直接在训练集上进行训练,不进行交叉训练,返回训练误差
train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
# 输出训练误差
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 计算测试集在网络模型中的预测标签
preds = net(test_features).detach().numpy()
# test_data['SalePrice']中一共包含两列,其中第一列为索引序号,第二列为测试集在模型上的预测值
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# test_data['Id']中一共包含两列,其中第一列为索引序号,第二列为样本序号
# 将test_data['SalePrice']和test_data['SalePrice']合并,submission中一共包含三列,其中第一列为索引序号,第二列为样本序号,第三列为测试集在模型上的预测值
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
# 将样本序号和样本的预测值写入到submission.csv文件中
submission.to_csv('submission.csv', index=False)
# 不进行交叉训练,直接在训练集上进行训练,然后用测试集在网络模型上进行预测,将预测结果写入submission.csv文件中
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)
# 输出:
# 训练log rmse:0.162150
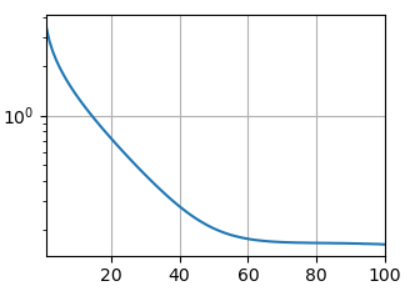
4.10.10 训练结果可视化
plt.savefig('OutPut.png')
本小节完整代码如下
import hashlib
import os
import tarfile
import zipfile
import requests
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
# ------------------------------设置要下载的数据集信息------------------------------------
# 创建一个空字典,用来存放要下载数据集的信息,格式为:(数据集名:(下载地址,加密签名))
DATA_HUB = dict()
# 数据集下载的基地址
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
# 训练集kaggle_house_train的下载地址和加密签名
DATA_HUB['kaggle_house_train'] = (DATA_URL + 'kaggle_house_pred_train.csv','585e9cc93e70b39160e7921475f9bcd7d31219ce')
# 测试集kaggle_house_test的下载地址和加密签名
DATA_HUB['kaggle_house_test'] = (DATA_URL + 'kaggle_house_pred_test.csv','fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
# ------------------------------下载数据集,并将数据集存放到指定路径加下的csv文件中,然后读入训练集和测试集到内存中------------------------------------
# 下载指定的数据集(name)保存到data文件夹下,文件格式为csv,并返回数据集文件路径
def download(name, cache_dir=os.path.join('..', 'data')):
# 判断请求的数据集(name)是否在数据集字典(DATA_HUB)中,如果不在,就抛出异常,并且异常信息为:name 不存在于 DATA_HUB字典
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
# 所请求文件的下载地址,所请求文件的加密签名
url, sha1_hash = DATA_HUB[name]
# 创建data文件夹,用来存放数据集
os.makedirs(cache_dir, exist_ok=True)
# 用来存放数据集的文件相对路径(..\data\kaggle_house_pred_train.csv)
fname = os.path.join(cache_dir, url.split('/')[-1])
# 如果data文件夹下已经存在数据集文件,对文件进行加密签名计算,如果计算出的加密签名和提供的加密签名一致,则返回文件相对地址
if os.path.exists(fname):
# hashlib.sha1:实例化1个sha1对象
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
# sha1.update传入需要加密的信息
sha1.update(data)
# sha1.hexdigest:得到计算出的加密签名
if sha1.hexdigest() == sha1_hash:
return fname # 命中缓存
# 如果计算出的加密签名和提供的加密签名不一致,或者数据集文件不存在,则下载数据集,并创建一个csv文件来存放数据集
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
# 返回数据集文件路径(..\data\kaggle_house_pred_train.csv)
return fname
# 下载指定的数据集(name)保存到data文件夹下,并对其进行解压,返回数据集文件路径
def download_extract(name, folder=None):
# 下载指定的数据集(name)保存到data文件夹下,文件格式为csv,并返回数据集文件路径
fname = download(name) # (..\data\kaggle_house_pred_train.csv)
# 将数据集文件(以".zip"、".tar"、".gz"结尾)进行解压
base_dir = os.path.dirname(fname) # (..\data)
data_dir, ext = os.path.splitext(fname) # (..\data\kaggle_house_pred_train) (.csv)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩'
fp.extractall(base_dir)
# 返回文件路径(不包含后缀名)(..\data\kaggle_house_pred_train)
return os.path.join(base_dir, folder) if folder else data_dir
# 下载数据集字典中的所有数据集文件
def download_all():
"""下载DATA_HUB中的所有文件"""
for name in DATA_HUB:
download(name)
# 下载并读入kaggle_house_train训练集
train_data = pd.read_csv(download('kaggle_house_train'))
# 下载并读入kaggle_house_test测试集
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape)
# 输出:
# (1460, 81) 训练集有1460个样本,每个样本有80个特征,第一列为序号,后面80列为特征
print(test_data.shape)
# 输出:
# (1459, 80) 测试集有1459个样本,每个样本有79个特征,第一列为序号,后面79列为特征,比训练集少了售价这一列
# 取出训练集中前4个样本的前4列和后3列(序号,Id,MSSubClass,MSZoning,LotFrontage,SaleType,SaleCondition,SalePrice)
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
