WorldPM: Scaling Human Preference Modeling 偏好模型复现过程以及代码实现
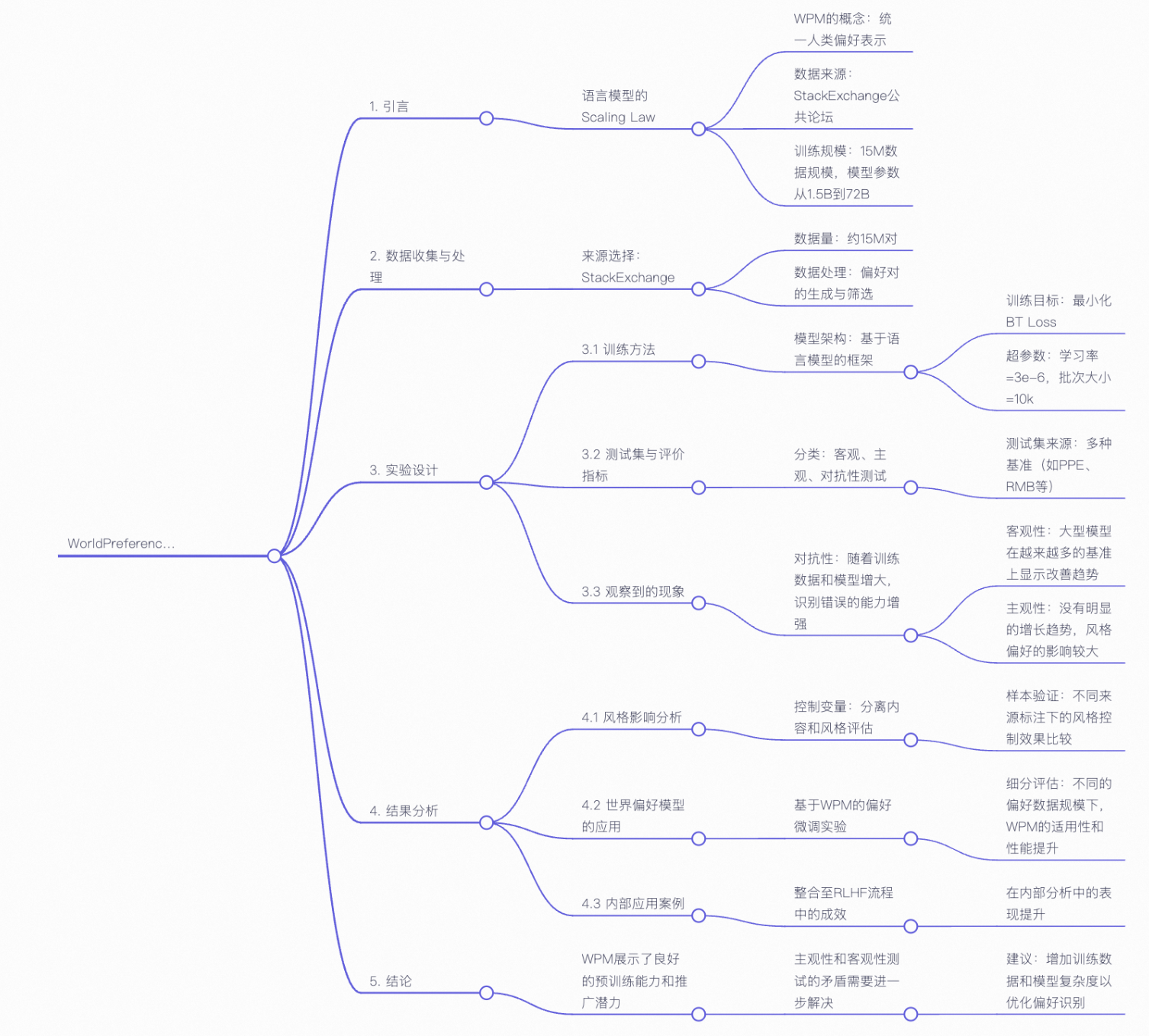
偏好模型复现思路:
如上图所示,通过Stackexchange公开论坛数据集使用qwen系列模型进行全参数微调,训练目标是最小化BT loss,超参数等和论文保持一致
偏好模型预训练:
数据下载:
StackExchange数据下载:https://www.modelscope.cn/datasets/swift/stack-exchange-paired/files
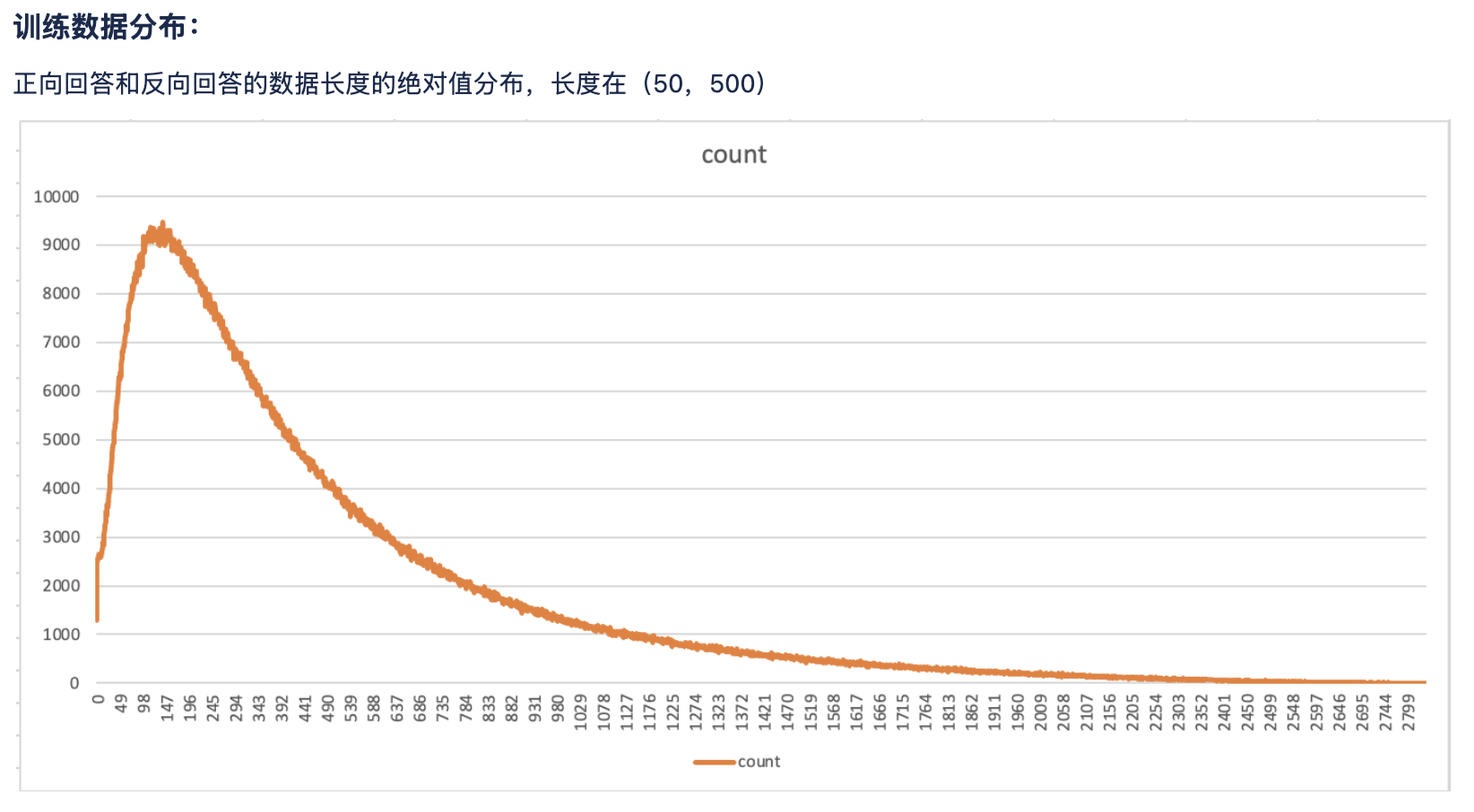
备注:每一个目录下面的数据集是20g
数据样例:
| qid,question,date,metadata,response_j,response_k 538868,I have a question to those who are really proficient in MHD generation. There exist some claims that degree of interaction between flowing molecules (gases) and ions on one hand and flowing molecules (gases) and electrons on other hand is vastly different. Therefore movement of ions in a gas flow will occur much faster than movement of free electrons. If this is correct then why we need to use a strong magnets to separate ions and electrons in MHD generator? If speed of the ions and electrons movement in the same gas flow is vastly different then doesn't charge separation suppose to occur by itself just due to a gas flow? Shouldn't majority of electrons concentrate at the beginning of the duct while many more ions at the end? Then only thing we need to generate current is to put an electrode at the beginning of the duct and another one at the end and let electrons flow from the inside of the duct through the external load to the end of the duct and recombine with ions there? And no need for a magnets.,2020/03/27,"['https://physics.stackexchange.com/questions/538868' 'https://physics.stackexchange.com' |
|---|
数据清洗:
1. 基础过滤:移除空值和无效样本
2. 长度过滤:保留合理长度的文本(参考论文中对长文本处理的隐含要求)
3. 偏好信号强化:过滤差异不明显的样本
4. 文本清洗:移除噪声和格式异常, 替换了所有的符号内容
待优化:需要过滤一下内容语义相对完整的内容
world PM模型复现代码执行:
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes=4 --config_file ds_zero3_config.yaml qwen2.5_7B_train.py
ds_zero3_config配置:
distributed_type: DEEPSPEED
num_processes: 4 # 与启动命令--num_processes保持一致
deepspeed_config:
zero_optimization:
stage: 3
offload_optimizer:
device: cpu # 启用优化器CPU卸载
pin_memory: true # 减少CPU-GPU数据传输开销
offload_param:
device: cpu # 启用参数CPU卸载
pin_memory: true
stage3_max_live_parameters: 1e8 # 降低活跃参数上限
stage3_max_reuse_distance: 5e8 # 缩小参数复用距离
stage3_prefetch_bucket_size: 2e7 # 减小预取桶大小
stage3_param_persistence_threshold: 1e3 # 降低持久化阈值
stage3_gather_16bit_weights_on_model_save: true
memory_efficient_linear: true # 启用内存高效线性层
gradient_accumulation_steps: 4 # 提高累积步数减少迭代次数
train_batch_size: 1 # 单步最小batch size
optimizer:
type: Adam
params:
lr: 1e-6
betas: [0.9, 0.95]
eps: 1e-8
fp16:
enabled: true # 保持混合精度训练
gradient_clipping: 1.0 # 启用梯度裁剪减少异常值
flops_profiler:
enabled: false # 关闭性能分析节省显存
python代码:
