
解释:解决分库分表之后,方便的关系型查询。
1 当数据量大的时候,你会根据oid来分库或者分表,关系表怎么分了?一个用户的订单列表可能在不同的库,一个卖家的订单列表也可能在不同的库?
2 那么本来的订单关系表就要冗余一份,从一张表(buyer_id,seller_id,oid),变成两张表(上面的t1,t2),t1和t2所以库加起来的内容是一样,意思就是t1冗余一份t2
3 t1,t2分库的规则不一样,一个根据buyer_id来分库分表,另外一个根据seller_id来分库分表,这样就解决这个问题了
二 怎么做数据表的冗余呢?
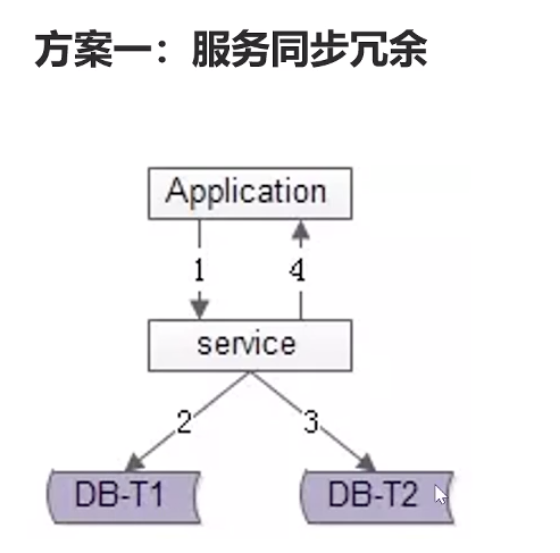
坏处:服务层分别写da_1和db_2,时间上面来说多了一倍,会有1个成功,另外一个失败,数据不一致的情况
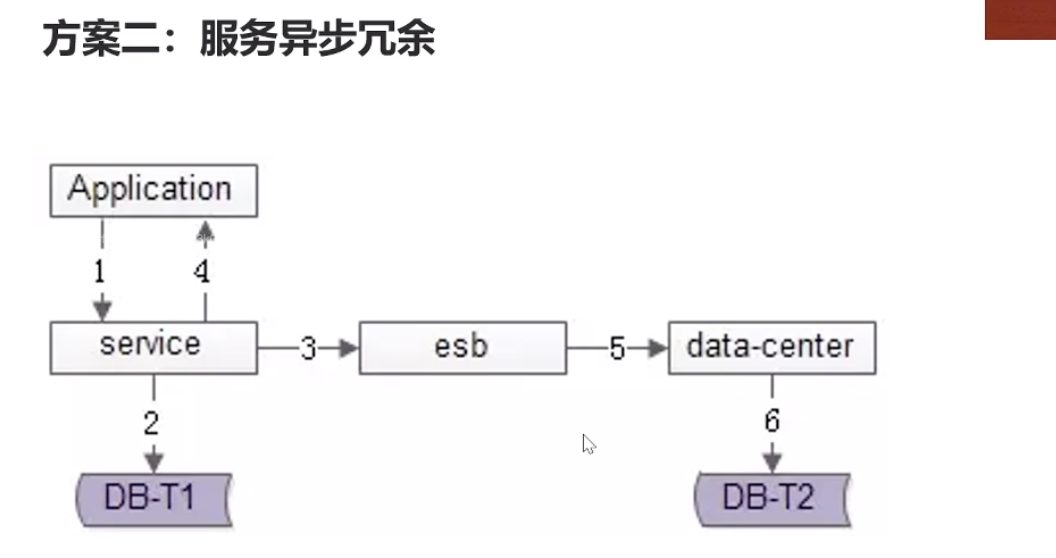
第二个方案,写db_1成功之后,写入一条消息队列异步去更新db_2
坏处:时间上面不需要2倍,但是也有数据不一致的情况。
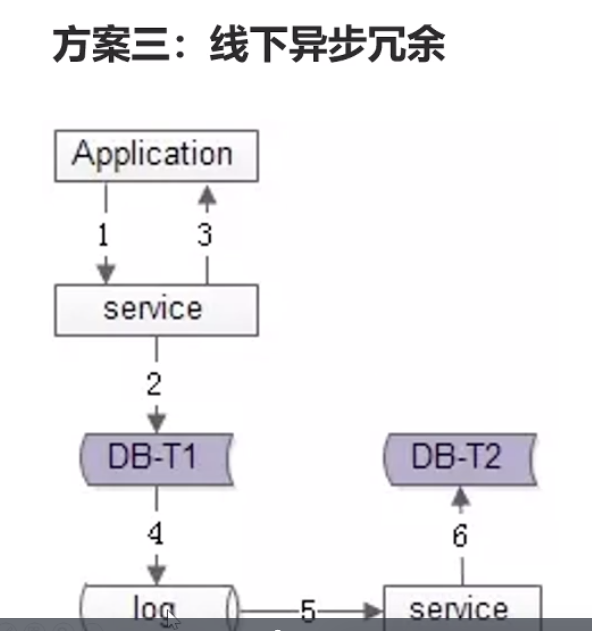
第三种方案:通过日志,异步更新到db_2,时间上面没有变大,依然有数据不一致情况
总结:

