HelpSteer2 与 StackExchange 谁是偏好建模的 “最佳拍档”?
1.数据基础对比
| 对比纬度 | StackExchange | HelpSteer2 |
|---|---|---|
| 数据来源 | 基于 Stack Overflow、Server Fault 等多个问答社区的真实用户互动内容。 | 主要来自客户支持场景(如企业客服对话、帮助中心问答),聚焦服务导向的交互数据。 |
| 数据数量 | 500w+ | 9k |
| 内容主题 | 覆盖技术、学术、生活等170+领域(如编程问题、学术讨论、日常咨询)。 | 以产品使用、服务咨询为主(如软件故障排查、订单查询、功能说明)。 |
| 内容质量 | 为 “自然生成”(真实用户提问和回答),质量参差不齐(可能包含错误回答、冗余信息、口语化表达,甚至无效内容,但也有经社区投票验证的优质回答)。 | 为 “人工设计 + 标注”(如专家编写用户请求,再生成或筛选优质回应),或基于真实对话清洗后的结构化数据,质量更可控(如无冗余、无错误)。 |
| 对话结构 | 多为 “提问 - 回答 - 补充讨论” 模式,存在多轮互动,包含用户追问、回答者补充等。 | 更贴近客服场景的 “用户问题 - 客服回应” 结构,对话流程相对固定(问题解决导向)。 |
| 数据规模 | 规模较大,包含数百万条问答数据,覆盖时间跨度长(积累多年用户内容)。 | 规模中等,具体数据量未公开,但更注重数据质量和场景针对性,筛选自真实客服对话。 |
| 语言风格 | 多样化,包含专业术语(技术领域)、口语化表达(生活领域),用户和回答者身份多元。英文为主 | 偏正式、礼貌的服务用语,客服回应需符合行业规范,语言风格更统一(服务导向)。包含多语言 |
| 标注信息 | 标注主要依赖社区互动数据(如 “采纳回答”“高投票回答” 可间接作为 “优质回答” 的信号),但缺乏人工对 “回应质量” 的直接打分,更多是 “用户行为驱动” 的间接质量标识。 | 包含丰富的人工标注(如回应的相关性、安全性、帮助性评分),或任务类型标签(用于区分 “信息类”“指令类” 等),适合训练 “对齐任务”(如奖励模型、指令微调) |
