
1 模块的介绍
1.1 什么是模块
写好的函数、变量、方法,放在一个文件里(这个文件可以被我们直接使用),这个文件就是模块。简言之,模块就是一组写好的功能的集合。python文件有py、dll、zip文件,dll文件(c写的)
1.2 如何写一个模块
(1) 创建一个py文件,给它起一个符合变量名命名规则的名字,这个名字就是模块名。
(2) import 模块名 #pycharm认为你的模块导入不进来,会显示语法错误
2 模块的导入
2.1 import
2.1.1 import 导入
import 模块名
(模块的导入相当于这个模块所在的文件,模块可以被重复导入,模块的多次导入不会重复执行)
使用:模块名.方法/变量
2.1.1.1 模块的导入过程发生了什么?
模块导入的过程:
|
(1) 找到这个模块 (2) 判断这个模块是否被导入过了 (3) 如果没有被导入过 a) 创建一个属于这个模块的命名空间 b) 让模块的名字 指向 这个空间 c) 执行这个模块中的代码
|
2.1.2 import的命名空间
import的命名空间,模块和当前文件在不同的命名空间中,这也是本空间与模块空间的变量不冲突的原因
2.1.2.1 如何判断模块已经被导入过了?
|
import sys |
2.1.3 导入多个模块
import os,time
缺点:
一注释就全注释了
规范建议
模块应该一个一个的导入 ,如下是被导入的顺序(可以在每种模块之间加一行空格,好区分)
# 内置模块 # 扩展(第三方)模块 # 自定义模块
2.1.4 为模块起别名
给模块起别名,起了别名之后,使用这个模块就都使用别名引用变量了
2.1.4.1 简化版
import my_module as m
m.read1()
|
(分析:为什么只能使用别名引用变量?在引入的模块的时候创建了一块命名空间,这个是别名指向了命名空间,那么就和模块名没什么关系了。import my_module是找模块,找到后,然后创建命名空间,在之后就as m,as m表示给命名空间起名为m;因此只有m指向命名空间了 ) |
2.1.4.2 复杂版(当相同的操作时)
|
def func(dic, t='json'):
|
2.2 from…import
2.2.1 from…import 的导入
需要从一个文件中使用哪个名字,就把这个名字导入进来
# from my_module import name
然后可以直接使用模块里的变量、方法,而不用 “模块.方法()”
2.2.2 命名空间
导入过程发生了什么?
|
1.找到要被导入的模块 2.判断这个模块是否被导入过 3.如果这个模块没被导入过 创建一个属于这个模块的命名空间 执行这个文件 找到你要导入的变量 给你要导入的变量创建一个引用,指向要导入的变量 3.如果这个模块已经被导入过 找到你要导入的变量 给你要导入的变量创建一个引用,指向要导入的变量 |
2.2.3 为导入的名字起别名
# from my_module import read1 as r1,read2 as r2
# def read1():
# print('in my read1')
# r1()
# r2()
# read1()
2.2.4 一行导入多个模块
# from my_module import read1,read2
# read1()
# read2()
2.2.5 *和__all__的关系
2.2.5.1 *
from my_module import * 这样把模块中的所有的都导入进来了,但是两个空间并不是合在一体了
(import *,就是在创建完命名空间后,所有的这些变量名、方法名都是指引了这个命名空间的对应的名字)
2.2.5.2 __all__(特殊的变量,只能是一个列表)
2.2.5.2.1 前提:
from my_module import *
2.2.5.2.2 作用:
__all__能够约束*导入的变量的内容,*会参考__all__变量,如果from my_module import name这样的__all__约束不了
2.2.5.2.3 案例:
如果模块A中没有__all__变量,那么当导入模块A时会执行一遍模块中的内容,但是如果模块A中有__all__变量,且这个变量中的列表中的东西才能在导入模块A后能被使用不报错
|
__all__ = ['name'] #主要里面是str,因为此时变量都还没创建
print(12345) name = 'alex' def read1(): print('hello world') def read2(): print('in read1 func',name) print(54321)
-------》以上是模块内容如果是在引用此模块from my_module import *,这么引用的,那么就只能使用__all__变量里的东西
if __name__ == '__main__': print(__name__) # "__main__" print([__name__])
|
|
模块classes中: print('123') def read1(): print('haha') def read2(): print('hihi') print('456') print([__name__])
---》单独运行结果: 123 456 ['__main__']
程序文件中 from classes import * read1()
-----》结果: 123 456 ['classes'] haha
-----》结论: 1、 |
3 模块引用中的情况
3.1 模块的循环引用(***)
假如有两个模块a,b。我可不可以在a模块中import b ,再在b模块中import a?
