网络包接收流程——Linux
这几天突发奇想,突然好奇数据从网线进入网卡是通过怎么样的一个流程最终才被程序读取到的,所以,特此梳理一篇文章!
1. 网卡&驱动程序&操作系统
考虑你平时编写的代码:
int l = recvfrom(socketfd, buf, size, 0);
你的代码运行在操作系统上,操作系统暴露给你的API是socket,你在socket上recvform,然后你就会等待,直到读到来自网络的数据。我猜想这里面有如下组件付出了努力:
- 网卡硬件:在传输媒介(如网线、无线)中传输的数据,或者说网卡接到的数据是比特流。根据不同类型的介质和网络类型,网卡或许需要识别特定的比特pattern(如前导码、帧起始界定符)来判定链路层帧开头和结束。网卡还需要执行CRC校验、MAC地址过滤等。最终,网卡会持有发送给我们的链路层帧。
- 网卡的驱动程序:网卡中被我们需要的链路层帧最后需要通过某种方式进入内存,比如DMA情况下,网卡驱动一定需要预先注册好DMA要拷贝到的内存位置。另外,每当帧从网卡被移到内存,网卡一定会通过中断机制来通知驱动程序继续处理该链路层帧。
- 操作系统:网卡驱动程序不可能实现整个协议栈,它顶多实现链路层协议,所以,OS必须给驱动程序接口,让驱动程序的帧被协议栈层层解析,最终进入socket队列中,被应用进程所用。
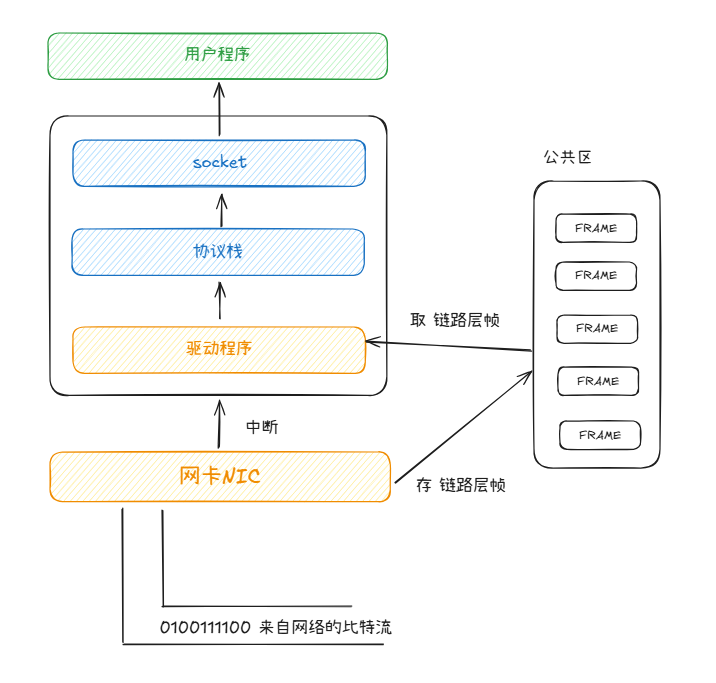
当然,这张图和上面的文字只是我当前的猜想,具体实现可能有所区别,不过这足以让我们想清楚整个链路中有哪些组件,以及它们大致的职责。
2. Linux下的实现
下面我们将探究Linux下网络包收取的实现方式。从哪里探起呢?
驱动程序一定会为网卡设置DMA来允许网卡在收到完整帧时将其拷贝到内存。
2.1. 网卡DMA设置
Linux驱动都会有一个描述结构体,我们只需要打开想要阅读代码的驱动,搜索相应关键字即可(比如搜.probe)。
这里我们以e1000网卡的驱动为例,它在/drivers/net/ethernet/intel/e1000/e1000_main.c:
static struct pci_driver e1000_driver = {
.name = e1000_driver_name,
.id_table = e1000_pci_tbl,
.probe = e1000_probe,
.remove = e1000_remove,
#ifdef CONFIG_PM
/* Power Management Hooks */
.suspend = e1000_suspend,
.resume = e1000_resume,
#endif
.shutdown = e1000_shutdown,
.err_handler = &e1000_err_handler
};
该结构体中的.probe属性,就是设备被发现时的回调,一般设备初始化、DMA配置等操作都在此。
e1000_probe->e1000_sw_init->e1000_alloc_queues,根据网卡适配器结构中的tx和rx队列个数,分配tx_ring和rx_ring的内存,这应该就分别是网卡发送和接收环状缓冲,DMA会将数据发送到rx_ring。
adapter->tx_ring = kcalloc(adapter->num_tx_queues,
sizeof(struct e1000_tx_ring), GFP_KERNEL);
if (!adapter->tx_ring)
return -ENOMEM;
adapter->rx_ring = kcalloc(adapter->num_rx_queues,
sizeof(struct e1000_rx_ring), GFP_KERNEL);
if (!adapter->rx_ring) {
kfree(adapter->tx_ring);
return -ENOMEM;
}
在e1000_open回调中,通过调用e1000_setup_rx_resources,将这块内存与设备DMA映射了:
static int e1000_setup_rx_resources(struct e1000_adapter *adapter,
struct e1000_rx_ring *rxdr)
{
// ...