# 输出:
# Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
# 0 1 60 RL 65.0 WD Normal 208500
# 1 2 20 RL 80.0 WD Normal 181500
# 2 3 60 RL 68.0 WD Normal 223500
# 3 4 70 RL 60.0 WD Abnorml 140000
# ------------------------------对训练集和测试集进行预处理------------------------------------
# 将训练集和测试集合并,其中训练集和测试集都去掉第一列序号,另外训练集再去掉最后一列售价
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
print(all_features)
# 输出:
# MSSubClass MSZoning LotFrontage ... YrSold SaleType SaleCondition
# 0 60 RL 65.0 ... 2008 WD Normal
# 1 20 RL 80.0 ... 2007 WD Normal
# 2 60 RL 68.0 ... 2008 WD Normal
# 3 70 RL 60.0 ... 2006 WD Abnorml
# 4 60 RL 84.0 ... 2008 WD Normal
# ... ... ... ... ... ... ... ...
# 1454 160 RM 21.0 ... 2006 WD Normal
# 1455 160 RM 21.0 ... 2006 WD Abnorml
# 1456 20 RL 160.0 ... 2006 WD Abnorml
# 1457 85 RL 62.0 ... 2006 WD Normal
# 1458 60 RL 74.0 ... 2006 WD Normal
# [2919 rows x 79 columns]
# 对数值类型的列进行预处理
# all_features.dtypes 获取每一列的数据类型,其中字符串的数据类型为object
# all_features.dtypes != 'object':获取每一列的数据类型,如果类型为object,就返回False,为object就返回True
# all_features.dtypes[all_features.dtypes != 'object']:
# all_features.dtypes[all_features.dtypes != 'object']:将类型为object的列去掉
# all_features.dtypes[all_features.dtypes != 'object'].index:得到所有类型为数值类型的列的列名
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
print(numeric_features)
# 输出:
# Index(['MSSubClass', 'LotFrontage', 'LotArea', 'OverallQual', 'OverallCond',
# 'YearBuilt', 'YearRemodAdd', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2',
# 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF',
# 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath',
# 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces',
# 'GarageYrBlt', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF',
# 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal',
# 'MoSold', 'YrSold'],
# dtype='object')
# 为了将所有特征都放在一个共同的维度上,通过将特征重新缩放到零均值和单位方差来标准化数据,即对每一列,令(x-均值)/方差
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))# all_features[numeric_features]:所有样本的数据类型为数值的所有列
# 将数值类型列的所有缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 对字符串类型的列进行预处理
# 采用独热编码来替换字符串类型的列,并且将“na”(缺失值)视为有效的特征值
all_features = pd.get_dummies(all_features, dummy_na=True)
print(all_features.shape)
# 输出:
# (2919, 331)
# 将训练集和测试集分开
# n_train:训练集的样本数
n_train = train_data.shape[0]
# train_features:训练集中的特征集合
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
# test_features:测试集中的特征集合
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
# train_labels:训练集中的标签集合
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
# in_features:每个样本的输入特征维度
in_features = train_features.shape[1]
print(in_features)
# 输出:
# 331
# ------------------------------定义网络模型------------------------------------
# 定义网络模型
def get_net():
net = nn.Sequential(nn.Linear(in_features,1)) #网络模型只有1个全连接层,输入维度为331,输出维度为1
return net
# ------------------------------定义损失函数------------------------------------
# 定义模型的损失函数
# 定义均方损失函数
loss = nn.MSELoss()
def log_rmse(net, features, labels):
# 将模型的预测标签中小于1的值统一设置为1,clipped_preds为模型的预测标签
clipped_preds = torch.clamp(net(features), 1, float('inf'))
# 预测价格与真实价格之间的损失,表示预测价格与真实价格之间的接近程度
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()
# ------------------------------定义训练过程------------------------------------
# net:网络模型
# train_features:训练集特征
# train_labels:训练集标签
# test_features:测试集特征
# test_labels:测试集标签
# num_epochs:训练轮数
# learning_rate:学习率
# weight_decay:L2正则项系数
# batch_size:批量大小
# 进行多轮训练,返回两个列表,一个列表中存放了每轮的训练损失,一个列表中存放了每轮的泛化损失
def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
