一 全文搜索引擎的架构一般是这样的
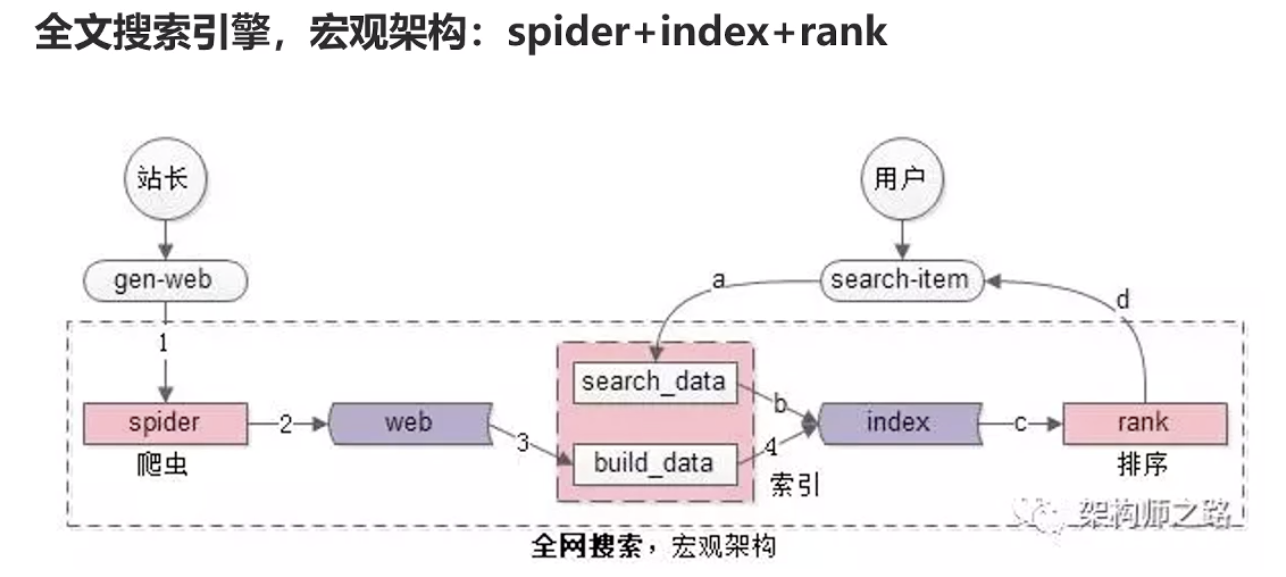
1 spider爬虫,爬取网页
2 index,建立索引
3 rank对搜索出来的结果做排序
spider和index是工程系统,一般找工程师都能做出来
rank是和业务,策略,算法相关,需要时间的沉淀,这个部分是最难的,百度跟google搜索都有各自的算法,新公司来做搜索引擎是很难短时间超过这两家公司的
rank的排序算法,核心的一个算法是你这个网站被多少人引用了,引用的越多,权重越高
上面这种方面索引不会实时的被修改,因为如果实时的修改索引,会产生碎片,极大的降低索引的效率(ES就是会实时修改索引,所以在高并发时,效率会有折扣)
那一个搜索引擎怎么最快索引热点数据呢,比如一个重大新闻出来,一般百度15分钟之内就能搜索的大?
