
最全的曲文检测整理
SummaryOnCurveTextDet_2018_12_26
方法和思路总结
-
从趋势和效果来看,应该基本确定:用instance-segmentation思路做
-
目前已用的框架来看:
- 检测:Faster RCNN、R-FCN
- 分割:Mask R-CNN、FPN、FCIS
-
目前在这个方面,探讨的比较多的两个instance-segmentation用在文字上的问题
- 多边形表示mask
- 多scale(FPN,低高层特征进行fusion)
- 黏连
-
我觉得比较好的可以参考的几个点
- 对gt做shrink
- attention
- PAN
- FCIS的PSROI也不错
-
常用需要拿来做实验对比的库
- CTW1500
- Total-Text
- ICDAR15
- ICDAR17-MLT
- MSRA-TD500
论文列表
-
Yuliang Liu_2017_Detecting Curve Text in the Wild_New Dataset and New Solution
- 方法名称:CTD+TLOC
-
Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes
- 方法名称:TextSnake
-
Yuchen Dai——【2017】Fused Text Segmentation Networks for Multi-Oriented Scene Text Detection
- 方法名称:FTSN
-
Jun Du——【ICPR2018】Sliding Line Point Regression for Shape Robust Scene Text Detection
- 方法名称:SLPR
-
XiangLi——【2018】Shape Robust Text Detection with Progressive Scale Expansion Network
- 方法名称:PSENet
-
Zhida Huang——【2018】Mask R-CNN with Pyramid Attention Network for Scene Text Detection
- 方法名称:Mask-PAN(自己取的名)
-
Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text Detection
- 方法名称:TextField
-
Enze Xie——【AAAI2019】Scene Text Detection with Supervised Pyramid Context Network
- 方法名称:SPCNET
-
Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network
- 方法名称:CENet
-
Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection
- 方法名称:MSR
方法详细描述
1. CTD+TLOC【![见之前博客]() 】
】
论文
Yuliang Liu_2017_Detecting Curve Text in the Wild_New Dataset and New Solution
亮点
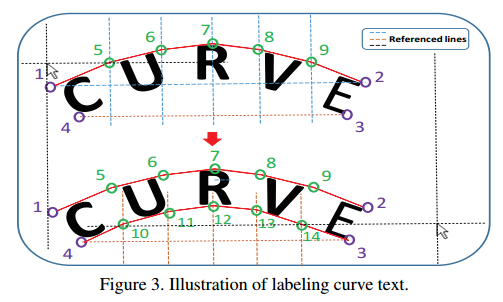
- 第一篇做曲文检测,还提出一个数据集CTW1500
- 使用14个点多边形来表示曲文
- 提出了一个结合CNN-RPN+RNN的检测方法专门做曲文检测
方法概述
针对曲文检测,基于RPN进行修改,除了学习text/non-text分类,多边形的bounding box回归(x1,y1,x2,y2),增加了14个点的回归,最后再进行后处理(去噪+nms)得到最终输出。

2. TextSnake【![见之前博客]() 】
】
论文
Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes
亮点
- 提出一个新的曲线文本表示方法TextSnake(由圆盘序列组成)
- 提出了一个新的曲文检测方法,并且精度比之前的高40%+(Total-Text数据集)
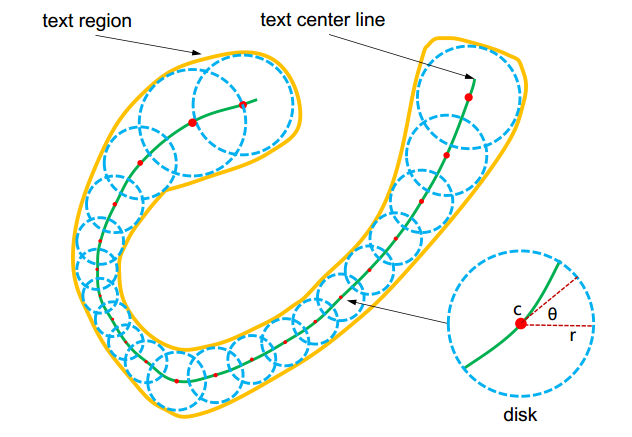
Fig. 2. Illustration of the proposed TextSnake representation. Text region (in yellow) is represented as a series of ordered disks (in blue), each of which is located at the center line (in green, a.k.a symmetric axis or skeleton) and associated with a radius r and an orientation θ. In contrast to conventional representations (e.g., axis-aligned rectangles, rotated rectangles and quadrangles), TextSnake is more flexible and general, since it can precisely describe text of different forms, regardless of shapes and lengths.