import pandas as pd from datasets import Dataset, load_dataset import torch from transformers import AutoModelForCausalLM, AutoTokenizer from accelerate import Accelerator import torch.nn as nn import torch.optim as optim import os import json from tqdm import tqdm import accelerate print(f"Accelerate version: {accelerate.__version__}") print(f"PyTorch version: {torch.__version__}") # -------------------------- # 1. 数据集格式转换(适配Qwen对话格式) # -------------------------- def convert_to_qwen_format(input_path, output_path): """将原始偏好数据转换为Qwen模型所需的对话格式""" with open(input_path, "r", encoding="utf-8") as fin, \ open(output_path, "w", encoding="utf-8") as fout: for line in fin: try: data = json.loads(line) # 提取偏好标注(preference_strength>0则response_2为优) preferred_response = data["response_2"] if data["preference_strength"] > 0 else data["response_1"] rejected_response = data["response_1"] if data["preference_strength"] > 0 else data["response_2"] # 构造Qwen格式的对话(system/user/assistant三角色) messages_chosen = [ {"role": "system", "content": "你是一个偏好评估专家,需要根据用户问题生成高质量回答。"}, {"role": "user", "content": data["prompt"]}, {"role": "assistant", "content": preferred_response} ] messages_rejected = [ {"role": "system", "content": "你是一个偏好评估专家,需要根据用户问题生成高质量回答。"}, {"role": "user", "content": data["prompt"]}, {"role": "assistant", "content": rejected_response} ] # 写入转换后的数据 fout.write(json.dumps({ "messages_chosen": messages_chosen, "messages_rejected": messages_rejected }, ensure_ascii=False) + "\n") except Exception as e: print(f"转换数据失败: {e}, 跳过该样本") # 转换训练集(根据实际路径调整) convert_to_qwen_format( input_path="/HelpSteer2/preference/preference.jsonl", output_path="train_formatted.jsonl" ) # -------------------------- # 2. 加载并预处理数据集 # -------------------------- # 加载转换后的JSONL数据集 dataset = load_dataset("json", data_files={"train": "train_formatted.jsonl"})["train"] print(f"原始数据集大小: {len(dataset)} 样本") # 预处理函数:将对话转换为模型输入格式 def preprocess_function(examples): chosen_inputs = [] rejected_inputs = [] # 遍历批量样本,构造Qwen格式输入(带特殊token) for chosen_msg, rejected_msg in zip(examples["messages_chosen"], examples["messages_rejected"]): # 提取对话内容(固定结构:[system, user, assistant]) system_prompt = chosen_msg[0]["content"] user_prompt = chosen_msg[1]["content"] chosen_response = chosen_msg[2]["content"] rejected_response = rejected_msg[2]["content"] # 构造完整输入(遵循Qwen的<|im_start|>和<|im_end|>格式) prompt = ( f"<|im_start|>system\n{system_prompt}<|im_end|>" f"<|im_start|>user\n{user_prompt}<|im_end|>" f"<|im_start|>assistant\n" ) chosen_input = prompt + chosen_response + "<|im_end|>" rejected_input = prompt + rejected_response + "<|im_end|>" chosen_inputs.append(chosen_input) rejected_inputs.append(rejected_input) return { "chosen_inputs": chosen_inputs, "rejected_inputs": rejected_inputs } # 应用预处理(批量处理加速) processed_dataset = dataset.map( preprocess_function, batched=True, remove_columns=dataset.column_names, # 移除原始字段 desc="预处理数据集" ) print(f"预处理后数据集大小: {len(processed_dataset)} 样本") # -------------------------- # 3. 模型与训练组件定义 # -------------------------- # 初始化Accelerator(分布式训练核心) accelerator = Accelerator( mixed_precision="fp16", # 启用FP16混合精度,减少显存占用 gradient_accumulation_steps=4 # 梯度累积,平衡显存与batch_size ) # 加载分词器 model_name = "/Qwen2.5-3B" tokenizer = AutoTokenizer.from_pretrained(model_name) tokenizer.pad_token = tokenizer.eos_token # 设置pad_token为eos_token tokenizer.padding_side = "right" # 右填充,避免影响最后一个token的隐藏状态 # 修复奖励模型的数据类型匹配问题 # -------------------------- class RewardModel(nn.Module): def __init__(self, base_model): super().