CSAPP(三)中——控制结构 程序的机器级表示
控制
CPU当然要提供一些指令和机制来允许开发者在其上构建出具有非完全顺序流程的程序了。
条件码
CPU维护者一组只有单个位的条件码寄存器,它们用来记录最近的算数或逻辑操作所产生的“副作用”。
- CF:进位标志。最近的操作使最高位产生了进位,可以用来检查无符号操作的溢出。
- ZF:零标志。最近的操作得到的结果为0。
- SF:符号标志。最近的操作得到的结果为负数。
- OF:溢出标志。最近的补码数操作得到了正溢出或负溢出。
leaq不改变任何条件码,因为它只用来做地址计算。对于逻辑操作,如XOR,进位和溢出标志会设置成0。移位操作进位标志将设置成最后一个被移出的位,溢出标志设置成0。INC和DEC会设置溢出和零标志,但不会改变进位标志(原因不知道书里没写)。
比较和测试指令
cmp指令和sub指令所做的操作相同,执行减法操作,但它不将结果设回到任何寄存器中,而是只设置条件码。test指令和and指令所做的操作相同,执行与操作,但也不设置结果,只设置条件码。
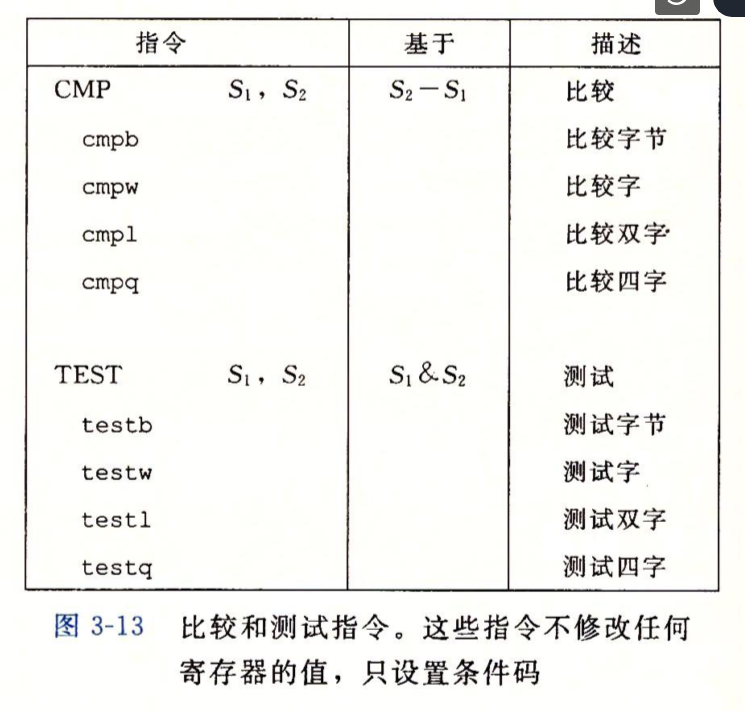
SET指令
set指令根据指定的条件码组合来判断一些事情是否发生,如果发生了,将一个位设置为1,否则设置为0,比如如果你想判断a是否小于b,你可能会手动调用cmp并自己想办法去根据条件码来确定这件事。你可能以为我们只需要读取一下SF条件码,看一看结果是否为负数就知道a是否小于b了,但是请考虑,在使用有限位表达的整数减法运算中会发生溢出,所以你往往需要完备周全的考虑来分析一个简单的比较操作的结果。
set指令是CPU提供给开发者和编译器的工具,它对于很多常见的判断(比如上面说的a<b)都提供了开箱即用的指令,虽然底层也是分析那些条件码的组合,但是你不用自己分析那些组合了。下面是set命令以及它们的条件码。
set指令的后缀表达的是要判断的条件,而非操作数的位数,比如setb不再是对字节操作,而是判断是否一个数在另一个数之下(below)。此外,有的set指令还有些别名,比如setg是大于,而setnle就是不小于等于,它们是等价的。
注意,对于有符号补码数,
set指令采用的术语是l-less,g-great,而对于无符号数,set采用b-below和a-above。
这里分析一下setg的条件码组合,它是用来判断a>b的。
令人迷惑的就是~(SF ^ OF),这个是用来判断a是否大于等于b的,也就是~(a<b),考虑t=a-b的六种情况:
| a | b | t=a-b | SF | OF | a<b? | 备注 |
|---|---|---|---|---|---|---|
| 负数 | 非负数 | <0 | 1 | 0 | 1 | 正常计算 |
| 负数 | 正数 | >0 | 0 | 1 | 1 | 负溢出 |
| 非负数 | 负数 | >0 | 0 | 0 | 0 | 正常计算 |
| 正数 | 负数 | <0 | 1 | 1 | 0 | 正溢出 |
| 负数 | 负数 | =0 | 0 | 0 | 0 | 相等 |
| 非负数 | 非负数 | =0 | 0 | 0 | 0 | 相等 |
所以,通过表格的前两行可以看出,仅当SF ^ OF == 1时,a<b,所以setg的表达式转换成等价的c语言表达式就是!(a<b) && a!=b,也就是a>b。
set的目的操作数是一个低位单字节寄存器或一个字节的内存位置,同时会对高位也清零。比如对于64位结果,会得到一个8字节的0。
练习题3.13