方法概述
针对曲文检测,提出一个新的曲线文本表示方法TextSnake——用一个有序的圆盘序列来表示文字,先用FCN检测文本区域、文本中心线、以及每个点的圆盘半径、方向,然后利用文本区域mask和中心线mask得到text instance segmentation。在每个text-instance上,交替进行点中心化和点扩展,得到文本中心点序列。最后结合圆盘半径,得到文本区域的TextSnake表示并进行union得到最终的文本区域。

3. FTSN
论文
Yuchen Dai——【2017】Fused Text Segmentation Networks for Multi-Oriented Scene Text Detection
亮点
- 比较早的一篇用FCIS做曲文检测的方法
- 提出Mask NMS
方法概述
针对曲文检测,采用instance-segmentation思路,基于FCIS框架,基本没特别改动,增加了一个Mask NMS。
检测流程是:使用FCIS得到instance-segmentation mask,然后再用Mask NMS,最后利用Mask得到多边形。

Fig. 2. The proposed framework consists of three parts: feature extraction, feature fusion along with region proposing and text instance prediction. The dashed line represents a convolution with 1x1 kernel size and 1024 output channels. The line in red is for upsampling operation and blue lines indicate on which feature maps PSROIPooling are performed using given ROIs.
Mask NMS实际上就是把IOU-overlap换成两个Mask的Intersection的像素点总数,分母的union area换成两个polygon的max_area。mask maximum-intersection (MMI) :
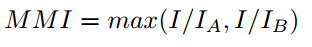
4. SLPR
论文
Jun Du——【ICPR2018】Sliding Line Point Regression for Shape Robust Scene Text Detection
亮点
- 基于检测框架进行修改,只需增加回归点的纵坐标或者纵坐标。是对于CTD+TLOC的简化和改进。
方法概述
针对曲文检测,采用object-detection思路,基于Faster R-CNN/R-FCN框架,增加了沿x/y轴均匀划线与多边形交点的纵/横坐标的回归(14个点,仅回归x或y坐标),最后把点串起来得到多边形。

PlusPS
总结了一波NMS的方法。
- locality-aware NMS
X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, and J. Liang, “East: An efficient and accurate scene text detector,” arXiv preprint arXiv:1704.03155, 2017.
- inclined NMS
Y. Jiang, X. Zhu, X. Wang, S. Yang, W. Li, H. Wang, P. Fu, and Z. Luo, “R2cnn: Rotational region cnn for orientation robust scene text detection,” arXiv preprint arXiv:1706.09579, 2017.
- Mask-NMS
Y. Dai, Z. Huang, Y. Gao, and K. Chen, “Fused text segmentation networks for multi-oriented scene text detection,” arXiv preprint arXiv:1709.03272, 2017.
- polygonal NMS(PNMS)
L. Yuliang, J. Lianwen, Z. Shuaitao, and Z. Sheng, “Detecting curve text in the wild: New dataset and new solution,” arXiv preprint arXiv:1712.02170, 2017.
5. PSENet
论文
XiangLi——【2018】Shape Robust Text Detection with Progressive Scale Expansion Network
亮点
- 利用不同shrink的segmentation来解决text-instance的黏连问题,很有新意;
- 提出一个自己设计的多个score map逐步扩展算法
方法概述
针对曲文检测,采用instance-segmentation思路,基于FPN框架进行修改,将其用在曲线文在检测上。
文章提出了曲文检测的当前两大问题:
第一,目前已有的文字表示方法(正矩形,斜矩形,四边形)无法满足任意形状的文字检测;
解决思路: 用分割来做。
第二,已有的分割方法最大问题在于靠的近的text instance容易黏连。
解决思路:对文字区域(gt-dt)进行不同程度的shrink,然后逐步扩展。

Figure 1: The results of different methods, best viewed in color. (a) is the original image. (b) refers to the result of bounding box regression-based method, which displays disappointing detections as the red box covers nearly more than half of the context in the green box. (c) is the result of semantic segmentation, which mistakes the 3 text instances for 1 instance since their boundary pixels are partially connected. (d) is the result of our proposed PSENet, which successfully distinguishs and detects the 4 unique text instances.
