Flink: 在单引擎上实现流式和批处理
本文是Flink论文的翻译,并非通篇翻译,只摘了关键部分帮助更好的理解Flink是什么,架构如何设计。
原文:Apache Flink: Stream and Batch Processing in a Single Engine
读者最好对于流式处理系统有一些基本的认知,知道流式系统面临哪些问题,比如事件时间、处理时间、窗口、水印等概念。推荐阅读《Streaming System》一书,倒也不用太深读...xD
介绍
背景:
- 今天(论文发表时)我们需要一个流式处理引擎,但大多数组织还在用批的方式处理,无法满足低延迟需求
- 今天(论文发表时),流和批被认为式完全两种不同类型的应用程序,使用两种编程模型,在两套系统运行
- 即使有流批整合的系统(lambda架构),其复杂性也非常高
目标:
- 提供流式处理和批处理的统一模型,批处理其实是特殊的流处理(流是有限的,记录的顺序和时间不重要)
- 提供高度灵活的窗口机制,允许用户计算提前的近似结果或延迟的精确结果
- 支持不同的时间概念(事件时间、摄取时间、处理时间),方便程序员定义事件如何关联
系统架构
软件堆栈
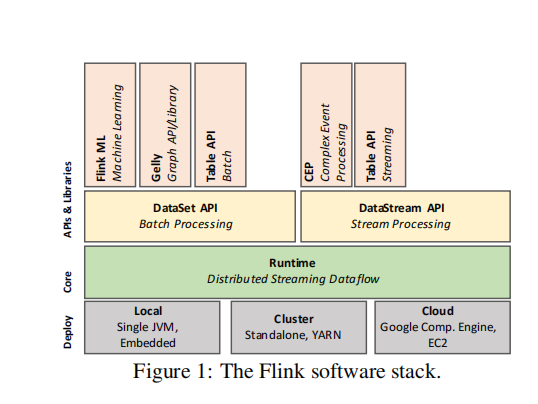
- core层是分布式dataflow引擎,用于执行dataflow程序。Flink运行时的程序就是一个由数据流(data stream)相连的有状态operator组成的DAG(其实Spark也是这样,它们论文里称为血缘)
- 往上是两个核心API,DataSet API用于处理有限数据(批处理),DataStream API用于处理无界数据(流处理)
- 在往上,是一些高级的API,用于快速构建机器学习应用、图处理应用以及SQL-like操作等
译者:Flink的核心运行时引擎可以被看作是一个流式dataflow引擎,而API则是用来创建该引擎可执行的程序的。无论使用什么API,最终创建的程序都是一个DAG,对于runtime来说是一样的。
译者:dataflow本应译为数据流,但Flink论文中还有一些并不同义的词用了data stream来描述。dataflow是指一个整体的由DAG描述的程序,data stream是指DAG中单个operator生成的流式数据。在后文中,我们将data stream翻译为数据流,dataflow不进行翻译
分布式处理模型
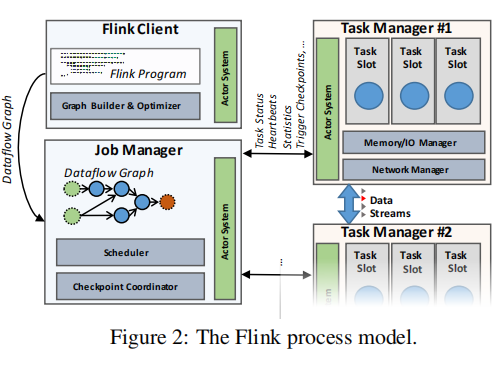
Flink集群由三种角色组成:
- 客户端:我想应该是嵌入到用户代码的一个库,它将用户代码转换成dataflow图,提交给JobManager。DataSet类型的程序还会额外的经历一个基于成本的查询优化阶段
- JobManager:协调dataflow的分布式执行,跟踪每一个operator和流(stream)的状态和进度,调度新的operator,协调检查点和恢复
- TaskManager:执行一个或多个operator来生成流,并向JobManager上报它们的状态。维护buffer pool来缓冲或物化流;维护网络连接来在operator之间交换数据流
通用结构:流式dataflow
即使用户可以使用大量不同的API来编写Flink程序,但最终,它们都会被编译成一个通用的表示:dataflow图。该图被Flink的运行时引擎执行,是DataSet和DataStream API之下的通用层。
Dataflow图
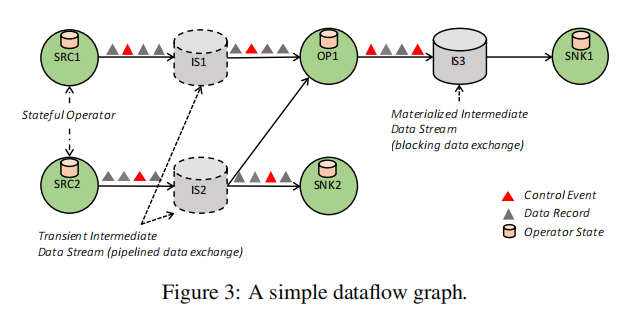
Dataflow图是一个DAG(有向无环图),它包含
- 有状态的operator
- 被一个operator产生的数据流,可以被其它的operator消费
dataflow图是以数据并行的方式执行的,所以operator实际上被并行化成一个或多个被称作subtask的并行实例,而流被分割成一个或多个流分区(stream partitions,一个producing subtask一个分区)。