__init__() self.base_model = base_model # 奖励头使用与基础模型一致的dtype(float16),避免类型不匹配 self.reward_head = nn.Linear( base_model.config.hidden_size, 1, dtype=base_model.dtype # 关键:使用基础模型的数据类型(float16) ).to(device=accelerator.device) def forward(self, input_ids, attention_mask): outputs = self.base_model( input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True, return_dict=True ) # 提取最后一个有效token的隐藏状态(保持原 dtype=float16) last_hidden = outputs.hidden_states[-1] batch_size = last_hidden.shape[0] last_token_indices = attention_mask.sum(dim=1) - 1 last_token_hidden = last_hidden[torch.arange(batch_size), last_token_indices] # 直接使用隐藏状态(float16)输入奖励头,无需转换为float32 reward = self.reward_head(last_token_hidden) return reward.squeeze(-1) # 加载基础模型并初始化奖励模型 base_model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, # 用FP16加载基础模型,节省显存 trust_remote_code=True, device_map={"": accelerator.device} # 自动分配到当前设备 ) # 强制开启基础模型的梯度跟踪(关键步骤) for param in base_model.parameters(): param.requires_grad = True base_model.train() # 确保模型处于训练模式 # 初始化奖励模型 reward_model = RewardModel(base_model) reward_model.train() # 奖励模型开启训练模式 # 定义优化器(使用Adam优化器,适合Transformer) optimizer = optim.Adam( reward_model.parameters(), lr=1e-6, # 学习率(奖励模型通常用较小的学习率) betas=(0.9, 0.95), # 适合Transformer的动量参数 eps=1e-8 ) # 数据加载器(控制batch_size,避免显存溢出) train_loader = torch.utils.data.DataLoader( processed_dataset, batch_size=1, # 单卡batch_size,根据显存调整(3B模型建议1-4) shuffle=True, pin_memory=True # 启用内存锁页,加速数据传输 ) # 适配分布式环境(DeepSpeed/多卡训练) reward_model, optimizer, train_loader = accelerator.prepare( reward_model, optimizer, train_loader ) # -------------------------- # 4. 训练配置与损失函数 # -------------------------- # 训练参数 num_epochs = 1 log_dir = "help_logs_Qwen2.5-3B_0708" model_dir = "help_models_Qwen2.5-3B_0708" os.makedirs(log_dir, exist_ok=True) os.makedirs(model_dir, exist_ok=True) # 记录指标 metrics = { "epoch_losses": [], # 每个epoch的平均损失 "batch_losses": [] # 每个batch的损失 } # 优化的BT损失函数(增强数值稳定性) def bt_loss(chosen_rewards, rejected_rewards, eps=1e-8): """ 偏好训练的BT损失函数:鼓励优选回答的奖励 > 非优选回答的奖励 """ # 计算奖励差值(优选 - 非优选) diff = chosen_rewards - rejected_rewards # 限制差值范围,避免sigmoid饱和(增强稳定性) diff = torch.clamp(diff, min=-8.0, max=8.0) # 计算sigmoid并添加微小偏移,避免log(0) sigmoid_diff = torch.sigmoid(diff) sigmoid_diff = torch.clamp(sigmoid_diff, min=eps, max=1 - eps) # 计算损失(负对数似然) loss = -torch.log(sigmoid_diff).mean() # 处理可能的nan值 if torch.isnan(loss): return torch.tensor(1e-6, device=loss.device, requires_grad=True) return loss # -------------------------- # 5. 训练循环 # -------------------------- for epoch in range(num_epochs): total_loss = 0.0 # 进度条(仅主进程显示) progress_bar = tqdm( train_loader, desc=f"Epoch {epoch + 1}/{num_epochs}", disable=not accelerator.is_main_process ) for batch_idx, batch in enumerate(progress_bar): # 编码输入(chosen和rejected) # 分别对 chosen_inputs 和 rejected_inputs 进行编码 # 1. 