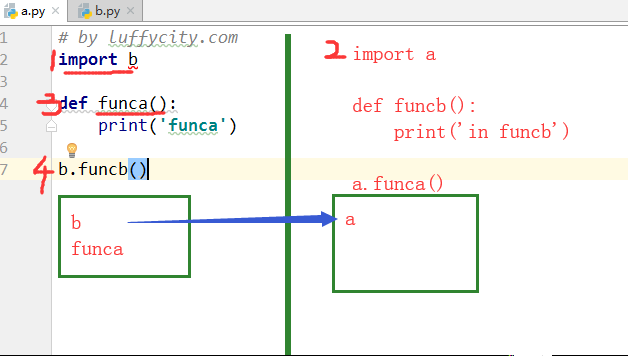
模块之间不允许循环引用
3.2 模块的加载和修改(*)
已经被导入的模块发生了修改,是不会被感知到的。那么该怎么感知呢?方法有两个
第一:重新加载模块
import lib import lib.reload(模块名)
第二:重启程序
3.3 把模块当作脚本执行(*****)
3.3.1 什么是脚本、模块
直接运行这个文件 这个文件就是一个脚本
导入这个文件 这个文件就是一个模块
3.3.2 执行一个py文件的方式:
(1)在cmd执行,在python执行 : 直接执行这个文件--> 以脚本的形式运行这个文件
(2)导入这个文件(在导入的过程中就会把模块执行一遍)
|
针对导入模块,我们并不希望它输出结果,而是我们调用它时输出我们想要的结果。我们只想要模块中的某一功能,那么该如何做呢? # 当一个py文件 # 当做一个脚本的时候 : 能够独立的提供一个功能,能自主完成交互 # 当成一个模块的时候 : 能够被导入这调用这个功能,不能自主交互
# 一个文件中的__name__变量 # 当这个文件被当做脚本执行的时候 __name__ == '__main__' # 当这个文件被当做模块导入的时候 __name__ == '模块的名字' |

3.4 模块的搜索路径(*****)
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看
在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
和被当做脚本执行的文件 同目录下的模块,可以被直接导入
除此之外其他路径下的模块, 在被导入的时候需要自己修改sys.path列表
import sys import calculate #自己写的模块 print(sys.path) path = r'D:\sylar\s15\day21\5模块的循环引用' sys.path.append(path)
|
4 包
4.1 包的介绍
4.1.1 什么是包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
|
#具体的:包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
#需要强调的是: 1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
|
4.1.2 为何使用包
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来
随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能,而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性
4.1.3 注意事项
|
#1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
#2、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
#3、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
|
4.2 __init__.py
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
4.3 从包中导入模块
例子:
方式一:import
# import glance.api.policy
# glance.api.policy.get()
# import glance.api.policy as policy
# policy.get()
方式二:from import
# from glance.api import policy
# policy.get()
# from glance.api.policy import get
# get()
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
4.3.1 from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有*。
此处是想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件中定义__all___:
4.4 直接导入包
直接导入包 ,需要通过设计init文件,来完成导入包之后的操作
导入一个包
# 不意味着这个包下面的所有内容都是可以被使用的
# 导入一个包到底发生什么了?
# 相当于执行了这个包下面的__init__.py文件
|
glance/
├── __init__.py
├── api
│ ├── __init__.py __all__ = ['policy','versions']
│ ├── policy.py
│ └── versions.py
├── cmd __all__ = ['manage']
│ ├── __init__.py
│ └── manage.py
└── db __all__ = ['models']
├── __init__.py
└── models.py
|
4.4.1 绝对导入
4.4.1.1 什么是绝对导入:
以glance作为起始
4.4.1.2 绝对导入的优缺点
优点:容易找到层级关系
缺点:如果当前导入包的文件和被导入的包的位置关系发生了变化,那么所有init文件都要做相应改变
4.4.1.3 绝对导入的分析
环境:
|
E:\python\老男孩\代码\模块\20180823模块和包
├── glance/
├── bao.py |
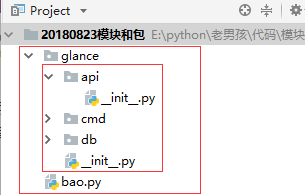
操作
|
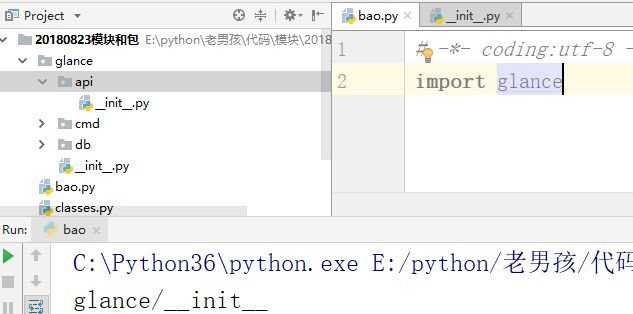
当在bao.py文件中: import glance #不报错,因为glance和bao.py在一个文件中 如何导入api文件? 我们在glance/__init__.py文件中写入import api 在bao.py中运行会报错,在glance/__init__.py中不报错 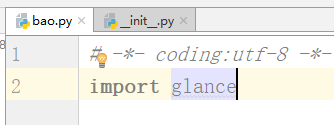 
原因分析: 当我们运行bao.py时,sys.path()决定了路径我们同目录下导入是没有问题的,import glance 是在E:\python\老男孩\代码\模块\20180823模块和包 路径下执行的glance/__init__.py这个是可以的。但是在我们在glance/__init__.py文件中写入import api,但我们执行bao.py,我们依然在上面的路径中,因此会报错 |
|
针对操作2:
可以看到这种方法是可行的,但这种方法太麻烦。 |
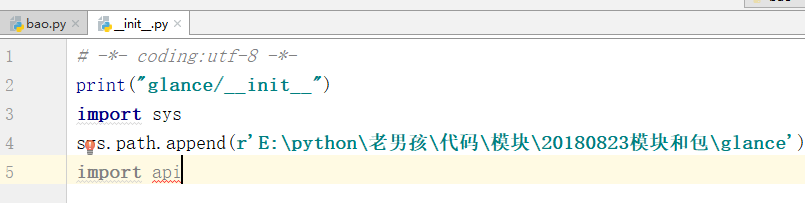
|
