

图像数据增强以及python实现
一、数据增强概述
数据增强是一种通过使用已有的训练样本数据来生成更多训练数据的方法,可以应用于解决数据不足的问题。数据增强技术可以用来提高模型的泛化能力,减少过拟合现象。比如在狗猫识别项目中,通过随机旋转、翻转和裁剪等数据增强方法,可以使模型具有对不同角度和尺寸的狗猫图像的识别能力。其主要作用包括:
1. 增加训练样本数量:通过生成新样本,可以扩充训练集,提供更多样本供模型学习,从而减轻过拟合问题。
2. 提升模型的泛化能力:通过引入随机性,数据增强可以帮助模型学习到更多的通用特征,使其对新样本的泛化能力更强。
3. 增强模型的鲁棒性:经过数据增强处理的模型对于输入数据的变化、噪声等具有一定的抗干扰能力。
4. 解决数据不平衡问题:在分类任务中,数据增强可以使各类别样本的数量更加平衡,有助于提升模型对于少数类别的识别能力
在医疗图像中,由于拍摄条件、器械位置等因素的影响,数据可能具有不同的旋转、缩放和翻转。通过数据增强,模型能够适应不同条件下的医疗图像,提高了疾病诊断的准确性。交通标志的图像可能会因为角度、光照等因素变化。数据增强可以帮助模型识别旋转或变形后的交通标志。不止是图像处理中用到了数据增强,在情感分析任务中,通过对文本进行随机替换、删除、插入等操作,可以生成多样化的训练样本,提升模型的泛化能力。
总的来说,这些项目中的数据增强技术有效地提升了模型的鲁棒性,使其能够在不同场景和条件下取得更好的性能。同时,数据增强也有助于防止模型的过拟合现象。
二、数据增强方法
图1数据增强方法
常用的数据增强手段可以分为以下几类:
1. 基于几何变换的数据增强,如翻转、旋转、裁剪、平移和添加噪声等,可以消除训练集和测试集的尺度、位置和视角差异。
2. 基于颜色空间变换的数据增强,如调整亮度、对比度、饱和度、通道分离和灰度图转换等,可以消除训练集和测试集的光照、色彩和亮度差异。
3. 其他的数据增强方法,如多样本数据增强、Cut Mix数据增强和 Mosaic 数据增强等。
常用的数据增强方法包括:
1. 随机旋转和翻转:对图像进行随机角度的旋转和水平/垂直翻转,以增加模型对旋转和镜像变换的鲁棒性。
2. 随机裁剪:随机选取图像中的一部分作为训练样本,使模型对不同裁剪位置的变化具有适应能力。
3. 随机缩放:对图像进行随机大小的缩放,以增加模型对尺度变化的适应性。
4. 颜色扭曲:对图像进行随机的色彩变换,如亮度、对比度、饱和度的调整,以增加模型对色彩变化的鲁棒性。
5. 随机添加噪声:向图像中添加随机噪声,以增加模型对噪声的鲁棒性。
6. 随机遮挡:随机遮挡图像的一部分,模拟遮挡情况下的目标识别。
7. 自动增强:使用自动增强算法,如AutoAugment或Fast AutoAugment,通过搜索策略来找到一组优秀的数据增强策略。
8. Mixup和CutMix:将两个或多个图像进行混合,以生成新的训练样本,促进模型对类别之间的平滑过渡。
9. 样本生成对抗网络(GAN):使用生成对抗网络来生成与原始样本具有一定相似性的新样本。
10. 局部扰动:对图像的局部区域进行微小扰动,以增加模型对小物体的识别能力。
11. 对比度增强:调整图像的对比度,使得图像中的特征更加清晰。