编码 chosen_inputs(优选回答) chosen_encoding = tokenizer( text=batch["chosen_inputs"], # 仅处理优选回答 padding=True, truncation=True, max_length=512, # 单独设置优选回答的最大长度 return_tensors="pt" ) # 2. 编码 rejected_inputs(非优选回答) rejected_encoding = tokenizer( text=batch["rejected_inputs"], # 仅处理非优选回答 padding=True, truncation=True, max_length=512, # 单独设置非优选回答的最大长度(可与chosen不同) return_tensors="pt" ) # 提取处理后的输入(无需分割,直接从各自的encoding中获取) chosen_input_ids = chosen_encoding.input_ids.to(accelerator.device) chosen_attention_mask = chosen_encoding.attention_mask.to(accelerator.device) rejected_input_ids = rejected_encoding.input_ids.to(accelerator.device) rejected_attention_mask = rejected_encoding.attention_mask.to(accelerator.device) """ # 注意:max_length根据数据长度调整,过短会截断信息,过长会增加显存占用 encoding = tokenizer( text=batch["chosen_inputs"] + batch["rejected_inputs"], # 合并编码,提高效率 padding=True, truncation=True, max_length=512, return_tensors="pt" ) # 分割为chosen和rejected的输入(前半部分是chosen,后半部分是rejected) batch_size = len(batch["chosen_inputs"]) chosen_input_ids = encoding.input_ids[:batch_size].to(accelerator.device) chosen_attention_mask = encoding.attention_mask[:batch_size].to(accelerator.device) rejected_input_ids = encoding.input_ids[batch_size:].to(accelerator.device) rejected_attention_mask = encoding.attention_mask[batch_size:].to(accelerator.device) """ # 计算奖励值(保留梯度) chosen_rewards = reward_model(chosen_input_ids, chosen_attention_mask) rejected_rewards = reward_model(rejected_input_ids, rejected_attention_mask) # 调试:验证梯度是否存在(仅主进程执行) if accelerator.is_main_process and batch_idx == 0 and epoch == 0: assert chosen_rewards.requires_grad, "chosen_rewards 丢失梯度!" assert rejected_rewards.requires_grad, "rejected_rewards 丢失梯度!" print("梯度检查通过:奖励值保留了梯度信息") # 计算损失 loss = bt_loss(chosen_rewards, rejected_rewards) # 反向传播(梯度累积) accelerator.backward(loss) # 梯度裁剪(防止梯度爆炸) accelerator.clip_grad_norm_(reward_model.parameters(), 1.0) # 优化器更新(每gradient_accumulation_steps步更新一次) if (batch_idx + 1) % accelerator.gradient_accumulation_steps == 0: optimizer.step() optimizer.zero_grad(set_to_none=True) # 高效清理梯度 # 记录损失(仅主进程) batch_loss = loss.item() total_loss += batch_loss if accelerator.is_main_process: metrics["batch_losses"].append({ "epoch": epoch + 1, "batch_idx": batch_idx, "loss": batch_loss }) # 更新进度条 progress_bar.set_postfix({ "batch_loss": f"{batch_loss:.4f}", "avg_loss": f"{total_loss / (batch_idx + 1):.4f}" }) # 每个epoch结束后保存结果(仅主进程执行) if accelerator.is_main_process: avg_loss = total_loss / len(train_loader) metrics["epoch_losses"].append({ "epoch": epoch + 1, "avg_loss": avg_loss }) print(f"\nEpoch {epoch + 1} 完成,平均损失: {avg_loss:.4f}") # 保存指标 with open(os.path.join(log_dir, "metrics.json"), "w", encoding="utf-8") as f: json.dump(metrics, f, indent=2, ensure_ascii=False) # 保存模型(使用accelerator.unwrap_model处理分布式包装) unwrapped_model = accelerator.unwrap_model(reward_model) torch.save( unwrapped_model.state_dict(), os.path.join(model_dir, f"reward_model_epoch_{epoch + 1}.pth") ) print(f"模型已保存至 {model_dir}/reward_model_epoch_{epoch + 1}.pth\n") # 训练完成(仅主进程) if accelerator.is_main_process: print("所有训练epoch完成!")
