Bigtable:一个用于结构化数据的分布式存储系统
本文是BigTable论文的翻译,并非通篇翻译,只摘了关键部分帮助更好的理解BigTable是什么,架构如何设计。
原文:Bigtable: A Distributed Storage System for Structured Data
介绍
Bigtable是谷歌设计的用于管理结构化数据的分布式存储系统,能够可靠地扩展至PB级数据和数千台机器,用于谷歌数十个产品和服务(谷歌分析、谷歌财经、个性化搜索、谷歌地球等),包含各式各样的工作负载,如从吞吐量导向型批量作业,到面向用户的低延迟数据服务。
数据模型
Bigtable是一个稀疏的、分布式的、持久化的多维度有序map,该map由row key、column key以及timestamp进行索引,值都是不经解释的字节数组
(row: string, column: string, time: int64) -> string
这个数据模型来自多种潜在的实际的用例,一个例子:假设我们想要保存大量web页面和相关信息的集合来用于多个项目,我们会使用一个名为Webtable的表,使用URL作为row key,web页面的各个方面作为列名(比如页面中所有a标签的内容),并且将web页面的内容存储在contents列中,列值实际存储在它们被抓取的时间戳下,如下图所示:

行
行是任意字符串,在单个row key下的数据读写是原子的(不管读写了多少不同的列),这让客户端能够在单行的并发更新下更好的推理系统行为。
Bigtable以row key的字典序维护数据,表的row range被动态分区,每一个row range称作tablet,是数据分布和负载均衡的单位。基于此,读短的行范围是非常高效的,并且通常只需要和少量机器交互。
用户可以利用这一点来设计row key,使得相关数据可以更好的聚合。比如在
Webtable案例中,将page的域名反向存储(反向域名/资源路径)以让相同域下的数据在存储上也相近。
列族(Column Families)
column key被分组到称作列族的集合中,列族,是访问控制的基本单元。
在任何列数据可以存储进列族之前,列族必须被显式的创建,只要列族创建了,任何column key都可以直接使用(译者:这里好像是在说列的创建是动态的,但其所属的列族必须是提前设计的)。我们的意图是,一个表中的列族通常很少,并且在操作过程中几乎不变,而对于列则可能会有无限数量个。
column key命名语法:列族名:限定符。举个例子,列族anchor存储网页中的链接,每一个column key都存储一个单一链接,限定符就是链接指向网站的名字,cell内容就是链接文本。
时间戳
Bigtable中的每一个cell都有同一数据的多个版本,它们通过时间戳被索引。时间戳可以被Bigtable实时分配,也可以被客户端程序显式指定。cell的不同版本以时间戳降序存储,最近的版本最先被读取。
为了减轻版本管理的负担,我们提供了两个列族级别的配置来告诉Bigtable如何自动GC单元版本。客户端可以指定只保存cell的last n版本,或只保存足够新的版本(如只保存近七天产生的版本)
API

