

GPT生成参数微调
在 GPT 等大语言模型中,top-p(核采样)和top-k(顶部 k 采样)是控制文本生成多样性与质量的核心参数,属于生成阶段的超参数调优范畴(与训练时的参数优化不同)。以下是其技术原理、调优方法及实际应用策略:
一、核心概念与原理
1. top-k 采样:固定范围的候选词筛选
· 定义:从概率分布中选择概率最高的前 k 个 token,仅在这 k 个 token 中随机采样。
· 数学逻辑:
- 原始概率分布:
![]()
- 筛选后分布:
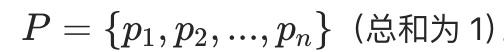
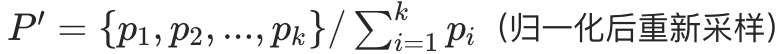
· 作用:
- 限制低质量候选:避免模型选择概率极低的 token(如拼写错误或语义无关的词)。
- 平衡多样性与质量:k 值越大,候选词越多,生成越随机;k 值越小,结果越聚焦(k=1 时等价于贪心解码)。
· 典型场景:
- k=50:适用于对话系统或故事生成,保留中等多样性。
- k=20:适合技术文档生成,减少无关词汇的干扰56。
- 定义:按概率降序累加 token 的概率,直到累积概率达到阈值 p,仅在这部分 token 中采样。
- 数学逻辑:
- 排序后概率:
![]()
- 筛选条件:
![]()
- 排序后概率:
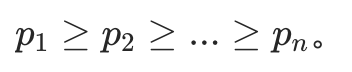
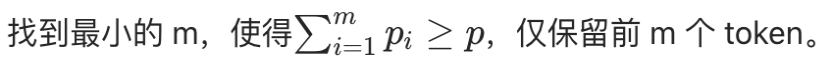
2. top-p 采样:动态范围的核采样
- 作用:
- 动态适应概率分布:当概率分布集中时,m 较小(如 p=0.9 时可能仅需前 3 个 token);当分布分散时,m 较大(如 p=0.9 可能需要前 20 个 token)。
- 保留长尾创意词:允许低概率但有创意的 token 进入候选集,同时过滤掉尾部噪声27。
- 典型场景:
- p=0.9:适合诗歌或小说生成,平衡创意与连贯性。
- p=0.75:适合问答系统,确保回答紧扣主题68。
- top-k 调优:
- 增大 k:增加候选词范围,提升多样性,但可能引入低质量 token。
- 减小 k:减少候选词范围,提升生成质量,但可能导致重复或机械的输出。
- top-p 调优:
- 增大 p:扩大候选词范围,生成更开放、随机(如 p=0.99 时几乎覆盖所有可能 token)。
- 减小 p:缩小候选词范围,生成更聚焦、保守(如 p=0.5 时仅保留概率最高的 50% token)。
- 协同使用:
- 同时设置 top-k 和 top-p 时,模型会优先满足更严格的条件。例如:
- 若 top-k=50 且 top-p=0.9,模型会先筛选前 50 个 token,再从中选择累积概率≥0.9 的子集6。
- 若 top-p=0.8 且 top-k=30,模型会先筛选累积概率≥0.8 的 token,若数量超过 30,则仅保留前 30 个4。
- 同时设置 top-k 和 top-p 时,模型会优先满足更严格的条件。例如:
- 温度的作用:
- 调整概率分布的平滑度:低温(如 0.3)使分布陡峭,高概率词主导;高温(如 1.2)使分布平坦,低概率词被激活。
- 组合策略:
- 高确定性场景(如技术文档):
- 低温(0.2-0.5) + 小 top-k(20-30) + 低 top-p(0.8-0.9)。
- 示例:temperature=0.3, top_k=20, top_p=0.8,生成严格遵循逻辑的文本。
- 高确定性场景(如技术文档):
- 高创造性场景(如小说续写):
- 高温(1.0-1.5) + 大 top-k(100-200) + 高 top-p(0.95-0.99)。
- 示例:temperature=1.2, top_k=100, top_p=0.95,允许更多意外但合理的词汇组合67。
- 重复惩罚(Repetition Penalty):
- 原理:对已生成过的 token 降低概率,避免重复内容。
- 调优:惩罚系数通常设为 1.1-1.5。例如:
- repetition_penalty=1.2:若 token 已出现,其概率降低 20%。