优化:
要在现有代码基础上实现 “保留生成能力 + 输出奖励得分 + 生成判别理由” 的多任务功能,需从模型结构、数据处理、损失函数三方面进行修改。以下是具体方案:
一、核心修改目标
二、具体修改步骤
1. 模型结构:新增理由生成分支(复用原始生成层)
import pandas as pd
from datasets import Dataset, load_dataset
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch.nn as nn
import torch.optim as optim
import os
import json
from tqdm import tqdm
import accelerate
print(f"Accelerate version: {accelerate.__version__}")
print(f"PyTorch version: {torch.__version__}")
# --------------------------
# 1. 数据集格式转换(新增偏好理由生成需求)
# --------------------------
def convert_to_qwen_format(input_path, output_path):
"""将原始偏好数据转换为Qwen模型所需的格式(含理由生成指令)"""
with open(input_path, "r", encoding="utf-8") as fin, \
open(output_path, "w", encoding="utf-8") as fout:
for line in fin:
try:
data = json.loads(line)
# 提取偏好标注
preferred_response = data["response_2"] if data["preference_strength"] > 0 else data["response_1"]
rejected_response = data["response_1"] if data["preference_strength"] > 0 else data["response_2"]
# 构造“生成偏好理由”的指令(核心新增)
reason_prompt = (
f"请解释为什么以下回答A比回答B更好:\n"
f"用户问题:{data['prompt']}\n"
f"回答A(优选):{preferred_response}\n"
f"回答B(非优选):{rejected_response}\n"
f"理由:"
)
# 构造Qwen格式的对话(含理由生成)
messages_chosen = [
{"role": "system", "content": "你是一个偏好评估专家,需要判断并解释哪个回答更好。"},
{"role": "user", "content": data["prompt"]},
{"role": "assistant", "content": preferred_response}
]
messages_rejected = [
{"role": "system", "content": "你是一个偏好评估专家,需要判断并解释哪个回答更好。"},
{"role": "user", "content": data["prompt"]},
{"role": "assistant", "content": rejected_response}
]
# 新增:理由生成的对话格式
messages_reason = [
{"role": "system", "content": "你需要生成详细理由,解释为什么优选回答比非优选回答更好。"},
{"role": "user", "content": reason_prompt},
# 注意:如果原始数据有标注的理由,可在此处添加作为目标输出(如data["reason"])
]
# 写入转换后的数据(含理由生成字段)
fout.write(json.dumps({
"messages_chosen": messages_chosen,
"messages_rejected": messages_rejected,
"messages_reason": messages_reason # 新增:理由生成的输入
}, ensure_ascii=False) + "\n")
except Exception as e:
print(f"转换数据失败: {e}, 跳过该样本")
# 转换训练集(含理由生成字段)
convert_to_qwen_format(
input_path="/data/team/lmq/prefenceModel/HelpSteer2/preference/preference.jsonl",
output_path="train_formatted.jsonl"
)
# --------------------------
# 2. 加载并预处理数据集(新增理由生成字段)
# --------------------------
dataset = load_dataset("json", data_files={"train": "train_formatted.jsonl"})["train"]
def preprocess_function(examples):
chosen_inputs = []
rejected_inputs = []
reason_inputs = [] # 新增:理由生成的输入
for chosen_msg, rejected_msg, reason_msg in zip(
examples["messages_chosen"],
examples["messages_rejected"],
examples["messages_reason"] # 新增
):
# 构造原始偏好判断的输入(同之前)
system_prompt = chosen_msg[0]["content"]
user_prompt = chosen_msg[1]["content"]
chosen_response = chosen_msg[2]["content"]
rejected_response = rejected_msg[2]["content"]
prompt = (
f"<|im_start|>system\n{system_prompt}<|im_end|>"
f"<|im_start|>user\n{user_prompt}<|im_end|>"
f"<|im_start|>assistant\n"
)
chosen_input = prompt + chosen_response + "<|im_end|>"
rejected_input = prompt + rejected_response + "<|im_end|>"
# 新增:构造理由生成的输入(带格式)
reason_system = reason_msg[0]["content"]
reason_user = reason_msg[1]["content"]
reason_input = (
f"<|im_start|>system\n{reason_system}<|im_end|>"
f"<|im_start|>user\n{reason_user}<|im_end|>"
f"<|im_start|>assistant\n"
)
# 如果有标注的理由目标,此处可添加(如reason_msg[2]["content"] + "<|im_end|>")
chosen_inputs.append(chosen_input)
rejected_inputs.append(rejected_input)
reason_inputs.append(reason_input) # 保存理由生成输入
return {
"chosen_inputs": chosen_inputs,
"rejected_inputs": rejected_inputs,
"reason_inputs": reason_inputs # 新增输出字段
}
# 应用预处理(包含理由生成字段)
processed_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset.column_names,
desc="预处理数据集(含理由生成)"
)
# --------------------------
# 3. 模型定义(支持奖励输出和理由生成)
# --------------------------
class RewardAndReasonModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.base_model = base_model
# 奖励头(判断偏好)
self.reward_head = nn.Linear(
base_model.config.hidden_size, 1,
dtype=base_model.dtype
).to(device=accelerator.device)
# 理由生成无需额外头(复用base_model的LM头)
def forward(self, input_ids, attention_mask, is_reason=False):
"""
is_reason: 若为True,返回生成理由的logits;否则返回奖励分
"""
outputs = self.base_model(