比如淘宝商城的例子,先写的db_1表是买家buy_id为规则的表,db_1成功了,db_2不成功时,卖家晚几秒看不到订单关系不大,因为买家可以正常生成订单,走完正常付款流程
三 数据冗余之后,怎么保证数据一致性
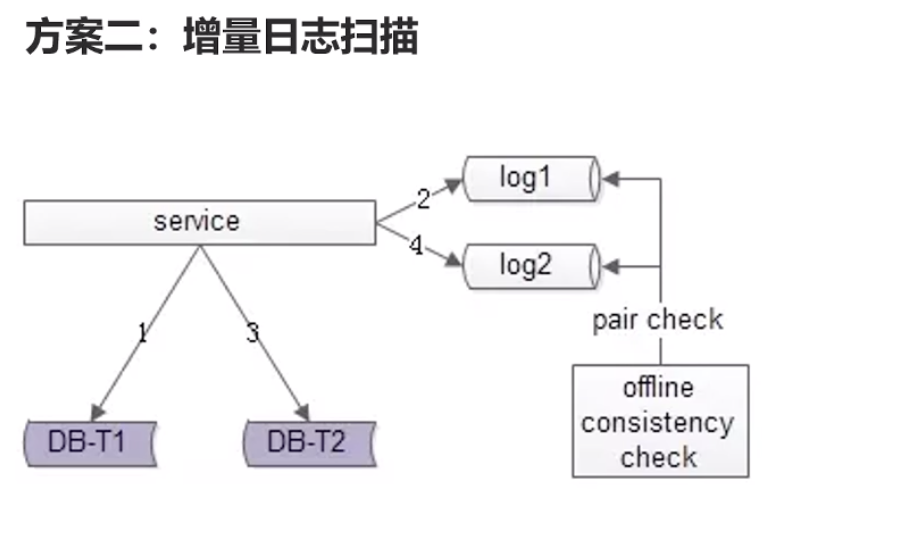
新增的sql命令记录下来。 每1个小时(或者更低时间)去对比一下增量日志,把有问题的同步进去

在互联网高并发,大数据面前,无法做到保证及时性的数据一致性,我们只能做到最终数据一致性。
如果用上面的方案,30分钟之内保证数据的最终一致性还不能满足需求,就用下面这种方案,5秒之内保证数据一致性.
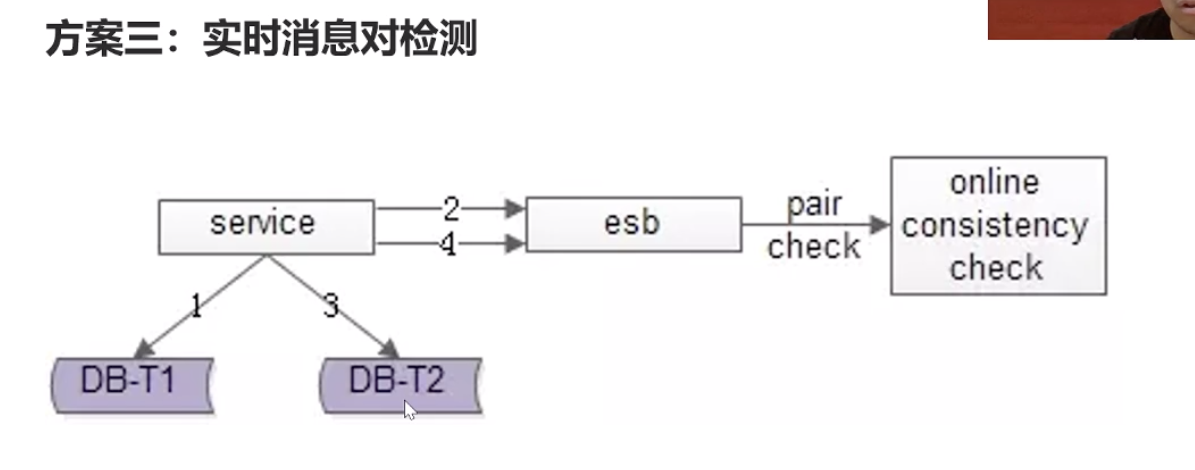
db_1写入成功之后发一条消息,db_2写入成功之后也发一条消息,维护一个消息服务系统,当收到消息1时,如果在5分钟之内没有收到db_2的消息,那么就怀疑db_2没有写成功,去查下db_2是否真没有写成功,没有写成功就补写
这种及时性一般是在金钱方面比较常用。
有个疑问,如果5秒之内,此条记录被修改了多次,那么应该怎么办,直接补可能会导致数据混乱.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号