
一:跨表查询(最重要)
引言:
查询python这本书出版社的名字和邮箱
book=Book.objects.filter(title="python").first()
pub_obj=Publish.objects.filter(nid=book.publish_id).first()
print(pub_obj.name)
print(pub_obj.email)
基于对象的跨表查询(基于子查询实现)
关于子查询请参考:博文
1:一对多:

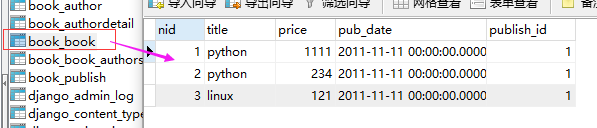
表关系:Book---Publish:多对一
查询python这本书出版社的名字和邮箱 多对一的查询方式
方法一:子查询
book=Book.objects.filter(title="python").first()
pub_obj=Publish.objects.filter(nid=book.publish_id).first()
print(pub_obj.name)
print(pub_obj.email)
#######################
方法二:
book = Book.objects.filter(title="python").first()
print(book.publish) # 与book这本书关联出版社对象 (book是对象,publish表示的就是Book类中的字段,这个字段就是用来ForeignKey关联Publish表的。所以book.publish获取的是book这本书关联的Publish
对象) 基表对象.基表关联字段
print(book.publish.name) # 对象。属性
print(book.publish.email)
查询苹果出版社出版的所有的书籍的名称 一对多的查询方式
pub_obj=Publish.objects.get(name="苹果出版社")
print(pub_obj.book_set.all()) # queryset <QuerySet [<Book:linux>,<Book:python>]> 一对多(一个出版社对应多个书籍),这样查出来的是一个集合,这里book_set中的book就是Book表名小写
基表对象.关联表名_set.all() 表名小写
print(pub_obj.book_set.all().values("title")) # queryset <QuerySet {'title':linux},{'title':python}]>
总结语法:
####### 一对多 ##########
'''
正向查询:关联属性所在的表查询关联表记录
反向查询
----正向查询按关联字段:book.publish (对象.字段)
Book表------------------------------------>Publish表
<-----------------------------------
反向查询表名小写_set.all():pub_obj.book_set.all()
'''
2:多对多

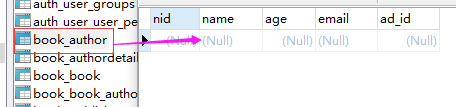
语法:
####### 多对多 ########## 实际上这些翻译成sql,都是子查询
'''
正向查询按字段 book.authors.all() (对象.字段.all())
Book表 -------------------------------------->Author表
<--------------------------------------
反向查询按表名小写_set.all(): name_obj.book_set.all()
'''
# 查询python这本书籍的作者的年龄 先book表里自己查询,再去book_author关联表查关联id对应的author_id,之后根据author_id再去author表里查询。 实际上有三个步骤 book=Book.objects.filter(title="python").first() ret=book.authors.all().values("age") # 与这本书关联的左右作者的queryset的集合 print(ret) #查询alex出版过的所有的书籍名称 alex=Author.objects.filter(name="alex").first() print(alex.book_set.all())
3:一对一
####### 一对一 ##########
'''
正常查询安字段:alex.ad ad是Author表结构中创建关联的字段
Author -----------------------------------------> AuthorDetail
<------------------------------------------
反向查询按表名小写 ad.author
'''
# 查询alex的手机号
alex = Author.objects.filter(name="alex").first()
print(alex.ad.tel)
# 查询手机号为110的作者的名字
ad=AuthorDetail.objects.filter(tel=110).first()
print(ad.author.name)
基于双下划线的跨表查询(基于join实现,本质:拼接表)
关于join拼接多表查询请参考:博文
语法:
正向查询按字段,反向查询按表名(小写)
准备环境:
publish---book:一对多 (反向)
book----author:多对多(正向)
author--authordetail:一对一 (正向)



1 from django.db import models 2 3 # Create your models here. 4 5 class Book(models.Model): 6 nid=models.AutoField(primary_key=True) 7 title=models.CharField(max_length=32) 8 price=models.DecimalField(max_digits=8,decimal_places=2) # 999999.99 9 pub_date=models.DateTimeField() # "2012-12-12" 10 publish=models.ForeignKey(to="Publish",on_delete=models.CASCADE) # 级联删除 11 authors=models.ManyToManyField(to="Author") 12 def __str__(self): 13 return self.title 14 15 16 class Publish(models.Model): 17 nid = models.AutoField(primary_key=True) 18 name=models.CharField(max_length=32) 19 email=models.CharField(max_length=32) 20 def __str__(self): 21 return self.name 22 23 