input_ids=input_ids,
attention_mask=attention_mask,
output_hidden_states=True,
return_dict=True
)
if is_reason:
# 理由生成:返回语言模型的logits(用于生成文本)
return outputs.logits
else:
# 奖励预测:返回奖励分
last_hidden = outputs.hidden_states[-1]
batch_size = last_hidden.shape[0]
last_token_indices = attention_mask.sum(dim=1) - 1
last_token_hidden = last_hidden[torch.arange(batch_size), last_token_indices]
reward = self.reward_head(last_token_hidden)
return reward.squeeze(-1)
def generate_reason(self, input_ids, attention_mask, max_length=200):
"""生成偏好理由(封装生成逻辑)"""
generation_config = GenerationConfig(
max_length=max_length,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
with torch.no_grad():
generated_ids = self.base_model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
generation_config=generation_config
)
# 解码生成的理由
generated_reason = tokenizer.batch_decode(
generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
return generated_reason
# --------------------------
# 4. 训练组件与损失函数(新增理由生成损失)
# --------------------------
# 初始化Accelerator
accelerator = Accelerator(mixed_precision="fp16")
# 加载分词器和基础模型
model_name = "/data/team/llm/Qwen2.5-3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map={"": accelerator.device}
)
for param in base_model.parameters():
param.requires_grad = True
base_model.train()
# 初始化模型(支持奖励和理由生成)
model = RewardAndReasonModel(base_model)
model.train()
# 优化器(同时优化奖励头和LM头)
optimizer = optim.Adam(
model.parameters(),
lr=1e-6,
betas=(0.9, 0.95)
)
# 数据加载器
train_loader = torch.utils.data.DataLoader(
processed_dataset,
batch_size=1,
shuffle=True,
pin_memory=True
)
# 适配分布式环境
model, optimizer, train_loader = accelerator.prepare(
model, optimizer, train_loader
)
# 新增:理由生成的损失函数(交叉熵损失)
lm_loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
# --------------------------
# 5. 训练循环(联合优化奖励和理由生成)
# --------------------------
num_epochs = 1
log_dir = "help_logs_Qwen2.5-3B_0708"
model_dir = "help_models_Qwen2.5-3B_0708"
os.makedirs(log_dir, exist_ok=True)
os.makedirs(model_dir, exist_ok=True)
metrics = {
"epoch_losses": [],
"batch_losses": [],
"batch_reason_losses": [] # 新增:记录理由生成损失
}
for epoch in range(num_epochs):
total_loss = 0.0
total_reason_loss = 0.0 # 新增
progress_bar = tqdm(
train_loader,
desc=f"Epoch {epoch + 1}/{num_epochs}",
disable=not accelerator.is_main_process
)
for batch_idx, batch in enumerate(progress_bar):
# 1. 编码输入(含理由生成的输入)
# 1.1 编码偏好判断的输入
chosen_encoding = tokenizer(
batch["chosen_inputs"],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
rejected_encoding = tokenizer(
batch["rejected_inputs"],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
# 1.2 编码理由生成的输入(新增)
reason_encoding = tokenizer(
batch["reason_inputs"],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
# 移动到设备
chosen_input_ids = chosen_encoding.input_ids.to(accelerator.device)
chosen_attention_mask = chosen_encoding.attention_mask.to(accelerator.device)
rejected_input_ids = rejected_encoding.input_ids.to(accelerator.device)
rejected_attention_mask = rejected_encoding.attention_mask.to(accelerator.device)
reason_input_ids = reason_encoding.input_ids.to(accelerator.device)
reason_attention_mask = reason_encoding.attention_mask.to(accelerator.device)
# 2. 计算奖励损失(同之前)
chosen_rewards = model(chosen_input_ids, chosen_attention_mask, is_reason=False)
rejected_rewards = model(rejected_input_ids, rejected_attention_mask, is_reason=False)
reward_loss = bt_loss(chosen_rewards, rejected_rewards)
# 3. 计算理由生成损失(新增)
# 3.1 构造理由生成的标签(输入左移一位,即下一个token预测)
reason_labels = reason_input_ids.clone()
reason_labels[:, :-1] = reason_input_ids[:, 1:] # 左移一位
reason_labels[:, -1] = tokenizer.pad_token_id # 最后一位设为pad
# 3.2 计算LM损失
reason_logits = model(reason_input_ids, reason_attention_mask, is_reason=True)
reason_loss = lm_loss_fn(
reason_logits.transpose(1, 2), # [batch, vocab, seq] -> [batch, seq, vocab]
reason_labels
)
# 4. 联合损失(权重可调整,如奖励损失占70%,理由损失占30%)
total_batch_loss = 0.7 * reward_loss + 0.3 * reason_loss
# 5. 反向传播
accelerator.backward(total_batch_loss)
accelerator.clip_grad_norm_(model.parameters(), 1.0)
if (batch_idx + 1) % accelerator.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# 6. 记录指标