整个检测方法的流程是:使用FPN网络得到多个shirink程度不一样的segmentation map,再把多个map进行逐步扩展得到最终的map。
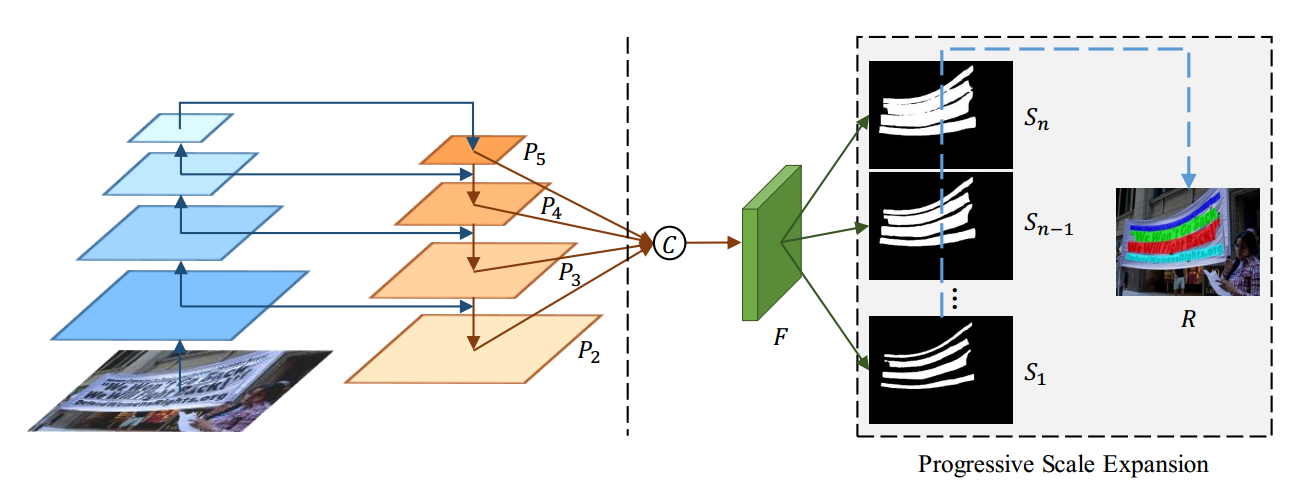
Figure 2: Illustration of our overall pipeline. The left part is implemented from FPN [16]. The right part denotes the feature fusion and the progressive scale expansion algorithm
PlusPS
这篇文章提供了两个比较有用的算法参考文献:
第一,Vatti clipping algorithm用于对多边形进行shrink:
Bala R Vatti. A generic solution to polygon clipping. Communications of the ACM, 1992.
第二,RamerDouglas-Peucker algorithm用于利用mask得到多边形:
Urs Ramer. An iterative procedure for the polygonal approximation of plane curves. CGIP, 1972.