首先索引分级
把索引分不同的等级,比如全部索引,本月索引,当天索引,1小时之内索引
这样有新的内容进来,索引需要修改时,先改最小的那份索引(1小时之内索引,因为数据量最小),每一份索引都是冗余,负载均稀对上层提供服务,所以先修改最小分级索引中,
某一个节点的索引,此时这台节点设置不对上层提供服务,改了好再对上层开放服务
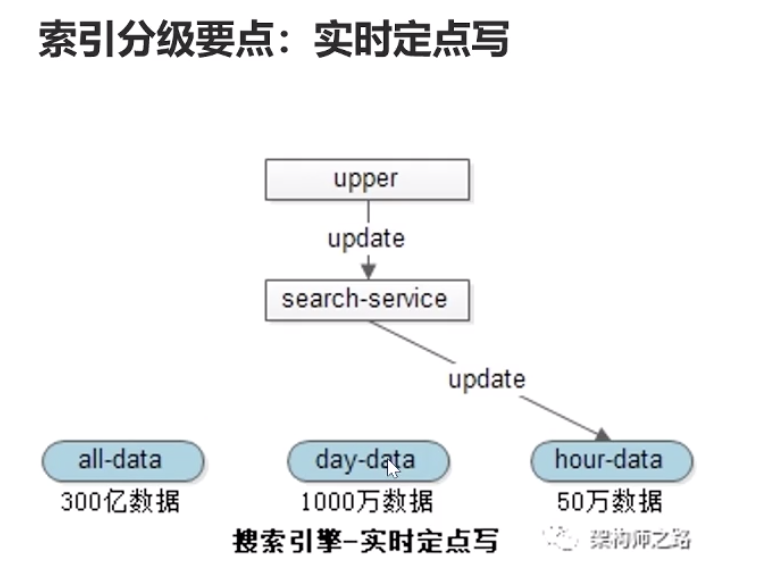
我只写最小份的索引,所以性能很快。
查的话,我会查所有分级索引块的数据,然后合并起来再返回给用户
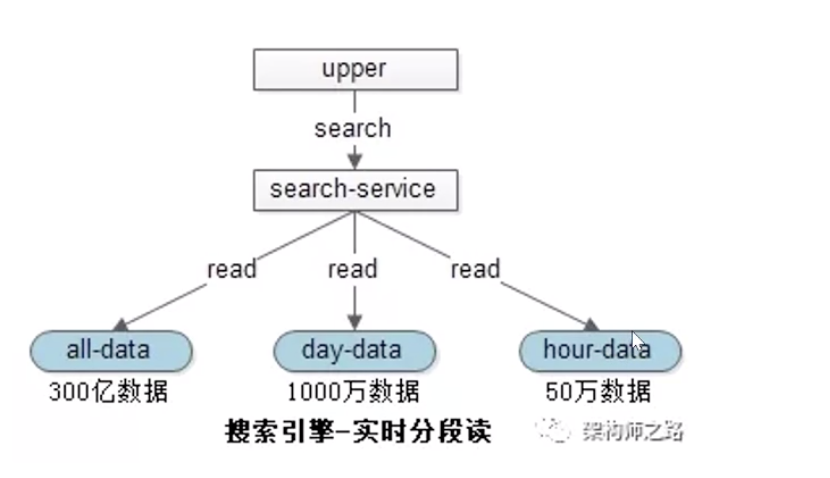
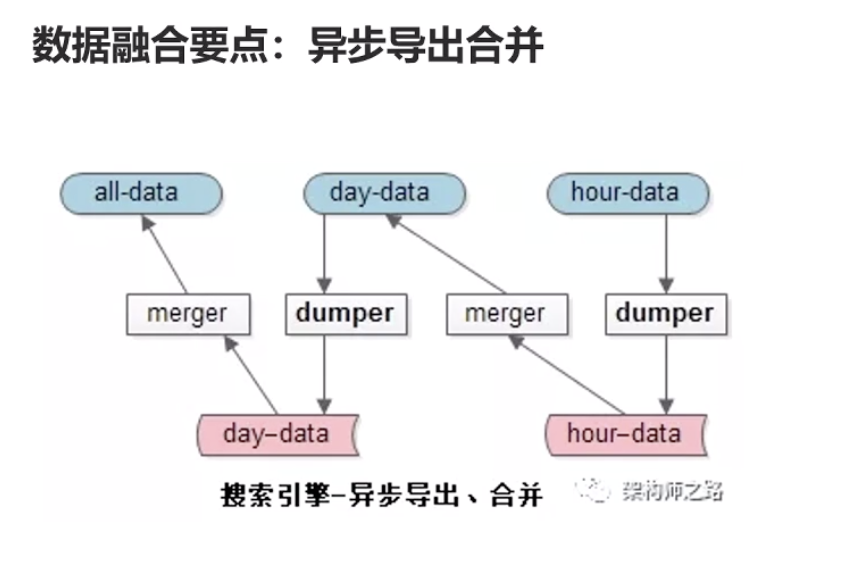
那么小时索引数据怎么同步到天索引块,天索引数据怎么同步到全部索引块呢?