| 适用场景 | 适合通用问答系统、知识检索、多领域对话模型预训练。更适合训练 “领域特定问答模型”(如编程问答、学术问题解答),或用于 “检索增强生成(RAG)” 的知识库构建(利用其高质量领域回答),也可用于研究 “社区驱动的知识生产机制”。 |
适合客服机器人、智能助手、服务领域对话生成(如自动回复、问题分诊)。 更适合训练 “帮助类对话模型” 或 “对齐模型”(如奖励模型、偏好模型),用于优化模型的 “帮助性”“安全性”,或微调模型在特定帮助场景(如客服、个人助理)的表现。 |
| 数据特点 | 开放性强,覆盖范围广,但存在噪声(如低质量回答、无关讨论)。 | 场景聚焦度高,数据质量更可控,贴近实际业务需求,但覆盖领域较窄(以服务为核心)。 |
2.数据长度分布分析
通过对比 HelpSteer2 和 StackExchange 两个数据集的文本长度统计指标,可清晰发现两者在文本长度分布、离散程度及优质 / 劣质回复(chosen/rejected)的特征上存在显著差异,具体对比分析如下:
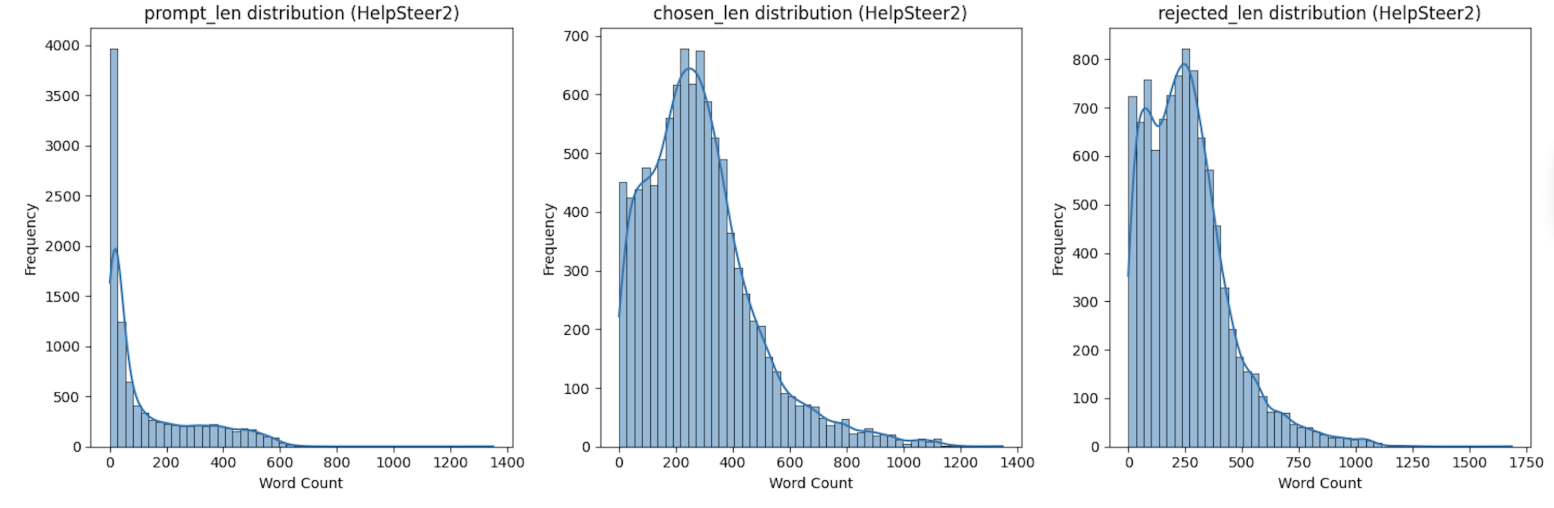
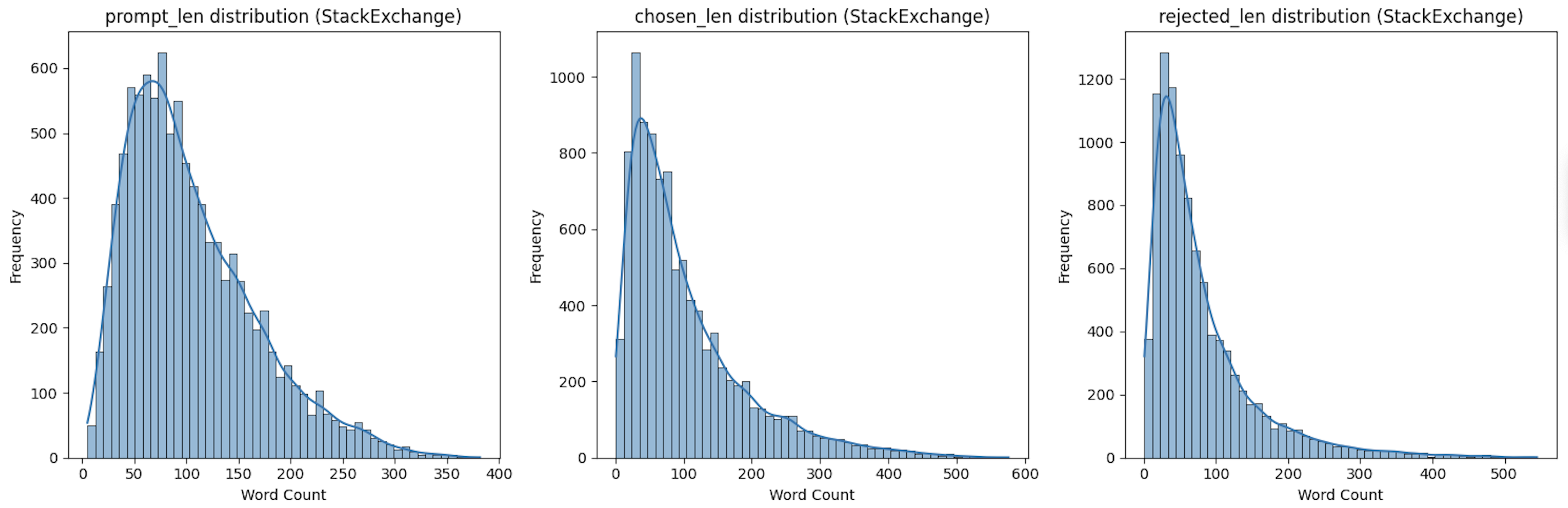
2.1、基础样本量对比
| 数据集 | 样本量(nobs) | 说明 |
|---|---|---|
| HelpSteer2 | 9881 | 近万条样本,规模适中 |
| StackExchange | 9982 | 样本量略多于 HelpSteer2,差距极小(约 1%),具备可比性 |
2.2、各文本类型长度对比(核心差异)
1. prompt 长度(用户提示文本)
| 指标 | HelpSteer2 | StackExchange | 差异解读 |
|---|---|---|---|
| 平均长度 | 135.8 词 | 104.9 词 | HelpSteer2 的提示文本平均更长(约长 30%),说明其用户提问更详细。 |
| 长度范围 | 1-1351 词(跨度极大) | 5-382 词(跨度较小) | HelpSteer2 存在超长长提示(1351 词),而 StackExchange 提示最长仅 382 词,更简洁。 |