# 将训练集打乱,然后按照批量大小进行切割和封装
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 定义Adam优化器,并且引入L2正则项
optimizer = torch.optim.Adam(net.parameters(),lr = learning_rate,weight_decay = weight_decay)
# 对于每一轮训练
for epoch in range(num_epochs):
# 对于一个批量的数据
for X, y in train_iter:
# 利用优化器来更新权重和形参
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
# 记录本轮的训练损失
train_ls.append(log_rmse(net, train_features, train_labels))
# 如果测试集存在真实标签,则记录本轮训练结果在测试集上的损失
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
# ------------------------------定义K折交叉训练过程------------------------------------
# k:把训练集分为k块
# i:把第i块作为验证集
# X:训练集的输入特征集合
# y:训练集的输出标签
# 对训练集进行划分,将其中的第i块作为验证集,其余的作为训练集,并返回训练集特征、训练集标签、验证集特征,验证集标签
def get_k_fold_data(k, i, X, y):
assert k > 1 # 在k小于等于1时触发异常
fold_size = X.shape[0] // k #求每一块的样本数量
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
# K折交叉验证:
# 将训练分割成K块
# for i = 1,….k
# 使用第i块作为验证数据集,其余的作为训练数据集
# 报告k个验证集误差的平均值
# k:把训练集分为k块
# X_train:训练集的输入特征集合
# y_train:训练集的输出标签
# num_epochs:训练轮数
# learning_rate:学习率
# weight_decay:L2正则化系数
# batch_size:批量大小
# 将训练集划分为K块,分别令每块作为验证集,其余作为训练集进行模型训练,然后返回平均训练误差和平均泛化误差
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):
train_l_sum, valid_l_sum = 0, 0 # 模型的训练误差之和、模型的泛化误差之和
for i in range(k): #把第i块作为验证集
# 对训练集进行划分,将其中的第i块作为验证集,其余的作为训练集
data = get_k_fold_data(k, i, X_train, y_train) #data:(训练集特征、训练集标签、验证集特征,验证集标签)
# 定义网络模型
net = get_net()
# 按照当前的划分,对模型进行训练,并将得到的训练误差和泛化误差进行累加
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 'f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k # 返回平均训练误差和平均泛化误差
# ------------------------------进行K折交叉训练------------------------------------
# 定义K、训练轮数、学习率、L2正则项系数、批量大小
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
# 进行K折交叉训练
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
# 输出K则交叉训练得到的平均训练误差和平均泛化误差
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')
# 输出:
# 折1,训练log rmse0.170761, 验证log rmse0.156945
# 折2,训练log rmse0.162245, 验证log rmse0.189869
# 折3,训练log rmse0.163735, 验证log rmse0.168194
# 折4,训练log rmse0.167888, 验证log rmse0.154507
# 折5,训练log rmse0.162521, 验证log rmse0.182383
# 5-折验证: 平均训练log rmse: 0.165430, 平均验证log rmse: 0.170379
# ------------------------------进行常规训练,并预测测试集的结果------------------------------------
# train_features:训练集+验证集特征集合
# test_features:测试集特征集合
# train_labels:训练集+验证集标签集合
# test_data:测试集特征集合(测试集没有标签)
# num_epochs:训练轮数
# lr:学习率
# weight_decay:L2正则项系数
# batch_size:批量大小
# 不进行交叉训练,直接在训练集上进行训练,然后用测试集在网络模型上进行预测,将预测结果写入submission.csv文件中
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):
# 定义网络模型
net = get_net()
# 直接在训练集上进行训练,不进行交叉训练,返回训练误差
train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
# 输出训练误差
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 计算测试集在网络模型中的预测标签
preds = net(test_features).detach().numpy()
# test_data['SalePrice']中一共包含两列,其中第一列为索引序号,第二列为测试集在模型上的预测值
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# test_data['Id']中一共包含两列,其中第一列为索引序号,第二列为样本序号
# 将test_data['SalePrice']和test_data['SalePrice']合并,submission中一共包含三列,其中第一列为索引序号,第二列为样本序号,第三列为测试集在模型上的预测值
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
# 将样本序号和样本的预测值写入到submission.csv文件中
submission.to_csv('submission.csv', index=False)
# 不进行交叉训练,直接在训练集上进行训练,然后用测试集在网络模型上进行预测,将预测结果写入submission.csv文件中
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)
# 输出:
# 训练log rmse:0.162150
# ------------------------------训练结果可视化------------------------------------
plt.savefig('OutPut.png')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号