向Bigtable写入,提供RowMutation抽象来执行一系列更新,调用Apply执行一个原子更新。

提供Scanner抽象来遍历特定行的所有anchors。客户端可以在多个列族上迭代,有多种方式来限制scan产生的行、列以及时间戳,例如,我们只限制上面的scan产出列匹配正则表达式anchor:*.cnn.com的,或只产出时间戳落在10天内的。
- Bigtable支持单行的事务,可以执行单个row key下原子的
read-modify-write - Bigtable允许cell作为整数计数器
- Bigtable支持执行客户端提供的脚本
Bigtable可以和MapReduce共用,我们已经编写了一系列的包装程序以让Bigtable可以作为MapReduce Job的输入数据以及输出数据。| 笔者之前的Map Reduce笔记
构建块
Bigtable构建在多个谷歌的其它基础设施之上
- 使用GFS存储日志和数据文件 | 译者之前的GFS论文笔记
- Bigtable集群通常运行在一个共享的机器池上,这些机器同时也在运行着其它分布式应用
- Bigtable依赖集群管理系统来调度任务、管理资源、处理机器故障、监控机器状态
- Bigtable内部使用谷歌的SSTable格式来存储数据
- Bigtable依赖高可用的持久性分布式锁——Chubby(如用来确保在任意时间只有一个master存在;存储Bigtable数据的bootstrap位置;发现tablet服务器,释放tablet server;存储Bigtable schema信息; 存储访问控制列表)。如果Chubby挂了,Bigtable就挂。
实现
三个主要组件:
- 一个链接到所有客户端的库
- 一个master服务器
- 许多tablet服务器(可以随着工作负载变更动态添加)
master负责:
- 给tablet服务器分配tablet
- 检测tablet服务器的新增和过期
- 均衡tablet服务器的负载
- 执行GFS文件的GC
- 处理schema变化(如表和列族的创建)
tablet服务器
- 管理一个tablet集合(通常一个tablet服务器有10到一千个tablet)
- 处理tablet的读写请求
- 分割变得过大的tablet
如同大多数单master的分布式存储系统,客户端直接与tablet server通信以读写数据,而且它们不依赖master来获取tablet位置信息,大多数客户端从不和master通信。实践中master的负载很轻。
一个表初始只包含一个tablet,随着表增大,它自动分割出多个tablet,默认每一个大约100到200MB。
Tablet位置
使用三级结构的模拟B+树来存储tablet位置信息
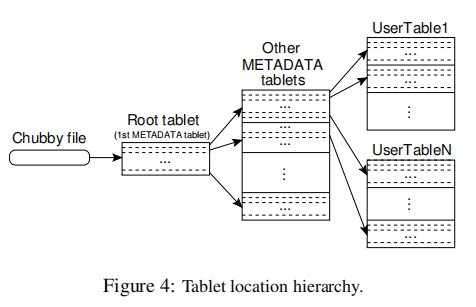
- 第一级是一个存储在Chubby中的文件,包含
root tablet的位置(1st元数据tablet) root tablet包含了所有tablet的位置,这些位置存储在一个特殊的METADATA表中- 每一个
METADATAtablet包含一系列用户tablet的位置 root tablet是METADATA表的第一个tablet,但被特殊对待了,它永远不会split,以确保tablet位置层次结构永远不会超过三级
METADATA表存储了row key所在的tablet位置,通过tablet的表标识符和tablet的end row来编码。每一个METADATA行存储大约1KB的内存数据。使用128MB的METADATAtablet,三级结构足以寻址\(2^{34}\)个tablet。
译者:考虑要查询Webtable表中的某一个rowkey(比如
com.google.map/xxx),首先要通过元数据表查询Webtable的所有tablet位置?并通过比较end row来确定所在tablet?此时并不知道数据是否真的存在,还要去tablet具体查询?
客户端库会缓存tablet位置,如果客户端不知道tablet的位置,或者发现缓存数据不正确,它按照tablet层次结构递归向上移动。如果客户端缓存为空,位置算法需要3个网络往返,包含一个Chubby读。如果客户端缓存过期,位置算法需要6个网络往返,因为过期的缓存条目只会在未命中时被发现(假设METADATAtablet不会变得太快)。因为tablet信息被存储在内存中,所以无需GFS访问,我们通过让客户端库预取tablet位置来进一步减少开销:无论何时它读取METADATA表时,它都会读取大于1个tablet
译者:看起来
METADATA表是一个内存表,那宕机咋办?依赖集群高可用吗?高可用的话怎么建立那个三级的树形层次结构?
Tablet分配
每一个tablet在给定时间只会分配给一个tablet server,master会跟踪存活的tablet server集合,以及当前server上的tablet分配情况(包含未分配的tablet)。当一个tablet未分配,并且有一个具有足够空间的tablet server,master会通过发送一个tablet负载请求到这个server上来分配tablet。
Bigtable使用Chubby来跟踪tablet服务器。当一个tablet服务器启动,它在指定Chubby目录下创建一个唯一名称的文件,并获取一个该文件的排他锁,master监控这个目录来发现tablet server。tablet server停止服务它的tablet,如果它丢失了它的排他锁。只要文件还存在,tablet server将会尝试重新获得排他锁,如果文件不存在了,tablet server将永远无法继续服务,所以它会杀掉自己(译者:或许是master放弃它了,将它的tablet全部调度给其它server,顺手删了它的文件告诉它不用回来了)。当tablet服务终结,它会尝试释放锁,以让master重新分配它的tablet。
译者:1. 首先Chubby好像是一个和ZooKeeper很像的东西,是一个分布式协调框架,只不过是基于锁的,也有文件层次结构。| 我半死不活的ZooKeeper论文笔记 2. tablet服务器本地貌似并不存储tablet,文件存在GFS,它只负责服务,所以它更像是一个无状态的计算服务?也不用担心failure
master为了检测tablet server的存活性,它周期性的询问每一个tablet server是否还持有锁,如果其回复已经没了,或者无法和它通信,master会尝试获取这个server文件的排他锁,如果master可以获取,那么就不是Chubby的问题,tablet server要么就是死了,要么就是无法和Chubby通信了,所以master此时可以直接删除它的server文件。一旦一个server的文件被删除,master可以将所有分配给它的tablet移动到未分配tablet列表中。为了确保master和Chubby之间没有网络问题,一旦master的Chubby session过期,master就会杀掉自己。同时,上面已经介绍过,master failures不会影响tablet和tablet server的分配(因为这些数据存在METADATA表)
译者:即使这样还是有一些细节问题,比如原子性怎么保证,master在删除某个tablet server文件后,将其上的tablet移动到未分配tablet之前failure,那么这些tablet将永远无法被访问?不过master应该能发现这一点,有没有无法发现的这种细节问题呢?
当master被集群管理系统启动,它需要在能够修改tablet分配状态之前发现这些状态。master会执行如下几步:
- master获取唯一的Chuuby
master锁,避免多master实例 - master扫描Chubby的server目录来发现存活server
- master与每一个存活tablet server交互来发现每一个server已经分配了哪些tablet
- master扫描
METADATA来学习tablet集合,当它发现了一个tablet并没被分配,它将其添加到未分配tablet集合中,使之能被分配(这解释了刚刚的问题,即有的tablet所在的server已经死了,但尚未被分配到未分配列表中)
One complication is that the scan of the METADATA table cannot happen until the METADATA tablets have been assigned. Therefore, before starting this scan (step 4), the master adds the root tablet to the set of unassigned tablets if an assignment for the root tablet was not discovered during step 3. This addition ensures that the root tablet will be assigned. Because the root tablet contains the names of all METADATA tablets, the master knows about all of them after it has scanned the root tablet.
tablet集合只会在以下几种情况下变更:
- 表创建删除
- 两个已经存在的tablet合并成一个更大的tablet
- 一个已经存在的tablet分割成两个更小的tablet
除了最后一个,其余两个都是master启动的,tablet split是tablet server启动的。server通过在METADATA表中记录新的tablet信息来完成split。In case the split notification is lost (either because the tablet server or the master died), the master detects the new tablet when it asks a tablet server to load the tablet that has now split. The tablet server will notify the master of the split, because the tablet entry it finds in the METADATA table will specify only a portion of the tablet that the master asked it to load
Tablet Serving
tablet的持久状态保存在GFS中,如图5。