12. 图像去噪:使用去噪算法对图像进行处理,以提升模型对噪声的鲁棒性。
选择合适的数据增强算法需要根据具体任务、数据集和模型来决定,通常需要进行实验和评估以找到最适合的方法。同时,可以结合多种数据增强方法以获得更好的效果。
三、图像数据增强
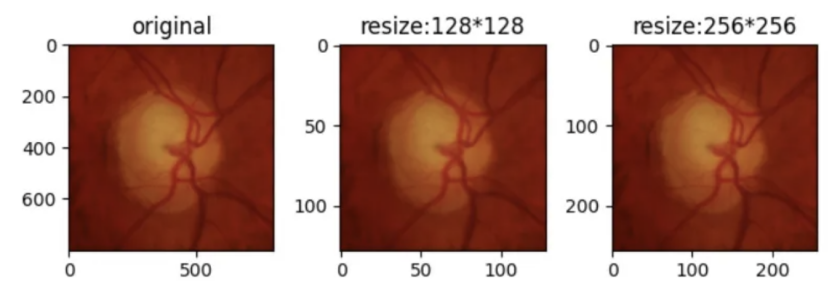
调整大小:在开始图像大小的调整之前我们需要导入数据(图像以眼底图像为例)。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/000001.tif'))
torch.manual_seed(0) # 设置 CPU 生成随机数的 种子 ,方便下次复现实验结果
print(np.asarray(orig_img).shape) #(800, 800, 3)
#图像大小的调整
resized_imgs = [T.Resize(size=size)(orig_img) for size in [128,256]]
# plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('resize:128*128')
ax2.imshow(resized_imgs[0])
ax3 = plt.subplot(133)
ax3.set_title('resize:256*256')
ax3.imshow(resized_imgs[1])
plt.show()
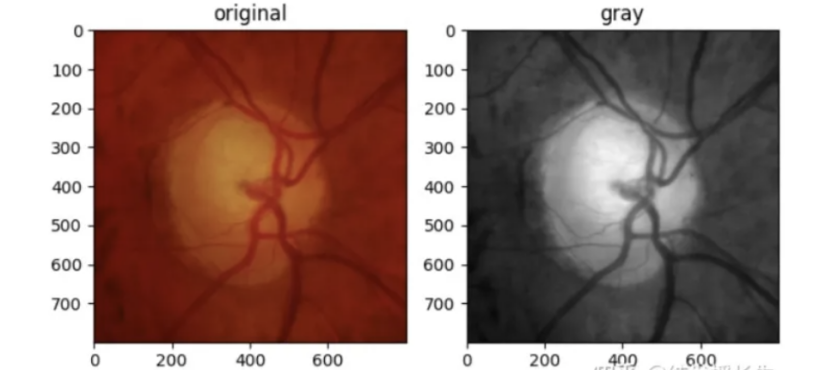
灰度变换:此操作将RGB图像转化为灰度图像。
gray_img = T.Grayscale()(orig_img)
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('gray')
ax2.imshow(gray_img,cmap='gray')
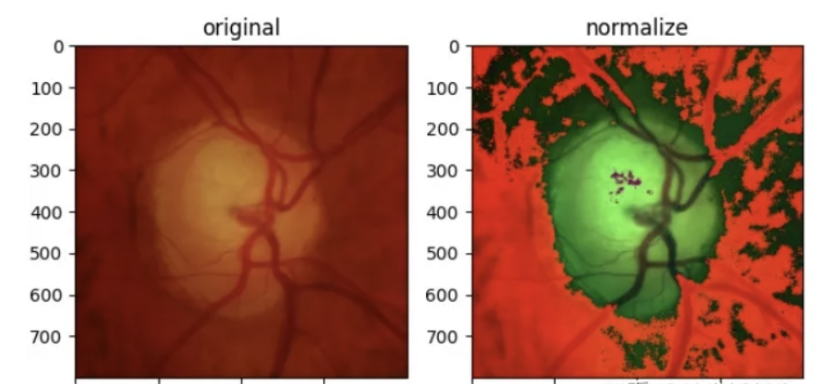
标准化:标准化可以加快基于神经网络结构的模型的计算速度,加快学习速度。
· 从每个输入通道中减去通道平均值
· 将其除以通道标准差。
normalized_img = T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))(T.ToTensor()(orig_img))
normalized_img = [T.ToPILImage()(normalized_img)]
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('normalize')
ax2.imshow(normalized_img[0])
plt.show()
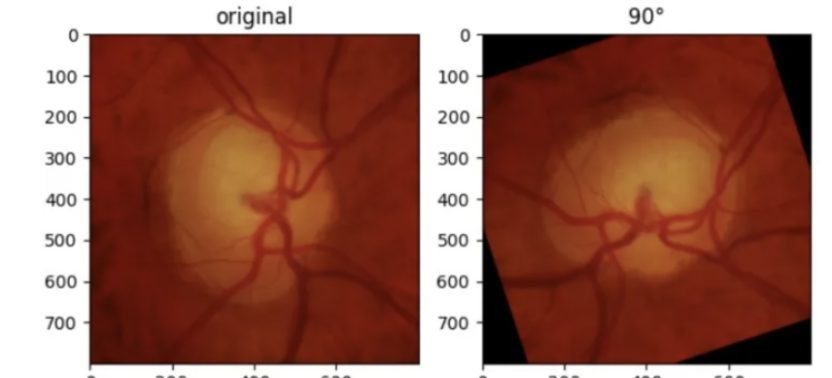
随机旋转:设计角度旋转图像
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
rotated_imgs = [T.RandomRotation(degrees=90)(orig_img)]
print(rotated_imgs)