batch_loss = reward_loss.item()
batch_reason_loss = reason_loss.item() # 新增
total_loss += batch_loss
total_reason_loss += batch_reason_loss # 新增
if accelerator.is_main_process:
metrics["batch_losses"].append({
"epoch": epoch + 1,
"batch_idx": batch_idx,
"loss": batch_loss
})
metrics["batch_reason_losses"].append({ # 新增
"epoch": epoch + 1,
"batch_idx": batch_idx,
"reason_loss": batch_reason_loss
})
progress_bar.set_postfix({
"reward_loss": f"{batch_loss:.4f}",
"reason_loss": f"{batch_reason_loss:.4f}", # 新增
"avg_total_loss": f"{(total_loss + total_reason_loss) / (batch_idx + 1):.4f}"
})
# 每个epoch结束后操作
if accelerator.is_main_process:
avg_loss = total_loss / len(train_loader)
avg_reason_loss = total_reason_loss / len(train_loader) # 新增
metrics["epoch_losses"].append({
"epoch": epoch + 1,
"avg_loss": avg_loss,
"avg_reason_loss": avg_reason_loss # 新增
})
print(f"\nEpoch {epoch + 1} 完成,平均奖励损失: {avg_loss:.4f}, 平均理由损失: {avg_reason_loss:.4f}")
# 保存指标和模型
with open(os.path.join(log_dir, "metrics.json"), "w", encoding="utf-8") as f:
json.dump(metrics, f, indent=2, ensure_ascii=False)
unwrapped_model = accelerator.unwrap_model(model)
torch.save(
unwrapped_model.state_dict(),
os.path.join(model_dir, f"model_epoch_{epoch + 1}.pth")
)
# --------------------------
# 6. 生成偏好理由的示例(训练后使用)
# --------------------------
def generate_preference_reason(prompt, response_a, response_b):
"""给定用户问题和两个回答,生成偏好理由"""
reason_prompt = (
f"请解释为什么以下回答A比回答B更好:\n"
f"用户问题:{prompt}\n"
f"回答A:{response_a}\n"
f"回答B:{response_b}\n"
f"理由:"
)
# 编码输入
encoding = tokenizer(
text=[f"<|im_start|>system\n你是偏好评估专家<|im_end|><|im_start|>user\n{reason_prompt}<|im_end|><|im_start|>assistant\n"],
padding=True,
return_tensors="pt"
).to(accelerator.device)
# 生成理由
model.eval()
reason = model.generate_reason(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
max_length=300
)
model.train()
return reason[0] # 返回生成的理由
# 训练完成后可调用示例
if accelerator.is_main_process:
print("\n生成偏好")
loss画图代码:
import json
import matplotlib.pyplot as plt
import numpy as np
# --------------------------
# 1. 加载数据
# --------------------------
file_path = "/stack_help_logs_Qwen2.5-3B/metrics.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 提取batch级损失并按batch_idx排序
batch_losses = sorted(data["batch_losses"], key=lambda x: (x["epoch"], x["batch_idx"]))
batch_indices = [item["batch_idx"] for item in batch_losses]
batch_loss_values = [item["loss"] for item in batch_losses]
batch_epochs = [item["epoch"] for item in batch_losses] # 新增:记录每个batch所属的epoch
# 提取epoch级平均损失
epoch_losses = data["epoch_losses"]
epoch_dict = {item["epoch"]: item["avg_loss"] for item in epoch_losses}
# 获取所有唯一的epoch
epochs = sorted(list(set(batch_epochs)))
# --------------------------
# 2. 按固定间隔计算每个epoch的平均loss(修复后的逻辑)
# --------------------------
interval_size = 50 # 每20步一个区间
epoch_interval_centers = {} # 存储每个epoch的区间中心
epoch_smoothed_losses = {} # 存储每个epoch的平滑后loss
for epoch in epochs:
# 筛选当前epoch的batch
epoch_mask = [e == epoch for e in batch_epochs]
epoch_batch_indices = [idx for idx, m in zip(batch_indices, epoch_mask) if m]
epoch_loss_values = [loss for loss, m in zip(batch_loss_values, epoch_mask) if m]
max_batch = max(epoch_batch_indices) if epoch_batch_indices else 0
num_intervals = (max_batch + interval_size - 1) // interval_size
# 存储当前epoch的区间平均loss
interval_centers = []
interval_avg_losses = []
for i in range(num_intervals):
start_idx = i * interval_size + 1
end_idx = min((i + 1) * interval_size, max_batch)
# 筛选区间内的损失
mask = [(start_idx <= idx <= end_idx) for idx in epoch_batch_indices]
interval_losses = [loss for loss, m in zip(epoch_loss_values, mask) if m]
# 修复:改进过滤逻辑,确保至少保留一个值
filtered_losses = interval_losses.copy()
# 只有当区间内损失值数量 > 2 时才移除最大值和最小值
if len(filtered_losses) > 2:
max_loss = max(filtered_losses)
min_loss = min(filtered_losses)
# 如果最大值和最小值不同,移除它们
if max_loss != min_loss:
filtered_losses = [loss for loss in filtered_losses if loss != max_loss and loss != min_loss]
# 如果移除后列表为空,恢复最小值
if not filtered_losses:
filtered_losses = [min_loss]
# 计算平均损失(确保列表非空)
if filtered_losses:
avg_loss = sum(filtered_losses) / len(filtered_losses)
interval_centers.append((start_idx + end_idx) / 2)