6. Mask-PAN
论文
Zhida Huang——【2018】Mask R-CNN with Pyramid Attention Network for Scene Text Detection
亮点
- 基于Mask RCNN进行修改,可做四边形回归
- 首次将PAN用在文字检测上
方法概述
针对曲文检测,采用Instance-segmentation思路,基于MaskR-CN0N进行修改,将其用在曲线文本检测上。
改进的点在于两个:
第一, 在backbone网络中加入PAN(Pyramid Attention Network,由Feature Pyramid Attention和Global Attention Up-Sample两个部分组成),使得特征对scale大小鲁棒性更强
第二,将Mask-RCNN的regression分支由box回归(4个值)改为polygon回归(8个值),使其可以用做四边形回归(但还是不能用来做曲文的回归,曲文用的是mask的多边形框
第三,参照ION的思想,提出Skip-RoiAlign在多层进行融合
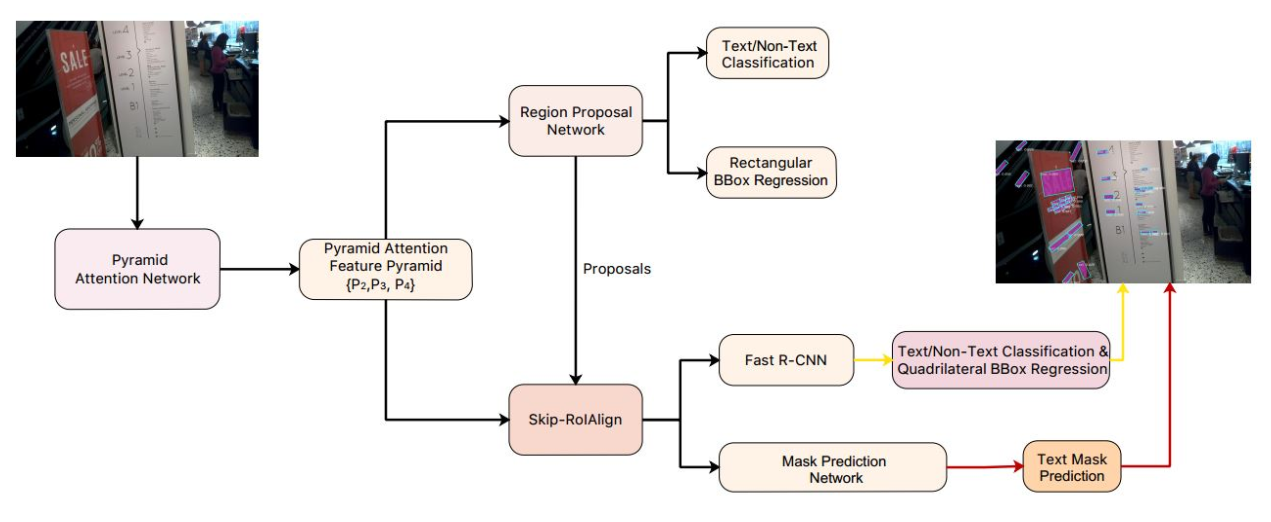
Figure 1: Architecture of our Mask R-CNN based text detector, which consists of a PAN backbone network, a region proposal network, a Fast R-CNN detector and a mask prediction network.
7. TextField
论文
Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text Detection
亮点
- 提出的TextField方法非常新颖,用点到最近boundary点的向量来区分不同instance
方法概述
针对曲文检测,采用Instance-segmentation思路,提出一种对于分割点的新的表示方法TextField,旨在解决text instance的黏连问题。
TextField是一个二维的向量v,用来表示分割score map上的每一个点,它的含义是:每个text像素点到离自己最近的boundary点的向量。它的属性包括:
- 非text像素点=(0, 0),text像素点 $\ne$ (0,0)
- 向量的magnitude,可以用来区分是文字/非文字像素点
- 向量的direction,可以用来进行后处理帮助形成文本块
具体检测流程是:用一个VGG+FPN网络学习TextField的两张score map图,然后这两张图上做关于超像素、合并、形态学等后处理来得到text instance。
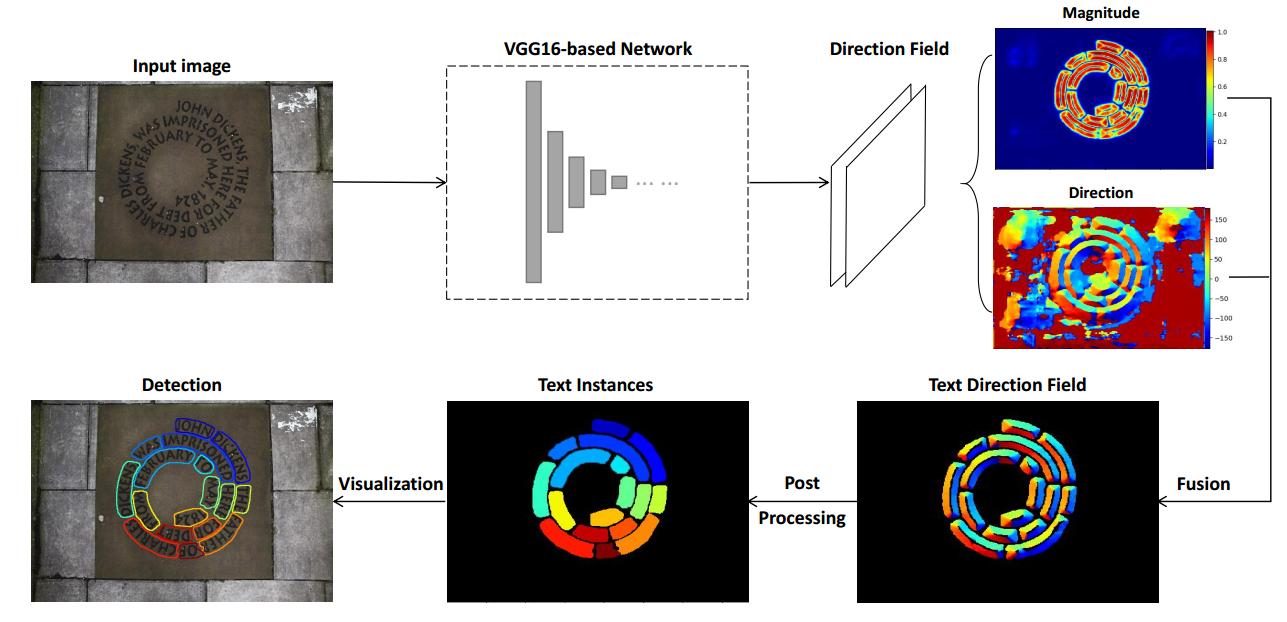