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('90°')
ax2.imshow(np.array(rotated_imgs[0]))
中心剪切:剪切图像的中心区域
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
center_crops = [T.CenterCrop(size=size)(orig_img) for size in (128,64)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('128*128°')
ax2.imshow(np.array(center_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('64*64')
ax3.imshow(np.array(center_crops[1]))
plt.show()
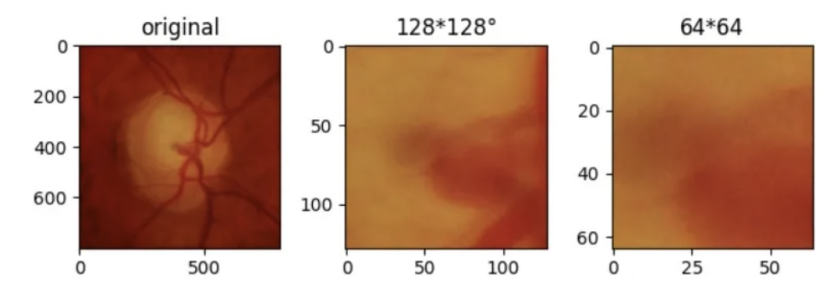
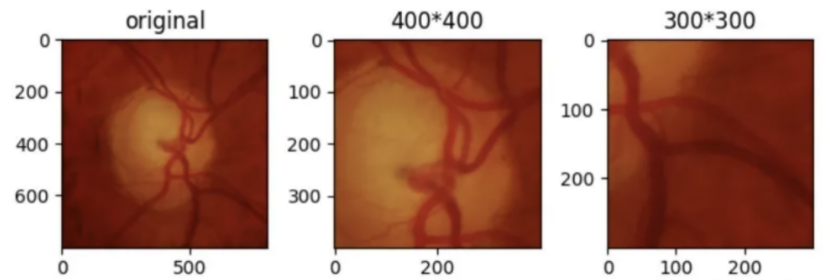
随机裁剪:随机剪切图像的某一部分
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
random_crops = [T.RandomCrop(size=size)(orig_img) for size in (400,300)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('400*400')
ax2.imshow(np.array(random_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('300*300')
ax3.imshow(np.array(random_crops[1]))
plt.show()
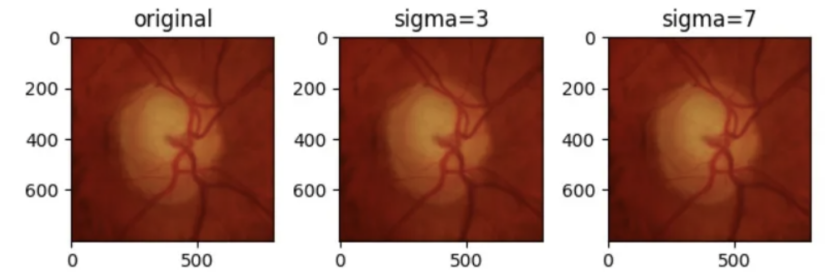
高斯模糊:使用高斯核对图像进行模糊变换
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
blurred_imgs = [T.GaussianBlur(kernel_size=(3, 3), sigma=sigma)(orig_img) for sigma in (3,7)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('sigma=3')
ax2.imshow(np.array(blurred_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('sigma=7')
ax3.imshow(np.array(blurred_imgs[1]))
plt.show()
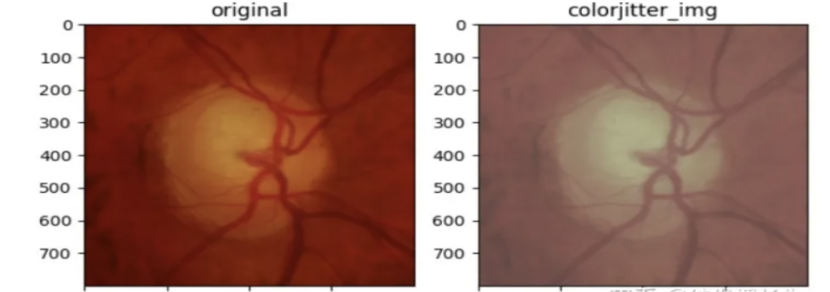
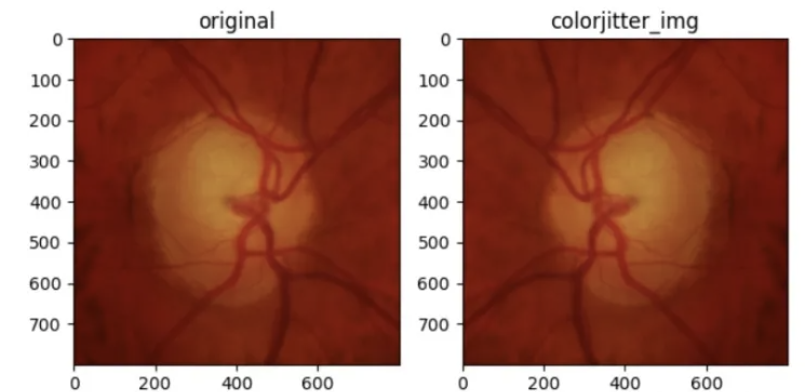
亮度、对比度和饱和度调节