| 离散程度(方差) | 27609(标准差≈166 词) | 3820(标准差≈61.8 词) | HelpSteer2 的提示长度差异更大(方差是后者的 7.2 倍),说明提问复杂度差异悬殊。 |
| 偏度(对称性) | 1.31(中等右偏) | 0.99(轻微右偏) | 两者均为右偏分布(多数提示偏短,少数超长),但 HelpSteer2 的长提示比例更高。 |
| 峰度(集中性) | 0.83(平峰,分散) | 0.75(平峰,更分散) | 均为平峰分布,但 StackExchange 的提示长度更分散,无明显集中区间。 |
2. chosen 长度(优质回复)
| 指标 | HelpSteer2 | StackExchange | 差异解读 |
|---|---|---|---|
| 平均长度 | 284.6 词 | 102.8 词 | HelpSteer2 的优质回复平均长度是 StackExchange 的 2.8 倍,内容更详细。 |
| 长度范围 | 1-1348 词 | 1-576 词 | HelpSteer2 的最长优质回复(1348 词)是 StackExchange(576 词)的 2.3 倍,覆盖更复杂的回复场景。 |
| 离散程度(方差) | 37075(标准差≈192.5 词) | 7790(标准差≈88.3 词) | HelpSteer2 的优质回复长度差异更大(方差是后者的 4.8 倍),说明其优质回复既有简短答案,也有超长详解。 |
| 偏度(对称性) | 1.19(中等右偏) | 1.63(强右偏) | StackExchange 的优质回复中,超长回复的比例更高(偏度更大),即 “少数超长回复” 对分布影响更明显。 |
| 峰度(集中性) | 2.14(平峰) | 2.82(接近正态分布峰度 3) | StackExchange 的优质回复长度更集中于均值附近(102.8 词),而 HelpSteer2 更分散。 |
3. rejected 长度(劣质回复)
| 指标 | HelpSteer2 | StackExchange | 差异解读 |
|---|---|---|---|