译者:论文中把subtask基于单个数据流分成了两类,生成该流的称作producing subtask,消费该流的称作consuming subtask
有状态的operator(有些特殊情况下是无状态的)实现了所有的处理逻辑(如filter、hash join和stream window函数)。
流在producing和consuming operator之间,可能以多种模式分发数据,如:点对点、广播、重分区、扇出、合并
译者:论文中提到并行执行,我理解和Spark一样是将一个RDD分区带来的并行性,一个subtask就是一个分区嘛。而在流式处理中,我想很多情况或许operator之间还可以元素级pipeline化,进一步提升性能。
通过中间数据流的数据交换
中间数据流定义:被一个operator产生,被另一个或多个operator消费的数据流
Pipeline和Blocking的数据交换
Pipelined intermediate streams在并发运行的producer和consumer之间交换数据,最终导致流水线化执行。
pipelined stream传播了consumer到producer的背压,通过中间buffer pool提供弹性以缓解短期的吞吐量波动
无论是连续流式程序还是批处理程序的很多部分,Flink都使用了pipelined stream来尽可能的避免物化发生
而blocking stream必须在缓冲了全部producing operator的数据后才对消费者可用,从而将生产和消费的operator分割到不同的执行阶段。
Blocking Stream通常需要更多内存,偶尔要溢出到二级存储,不会传播背压
译者:看起来中间数据流应该是存储在producer operator执行的TaskManager的buffer pool中。对于这两种stream,感觉这个行为没啥区别,就是什么时候暴露给消费者的事?
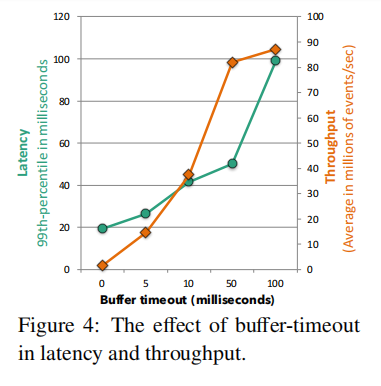
平衡延迟和吞吐量
Flink的数据交换机制围绕着buffer的交换实现,当数据在producer侧产生,它就被序列化并分配到一个或多个buffer上,稍后被转发给consumer。
一个buffer会被发送给consumer:
- 只要它满了
- timeout条件达到了
这让Flink可以通过设置buffer size到一个大值来达到高吞吐量;通过设置timeout到一个小值来实现低延迟
控制事件
除了交换数据,Flink中的流还交换着各种类型的控制事件
这些特殊事件被注入到operator的数据流中,和流分区内的所有其它数据记录、事件一起按顺序传送。接受的operator通过执行特定的动作来响应这个事件。Flink使用大量的特殊类型的控制事件,包含:
- checkpoint barriers:通过将流拆分成pre-checkpoint和post-checkpoint来协调检查点
- watermark:指示一个流分区中,事件时间的进度
- iteration barriers:signaling that a stream partition has reached the end of a superstep, in Bulk/Stale Synchronous-Parallel iterative algorithms on top of cyclic dataflows
容错
Flink能提供可靠的执行,这是通过严格精确一次处理的一致性保证,以及通过checkpoint和部分重执行来处理故障来完成的。为了实现这些,系统所做的通用假设是数据源是持久且可重放的(如文件、持久化消息队列)。实践中,可以通过在源操作符的内部状态中保存一个WAL来整合非持久性源。
CheckPoint机制基于分布式一致性快照构建,以达到精确一次保证。流式数据可能是无限的,为了限制恢复时间,Flink定期对操作符的状态进行快照,包含input流的当前位置。
核心挑战是对所有并行流进行一致性快照而不能停掉拓扑结构的执行,因为所有operator的快照应该在相同的计算逻辑时间。Flink使用的机制被称作异步屏障快照(ABS),屏障是注入到输入流的控制记录,关联了一个逻辑时间,它将流逻辑上分成两部分,一部分是将包含在当前快照的,另一部分是将稍后快照的。