rxdr->desc = dma_alloc_coherent(&pdev->dev, rxdr->size, &rxdr->dma, GFP_KERNEL);
// ...
}
至此,网卡在具有帧的情况下就可以DMA到rx_ring中,并发起中断
2.2. 中断处理程序注册
在e1000_open中调用了e1000_request_irq注册了网卡中断的处理函数——e1000_intr:
static int e1000_request_irq(struct e1000_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
irq_handler_t handler = e1000_intr;
int irq_flags = IRQF_SHARED;
int err;
err = request_irq(adapter->pdev->irq, handler, irq_flags, netdev->name,
netdev);
if (err) {
e_err(probe, "Unable to allocate interrupt Error: %d\n", err);
}
return err;
}
2.3. 处理中断
到此,我们已经知道在e1000_intr中会处理网卡传过来的中断,在中断中,我们需要读取rx_ring中的帧数据,向上传递给协议层。
/**
* e1000_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t e1000_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct e1000_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
u32 icr = er32(ICR); // icr => 中断原因
if (unlikely((!icr)))
return IRQ_NONE; /* Not our interrupt */
/*
* 驱动down了,直接已处理
*/
if (unlikely(test_bit(__E1000_DOWN, &adapter->flags)))
return IRQ_HANDLED;
/*
* 如果中断原因是序列接收错误,或链路状态变化。异步处理这些情况
*/
if (unlikely(icr & (E1000_ICR_RXSEQ | E1000_ICR_LSC))) {
hw->get_link_status = 1;
if (!test_bit(__E1000_DOWN, &adapter->flags))
schedule_delayed_work(&adapter->watchdog_task, 1);
}
// 关闭中断
ew32(IMC, ~0);
E1000_WRITE_FLUSH();
// napi检查
if (likely(napi_schedule_prep(&adapter->napi))) {
adapter->total_tx_bytes = 0;
adapter->total_tx_packets = 0;
adapter->total_rx_bytes = 0;
adapter->total_rx_packets = 0;
__napi_schedule(&adapter->napi); // napi调度
} else {
/* this really should not happen! if it does it is basically a
* bug, but not a hard error, so enable ints and continue
*/
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return IRQ_HANDLED;
}
中断代码也没干啥,貌似就是关中断,委托napi去做一些操作,napi是啥呢??这些操作是啥意思呢??