| 平均长度 | 260.5 词 | 79.3 词 | HelpSteer2 的劣质回复平均长度是 StackExchange 的 3.3 倍,差距比优质回复更显著。 |
| 长度范围 | 1-1686 词(比 chosen 更长) |
1-545 词(比 chosen 略短) |
HelpSteer2 存在劣质但超长的回复(1686 词),而 StackExchange 的劣质回复最长仅 545 词,整体更短。 |
| 离散程度(方差) | 34953(标准差≈186.9 词) | 5356(标准差≈73.2 词) | HelpSteer2 的劣质回复长度差异极大(方差是后者的 6.5 倍),说明其劣质回复质量不稳定(既有过短无效回复,也有冗长低质回复)。 |
| 偏度(对称性) | 1.27(中等右偏) | 2.14(强右偏) | StackExchange 的劣质回复中,超长低质回复的比例远高于 HelpSteer2(偏度是后者的 1.7 倍)。 |
| 峰度(集中性) | 2.56(平峰) | 5.81(尖峰) | StackExchange 的劣质回复长度高度集中(峰度远高于 3),且存在较多极端长值(尾部厚);而 HelpSteer2 更分散。 |
2.3、核心差异总结
2.4、对模型训练的启示
3.数据偏好分布分析
通过对比 StackExchange 和 HelpSteer2 两个数据集的长度差(chosen - rejected) 和语义相似度指标,可清晰发现两者在 “优质回复与劣质回复的差异特征” 上存在显著不同,具体分析如下:
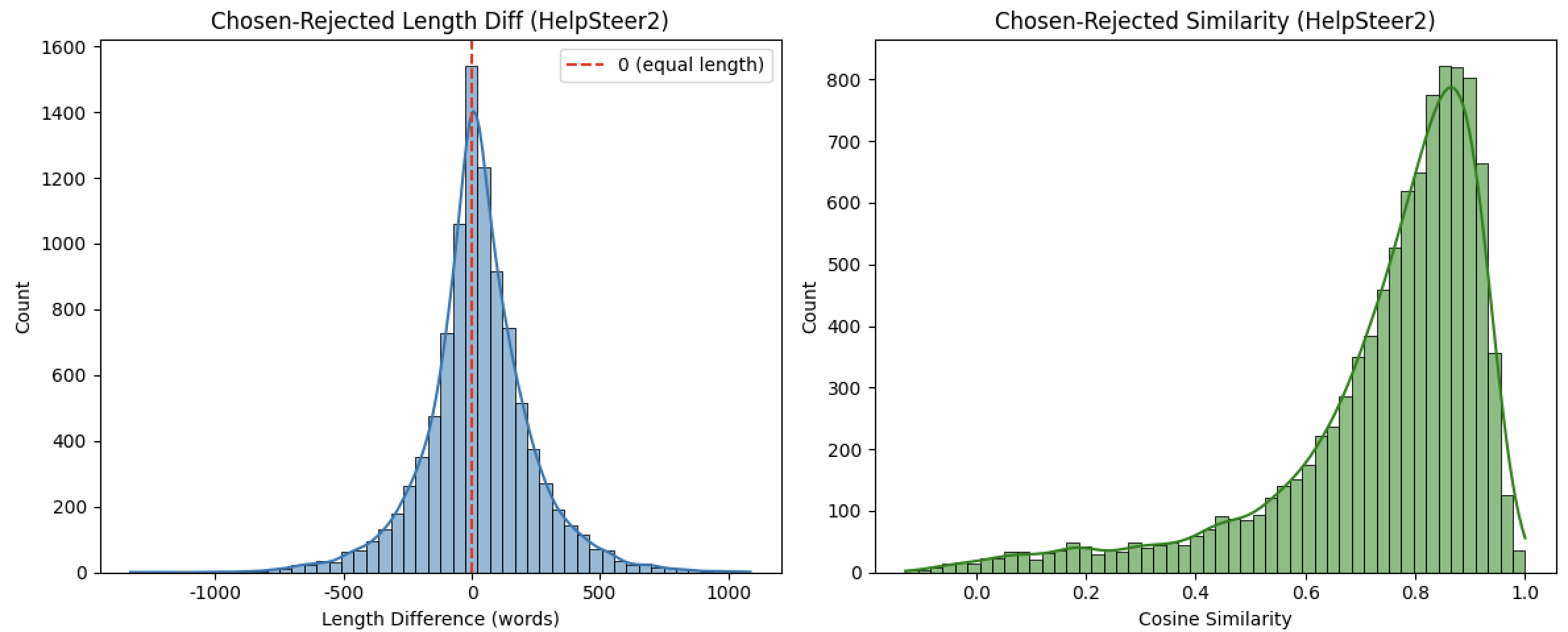
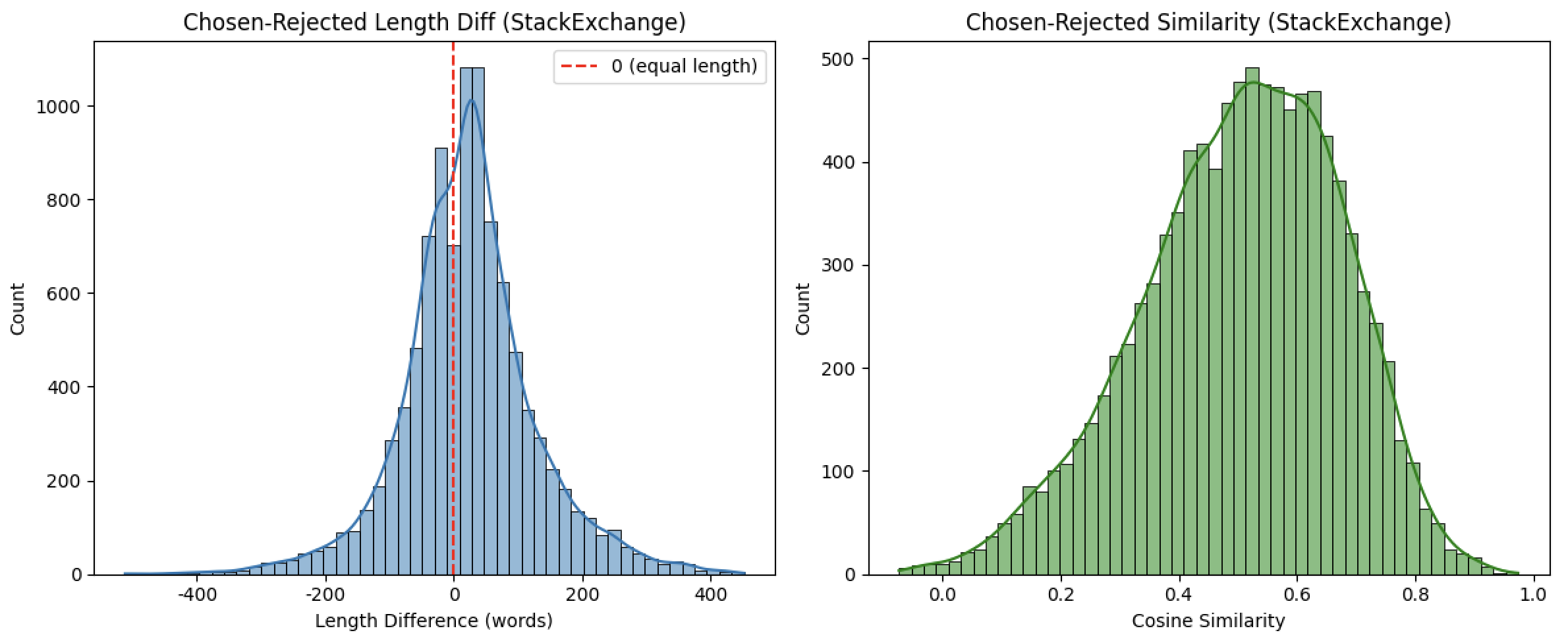
3.1、长度差(chosen - rejected):优质回复与劣质回复的长度差异
| 指标 | StackExchange | HelpSteer2 | 差异解读 |
|---|---|---|---|
| nobs | 9982 | 9881 | 样本量接近(约 1 万条),具备可比性。 |
