Transformer原理与实现详解:从零入门到实战
本文将从 Transformer的本质、Transformer的原理 和 Transformer架构改进三个方面,搞懂Transformer。
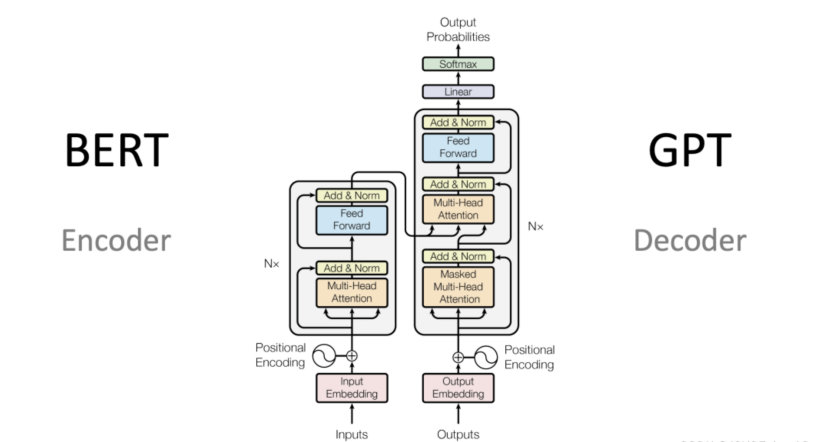
一、Transformer的本质
Transformer的核心原理基于自注意力机制,通过编码器-解码器架构实现序列到序列的转换,其核心创新在于并行处理能力和长距离依赖捕捉技术。
整体架构设计
(1)输入部分
源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
位置编码层:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
(2)编码器部分
- 由N个编码器层堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是多头自注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
(3)解码器部分
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接层。每个子层后都接有一个规范化层和一个残差连接。
(4)输出部分
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
2. Encoder-Decoder(编码器-解码器)
左边是N个编码器,右边是N个解码器,Transformer中的N为6。
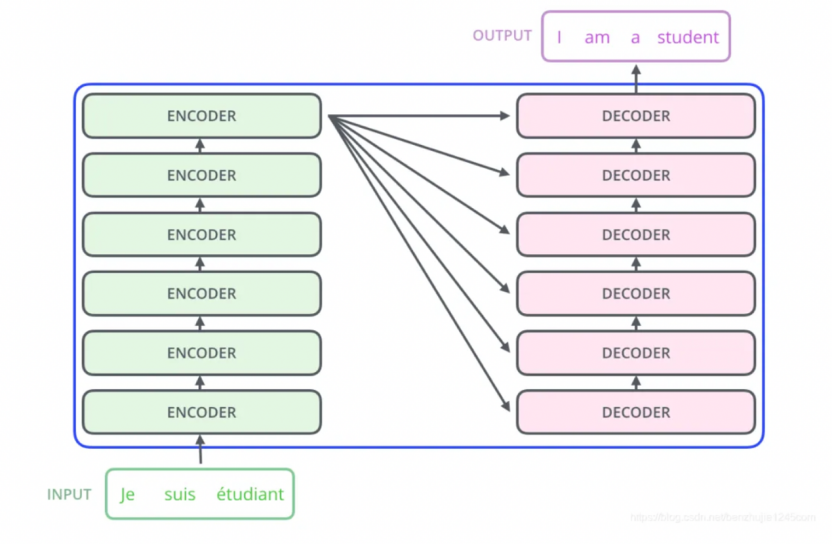
Encoder-Decoder (编码器-解码器)
(1)Encoder 编码器
· Transformer中的编码器部分一共6个相同的编码器层组成。
· 每个编码器层都有两个子层,即多头自注意力层(Multi-Head Attention)层和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为 Add&Norm 操作。

Encoder(编码器)架构
(2)Decoder 解码器
Transformer中的解码器部分同样有6个相同的解码器层组成。
每个解码器层都有三个子层,掩码自注意力层(Masked Self-Attention)、Encoder-Decoder自注意力层、逐位置的前馈神经网络。同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为 Add&Norm操作。
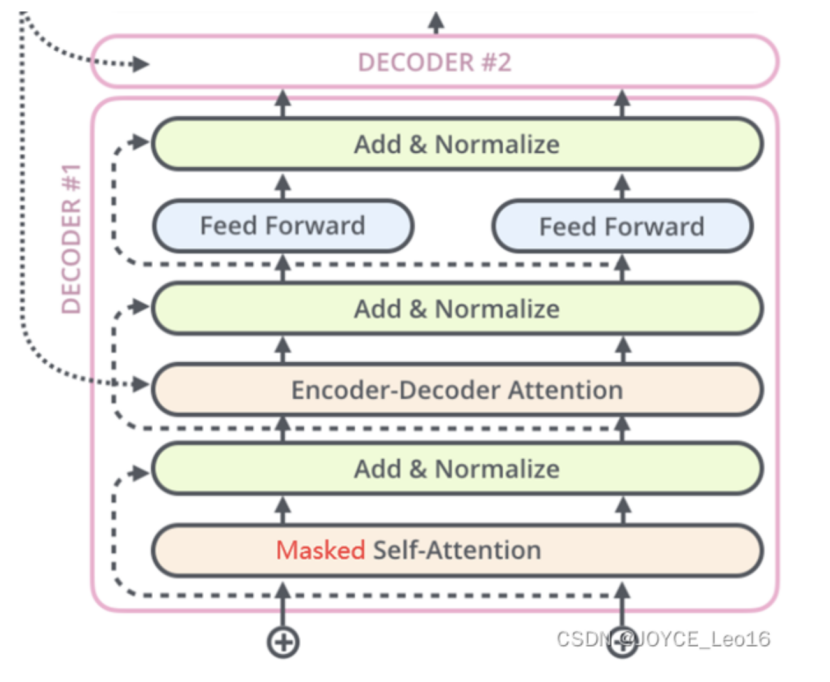
Decoder(解码器)架构
二、Transformer的原理
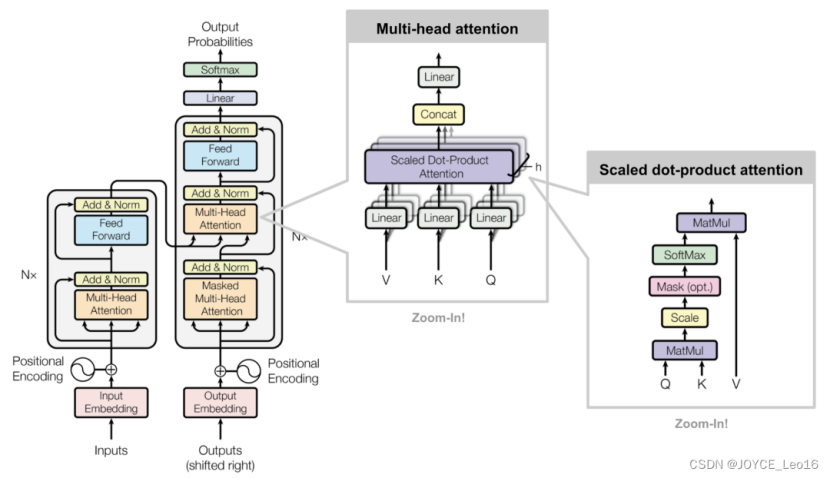
Transformer工作原理
1. Multi-Head Attention(多头自注意力)
它允许模型同时关注来自不同位置的信息。通过分割原始的输入向量到多个头(head),每个头都能独立地学习不同的注意力权重,从而增强模型对输入序列中的不同部分的关注能力。
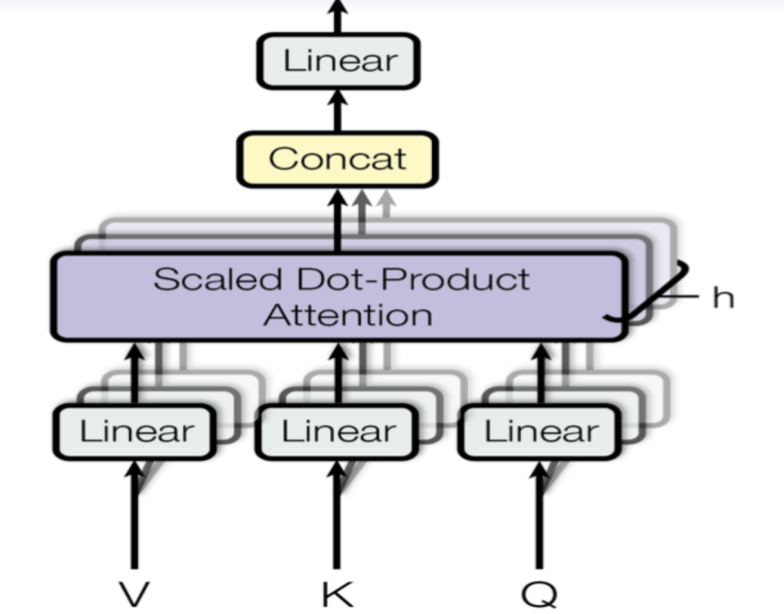
Multi-Head Attention(多头自注意力)
(1)输入线性变换
对于输入的Query(查询)、Key(键)和Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
(2)分割多头
经过线性变换后,Query、Key和Value向量被分割成多个头。每个头部都会独立地进行注意力计算。