- cmpl代表四字节数据,(setl)
l是在比较有符号数,所以int - cmpw代表双字节数据,
g是在比较有符号数,所以short - cmpb代表单字节数据,
b是在比较无符号数,所以unsigned char - cmpq代表八字节数据,这个指令不限定是否有符号,所以
long、unsigned long或者某种形式的指针
练习题3.14

- testq代表八字节,
g是在比较有符号数,所以long - testw代表二字节,
sete不区分符号,所以可能是short、unsigned short - testb代表一字节,
a是在比较无符号数,所以unsigned char - testl代表四字节,
setne不区分符号,所以int、unsigned int
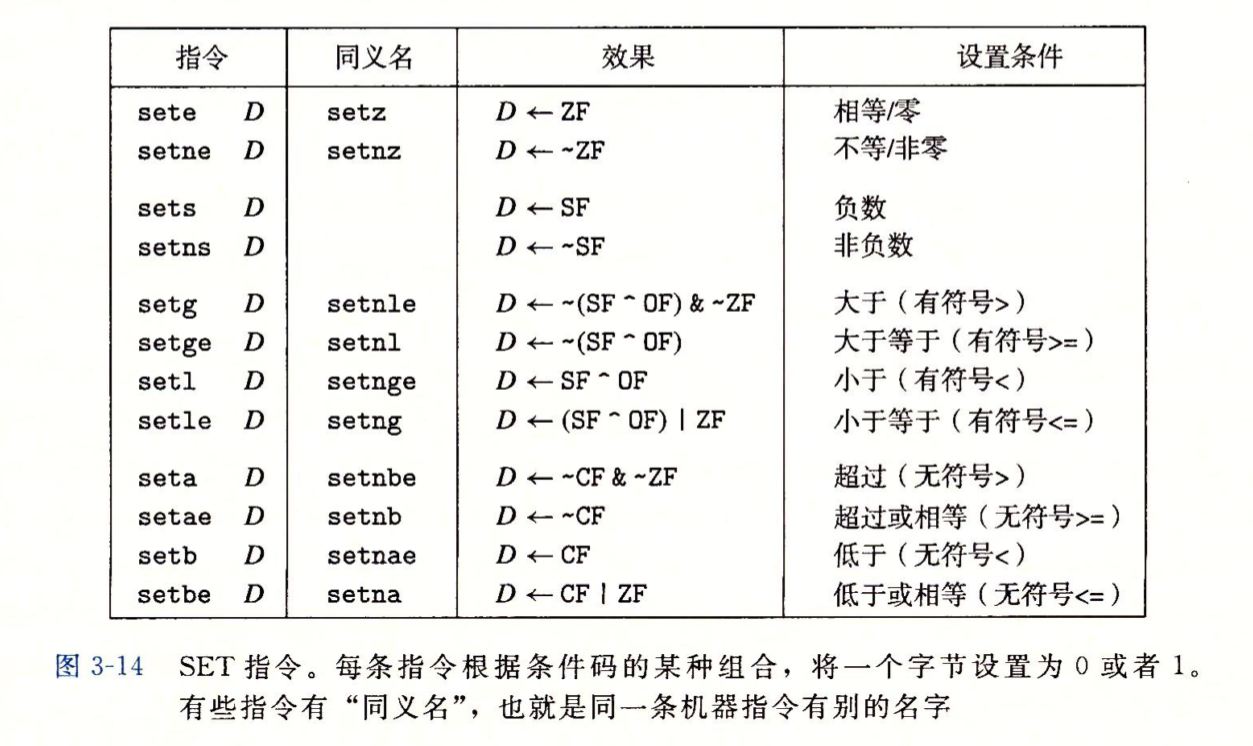
跳转指令

