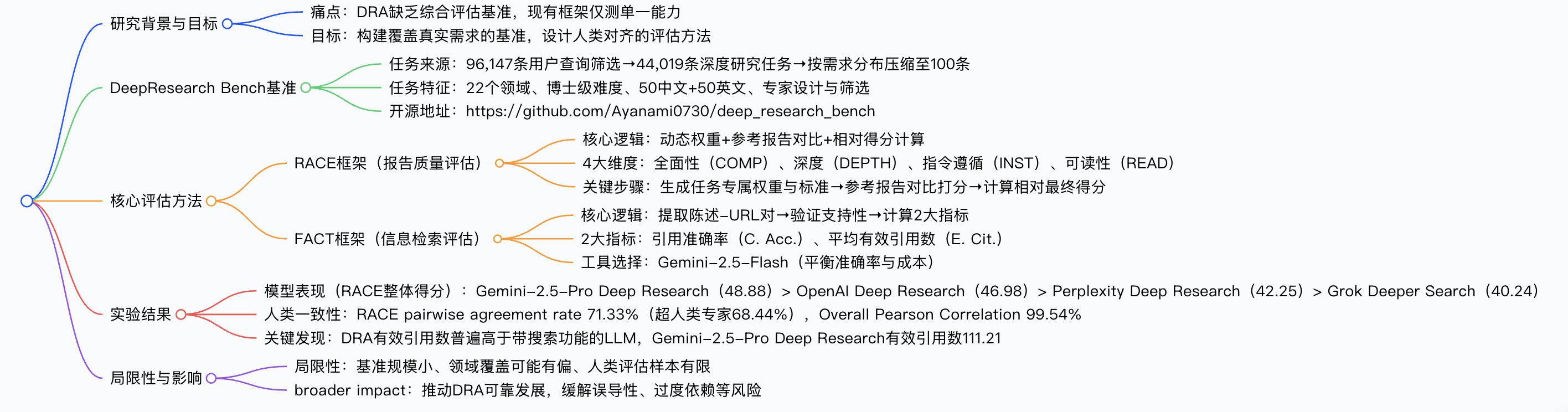
为填补深度研究智能体(DRA)评估的空白,研究团队提出DeepResearch Bench基准,包含 100 个博士级研究任务(覆盖 22 个领域,50 中文 + 50 英文),基于 96,147 条真实用户查询统计设计;同时提出RACE(参考驱动的自适应标准评估框架)和FACT(事实丰富度与引用可信度评估框架)两大评估方法,分别用于评估报告质量(从全面性、深度、指令遵循度、可读性 4 维度动态加权)和信息检索能力(计算引用准确率与平均有效引用数)。实验显示,Gemini-2.5-Pro Deep Research在 RACE 整体得分(48.88)和 FACT 有效引用数(111.21)上表现最优,且 RACE 与人类判断一致性高( pairwise agreement rate 达 71.33%,超人类专家间一致性),目前该基准已开源(https://github.com/Ayanami0730/deep_research_bench)。
![image]()
-
行业痛点
- 深度研究智能体(DRA)可将数小时人工研究压缩至分钟级,但缺乏专门评估基准:现有框架仅测单一能力(如网页浏览、生成能力),无法覆盖 DRA “检索 - 分析 - 报告” 全流程。
- 复杂研究报告评估难度高:无明确 “标准答案”,且内部推理 / 检索过程不透明,仅能通过最终报告判断性能。
-
研究目标
- 构建反映真实需求的 DRA 评估基准(DeepResearch Bench)。
- 设计与人类判断高度对齐的评估方法,分别评估报告质量与信息检索能力。
-
数据来源与任务筛选
- 初始数据:收集 96,147 条带网页搜索功能的 LLM 聊天机器人用户查询,匿名化处理后,用 DeepSeek-V3-0324 筛选出 44,019 条符合 “深度研究任务” 定义的查询(需多轮检索、分析、生成报告)。
- 领域分类:参考 WebOrganizer taxonomy,将 44,019 条任务归为 22 个领域,统计真实需求分布(如科技、金融占比最高,分别 17.80%、16.86%)。
- 最终任务:按真实分布比例压缩至 100 条,50 中文 + 50 英文,由博士或 5 年以上资深从业者设计,经人工筛选确保难度与真实性。
-
基准特征
- 设计逻辑:评估 DRA 检索信息的 “量”(有效引用数)与 “质”(引用准确率)。
- 关键步骤:
- 陈述 - URL 对提取与去重:Judge LLM(Gemini-2.5-Flash)从报告中提取离散陈述及对应 URL,去重重复事实的对。
- 支持性判断:用 Jina Reader API 获取网页内容,Judge LLM 判断内容是否支持陈述(二元结果:支持 / 不支持)。
-
指标计算(表 2):
| 指标 | 定义 | 计算公式 |
|---|
| Citation Accuracy(C. Acc.) |
引用准确率,反映陈述与 URL 的匹配度 |
|
| Average Effective Citations(E. Cit.) |
平均有效引用数,反映有效信息总量 |
|
-
实验设置
- 评估模型:4 个 DRA(Gemini-2.5-Pro Deep Research、OpenAI Deep Research 等)+12 个带搜索功能的 LLM(Claude-3.7-Sonnet w/Search、GPT-4o-Search-Preview 等)。
- Judge LLM 选择:RACE 用 Gemini-2.5-Pro(平衡性能与成本),FACT 用 Gemini-2.5-Flash(与人类判断一致性达 92%-96%,成本更低)。
-
核心结果
-
RACE 框架表现(表 3,仅列 DRA):
| 模型 | RACE 整体得分 | 全面性 | 深度 | 指令遵循 | 可读性 |
|---|
| Gemini-2.5-Pro Deep Research |
48.88 |
48.53 |
48.50 |
49.18 |
49.44 |
| OpenAI Deep Research |
46.98 |
46.87 |
45.25 |
49.27 |
47.14 |
| Perplexity Deep Research |