(3)缩放点积注意力
在每个头内部,使用缩放点积注意力来计算Query和Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。
(4)注意力权重应用
将计算出的注意力权重应用于Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
(5)拼接和线性变换
将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的Multi-Head Attention输出。
2. Scaled Dot-Product Attention(缩放点积注意力)
它是Transformer模型中的多头注意力机制的一个关键组成部分。
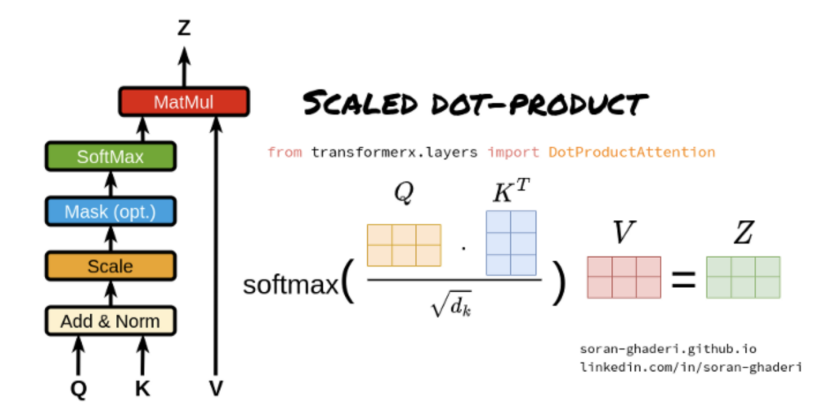
Scaled Dot-Product Attention(缩放点积注意力)
(1)Query、Key和Value矩阵
Query矩阵(Q):表示当前的关注点或信息需求,用于与Key矩阵进行匹配。
Key矩阵(K):包含输入序列中各个位置的标识信息,用于被Query矩阵查询匹配。
Value矩阵(V):存储了与Key矩阵相对应的实际值或信息内容,当Query与某个Key匹配时,相应的Value将被用来计算输出。
(2)点积计算
通过计算Query矩阵和Key矩阵之间的点积(即对应元素相乘后求和),来衡量Query与每个Key之间的相似度或匹配程度。
(3)缩放因子
由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致softmax函数在计算注意力权重时进入饱和区。为了避免这个问题,缩放点积注意力引入了一个缩放因子,通常是输入维度的平方根。点积结果除以这个缩放因子,可以使得softmax函数的输入保持在一个合理的范围内。
(4)Softmax函数
将缩放后的点积结果输入到softmax函数中,计算每个Key相对于Query的注意力权重。Softmax函数将原始得分转换为概率分布,使得所有的Key的注意力权重之和为1。
(5)加权求和
使用计算出的注意力权重对Value矩阵进行加权求和,得到最终的输出。这个过程根据注意力权重的大小,将更多的关注放在与Query更匹配的Value上。
三、Transformer架构改进
1. BERT
BERT 是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了 双向Transformer编码器 ,这使得模型可以同时考虑输入序列的前后上下文信息。

BERT架构
(1)输入层(Embedding)
Token Embeddings:将单词或字词转换为固定维度的向量。
Segment Embeddings:用于区分句子对中的不同句子。
Position Embeddings:由于Transformer模型本身不具备处理序列顺序的能力,所有需要加入位置嵌入来提供序列中单词的位置信息。
(2)编码层(Transformer Encoder)
BERT模型使用双向Transformer编码器进行编码。
(3)输出层(Pre-trained Task-specific Layers)
MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。
NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。
2. GPT
GPT 也是一种基于Transformer的预训练语言模型,它的最大创新之处在于使用了 单向Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。