第二行的jmp指令会让程序跳过movq直接执行popq。跳转指令的参数是跳转目标,直接跳转是将目标直接作为指令的一部分编码,间接跳转是将跳转目标设置成一个寄存器或内存位置。间接跳转的写法是在参数前面加个*。
jmp *%rax 从寄存器中读取跳转目标
jmp *(%rax) 从内存中读取跳转目标
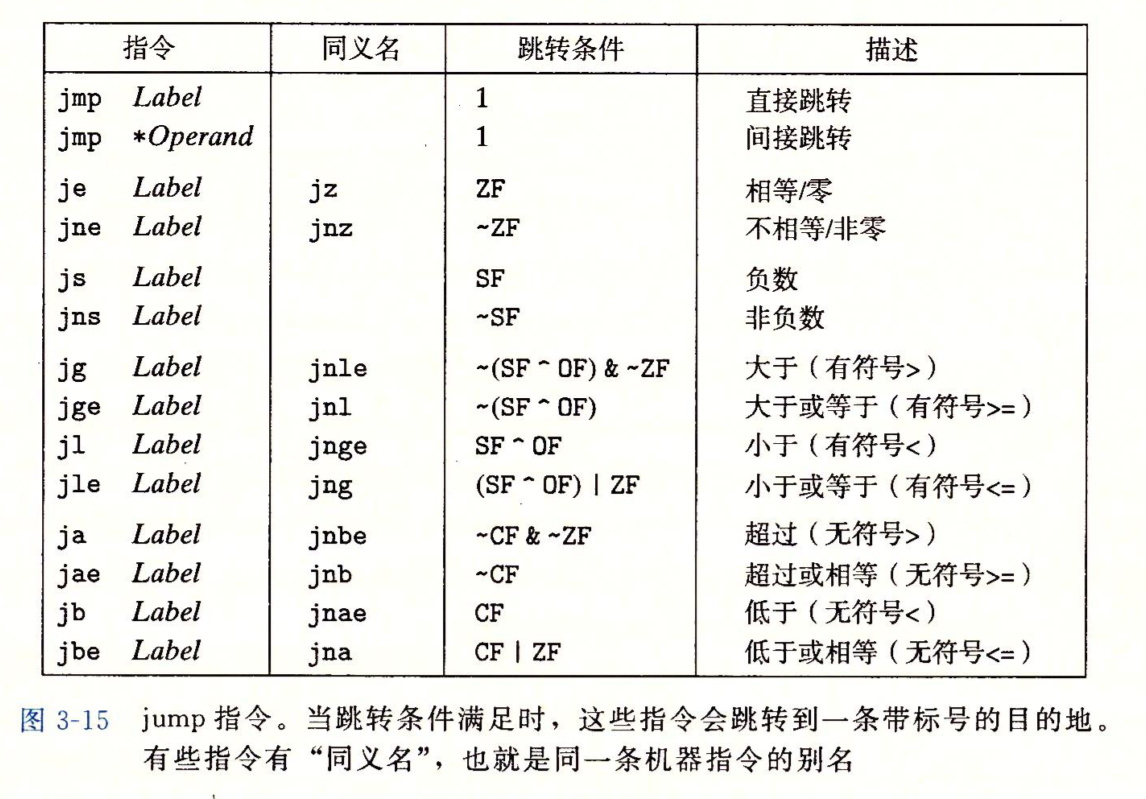
jmp是无条件跳转,剩下的都是有条件跳转,和set一样,它们也是根据条件码的某种组合来决定是跳转还是执行代码序列中的下一条指令。
跳转指令的编码
编码方式有PC相对方式和绝对方式,前者比较常见。
下面看一个PC相对方式的例子。第一处指令跳转到.L2,第二处的跳转指令跳转到.L3。