class Author(models.Model): 24 nid = models.AutoField(primary_key=True) 25 name=models.CharField(max_length=32) 26 age=models.IntegerField() 27 email=models.CharField(max_length=32) 28 ad=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) 29 #books=models.ManyToManyField("Book") 30 def __str__(self): 31 return self.name 32 33 class AuthorDetail(models.Model): 34 addr=models.CharField(max_length=32) 35 tel=models.IntegerField() 36 #author=models.OneToOneField("Author",on_delete=models.CASCADE) 37 def __str__(self): 38 return self.addr 39 40 # class Author2Book(models.Model): 41 # nid = models.AutoField(primary_key=True) 42 # book=models.ForeignKey(to="Book",on_delete=models.CASCADE) 43 # author=models.ForeignKey(to="Author",on_delete=models.CASCADE) 44 45 46 ############################################################### 47 48 49 class Emp(models.Model): 50 name=models.CharField(max_length=32) 51 age=models.IntegerField(default=20) 52 dep=models.CharField(max_length=32) 53 pro=models.CharField(max_length=32) 54 salary=models.DecimalField(max_digits=8,decimal_places=2)
1:一对多
表关系:Book----Publish :多对一
(1) 查询python这本书出版社的名字
SQL语句: SELECT book_publish.`name` from book_book INNER JOIN book_publish ON book_book.publish_id = book_publish.nid WHERE book_book.title = 'python' 正向:按字段(关联字段) ret=Book.objects.filter(title="python").values("price") #单表Book中的操作,filter:过滤本表,value:取值(本表);
ret=Book.objects.filter(title="python").values("publish__name") #如何提醒ORM引擎Book join Publish:通过双下划线的方式 #跨表操作 print(ret) 基表的关联字段__关联表的字段 反向:按表名 ret=Publish.objects.filter(book__title="python").values("name") print(ret) 关联表名__关联表的字段
(2) 查询苹果出版社出版的所有的书籍的名称 ret=Publish.objects.filter(name="苹果出版社").values("book__title")
2:多对多
表关系:Book----Author :多对多 ,book_book_authors:关联表
(3)查询python这本书籍的作者的年龄 SQL: SELECT book_author.age from book_book INNER JOIN book_book_authors ON book_book.nid = book_book_authors.book_id INNER JOIN book_author ON book_author.nid = book_book_authors.author_id WHERE book_book.title = "python" 正向: ret=Book.objects.filter(title="python").values("authors__age") #ORM会自动拼接的 反向: ret=Author.objects.filter(book__title="python").values("age")
3:一对一
表关系:Author---AuthorDetail:一对一
(4)查询alex的手机号 正向: ret=Author.objects.filter(name="alex").values("ad__tel") 反向: ret=AuthorDetail.objects.filter(author__name="alex").values("tel")
4:连续跨表
1 ########## 连续跨表 ############### 2 3 查询苹果出版社出版过的所有书籍的名字以及作者的姓名 4 5 ret=Publish.objects.filter(name="苹果出版社").values("book__title","book__authors__name") 6 ret=Book.objects.filter(publish__name="苹果出版社").values("title","authors__name") 7 ret=Book.objects.filter(publish__name="苹果出版社").values("title","authors__name") 8 print(ret) 9 10 手机号以110开头的作者出版过的所有书籍名称以及出版社名称 11 方式1: 12 ret=Author.objects.filter(ad__tel__startswith=110).values_list("book__title","book__publish__name") 13 print(ret) 14 15 方式2: 16 ret=AuthorDetail.objects.filter(tel__startswith=110).values("author__book__title","author__book__publish__name") 17 18 # 方式3: 19 ret=Book.objects.filter(authors__ad__tel__startswith=110).values("title","publish__name")
二:分组查询与聚合查询