42.25 |
40.69 |
39.39 |
46.40 |
44.28 |
| Grok Deeper Search |
40.24 |
37.97 |
35.37 |
46.30 |
44.05 |
-
FACT 框架表现(表 4,仅列 DRA):
| 模型 | 引用准确率(%) | 平均有效引用数 |
|---|
| Gemini-2.5-Pro Deep Research |
81.44 |
111.21 |
| OpenAI Deep Research |
77.96 |
40.79 |
| Perplexity Deep Research |
90.24 |
31.26 |
| Grok Deeper Search |
83.59 |
8.15 |
-
人类一致性验证
- 实验设计:50 个中文任务,4 个 DRA 生成报告,70 + 硕士以上专家评分(3 人 / 任务)。
- 关键指标:RACE 的 pairwise agreement rate 达 71.33%(超人类专家间的 68.44%),Overall Pearson Correlation 达 99.54%,证明与人类判断高度对齐。
-
局限性
- 基准规模:100 条任务虽高质量,但统计稳健性不足,需扩大规模。
- 领域偏差:可能存在领域覆盖偏倚,需引入更多外部专家审核。
- 人类评估:仅 600 份报告(50 任务 ×4DRA×3 专家),样本有限。
-
Broader Impact
- 积极:推动 DRA 可靠发展, democratize 深度研究能力。
- 风险缓解:通过 FACT 的事实验证和 RACE 的质量评估,减少误导性、过度依赖等问题。
答案:通过 “数据驱动 + 专家验证” 双环节实现:
- 数据驱动:先收集 96,147 条带网页搜索功能的 LLM 用户查询,匿名化后用 DeepSeek-V3-0324 筛选出 44,019 条符合 “深度研究任务” 定义的查询(需多轮检索、分析、生成报告);再参考 WebOrganizer taxonomy 将其归为 22 个领域,统计真实需求分布(如科技占 17.80%、金融占 16.86%)。
- 专家验证:按真实分布比例将 44,019 条任务压缩至 100 条(50 中文 + 50 英文),由博士或 5 年以上资深从业者设计任务,经人工筛选确保难度(博士级)、清晰度与真实性,最终形成覆盖 22 个领域的基准,完全匹配真实研究场景需求。
答案:RACE 通过 “动态权重 + 参考对比 + 相对得分” 三大设计突破传统框架局限:
![截屏2025-09-04 11.48.13]()
答案:选择 Gemini-2.5-Flash 基于 “准确率 - 成本” 平衡原则,且评估效果与高性能模型持平:
- 选择原因:FACT 需处理 “陈述 - URL 对提取”“支持性判断” 等 token 密集型任务,对成本敏感;Gemini-2.5-Flash 在测试中与人类判断一致性达 92%-96%(“支持” 判断一致 96%,“不支持” 判断一致 92%),准确率接近 Gemini-2.5-Pro,但成本更低,适合大规模评估。
- 评估效果:通过 FACT 的两大指标验证,Gemini-2.5-Flash 能有效区分模型能力:
- 引用准确率:Perplexity Deep Research 以 90.24% 居首,反映其能更精准匹配陈述与 URL;
- 平均有效引用数:Gemini-2.5-Pro Deep Research 达 111.21,显著高于其他模型,证明其检索有效信息的能力更强。 同时,FACT 的评估结果与 RACE 形成互补(如 Gemini-2.5-Pro Deep Research 在 RACE 全面性得分高,对应 FACT 有效引用数多),共同构成 DRA 的综合能力评估。
https://deepresearch-bench.github.io/
2401.04056v2.pdf
2411.15594v5.pdf
2505.10527v1.pdf
![image]()
![image]()

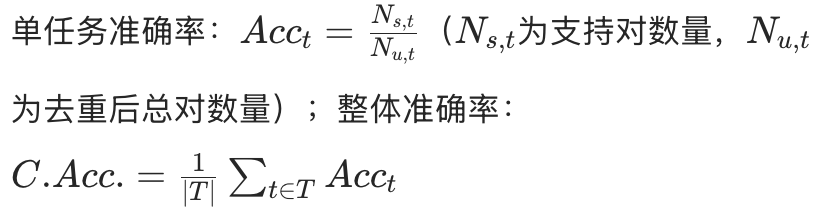




 浙公网安备 33010602011771号
浙公网安备 33010602011771号