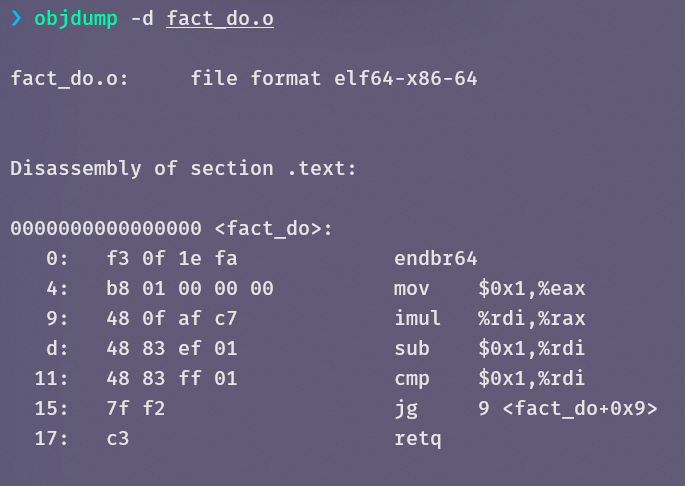
编译器产生的.o格式的反汇编版本如下:

jmp的参数是03,加上下一条指令(PC寄存器中的值)的地址0x5就是0x8,也就是说它最终会跳转到地址为8的指令上。
jg的参数是f8,十进制是-8,也就是在下一条指令地址的基础上减8,下一条指令是0xd,也就是0x5,跳转到地址为5的指令上。
下面是链接后的反汇编版本,可以看到,基于PC相对编码方式的跳转指令在链接时根本不用修改,即使所有指令的实际地址都发生了改变:

练习题3.15

- 4003fe
- 400425
- 第二个指令地址:400545,第一个指令地址400543(因为je使用两个字节)
- 400560
条件分支
用条件控制来实现条件分支
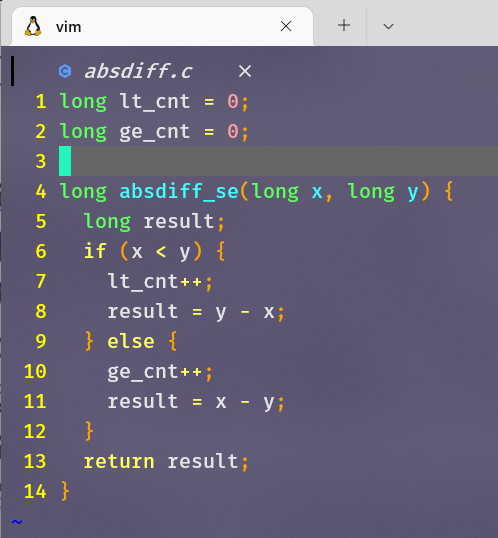
x in %rdi, y in %rsi
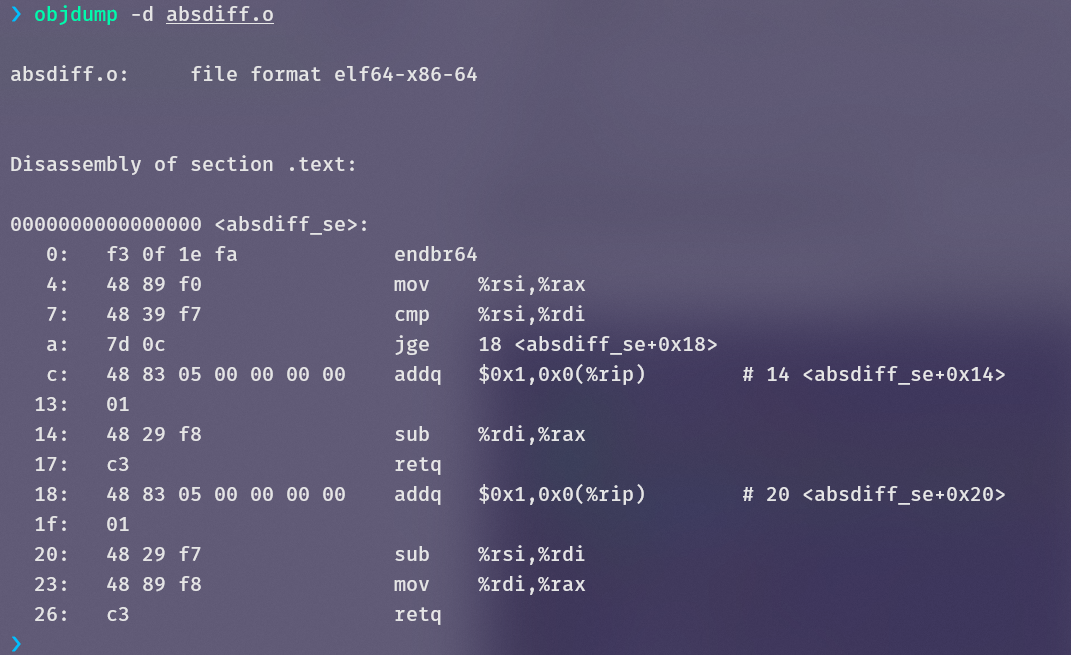
对于if-else这种分支,编译器通常会编译成这样的形式(用c语言中的goto语句描述):
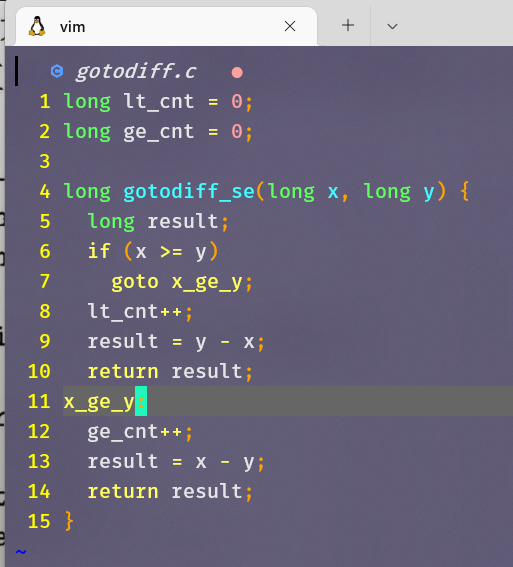
练习题3.16