答:数据融合
索引,又分为正排索引,倒排索引,分词等

由url地址直接找到这个网站详情,就属于正排索引
分词就是把文字分成一个个字,或者是词语
倒排索引,就是用分词搜索出url地址,因为事先已经生成了分词对应url地址的索引,所以搜索时间维度是O(1)
无论是正排还是倒排,搜索时间维度都是O(1) ,
下一步
我们通过分词搜索出了很多结果,最后我们求结果的交集
????如果求交集???
1 for*for循环,效率很低不行
2 拉链法
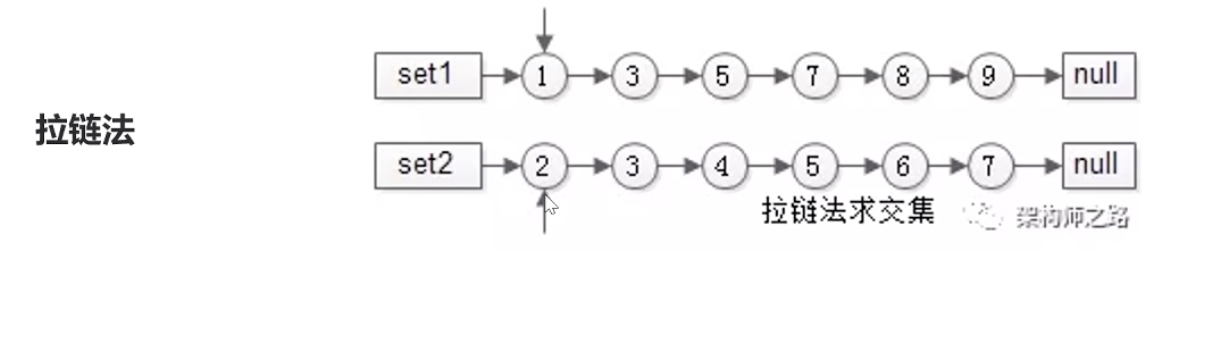
首选结果集我们在生成索引的时候已经排好序了,
首先比较集合1和集合2的第一个,谁小,就往后面移一位,继续比较,一直这样循环移到结尾
这样效率就提高到每个元素我都只比较了一次
3 分桶并行思路:
一般情况下,生成的集合里面的数据会很多
我可以会成3份或者更多份,
线程并发把每一份去求交集,
最后再合并,就是要的结果,这样效率又提高了

4 bitmap求交集
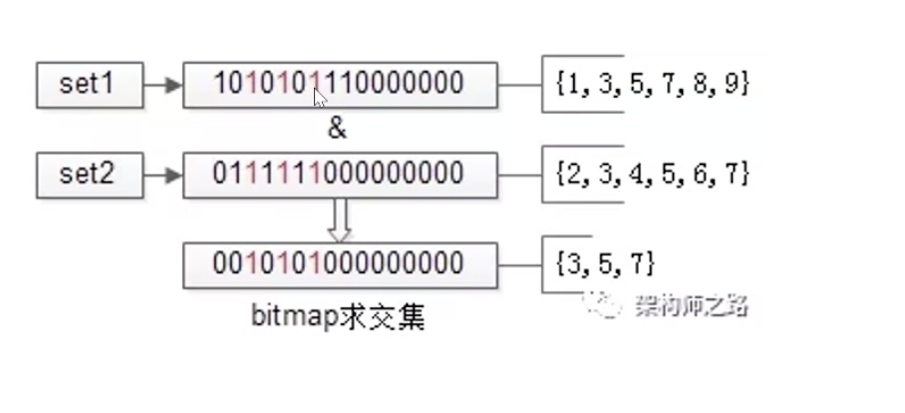
这种方法比链路法更快
5 跳表优化
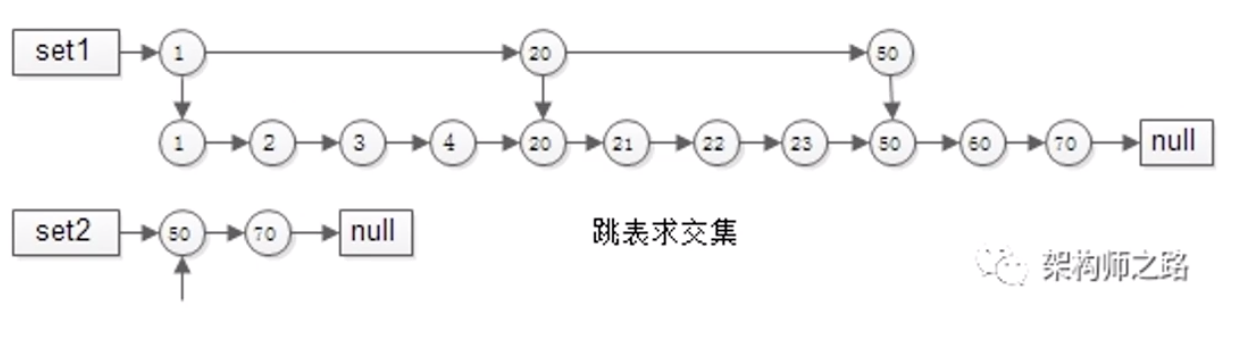
一般情况,集合数据很多,间隔很大
所以我们没有必要一个个去对比,可以跨大步跳着去对面,比如上图,1跟50比,1小,那么我不拿2去跟50比,我直接跳到20去跟50比,这样效率又会快很多