| minmax | (-512, 452) | (-1330, 1085) | HelpSteer2 的长度差范围显著更大: - 最小值 - 1330(劣质回复比优质回复长 1330 词)和最大值 1085(优质回复比劣质回复长 1085 词)均远超过 StackExchange,说明其回复长度波动更极端(存在极长的劣质回复或极长的优质回复)。 |
| mean | 23.52 词 | 24.04 词 | 两个数据集的平均长度差几乎一致:优质回复平均比劣质回复长约 24 词,说明 “优质回复更长” 是两个数据集的共同规律。 |
| variance | 10965.59(标准差≈104.7 词) | 43974.65(标准差≈209.7 词) | HelpSteer2 的方差是 StackExchange 的 4 倍,说明其长度差分布更分散:个体差异极大(有的优质回复比劣质回复短 1000 + 词,有的长 1000 + 词),而 StackExchange 的长度差相对集中。 |
| skewness | 0.10(接近对称) | 0.02(接近对称) | 两者均接近对称分布,说明 “优质回复比劣质回复长” 和 “劣质回复比优质回复长” 的极端情况比例大致均衡,无明显偏向。 |
| kurtosis | 1.80(平峰) | 2.58(接近尖峰) | HelpSteer2 的峰度更高,说明其长度差虽然整体分散,但仍有较多样本集中在均值(24 词)附近,且极端值(超长差)的比例高于 StackExchange。 |
3.2、语义相似度:优质回复与劣质回复的内容相关度
| 指标 | StackExchange | HelpSteer2 | 差异解读 |
|---|---|---|---|
| nobs | 9982 | 9881 | 样本量接近,具备可比性。 |
| minmax | (-0.073, 0.974) | (-0.129, 1.0) | HelpSteer2 的相似度范围更宽: - 最小值更低(-0.129),说明存在优质与劣质回复语义完全相反的情况; - 最大值达 1.0,说明存在两者语义完全相同的情况(可能因其他维度如逻辑性、详略度被区分)。 |