操作3:
根据glance识别api,那么同理api/__init__.py路径这么写
再次运行bao.py:
|
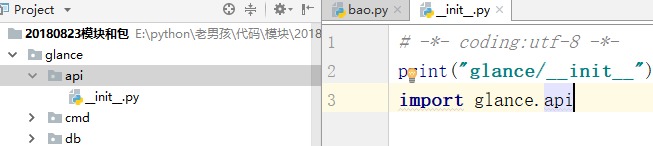

从上面的操作中我们引出了绝对导入
我们以glance为根。然后通过设计下面的目录__init__.py文件。
但绝对引入的缺点就是我们把glance目录移动到别处去
如果当前导入包的文件和被导入的包的位置关系发生了变化,那么所有init文件都要做相应改变
4.4.2 相对导入
4.4.2.1 什么是相对导入:
用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
4.4.2.2 相对导入的优缺点 :
优点:
不需要去反复的修改路径
只要一个包中的所有文件夹和文件的相对位置不发生改变
也不需要去关心当前这个包和被执行的文件之间的层级关系
缺点
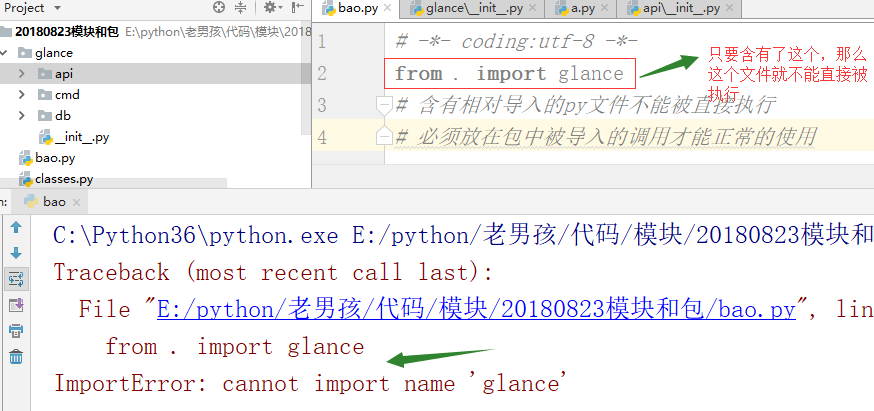
含有相对导入的py文件不能被直接执行
必须放在包中被导入的调用才能正常的使用
4.4.2.3 相对导入的理解
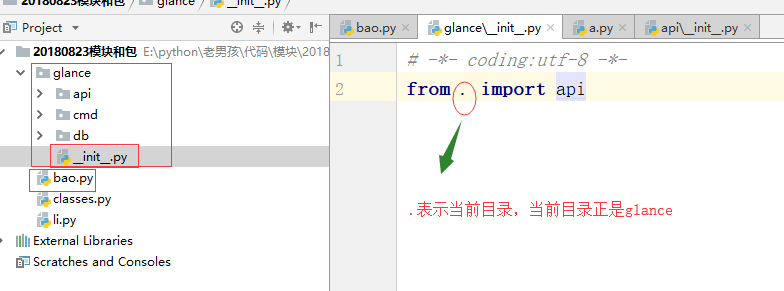
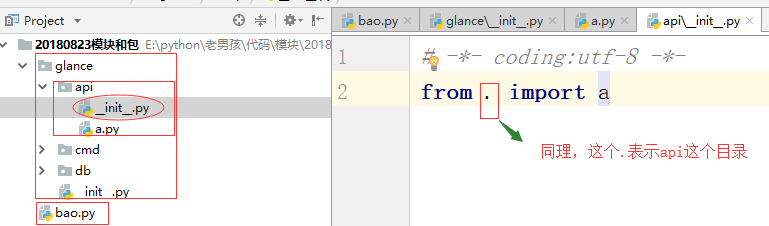
再次运行bao.py文件运行正常
这样即使路径变了
优点:
不需要去反复的修改路径
只要一个包中的所有文件夹和文件的相对位置不发生改变
也不需要去关心当前这个包和被执行的文件之间的层级关系
缺点
# 含有相对导入的py文件不能被直接执行---》如果glance文件的路径改在bbb下(与bao.py同级),那么在bao.py中写入from . import bbb,这会报错。(本身bbb就是bao.py同级)
# 必须放在包中被导入的调用才能正常的使用
5 软件开发规范
文件的拆分:
|
bin目录: |
放启动脚本 |
|
core目录 |
放入核心代码 |
|
db目录(database) |
数据库 |
|
lib目录: |
库(如os这种的是库,不是内置的也不是第三方库,可以是自己写的, 但这里并不是大家认可的,还和当前项目的相关性不大,通用模块) |
|
conf目录: |
配置文件,用到了某一个值,这个值在程序执行的过程中会被修改,且一旦修改,要修改代码,要修改多处。这样的值,我们应该单独的写在 |
|
log目录 |
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号