Paper:列存格式的实证评估
原文:An Empirical Evaluation of Columnar Storage Formats
本文是该论文的翻译,并非逐句翻译,只摘取了关键部分
本文论述了主流的开放标准列存储格式Parquet和ORC的实现差异、并提供了基于真实负载的有说服力的性能评估,并提出它们的不足。
介绍
关于开放格式列存文件:2010年早期,各种大数据处理引擎出现,如Hive、Impala、Spark和Presto,为了解决它们之间的数据共享,所以提出开源列存结构,Parquet和ORC就是其中比较常见的,且已经称为如今数据仓库和数据湖的事实标准。
为什么本篇论文出现了:
- Parquet和ORC已经被开发很多年了,当今软硬件环境发生了很大变化
- 持久存储性能获得巨大提升(G/s)
- 数据湖的兴起导致这些文件被大量的存储在廉价云存储上(S3...),它们通常具有高带宽和高延迟
- 学术上,越来越多的轻量级压缩模式、索引、过滤技术被发明。而现存的格式还在用2000年代的DBMS方法
- 之前关于存储格式的研究没有很好的分析它们的设计决策和权衡,且它们并没有使用真实世界的数据(从而没有数据分布的倾斜)
本篇论文的目标:分析常见列存文件格式(Parquet、ORC)的设计考量,以提供开发下一代存储格式的洞见。使用可靠的数据来分析二者在各方面的性能表现。特别是它们支持常见机器学习负载的效率以及设计是否对GPU友好。
本篇论文主要发现:
- Parquet和ORC之间并没有优劣,Parquet文件较小,列解码速度更快,ORC的zone map粒度更细,在剪枝(过滤)方面更为优秀
- 现实数据中大多数列只具有少量不同值(低NDV比率),非常适合字典编码。所以证书编码算法的效率对格式的大小和解码速度至关重要
- 现在的存储更快更便宜,可以使用更快的编解码方案,而非一味追求激进压缩以节省I/O带宽(即CPU反倒成了瓶颈)。格式不应该默认应用通用的块压缩(如gzip、zstd)
- Parquet和ORC提供了简单的辅助数据结构支持(如zone map、bloom filter),随着瓶颈从存储转移到计算,有机会将更复杂的结构和预先计算的结果嵌入到格式中,换取更少量的计算
- 现有格式在ML工作负载效率低下
- 当前格式没有提供足够的并行单元来充分利用GPU的计算能力
特征分类
前言
下表从各种方面(内部布局、编码方式、压缩、类型系统、zone map和索引粒度、布隆过滤器粒度、嵌套数据编码)来对比Parquet和ORC的设计差异:

另外,Parquet和ORC对于PAX布局方式中的术语并未统一,下表是本文采用的术语和两种格式各自的术语间的映射关系

格式布局
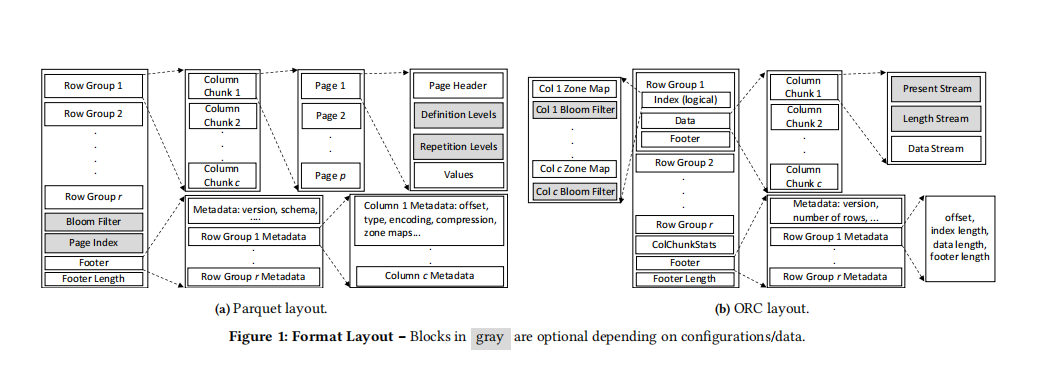
相同:
- 两种格式都使用PAX
- 首先将表中所有行水平分成多个row group,在每个row group内按列存储元素,每个列形成一个column chunk
- 这种格式具有纯按列存储(DSM)的好处——能够向量化查询处理;还有按行存储(NSM)的好处——即元组重建开销较小
- PAX已经是OLTP数据库的主流布局方式
- 两种格式都先将轻量级编码(如RLE、字典)方案应用于每个列块,然后可以应用通用的块压缩算法来减小列块大小
- 两种格式的入口都是页脚,其中包含文件级元数据(表结构、元组计数...)以及行组级元数据(偏移量、列块的zone map...)
不同:
- 行组大小:Parquet基于行数量(e.g., 1M个行) / ORC使用固定存储大小(e.g., 64MB)
- Parquet的方案可以保证行组中始终有足够的元素来向量化查询处理,但可能会陷入大的内存占用,尤其是对宽表来说
- ORC则能更好的限制内存用量,但对于大属性来说,可能导致行组中的元素数量不够
- 压缩:
- Parquet将压缩单元映射到最小的zone map上
- ORC调节块压缩算法在性能和空间上的权衡,以提供灵活性。而最小zone map和压缩单元之间的不对齐会在查询处理时引入额外的复杂性(如一个值跨了单元界限)
译者:这里的向量化处理说的应该是列式存储处理时可以将列视为一个向量,其在内存中以连续数组的形式存储,便于SIMD优化,可以被批量处理。但具体我也不懂。
编码
- 字典编码:
- Parquet会在默认情况下,激进的在每一列上应用字典编码,而不考虑类型
- ORC只将其应用在字符串上
- 二者都在字典code上又做了一层整数编码(或许是说RLE?)
- 它们仅使用Bitpacking和RLE进一步压缩字典编码
- 字典启停:
- Parquet给每一个column chunk一个字典大小限制,默认1MB。当字典满了,后面的值将不会再编码,保持原始值
- ORC则会计算NDV比率(NDV/行数)来确定是否在一个列上应用字典编码。如果NDV比阈值更大,ORC会关闭字典编码
- 整数列
- Parquet首先应用字典编码,然后在字典code上混合应用RLE和Bitpacking。当相同值连续出现大于等于8次,使用RLE,否则使用Bitpacking。这个8是不可调的,可能导致对于某些数据集的压缩效果不理想
- ORC整数编码器使用贪心算法为每一个值子序列采用最佳模式。从序列开始处,算法维护一个look-ahead缓冲(最大512个值),尝试检测特定模式。
- 若子序列具有3到10个相同值,使用RLE来编码它们
- 如果子序列单调递增或递减,使用Delta编码
- 对于剩下的子序列,使用Bitpacking或PFOR的一个变体来压缩,这取决于子序列中是否存在异常值(outlier)
- ORC精妙的编码算法让它可以获得更多压缩的机会(也许可以获得更好的压缩比),但是在四种算法见动态转换会减速解码过程,而且会建立更多的碎片化子序列,需要更多的元数据来跟踪
- 我们调查的所有开源DBMS和库都遵循Parquet和ORC的默认编码模式,没有在其之上来选择文件的编码算法