| mean | 0.505(中等相关) | 0.743(高度相关) | 核心差异:HelpSteer2 中优质与劣质回复的语义相似度显著更高(0.743 vs 0.505),说明其优质回复并非 “完全替换” 劣质回复,而是在相似内容基础上优化(如更准确、更详细);而 StackExchange 中两者语义差异更大(可能是方向不同的回复)。 |
| variance | 0.0285(标准差≈0.169) | 0.0378(标准差≈0.194) | 两者方差均较小,说明相似度分布相对集中,但 HelpSteer2 略分散(因存在极端值 1.0 和 - 0.129)。 |
| skewness | -0.39(轻微左偏) | -1.77(强左偏) | - StackExchange 轻微左偏:多数相似度略高于均值(0.505),但分布较均衡; - HelpSteer2 强左偏:绝大多数相似度远高于均值(0.743),即 “优质与劣质回复高度相似” 是普遍现象,低相似度样本极少。 |
| kurtosis | -0.12(接近正态分布) | 3.23(尖峰分布) | HelpSteer2 峰度 > 3,说明相似度高度集中在 0.7-0.9 区间(多数样本语义高度相关);StackExchange 峰度接近正态,相似度在 0.3-0.7 区间分布更均匀。 |
3.3、总结:两个数据集的偏好差异特征
这些特征可指导模型训练:若训练 “内容优化型” 奖励模型(如在相似内容上区分优劣),优先用 HelpSteer2;若训练 “方向判断型” 奖励模型(如区分正确与错误回复),StackExchange 更合适。
4.数据主题分布分析
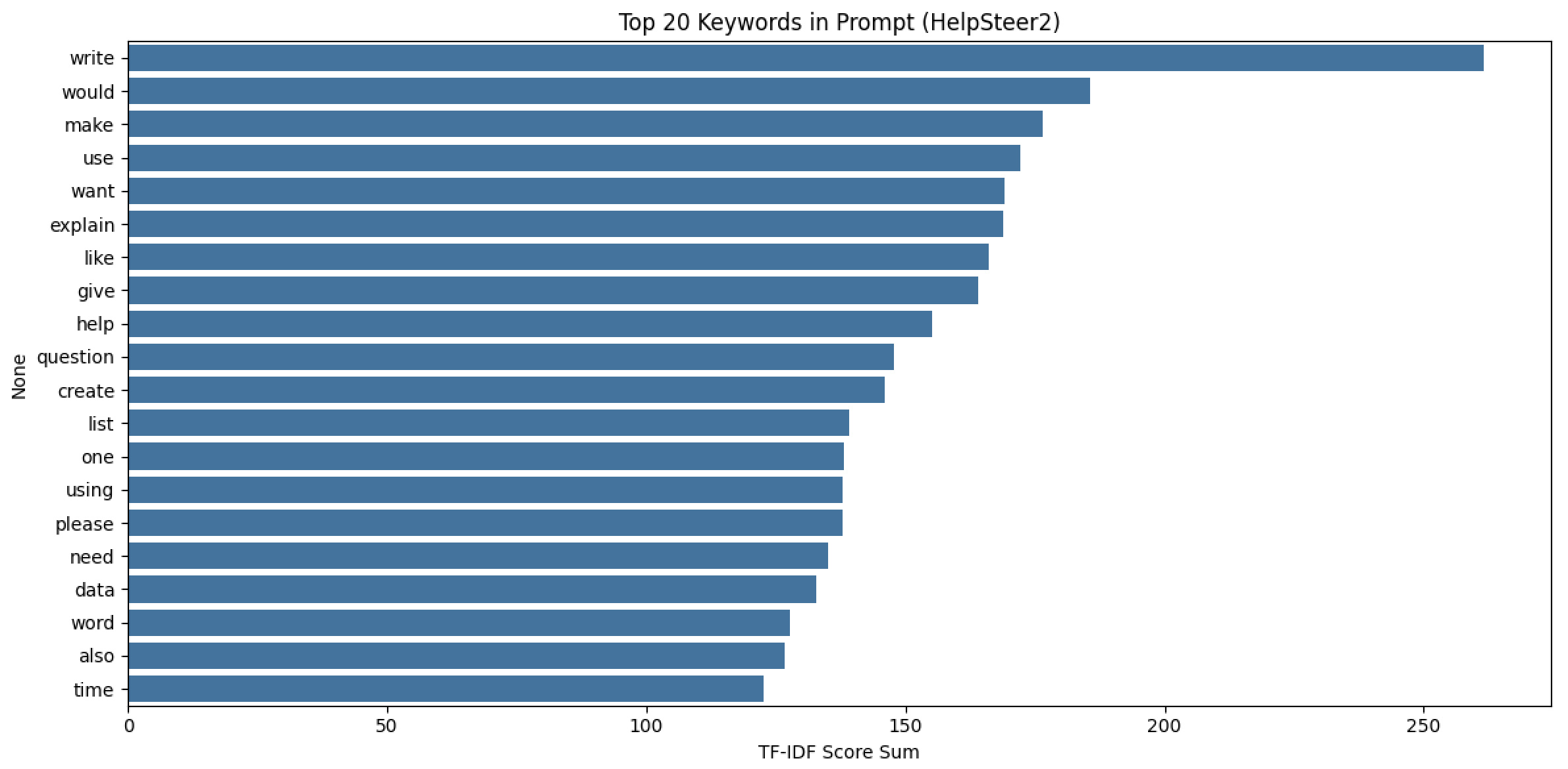
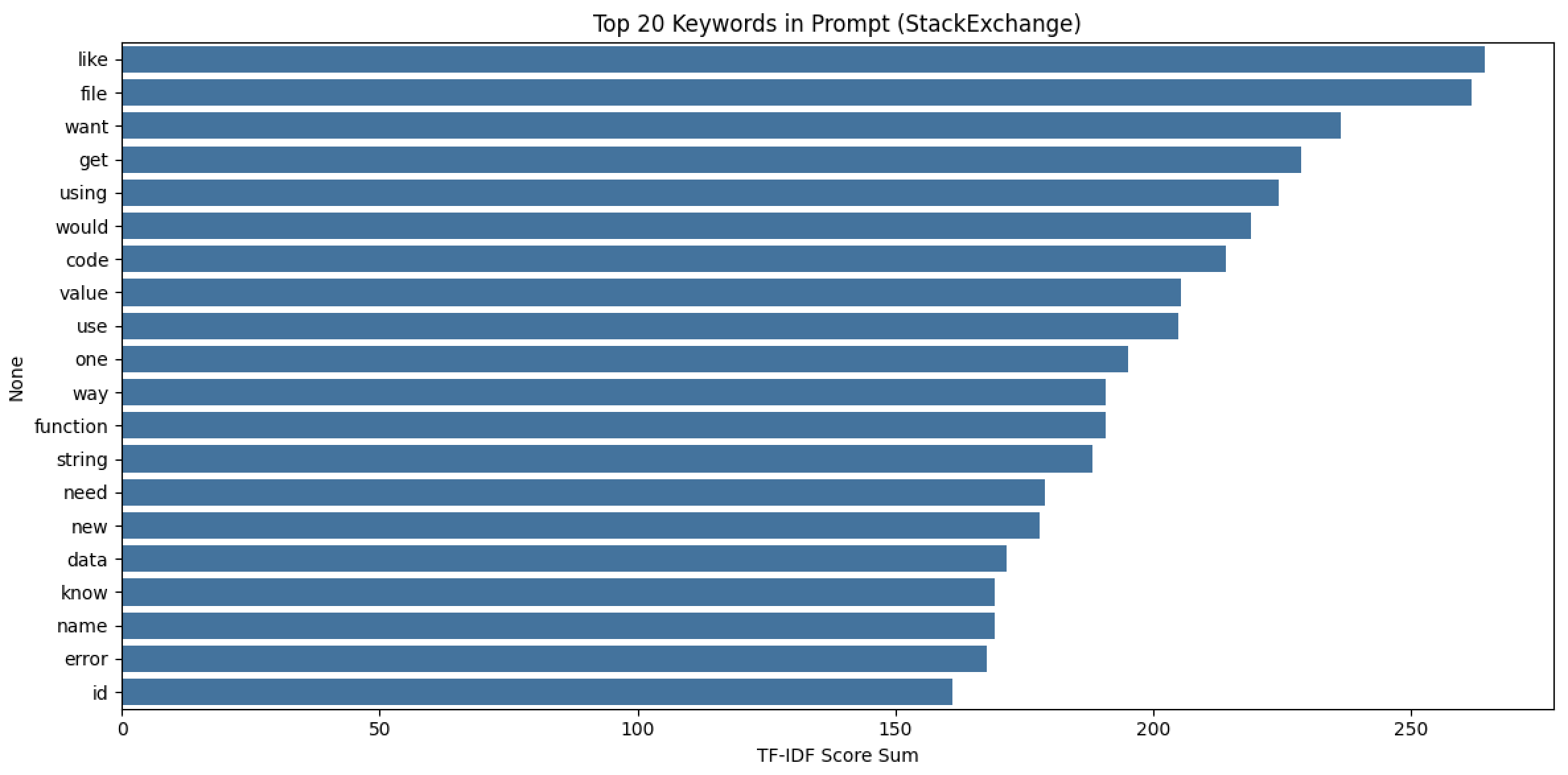
对比 StackExchange 和 HelpSteer2 两个数据集的高频关键词(Top 20),可以清晰发现它们在用户提问场景、核心需求上的显著差异,具体分析如下:
4.1、共同高频关键词(重叠度分析)
两个数据集共有的高频词有 7 个:like、want、use、would、using、need、data
这些词均为表达 “需求”“意图” 的通用词汇(如 want“想要”、need“需要”、use“使用”),说明无论哪个场景,用户提问的核心都是 “表达自己的需求或目标”。