Fig. 3: Pipeline of the proposed method. Given an image, the network learns a novel direction field in terms of a two-channel map, which can be regarded as an image of two-dimensional vectors. To better show the predicted direction field, we calculate and visualize its magnitude and direction information. Text instances are then obtained based on these information via the proposed post-processing using some morphological tools.
8. SPCNET
论文
Enze Xie——【AAAI2019】Scene Text Detection with Supervised Pyramid Context Network
亮点
- 基于Mask R-CNN进行修改,加Attention机制,结合global信息
- 利用Mask的分数来进行Re-score
方法概述
针对曲文检测,采用Instance-segmentation思路,基于MaskR-CNN进行修改,将其用在曲线文本检测上。
文章的motivation认为:
已有的Mask R-CNN用在文字检测上有两个问题:
第一,每个ROI单独做box regression等,缺乏不同region间的context信息(例如,盘子经常出现在桌子上);
第二,Mask R-CNN的box针对水平文字,不利于倾斜文本,因为背景像素点占了很大比例(还有,比如用box后两行text的box会有较大覆盖)。
作者提出的解决办法是:
针对问题一,提出一个Text Context Module,加入SSTD的Attention机制并把global信息和local信息进行fusion;
针对问题二,提出一种Re-score Mechanism,利用Mask的score和box的score进行平均来解决倾斜文本的分类分数错误问题。
整个检测流程是:用Mask-RCNN+Attention网络进行inference,后处理用Mask的分数Re-socre,利用得到的mask来得到最后的检测结果(minAreaRect)。
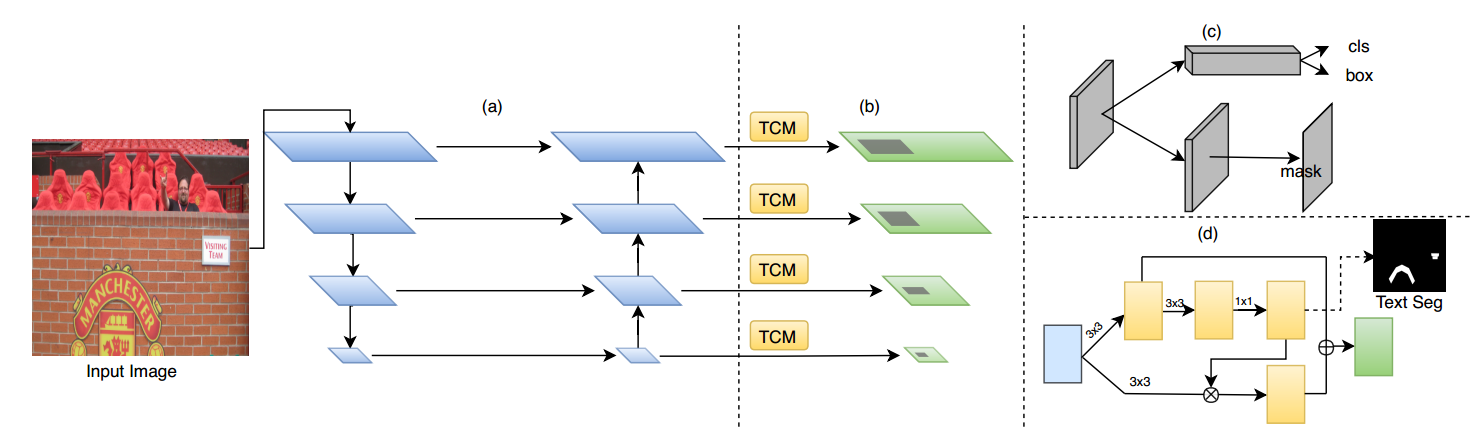