- goto版本代码
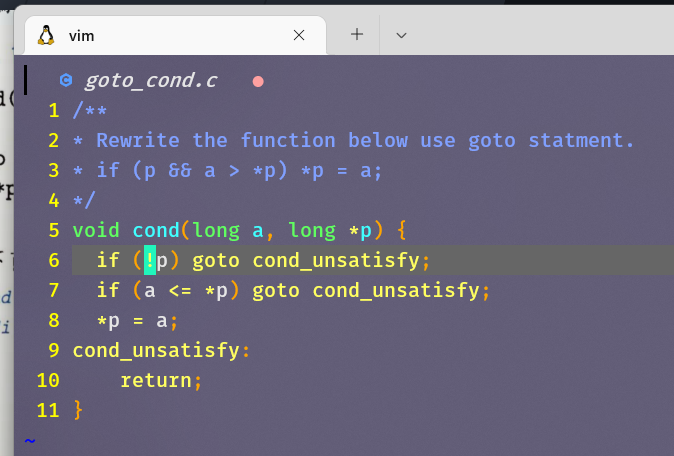
- 对于&&前面的条件
p,如果测试失败,会跳过&&后面的测试,直接返回。
用条件传送来实现条件分支
前面的条件分支实现是通过测试条件表达式结果,根据结果完成相应的跳转,这种实现方式称作条件控制。在现在的基于流水线作业的CPU上,一次可能只执行一个指令的一小部分,然后连续的指令之间可能有重叠,比如在执行一条指令中的内存读取时执行它上面一条指令的算术运算。
流水线作业要保证最终执行的效果和顺序执行是一致的,所以它必须要知道完整的指令执行序列才能使用,而在分支中,必须要等待条件表达式运算完成才能决定应该走向哪边。现代处理器中具有分支预测逻辑,它可以在遇到分支时猜测要执行哪边的代码,如果它预测正确,流水线就可以保持忙碌,如果它预测错误,虽然流水线也忙碌着了,但是处理器必须放弃它之前做的所有操作,重新去执行另一条分支,这会消耗大量时钟周期。然而,在足够随机的分支选择中,最佳的分支预测准确率也就是50%。
条件传送是指先计算出两个分支中的结果,然后计算条件,根据条件选择一个正确的分支,这在分支中任务不是很大的情况下能够让流水线比条件控制模式下更好更高效的工作。下面图b是图a利用条件传送编译代码的C语言表示,图c是实际的汇编表示,cmovge是条件传送指令,意为比较并移动。