操作符从上游接收到屏障,首先执行一个对齐阶段,确保已经接收到来自于所有输入的屏障(译者:有的operator是多个输入,快照时需等待所有的输入屏障都到达),然后,operator写下它的状态到持久存储中,一旦状态被写入,operator将barrier转发到下游。
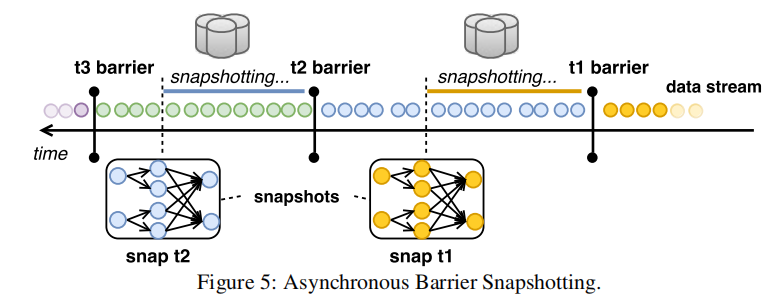
恢复时,只需恢复所有操作符的最后一个成功快照即可。
迭代数据流
略
Dataflow上的流式分析
DataStream API在运行时上提供了一个完整的流式分析框架,包含乱序事件处理、定义窗口、维护以及更新用户定义的状态等机制。
Stream API基于DataStream概念,它是一个(可能无界)的给定类型的元素的不可变集合。
因为Flink运行时已经支持管道数据传输、持续的有状态的操作符以及一致性状态更新的容错机制,在其上叠加一个流式处理器基本上就是实现一个窗口系统以及状态的接口,这些对于runtime不可见,在它眼中的窗口只是有状态操作符的一个实现。
时间概念
Flink区别两种时间概念:
- 事件时间:事件发生的时间(如传感器上的信号关联的时间戳)
- 处理时间:处理数据时,机器的墙上时钟时间
在分布式系统中,事件时间和处理时间可能存在任意的倾斜,这个倾斜可能意味着在事件时间的语义上获取一个答案可能具有任意延迟。为了避免这种延迟,系统通常会周期性插入一个特别的事件,称作低水位(lower watermarks)来标记一个全局进度度量。
举个时间进程上的例子,一个水位包含一个时间属性t,表示所有低于t的事件已经进入operator。
水位源自拓扑的源头,在那里我们可以确定未来元素的固有时间。水印从源头传递到dataflow中其它operator,operator来决定如何对待watermark。如map、filter这种简单的操作,只是简单的转发它们接收到的水印(译者:因为它们的操作和时间无关),复杂的operator可能基于水印去做计算(如事件时间窗口),再转发它。如果operator有多个输入,系统只会转发最小的输入水印以确保正确结果。
基于处理时间的Flink程序再时间上不可靠,可能在恢复时导致不正确的重放结果,但它们具有更低的延迟。基于事件时间的程序在语义上更可靠,但有事件时间-处理时间的延迟。Flink包含第三种时间概念,称作摄取时间(ingestion-time),它是事件进入Flink的时间,它比事件时间延迟更低,比处理时间更精确。
流窗口
在无界流数据上的步进式计算通常是在不断演化的逻辑视图上完成的,这个视图被称为:窗口。
Apache Flink在通过由三个核心函数组成的灵活声明配置的有状态operator中集成了窗口功能:一个窗口assigner、可选的一个trigger以及一个evictor。这三个函数可以在已经预定义的通用函数实现池中直接选择,也可以自己定义。
assigner负责将记录分配到逻辑窗口中,举个例子,如果想实现事件时间窗口,assigner的决策可以基于记录上的时间戳。
可选的trigger定义了何时执行与窗口定义相关的操作。
可选的evictor确定了在每个窗口中保留哪些记录。
Flink的窗口分配过程有能力覆盖所有已知的窗口类型,如:周期性的时间、数量窗口、punctuation、landmark、session以及delta窗口。
下面是一个具有6秒且每2秒滑动的窗口定义(assigner),水印通过窗口的末端时,计算结果(trigger)
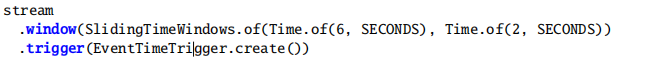
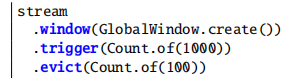
一个全局的窗口创建了一个单一的逻辑组,如下例子定义了一个全局窗口(assigner),每有1000个事件时调用操作(trigger),只保留最后100个元素(evictor)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号