![]()
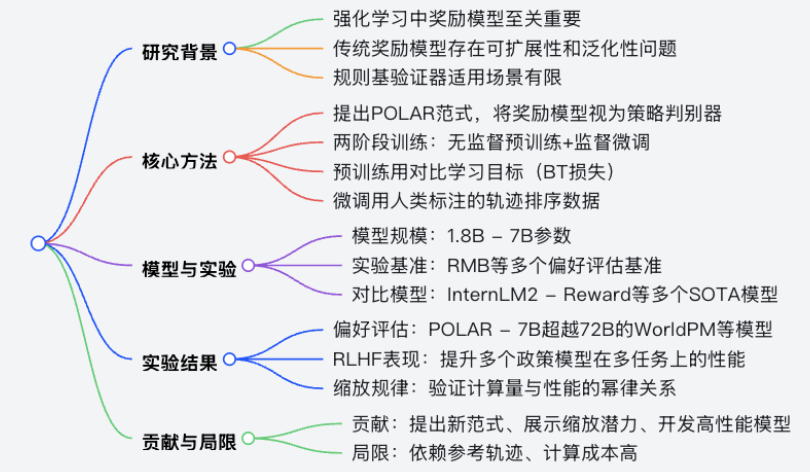
- 强化学习(RL)在大型语言模型(LLMs)的训练中至关重要,其成功取决于奖励模型(RM)提供精确稳定反馈的能力。
- 传统奖励模型依赖标注的偏好对训练,存在可扩展性和泛化性问题,前者受限于获取大量高质量标注对的难度,后者因建模人类偏好的主观性易受奖励攻击。
- 规则基验证器虽能提供准确奖励信号,但仅适用于可通过预定义规则自动验证输出的场景,在开放式领域难以扩展。
- POLAR 范式:将奖励模型重新定义为 “策略判别器”,通过量化候选策略与给定目标策略的差异,建立与标准无关的目标,为更相似于期望目标策略的政策分配更高分数,指导训练策略向期望行为发展。
- 训练流程
- 无监督预训练:从多样化政策池中采样轨迹构建大规模合成语料,采用 Bradley - Terry(BT)损失的对比学习目标,使 RM 识别相同政策的轨迹并区分不同政策的轨迹,学习为与目标政策一致性更高的轨迹分配更高奖励。
- 监督微调:使用人类标注的轨迹排序数据,让预训练的 RM 快速适应人类判断标准,采用与预训练一致的 Bradley - Terry 框架的监督排序损失。
- 模型架构:基于自回归 Transformer,类似 GPT 系列,增加线性预测头,输入为提示词、参考轨迹和候选轨迹的组合,通过特殊标记拼接,线性头处理最终层 <|reward_token|> 对应的隐藏状态产生奖励值。
- 模型与训练细节
- 训练了 1.8B 和 7B 参数的奖励模型(POLAR - 1.8B 和 POLAR - 7B),基于 InternLM - 2.5 系列模型初始化。
- 预训练数据来自多样化 LLMs 生成的提示 - 轨迹对,总量达 3.60T tokens;微调数据含 150K 人工标注示例,每个示例有一个提示和三个候选输出及排序。
- 实验基准与对比模型
- 评估基准:使用 RMB 等偏好评估基准,以及 20 个下游任务基准评估 RLHF 性能。
- 对比模型:包括 InternLM2 - Reward 系列、Skywork - Reward 系列、WorldPM - 72B - UltraFeedback 等。
- 实验结果
- 偏好评估:POLAR 模型在多任务上表现优异,POLAR - 7B 在 STEM 任务上偏好准确率从 54.8% 提升至 81.0%,创意写作任务从 57.9% 提升至 85.5%,超越更大参数的 SOTA 模型。
- RLHF 表现:在 RLHF 中使用 RFT,显著提升政策模型性能,如 LLaMa3.1 - 8B 平均得分从 47.36% 升至 56.33%,Qwen2.5 - 32B 从 64.49% 升至 70.47%。
- 缩放规律:验证了模型参数和计算量与性能的幂律关系,如模型参数的拟合公式为\(L = 0.9 \cdot N^{-0.0425}\),\(R^2 = 0.9886\),计算量的拟合公式为\(L = 2.4 \cdot C^{-0.0342}\),\(R^2 = 0.9912\)。
- 预训练阶段对模型性能和泛化能力至关重要,无预训练的模型在 RLHF 训练中性能大幅下降。
- 参考轨迹提供关键指导,即使无预训练,有参考轨迹的模型也优于无参考轨迹的传统模型。
- 在 RLHF 中,使用 POLAR 的 RFT 方法优于直接在参考数据上进行 SFT,表明 RL 能更有效地利用训练数据,POLAR 提供更准确的监督信号。
- 贡献
- 提出基于策略判别的 POLAR 预训练范式,为奖励模型提供通用训练目标。
- 展示了 POLAR 的缩放规律,证明其在提升奖励模型上限方面的潜力。
- 开发的 POLAR 系列奖励模型性能优异,扩展了 RL 算法的应用潜力。
- 局限
- 依赖参考轨迹增加了强化学习成本,且目前每个提示仅提供一个参考轨迹,可能在开放式任务中增加奖励方差。
- 生成和标注参考轨迹需额外资源,数据准备成本高于传统 LLM。
-
![6e224f3139f5aa5edd8e05e475d7fa18]()
-
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号