Figure 2: The architecture of our method. (a) The Feature Pyramid Network (FPN) architecture. (b) Pyramid Feature fusion via TCM. (c) Mask R-CNN branch for text classification, bounding box regression and instance segmentation. (d) The proposed Text-Context Module(TCM). Dotted line indicates the text semantic segmentation branch. The text segmentation map is upsampled to the input image size and calculates the loss with Ground Truth.
9. CENet
论文
Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network
亮点
- 通过将文字的字符合并问题转成字符embedding问题,利用一个网络来学习字符间的连接关系
方法概述
针对任意文字检测(水平、倾斜、曲文),采用从字符到文本行的自底向上的pipeline。先用一个网络CENet学习两个任务,包括单个字符的检测,以及一个字符对的embedding向量(表示两个字符是否可以构成一个pair)。然后再用一个字符分类阈值提取检测到的字符,和一个合并阈值提取group的字符对。最后利用WordSup中的文本线形成算法(图模型+一阶线性模型)得到文本行。
实际test时步骤:
- 运行CENet,得到字符候选集合+字符对候选集合
- 利用分数阈值s过滤非字符噪声
- 对每个字符运用r-KNN,查找local的character pairs(参数d、k)
- 使用piecewise linear model(分段线性拟合)来得到character group的最外接任意多边形
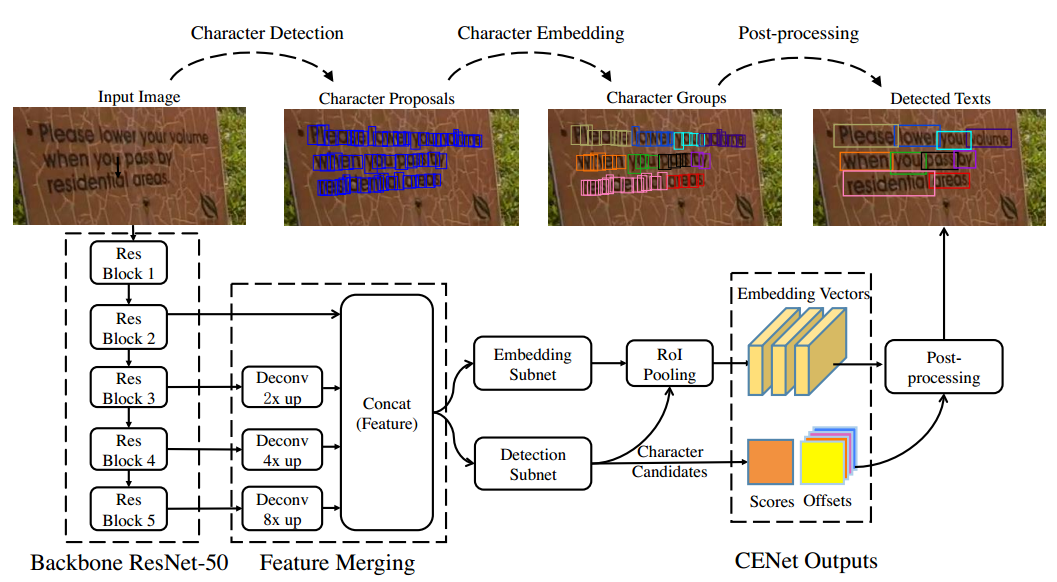
Fig. 2. Overall process of the model. Blue bounding boxes in \character proposals" are character candidates with high confidence scores. \Character Clusters" is the character clusters in embedding space, where candidates in the same cluster use the same color. The final detected words represented in quadrangles are shown in \Detected text". Better view in color.