1 emp 2 id name dep pro salary 3 1 alex 教学部 山东 1000 4 2 mjj 教学部 山东 3000 5 3 林海峰 保安部 山东 5000 6 4 peiqi 人事部 河北 10000 7 8 select Count(id) from emp; 9 select AVG(salary) from emp; 10 11 select dep,AVG(salary) from emp group by dep 12 select pro,Count(1) from emp group by pro
1:聚合
聚合表示不分组,整个就是一个组,如select Count(1)from emp; select Avg(price) from emp
聚合函数请参考:博文
查询所有书籍的平均价格 from django.db.models import Avg,Max,Sum,Min,Count ret=Book.objects.all().aggregate(priceAvg=Avg("price")) print(ret) # {'priceAvg': 142.0} 查询所有书籍的个数 ret=Book.objects.all().aggregate(c=Count(1)) print(ret) # {'c': 4}
2:分组(group by,本质先拼接成一张表在group by)
SQL(MySQL)部分请参考:博文
2.1种类一:直接分组查询 ,只有group by
2.1.1:单表分组查询
准备1:
下面两种写法完全等效
Book.objects.all().values('title') #相当于select title from Book Book.objects.values('title')
准备2:
key: annotate()前values哪一个字段就按哪一个字段group by;分组完后就是annotate统计哪个字段 ret=Book.objects.values("publish_id").annotate(c=Count(1))
相当于:
select Count(1) as c from Book group by publish_id
案例:
查询书籍表每一个出版社id以及对应的书籍个数 ret=Book.objects.values("publish_id").annotate(c=Count(1)) print(ret)
查询每一个部门的名称以及对应员工的平均薪水 #可以看到结果是两个字段(分组的那个字段,要查询的字段) ret=Emp.objects.values("dep").annotate(avg_salary=Avg("salary")) print(ret) #
<QuerySet [{'dep': '教学部', 'avg_salary': 2500.0}, {'dep': '保洁部', 'avg_salary': 3500.0}, {'dep': '保安部', 'avg_salary': 4000.0}]>
2.1.2:跨表分组查询
1 查询出版社名称以及每个组中出版社的数量 2 select app01_publish.name,COUNT(1) from app01_book INNER JOIN app01_publish ON app01_book.publish_id=app01_publish.nid 3 4 GROUP BY app01_publish.nid
案例1:
查询每一个出版社的名称以及对应的书籍平均价格 ret=Publish.objects.values("name").annotate(avg_price=Avg("book__price")) print(ret) # <QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]>
ret=Publish.objects.values("name","email").annotate(avg_price=Avg("book__price")) #按照name,email字段分组。也就是name相同,email也相同的分在一组
print(ret) # <QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]>
案例2:
查询每一个作者的名字以及出版的书籍的最高价格 ret=Author.objects.values("pk","name").annotate(max_price=Max("book__price")) print(ret) 查询每一个书籍的名称以及对应的作者的个数 ret=Book.objects.values("title").annotate(c=Count("authors")) print(ret) # <QuerySet [{'title': 'python', 'authors__count': 2}, {'title': 'linux', 'authors__count': 1}, {'title': 'go', 'authors__count': 1}, {'title': 'java', 'authors__count': 0}]>
补充:
ret=Publish.objects.all()print(ret) # <QuerySet [<Publish: 苹果出版社>, <Publish: 橙子出版社>, <Publish: 西瓜出版社>]> #all表示所有字段
ret=Publish.objects.all().annotate(avg_price=Avg("book__price")) #相对于上面多了一个book__price字段
print(ret) # <QuerySet [<Publish: 苹果出版社>, <Publish: 橙子出版社>, <Publish: 西瓜出版社>]>
下面两种方式是相同的。方式二是方式一的简写
方式一
按哪个字段分组.annotate(分完组后需要统计的的字段).values(取出哪个字段的值)
ret=Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name","email","avg_price")
print(ret) #<QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]>
annotate前面表示分组,annotate表示分完组后按哪个字段统计(得到QuerySet的对象就是按什么分组的那个字段加上annotate要统计的字段)。value表示取值
方式二
ret=Publish.objects.annotate(avg_price=Avg("book__price")).values("name","email","avg_price")
print(ret) #<QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]>
还是案例1,那么案例1的书写方式:
# 1 查询每一个出版社的名称以及对应的书籍平均价格 # 方式1: # ret=Publish.objects.values("name","email").annotate(avg_price=Avg("book__price")) # print(ret) # <QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]> # 方式2: ret=Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name","email","avg_price") print(ret) # <QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]> # 方式3: ret=Publish.objects.annotate(avg_price=Avg("book__price")).values("name","email","avg_price") print(ret) # <QuerySet [{'name': '苹果出版社', 'avg_price': 117.0}, {'name': '橙子出版社', 'avg_price': 112.0}, {'name': '西瓜出版社', 'avg_price': 222.0}]>
案例2的书写方式:
2 查询每一个作者的名字以及出版的书籍的最高价格
方式一: ret=Author.objects.values("pk","name").annotate(max_price=Max("book__price")) print(ret)
方式二: ret=Author.objects.annotate(maxprice=Max("book__price")).values("name","maxprice") print(ret)
2.2种类二:复杂分组查询(除了group by ,还有having就是分组之后再次过滤)
查询作者数不止一个的书籍名称以及作者个数 ret=Book.objects.annotate(c=Count("authors__name")).filter(c__gt=1).values("title","c") SQL: SELECT book_book.title,COUNT(book_author.nid) as c from book_book LEFT JOIN book_book_authors ON book_book.nid = book_book_authors.book_id LEFT JOIN book_author ON book_author.nid = book_book_authors.author_id GROUP BY book_book.nid,book_book.title,book_book.price HAVING c>1
根据一本图书作者数量的多少对查询集 QuerySet进行排序 ret=Book.objects.annotate(c=Count("authors__name")).order_by("c") 升序,-c就是降序
统计每一本以py开头的书籍的名称以及作者个数 ret=Book.objects.filter(title__startswith="py").annotate(c=Count("authors__name"))
三:F与Q查询
from django.db.models import F,Q
1:F(普通运算)
两个不同字段相互运算需要加上F(),因为两个字段不能直接运算
查询评论数大于100的所有的书籍名称 ret=Book.objects.filter(comment_count__gt=100).values("title") 查询评论数大于2倍点赞数的所有的书籍名称 ret=Book.objects.filter(comment_count__gt=F("poll_count")*2) #比较两个字段是没法比的,所以用F函数 print(ret)
给每一本书籍的价格提升100 Book.objects.all().update(price=100+F("price"))
2:Q(逻辑运算)
(1)基本使用
# 查询价格大于300或者评论数大于3000的书籍 # ret=Book.objects.filter(price__gt=300,comment_count__gt=3000) # print(ret) # 与 & 或 | 非 ~ # ret = Book.objects.filter(Q(price__gt=300)|~Q(comment_count__gt=3000)) # print(ret) ret = Book.objects.filter(Q(Q(price__gt=300) | ~Q(comment_count__gt=3000))&Q(poll_count__gt=2000)) ret = Book.objects.filter(Q(Q(price__gt=300) | ~Q(comment_count__gt=3000)),poll_count__gt=2000) #ret = Book.objects.filter(poll_count__gt=2000,Q(Q(price__gt=300) | ~Q(comment_count__gt=3000))) print(ret)
(2)深入使用
精确查询
#引入 >>>from django.db.models import Q >>>from app01.models import UserInfo,Customer >>>Customer.objects.filter(Q(name="王丽丽")) #过滤条件是字段 <QuerySet [<Customer: 王丽丽:66668888>]> >>>q=Q() >>>q.children.append(("name","王丽丽")) #条件放到了q对象里了;注意这里的条件是字符串 >>>Customer.objects.filter(q) #过滤 <QuerySet [<Customer: 王丽丽:66668888>]>
注意:当字段是字符串的时候的另一种方法:
StudentStudyRecord.objects.filter(pk=pk).update(**{field:value}) #**{field:value} 相当于 field=value 打散 不过这个方法只有且的关系
##################默认是且的关系(and) >>>q=Q() >>>q.children.append(("sex","女")) #元组 >>>q.children.append(("name","王丽丽")) >>>Customer.objects.filter(q) <QuerySet []> ########################## >>>q=Q() >>>q.connector="or" >>>q.children.append(("sex","女")) >>>q.children.append(("name","王丽丽")) >>>Customer.objects.filter(q) <QuerySet [<Customer: 王丽丽:66668888>]>
模糊查询
q.children.append((field+"__contains",val))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号