4.2、差异关键词(场景与需求的核心区别)
1. StackExchange 特有高频词(技术 / 工具导向)
2. HelpSteer2 特有高频词(创作 / 解释导向)
4.3、场景与需求总结
| 维度 | StackExchange | HelpSteer2 |
|---|---|---|
| 核心场景 | 技术问答(编程、开发、工具使用) | 创作与解释(写作、提问、内容生成) |
| 用户需求 | 解决具体技术问题(调试、操作、实现) | 完成创作任务或获取解释(写作、列清单、理解概念) |
| 提问风格 | 直接、目标明确(“如何用代码实现 XX”) | 委婉、互动性强(“请解释 XX”“帮我写 XX”) |
| 高频词背后逻辑 | 聚焦 “技术元素” 和 “操作步骤” | 聚焦 “创作行为” 和 “交互请求” |
4.4、关键词重叠度与主题关联
这些关键词特征可进一步指导模型训练:例如,针对 StackExchange 优化 “技术术语理解与问题解决能力”,针对 HelpSteer2 强化 “创作辅助与解释能力”。
5.跨数据集分布分析
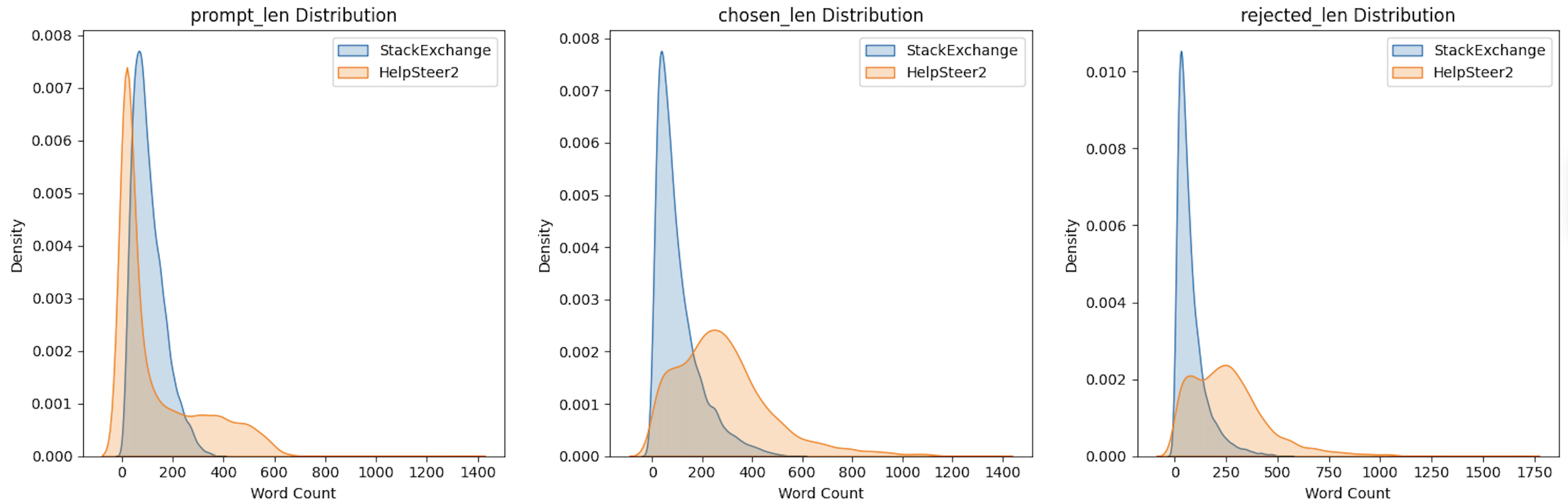
这组图对比了 StackExchange 和 HelpSteer2 数据集在 Prompt(提问)、Chosen(优质回复)、Rejected(劣质回复) 三个维度的文本长度分布规律,能得出以下核心结论:
5.1.1、Prompt(提问)长度分布(左图)
5.1.2、Chosen(优质回复)长度分布(中图)
5.1.3、Rejected(劣质回复)长度分布(右图)
5.1.4、综合结论:数据集的场景与需求差异
| 维度 | StackExchange | HelpSteer2 |
|---|---|---|
| 核心场景 | 技术问答(编程、开发) | 创作 / 解释(写作、内容优化) |
| 内容长度规律 | 提问、回复均更 “短而精”,长度稳定 | 提问更短、回复更长,长度波动更大 |
| 优质回复标准 | 优先 “精准解决问题”(正确性 > 长度) | 优先 “详细优化内容”(质量 > 简洁性) |