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
# random_crops = [T.RandomCrop(size=size)(orig_img) for size in (832,704, 256)]
colorjitter_img = [T.ColorJitter(brightness=(2,2), contrast=(0.5,0.5), saturation=(0.5,0.5))(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('colorjitter_img')
ax2.imshow(np.array(colorjitter_img[0]))
plt.show()
水平翻转
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
HorizontalFlip_img = [T.RandomHorizontalFlip(p=1)(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('colorjitter_img')
ax2.imshow(np.array(HorizontalFlip_img[0]))
plt.show()
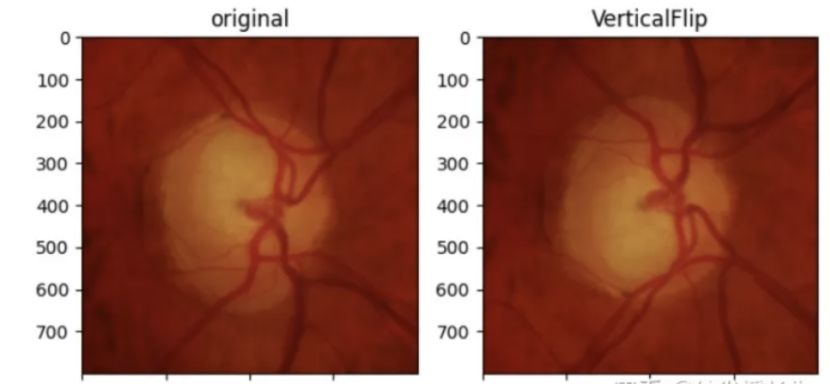
垂直翻转
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
VerticalFlip_img = [T.RandomVerticalFlip(p=1)(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('VerticalFlip')
ax2.imshow(np.array(VerticalFlip_img[0]))
# ax3 = plt.subplot(133)
# ax3.set_title('sigma=7')
# ax3.imshow(np.array(blurred_imgs[1]))
plt.show()
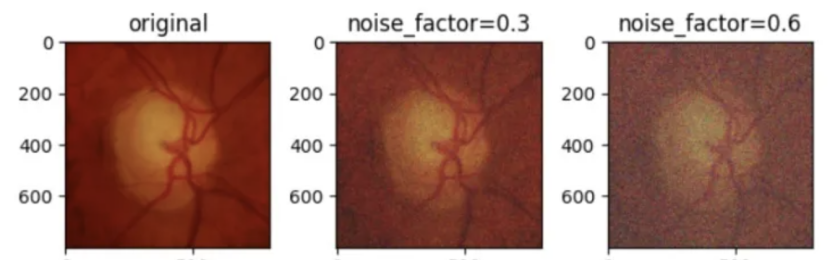
高斯噪声:向图像中加入高斯噪声。通过设置噪声因子,噪声因子越高,图像的噪声越大。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_noise(inputs, noise_factor=0.3):
noisy = inputs + torch.randn_like(inputs) * noise_factor
noisy = torch.clip(noisy, 0., 1.)
return noisy
noise_imgs = [add_noise(T.ToTensor()(orig_img), noise_factor) for noise_factor in (0.3, 0.6)]
noise_imgs = [T.ToPILImage()(noise_img) for noise_img in noise_imgs]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('noise_factor=0.3')