- 长度惩罚(Length Penalty):
- 原理:对长序列进行惩罚,避免生成冗长内容。
- 调优:系数设为 0.6-1.0。例如:
- length_penalty=0.8:长序列的得分会被乘以 0.8,鼓励模型提前终止49。
二、调优策略与协同作用
1. 参数调整的核心原则
2. 与温度(temperature)的联动
3. 与其他参数的协同
三、实际应用中的调优步骤
1. 明确任务目标:
- 优先质量(如代码生成):小 top-k + 低 top-p + 低温。
- 优先创意(如广告文案):大 top-k + 高 top-p + 高温。
2. 分步调参:
- 第一步:固定温度(如 0.7),调整 top-k 或 top-p,观察生成结果的多样性与连贯性。
- 第二步:根据结果微调温度,例如:
- 若生成过于机械,提高温度至 1.0;
- 若生成偏离主题,降低温度至 0.5。
3. 组合实验:
- 尝试不同参数组合,例如:
- top_k=50, top_p=0.9, temperature=0.8(平衡对话);
- top_k=100, top_p=0.99, temperature=1.2(创意写作)。
4. 监控指标:
- 多样性:生成多组结果,统计重复 token 或短语的比例。
- 相关性:检查生成内容是否紧扣输入主题(如使用 BLEU 等指标评估)。
- 逻辑连贯性:人工评估生成文本的语法和语义合理性67。
- 目标:高准确性、低重复。
- 参数组合:
- temperature=0.3(低温)
- top_k=20(限制候选词范围)
- top_p=0.8(聚焦高概率词)
- repetition_penalty=1.3(强惩罚重复)
- 效果:生成严谨、专业的技术描述,避免冗余。
- 目标:自然流畅、适度随机。
- 参数组合:
- temperature=0.7(平衡随机性)
- top_k=50(中等候选范围)
- top_p=0.95(允许少量低概率词)
- length_penalty=0.9(避免过长回复)
- 效果:生成符合语境的对话,同时保持一定灵活性。
- 目标:高创意、非常规词汇组合。
- 参数组合:
- temperature=1.5(高温激活长尾词)
- top_k=200(扩大候选范围)
- top_p=0.99(几乎覆盖所有可能词)
- 关闭repetition_penalty(允许隐喻性重复)
- 效果:生成富含意象和隐喻的诗句,突破常规语言模式78。
四、典型应用场景与参数建议
1. 技术文档生成
2. 开放域对话
3. 诗歌创作
五、注意事项与常见问题
1. 参数冲突:
- 同时设置 top-k 和 top-p 时,模型会优先满足更严格的条件。例如:
- top_k=50且top_p=0.9,若前 50 个 token 的累积概率已超过 0.9,则仅使用前 50 个 token;
- 若前 50 个 token 的累积概率不足 0.9,则自动扩大候选范围至满足 p=0.96。
2. 模型敏感性:
- 不同模型(如 GPT-3、Llama、Claude)对参数的响应不同。例如:
- GPT-3 可能对 top-p 更敏感,而 Llama 可能对 top-k 更敏感,需通过实验确定最佳配置6。
3. 长文本生成:
- 高温或高 top-p 可能导致长文本偏离主题。建议采用动态调参:
- 初始段落使用高温(如 1.0)激发创意;
- 后续段落降低温度至 0.6,维持连贯性7。
top-p 和 top-k 是 GPT 生成调优的 “双引擎”:top-p 通过动态候选集平衡多样性与质量,top-k 通过固定范围过滤低质量词。实际应用中需结合温度、重复惩罚等参数,根据任务需求灵活调整。核心原则是:高质量任务用小范围 + 低温,高创意任务用大范围 + 高温,并通过实验逐步校准参数组合,最终在 “确定性” 与 “创造性” 之间找到最优解。

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18993982

 浙公网安备 33010602011771号
浙公网安备 33010602011771号