| 模型训练启示 | 需适应 “短文本、高精准” 的回复逻辑 | 需适应 “长文本、多细节” 的优化逻辑 |
简单来说:
这种差异会直接影响模型对 “优质回复” 的理解(是短而准,还是长而优),需根据场景调整训练策略。
5.2 偏好差异 && 相似度差异
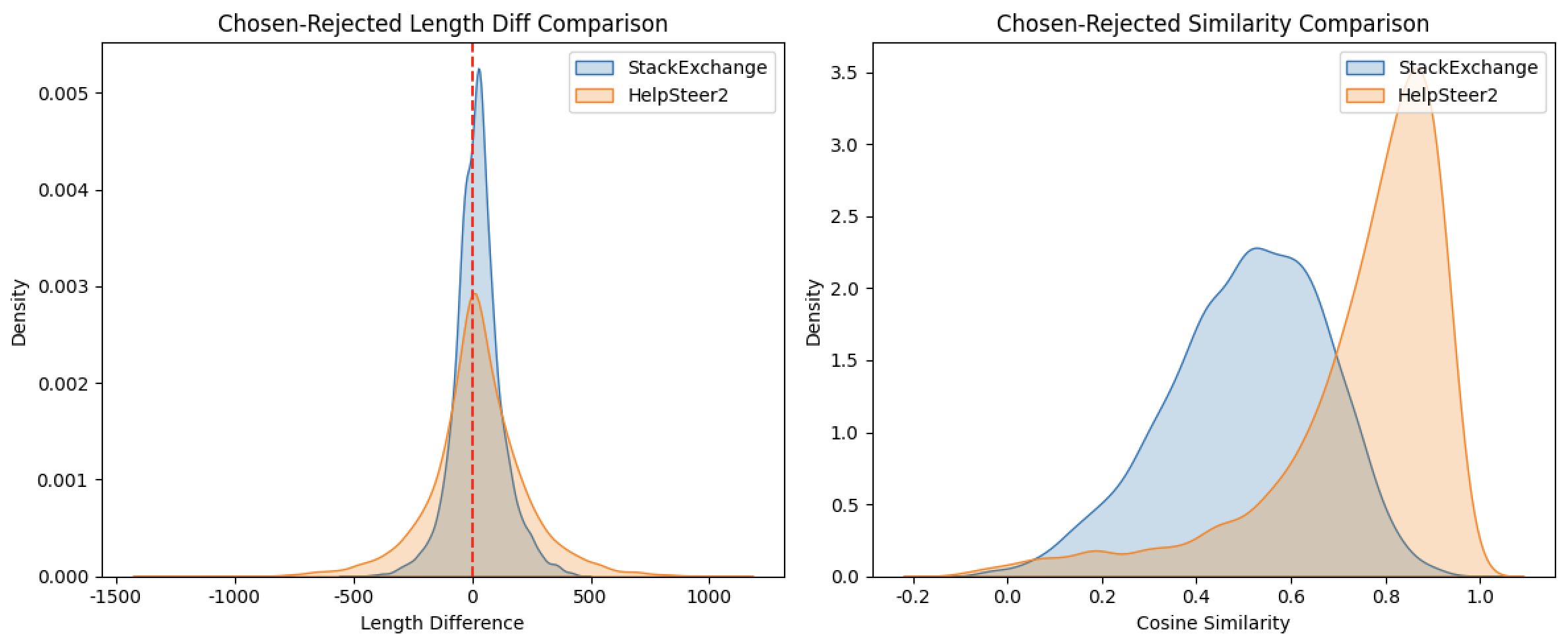
从这两张分布图(长度差异、语义相似度)能得出以下核心结论,可结合数据特征和场景差异理解:
5.2.1、长度差异(左图:Chosen-Rejected Length Diff)
5.2.2、语义相似度(右图:Chosen-Rejected Similarity)
5.2.3、综合结论:两个数据集的 “优质回复标准” 差异
| 维度 | StackExchange | HelpSteer2 |
|---|---|---|
| 优质回复核心逻辑 | 更关注正确性、技术可行性(语义差异大,可能直接替换错误思路) | 更关注质量优化、细节完善(语义高度相关,在相似内容上做提升) |
| 场景暗示 | 偏向技术问答(如编程问题,正确解法与错误尝试差异大) | 偏向创作 / 解释场景(如写作、内容生成,优质回复是对初稿的优化) |
| 模型训练启示 | 需强化 “判断正确 / 错误逻辑” 的能力 | 需强化 “区分内容优劣细节” 的能力(如详略、准确性、表达清晰性) |
简单来说:
这种差异会直接影响模型训练方向(是学 “对错判断” 还是 “优劣打磨”),也反映了两个数据集的应用场景不同(技术问题 vs 创作辅助)。

课程目前优惠中下单链接:https://study.163.com/course/courseMain.htm?share=2&shareId=480000002313477&courseId=1213834824&_trace_c_p_k2_=7fde5d2df42143b89d5c69025dbfd3f2
本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/19012639

 浙公网安备 33010602011771号
浙公网安备 33010602011771号