ax2.imshow(np.array(noise_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('noise_factor=0.6')
ax3.imshow(np.array(noise_imgs[1]))
plt.show()
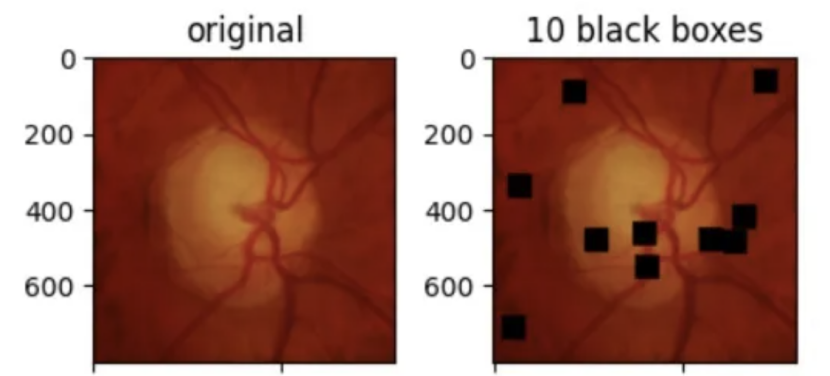
随机块:正方形补丁随机应用在图像中。这些补丁的数量越多,神经网络解决问题的难度就越大。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_random_boxes(img,n_k,size=64):
h,w = size,size
img = np.asarray(img).copy()
img_size = img.shape[1]
boxes = []
for k in range(n_k):
y,x = np.random.randint(0,img_size-w,(2,))
img[y:y+h,x:x+w] = 0
boxes.append((x,y,h,w))
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
blocks_imgs = [add_random_boxes(orig_img,n_k=10)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('10 black boxes')
ax2.imshow(np.array(blocks_imgs[0]))
plt.show()
中心区域:和随机块类似,只不过在图像的中心加入补丁
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_central_region(img, size=32):
h, w = size, size
img = np.asarray(img).copy()
img_size = img.shape[1]
img[int(img_size / 2 - h):int(img_size / 2 + h), int(img_size / 2 - w):int(img_size / 2 + w)] = 0
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
central_imgs = [add_central_region(orig_img, size=128)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('')
ax2.imshow(np.array(central_imgs[0]))
plt.show()
书籍参考:

本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18990556

 浙公网安备 33010602011771号
浙公网安备 33010602011771号