压缩
- 默认情况下二者都开启块压缩
- Parquet直接暴露了压缩比参数来让用户在空间和效率上权衡
- ORC只提供“optimized for speed”和“optimized for compression”选项
- 我们的关键发现:在现代硬件上给列式存储格式应用块压缩对于端到端查询速度没什么帮助
类型系统
类型实现方式:
- Parquet提供最小的原始类型集合(如INT32、FLOAT、BYTE_ARRAY),所有其它类型(如INT8、date、timestamp)都使用这些原始类型实现
- 示例:INT8在内部使用INT32表示,因为小整数可以很好的被字典编码表示,所以不用担心空间浪费
- ORC对于每种类型都有单独的实现,以及一个专用的reader和writer,这使得它可以做更多类型特定的优化,但也使得实现更加复杂
复杂类型:
Parquet/ORC都支持Struct、List和Map,Parquet不支持Union(ORC支持)
索引和filter
Zone Map简要介绍:
列存格式通常为一系列元素建立一个统计区域,该区域包含元素中的最大最小值,元素数量等。
这个结构用于在扫描时,不遍历数据本身的情况下进行一些数据跳过。
Zone Map粒度:
- 二者都支持file、row group级别的zone map
- Parquet最小粒度是物理页
- ORC可配置为指定行数量
Zone Map存储位置:
- Parquet 2.9.0之前,最小的zone map(页面级)存在page header中,这会带来额外随机IO。后面版本统一放在文件footer前的一个被称作PageIndex的区域
- ORC放在每一个行组开始处(随机IO)
布隆过滤器:
- ORC的布隆过滤器都有着和zone map相同的最小粒度和位置
- Parquet中只在column chunk粒度上维护布隆过滤器
- Parquet实现了Split Block Bloom Filter(SBBF),其具有更好的缓存性能和SIMD支持
商业系统的使用:
- DuckDB和Arrow只在row group级别使用Parquet的zone map
- Influx DB和Spark开启了PageIndex和Bloom Filter来用空间交换更好的性能
嵌套数据类型

- Parquet中的嵌套数据模型基于Dremel。将每一个原子域(叶子节点)的值作为独立的列存储(译者:这个嵌套数据的表示方法被精心设计过,不是那么直观,暂时不去理解了)
- ORC使用更直观的模型,其基于长度和存在性来编码
- 对于非原子域,ORC需要创建存在和长度两列,而Parquet将其编码在R和D中。Parquet的优势是可以读取更少的列,然而,由于在first和last中都冗余了name的存在性,所以,Parquet往往产生更大的文件
译者:Dremel的核心思路在于将JSON等嵌套数据类型打散,以让如
SELECT object FROM yy WHERE root.name.first = 'zz'这种语句可以直接执行。root.name.first域单独的表可以让它快速的找到匹配的数据,并通过R和D信息重建整个对象文档。
列存Benchmark
见原文
未完...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号