x86-64下的条件传送指令
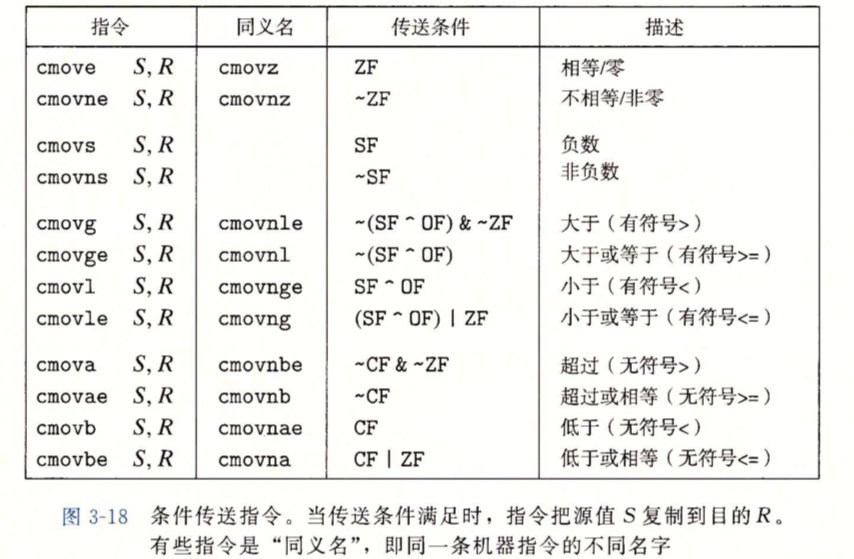
只有当两个表达式都非常容易计算时,如仅仅是一条加法指令,才会使用条件传送。即使分支预测错误的开销会超过多个分支中的计算。
循环
do-while循环
do-while循环会被编译成下面的样子
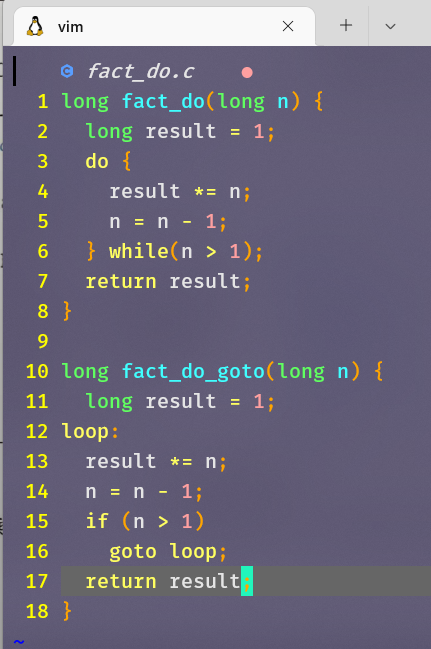
下面是它的汇编代码,也是一样的形式:
while循环
while循环需要先判断条件,如果条件不满足,循环甚至不能开启,下面是一种将它们转换成汇编代码的方式,即先跳转到测试块中,如果测试块中条件满足就走到实际的loop块中。这种翻译方式叫跳转到中间。

练习题3.24


- 1
- a < b
- result * (a + b)
- a + 1
第二种翻译方式有点耍机灵,因为while和do-while除了前者会先行判断一次后再无任何差别,所以第二种翻译方式提前判断了一下条件,如果不满足直接跳转到结束,然后剩下的部分就用一个do-while来代替。这种翻译方式称为guarded-do。


练习题3.25

- b
- b > 0
- result * a
- b - a
习题3.26

- 使用跳转到中间的翻译方法
- 填写代码:
long val = 0; while (x != 0) { val = x ^ val; x = x >> 1; } return 0x1 & val; - 不知道,答案上说计算x的奇偶性,有奇数个1返回1,偶数个1返回0。
switch语句
switch可以使用两种方式翻译,第一种就是类似if else那种翻译方式,第二种就是使用跳转表数组。下图是将switch语句使用跳转表方式翻译到一种扩展的C语言中的例子,&&是指向对应位置的指针。

通过上面例子,可以看出跳转表并非使用所有情况,但当分支较多,且分支范围跨度较小时,使用跳转表能大大增加性能,因为跳转表无需进行分支测试,它执行的速度与分支数量无关。
嘶,想起我中专的时候写数据库作业的时候就曾经采用过类似跳转表这种优化手段来优化Visual Fox中长篇大论的
do case语句。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号