以上是大数据,高并发情况的处理方案,一般是在百亿级别的数据,万级别的并发以上去使用
一般从小到大做搜索架构是
一 数据库like
二 数据库建全文索引fulltext (几十万数据量时,这样做还行,还有就是早期的innodb不支持)
三 开源外置索引ES (elastic eearch) ,核心是:索引数据和源始数据分开,索引数据外置(一般,几十亿级别的数据,几千并发,es可以顶住),es支持分布式
如果数据量更大
四 自研搜索引擎
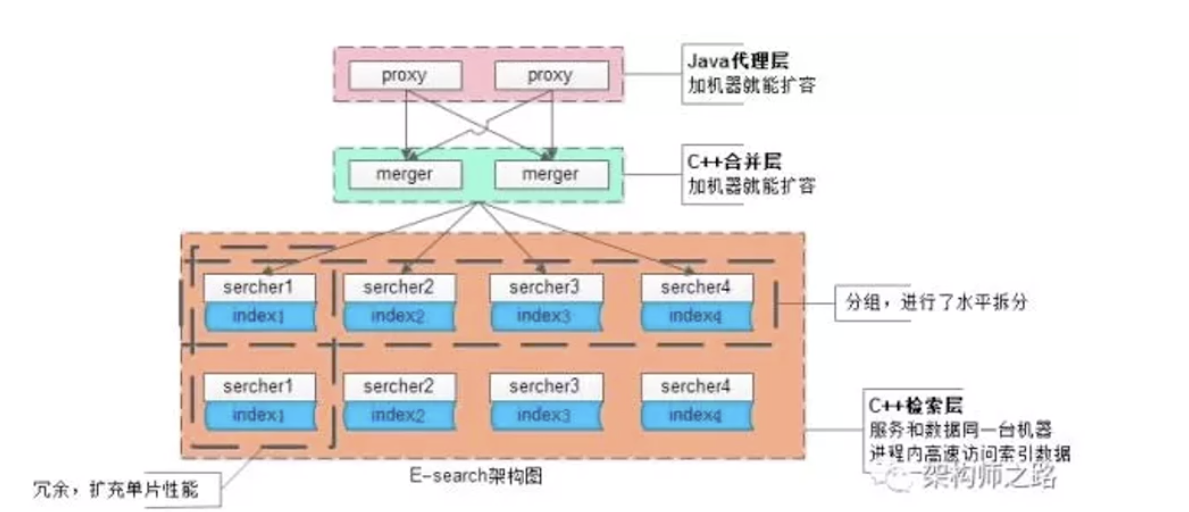
思路是可以无限水平扩容,增加机器就能增加吞吐量
如上图:
入口层merger是无状态的接收请求,可以水平扩展n份,
100亿的数据,我分成1000份,那么每一份就只有1000W的数据了,上图就是分成了4份,merger一个搜索请求过来了,我并发同时去向下面4份请求,拿到结果之后我再合并
这里要注意的是我的索引,和索引对应的真实数据放在同一台服务器了,那么我通过索引拿数据就会很快
数据量不断的增加,水平上面我可以无限扩展多份来解决,每一份上面我也可以做冗余,可以扩展多个节点,这样我单份的搜索性能也可以无限增大
这种方案来实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号