interval_avg_losses.append(avg_loss)
# 对当前epoch的loss进行标准化和平滑
def normalize(values):
if not values:
return []
min_val = min(values)
max_val = max(values)
if max_val == min_val:
return [0.5 for _ in values]
return [(v - min_val) / (max_val - min_val) for v in values]
normalized_losses = normalize(interval_avg_losses)
# 滑动平均平滑
window_size = 3
smoothed_losses = []
for i in range(len(normalized_losses)):
start = max(0, i - window_size//2)
end = min(len(normalized_losses), i + window_size//2 + 1)
window = normalized_losses[start:end]
smoothed_losses.append(sum(window) / len(window))
# 存储当前epoch的结果
if interval_centers and smoothed_losses:
epoch_interval_centers[epoch] = interval_centers
epoch_smoothed_losses[epoch] = smoothed_losses
# --------------------------
# 3. 绘制每个epoch的loss曲线
# --------------------------
plt.figure(figsize=(12, 6))
# 定义不同epoch的颜色
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd']
for i, epoch in enumerate(epochs):
if epoch in epoch_interval_centers and epoch in epoch_smoothed_losses:
plt.plot(
epoch_interval_centers[epoch],
epoch_smoothed_losses[epoch],
'-',
color=colors[i % len(colors)],
linewidth=2.5,
label=f"Epoch {epoch} Loss"
)
# 添加该epoch的平均loss水平线
if epoch in epoch_dict:
plt.axhline(
y=epoch_dict[epoch],
color=colors[i % len(colors)],
linewidth=1.5,
linestyle='--',
alpha=0.7,
label=f"Epoch {epoch} Avg Loss: {epoch_dict[epoch]:.4f}"
)
# 设置y轴范围为0-1
plt.ylim(0, 1)
# 添加标题和标签
plt.title("Reward Model Loss by Epoch", fontsize=14)
plt.xlabel("Batch Index (within each epoch)", fontsize=12)
plt.ylabel("Normalized Loss", fontsize=12)
plt.legend()
plt.grid(alpha=0.3)
# 显示图片
plt.show()
附录:

链接:https://arxiv.org/pdf/2505.10527
数据地址如下:
https://stackexchange.com
https://www.reddit.com
https://www.quora.com
https://lmarena.ai/
中文版该论文解析地址:https://zhuanlan.zhihu.com/p/1906747872642339918
Bradley–Terry model - FzKuji的文章 - 知乎:https://zhuanlan.zhihu.com/p/1887534462046278533
deepseek 中的grpo:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247569612&idx=3&sn=a3e0e3fd74c391da56fe39d2ac5ba62c&chksm=eab415c5169c91180f00186aa3bfd96a94950f17c03181a279828a0f097a44f874287699b45e&scene=27
qwen代码:https://github.com/QwenLM/Qwen/blob/main/recipes/finetune/deepspeed/finetune_fullparameter_single_gpu.ipynb
该论文代码:https://github.com/QwenLM/WorldPM
微调大模型需要的内存计算方式:https://zhuanlan.zhihu.com/p/1900879098915586893
qwen模型下载地址:https://www.modelscope.cn/models/Qwen/WorldPM-72B/files
qwen多模态内容:https://zhuanlan.zhihu.com/p/1888934522504077319
简历信息抽取:https://aistudio.csdn.net/63e901132bcaa918ade995f9.html
简历不同格式的内容抽取:https://aistudio.baidu.com/projectdetail/2493247?contributionType=1&sUid=90149&shared=1&ts=1674726578546&login=from_csdn
文档阅读顺序:https://baijiahao.baidu.com/s?id=1733600986343592047&wfr=spider&for=pc
Qwen3模型微调的代码:https://zhuanlan.zhihu.com/p/1905212234478630715
程序员简历模版:https://www.github-zh.com/projects/23783375-resumesample
招聘数据:https://www.heywhale.com/mw/dataset/643617f610fc15e023ba1f81/file
人岗匹配数据集:https://gitcode.com/Premium-Resources/d3f01/?utm_source=article_gitcode_universal&index=top&type=card
人力资源分析数据:https://www.heywhale.com/mw/dataset/654ddccf0a272988204541f1/content
deepspeed --num_gpus 4 train_qwen25_stackexchange.py
stack 数据代码:https://www.modelscope.cn/datasets/AI-ModelScope/stack-exchange-paired/file/view/master/StackExchangeProcessing.ipynb?id=9289&status=1
stack 中文数据下载地址:https://www.modelscope.cn/datasets/swift/stack-exchange-paired/files
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes=4 --config_file ds_zero3_config.yaml qwen2.5_7B_train_0702_new2.py
偏好模型中文详细解析:https://blog.csdn.net/m0_37733448/article/details/148105600
worldPM解析:https://modelscope.cn/papers/145782/aiRead
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download --repo-type dataset lmms-lab/multimodal-open-r1-8k-verified \
--resume-download \
--local-dir ./dataset
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes=4 --config_file ds_zero3_config.yaml qwen2.5_7B_train_0702_new2.py
https://www.modelscope.cn/datasets/OpenBMB/UltraFeedback
本文来自博客园,作者:limingqi,转载请注明原文链接:https://www.cnblogs.com/limingqi/p/18972612

 浙公网安备 33010602011771号
浙公网安备 33010602011771号