2.3. Napi
Napi是Linux为网络驱动设备提供的一种高效API,使用中断与轮询相结合的一种工作方式,避免高网络负载时的中断风暴。
- 中断触发:第一个数据包到达,网卡触发中断
- 中断处理:关闭网卡中断,开始主动轮询网卡接收队列
- 退出条件:当轮询到达时间限制或处理完所有数据包时,开启中断
2.3.1. napi_struct
// include/linux/netdevice.h
/*
* Structure for NAPI scheduling
*/
struct napi_struct {
// 链表节点,用于将当前驱动的napi_struct实例链接到CPU全局轮询队列
struct list_head poll_list;
// napi当前状态
unsigned long state;
// 每次轮询最大包处理量
int weight;
// gro机制是将多个相似的小包合并成大包的机制,这个是合并数量
unsigned int gro_count;
// 网卡驱动的轮询回调,一会会提到
int (*poll)(struct napi_struct *, int);
// 设备,用于获取设备上下文
struct net_device *dev;
// 合并后数据包链表头
struct sk_buff *gro_list;
struct sk_buff *skb;
struct list_head dev_list;
};
2.3.2. 注册轮询回调
在e1000_probe中,驱动向linux注册了轮询的回调函数——e1000_clean:
// e1000_probe中的调用
netif_napi_add(netdev, &adapter->napi, e1000_clean, 64);
netif_napi_add函数:
void netif_napi_add(struct net_device *dev, struct napi_struct *napi,
int (*poll)(struct napi_struct *, int), int weight)
{
INIT_LIST_HEAD(&napi->poll_list);
hrtimer_init(&napi->timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_PINNED);
napi->timer.function = napi_watchdog;
napi->gro_count = 0;
napi->gro_list = NULL;
napi->skb = NULL;
napi->poll = poll;
if (weight > NAPI_POLL_WEIGHT)
pr_err_once("netif_napi_add() called with weight %d on device %s\n",
weight, dev->name);
napi->weight = weight;
list_add(&napi->dev_list, &dev->napi_list);
napi->dev = dev;
#ifdef CONFIG_NETPOLL
napi->poll_owner = -1;
#endif
set_bit(NAPI_STATE_SCHED, &napi->state);
napi_hash_add(napi);
}
2.3.3. __napi_schedule
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
// 获取每个cpu的softnet_data
____napi_schedule(&__get_cpu_var(softnet_data), n);
local_irq_restore(flags);
}
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
// 将网卡napi的poll节点,追加到cpu poll_list的poll节点
list_add_tail(&napi->poll_list, &sd->poll_list);
// 发起软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
可以看到__napi_schedule就是将当前网卡的napi挂载到某个cpu的全局链表中,这样cpu或许就能通过napi中定义的poll回调来调度e1000_clean来轮询包了。
注意__napi_schedule必须在中断关闭的情况下调用,硬中断产生时中断本就是关闭的,硬中断处理结束后恢复。
在__napi_schedule的最后,调用了__raise_softirq_irqoff发起了网络接收软中断,该软中断的处理程序就是调用当前CPU的napi链表中的poll回调来处理网络包。
由于硬中断发生时,整个中断都是屏蔽的,为了不影响全局,大部分重型中断处理程序都会把中断处理分成上下两部,硬中断中快速完成返回,恢复中断,后续慢慢处理复杂步骤。Linux实现上下部的方式是通过软中断。
至此,e1000网卡的中断处理程序运行结束,全程都是很轻量级的操作:
- 检查一些错误
- 关闭网卡中断
- 将自己的napi挂到某个cpu的链表中,等待cpu调度,轮询网络包
- 发起软中断
不知读者是否注意,每一次网卡包的硬中断,设备的napi结构体都会被挂在同一个cpu上,并触发当前cpu的软中断,然后当前cpu负责处理本次的轮询。
2.4. e1000_clean
这里面的代码好像...和读取有关的只有adapter->clean_rx这一行
/**
* e1000_clean - NAPI Rx polling callback
* @adapter: board private structure
**/
static int e1000_clean(struct napi_struct *napi, int budget)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter,
napi);
int tx_clean_complete = 0, work_done = 0;
tx_clean_complete = e1000_clean_tx_irq(adapter, &adapter->tx_ring[0]);
// 清空rx_ring
adapter->clean_rx(adapter, &adapter->rx_ring[0], &work_done, budget);
if (!tx_clean_complete)
work_done = budget;
/* 如果本次轮询没有耗空预算,认为当前网络负载已经不高了,开启网卡中断 */
if (work_done < budget) {
if (likely(adapter->itr_setting & 3))
e1000_set_itr(adapter);
napi_complete(napi);
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return work_done;
}
还记得rx_ring吗,在e1000_probe中,驱动配置了网卡的DMA,当网卡接收到包时,会通过DMA将其直接拷贝到rx_ring,然后再触发中断。所以,我们的接收程序本质上就是消费rx_ring中的包。
clean_rx绑定到了e1000_clean_jumbo_rx_irq函数,这个函数太长,而且全部是硬件相关的细节,这里我们就不看了,最终,e1000_clean_jumbo_rx_irq->e1000_receive_skb->napi_gro_receive->napi_skb_finish->netif_receive_skb。