更新被提交至一个存储redo记录的提交日志中,在这些更新中,最近的更新存储在被称作memtable的内存缓冲中,更老的更新被存储在一个SSTable序列中,为了恢复一个tablet,tablet server从METADATA表中读取它的元数据,这个元数据包含了组成tablet的SSTable列表,以及一系列的redo点,其指向任意的可能包含数据的提交日志上。server读取SSTable的索引到内存中,通过重放在redo点已经提交的所有更新来重建memtable。
当一个写操作到达tablet server,server检查它是否正确,并且检查发送者是否具有执行修改的权限(通过Chubby),一个有效的修改被写入到commit log中。为了提升吞吐量,大量的小型修改被以组的方式被批量提交。在写入已经被提交后,它的内容被插入到memtable。
当一个读取操作到达tablet server,它也检查是否格式正确,以及具有权限。一个正确的read操作在一个由SSTable序列和memtable组成的合并视图上执行。因为SSTable以及memtable都是字典序的有序数据结构,所以合并视图可以高效的形成。
在tablet被分割或合并过程中的read和write操作可以继续执行。
压缩
优化
本地组
压缩
读性能缓存
布隆过滤器
提交日志实现
加速tablet恢复
利用不可变性
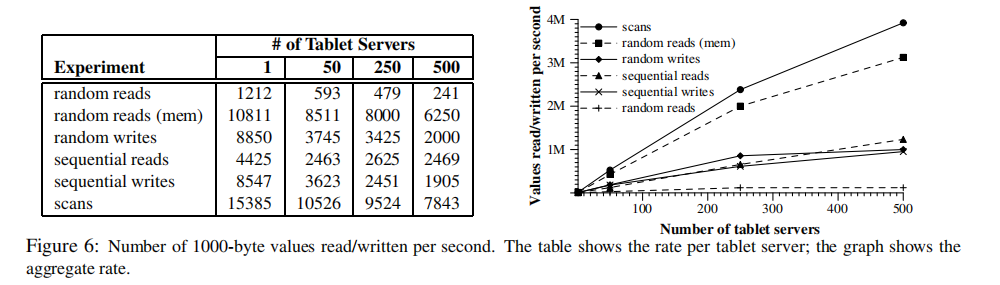
性能评估

 浙公网安备 33010602011771号
浙公网安备 33010602011771号