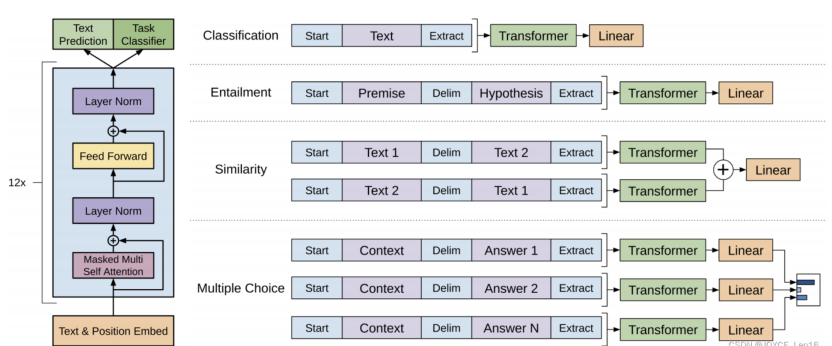
(1)输入层(Input Embedding)
将输入的单词或符号转换为固定维度的向量表示。
可以包括词嵌入、位置嵌入等,以提供单词的语义信息和位置信息。
(2)编码层(Transformer Encoder)
GPT模型使用单向Transformer编码器进行编码和生成。
(3)输出层(Output Linear and Softmax)
线性输出层将最后一个Transformer Decoder Block的输出转换为词汇表大小的向量。
Softmax函数将输出向量转换为概率分布,以便进行词汇选择或生成下一个单词。
四、Transformer实现
下面我们使用PyTorch实现一个简化版的Transformer模型,帮助理解其内部机制
4.1 自注意力实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(SelfAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# 定义Q、K、V的线性变换
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
# 输出线性变换
self.fc = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size = x.size(0)
# 线性变换并分割成多头
Q = self.W_q(x).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = self.W_k(x).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = self.W_v(x).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
# 应用掩码(解码器用)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attention = F.softmax(scores, dim=-1)
# 加权求和
out = torch.matmul(attention, V)
# 拼接多头结果
out = out.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 最终线性变换
out = self.fc(out)
return out
4.2 Transformer编码器层实现
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = SelfAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 多头自注意力子层
attn_output = self.self_attn(x)
x = self.norm1(x + self.dropout(attn_output))
# 前馈网络子层
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
4.3 Transformer解码器层实现
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = SelfAttention(d_model, num_heads)
self.encoder_attn = SelfAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask=None, tgt_mask=None):