从这个调用链路基本可以看出,e1000是从ring_rx解出了包,并进行了该有的gro合并,放到一个sk_buff里,最终调用OS提供的napi函数,最终netif_receive_skb负责实际接收这些数据包。
2.5. netif_receive_skb
现在,网卡驱动程序的活已经结束了,接下来netif_receive_skb应该将这些包贯穿协议栈了。
这个代码太多,感觉大部分好像都是为了内核调试、网络跟踪工具、抓包工具还有特定的网络模式(VLAN)等定制的,比如这块:
/* 遍历全局协议处理链表(ptype_all),
ptype_all是对所有协议类型都感兴趣的处理函数列表,
一般是网络分析程序、抓包程序(如tcpdump)会注册到这个链表中
每一个元素都绑定了一个关心的设备和处理回调函数
这里就是将数据包deliver给这些程序 */
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) { // 设备匹配
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // 传递给上一个处理器
pt_prev = ptype; // 更新上一个处理器指针
}
}
下面这段代码是真的将数据包deliver给协议栈的:
// 取出协议类型
type = skb->protocol;
// 遍历所有跟当前协议类型相关的处理器链表
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // deliver到处理器
pt_prev = ptype;
}
}
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
return -ENOMEM;
atomic_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); // 调用处理器回调
}
至此,我们需要知道是谁给e1000网卡设备注册了各种协议类型的处理器。
2.6. 协议处理程序注册
在OS的inet_init中,将ip协议的处理程序注册到上面的ptype_base表中了,上级向协议栈deliver的只有链路层协议(至少我们当前关心的是这样的)。此外,我们也能够看到传输层协议的处理是在另一套方案中:
// ip协议结构体
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
// udp协议结构体,处理函数udp_rcv
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
// ... in inet_init:
inet_init() {
// ...
// 注册icmp、udp、tcp等处理函数
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
// ...
// 添加ip包处理函数
dev_add_pack(&ip_packet_type);
// ...
}
void dev_add_pack(struct packet_type *pt)
{
// 拿到ptype_all或者ptype_base(根据协议中的type)
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else
return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
至此,我们已经知道ip协议的处理函数是如何被放到ptype_base(以及ptype_all)中的了,并且我们也看到了一些传输层协议的注册。现在,我们看一看ip_rcv是如何解包并向协议栈上层deliver包的。
2.7. ip_rcv
过于专业,看不懂,但是最终,ip_rcv在处理了一大圈之后,进入了ip_local_deliver_finish函数,来完成数据包向上层协议栈的deliver:
// 解析inet_protos表,找到上层协议处理器
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
int ret;
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
goto out;
}
nf_reset(skb);
}
// 调用上层协议处理器
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
}
上文中udp、tcp已经把自己的协议处理程序注册到inet_protos表中了,这里读这个表来找到上一层的处理函数,并调用其处理程序。
2.8. udp_rcv
回顾:ip层解决了从主机到主机的消息递送,传输层加入了端口号,根据端口号,我们就可以找到绑定在该端口上的进程的socket信息
下面的代码我们也省略了很多内容,比如udp广播等处理,只保留了我们最关心的部分——udp解包并put到socket队列:
int udp_rcv(struct sk_buff *skb)
{
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
int __udp4_lib_rcv(...) {
struct sock *sk;
// ...
// 根据源、目标端,找到对应的socket
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
// 解包,放到socket中
int ret = udp_queue_rcv_skb(sk, skb);
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
// ...
}
int udp_queue_rcv_skb(...) {
ipv4_pktinfo_prepare(skb);
bh_lock_sock(sk); // 锁
if (!sock_owned_by_user(sk)) // 用户是否在socket上进行系统调用
rc = __udp_queue_rcv_skb(sk, skb); // 直接放到socket接收队列
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) { // 用户正在占用,放到backlog队列
bh_unlock_sock(sk); // 解锁
goto drop;
}
bh_unlock_sock(sk);
}
3. 总结&思考
3.1. Linux网络包接收的总体流程
- 网卡接收到比特流,分成帧,通过DMA将其拷贝到驱动注册好的
rx_ring中 - 网卡触发硬中断,某个CPU会响应中断
- 网卡驱动开始基于napi工作,将自己放到当前CPU的一个链表中,然后触发网络接收软中断,硬中断至此结束
- 软中断会回调网卡的napi结构体,调用其poll函数,主动轮询数据
- poll函数去
rx_ring中读取数据 - 读取到的帧会deliver到OS提供的协议栈中
- ip_rcv对ip协议进行解包,并向上交付
- udp_rcv或者tcp_rcv会对传输层协议进行解包,通过目标端口找到对应socket,将包放到socket的队列中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号