10. MSR
论文
Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection
- multi-scale网络中利用FPN的up-sampling把多个不同scale得到的结果进行融合(concat + uppooling)
- boundary-point regression部分直接预测点与最近的boundary point的dx和dy,思路清晰且易实现
方法概述
针对任意文字检测(水平、倾斜、曲文),通过网络来regress文字的边界像素点来得到text region。
整个检测的流程包括:
- 特征提取:通过一个类似于Image Pyramid的多通道多尺度网络来提取不同scale的图像特征(FPN框架)
- 目标预测:预测包括三个分支
- text region的classification分支
- 与nearest boundary point之间的x的dis
- 与nearest boundary point之间的y的dis
- 结果输出:利用Alpha-Shape Algorithm从boundary point set中的得到外边界凸多边形
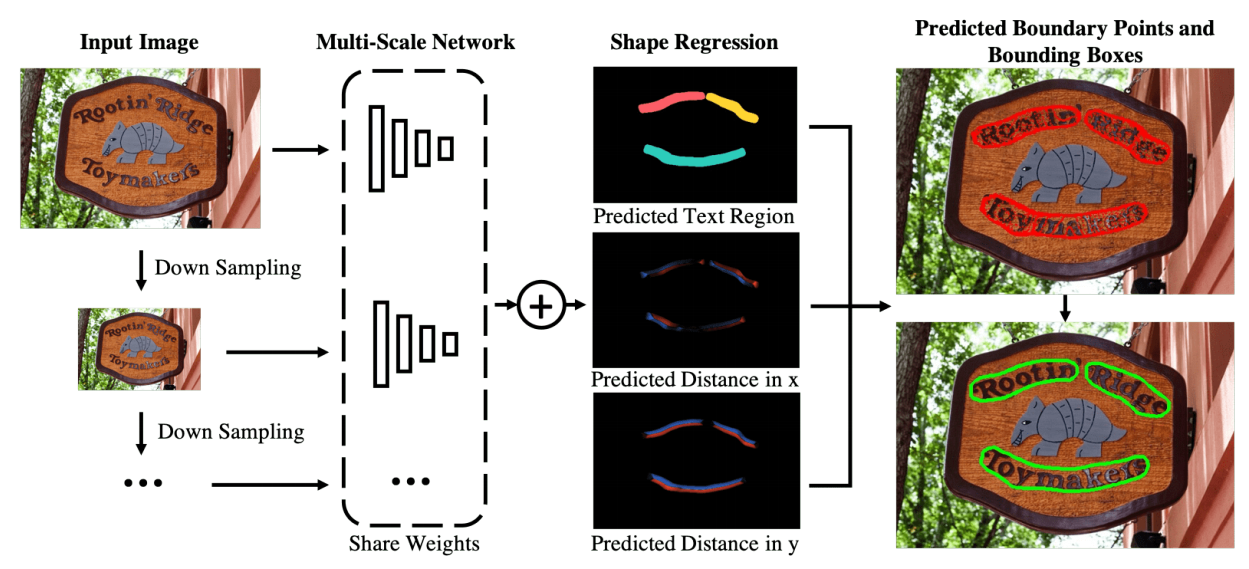
Fig. 1: Scene text detection using the proposed multi-scale shape regression network (MSR): For scene texts with arbitrary orientations and shapes in (a), MSR first predicts dense text boundary points (in red color) as shown in (b) and then locates texts by a polygon (in green color) that encloses all boundary points of each text instance as shown in (c).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号