# 掩码自注意力子层
attn_output = self.self_attn(x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 编码器-解码器注意力子层
attn_output = self.encoder_attn(torch.cat((x, encoder_output), dim=1))
x = self.norm2(x + self.dropout(attn_output))
# 前馈网络子层
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
4.4 完整Transformer模型实现
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
num_layers=6, d_ff=2048, max_seq_length=512, dropout=0.1):
super(Transformer, self).__init__()
# 词嵌入层
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
# 位置编码
self.positional_encoding = self._generate_positional_encoding(d_model, max_seq_length)
# 编码器和解码器堆叠
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
# 输出层
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def _generate_positional_encoding(self, d_model, max_len):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
return pe
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
# 源语言嵌入和位置编码
src_embedded = self.dropout(self.src_embedding(src) + self.positional_encoding[:, :src.size(1)])
# 目标语言嵌入和位置编码
tgt_embedded = self.dropout(self.tgt_embedding(tgt) + self.positional_encoding[:, :tgt.size(1)])
# 编码器处理
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output)
# 解码器处理
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
# 输出层
output = self.fc(dec_output)
return output
⚠训练技巧
(1) 学习率调度:使用"warmup"策略,先线性增加学习率,再按步数平方根的倒数衰减。
(2) 标签平滑:防止模型对预测结果过于自信,提高泛化能力。
(3) 梯度裁剪:防止梯度爆炸。
(4) 残差连接和层归一化:帮助训练更深层的网络。
(5) Dropout:在全连接层和注意力权重上应用,防止过拟合。

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18992275

 浙公网安备 33010602011771号
浙公网安备 33010602011771号