软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 学习PSP 阅读《构建之法》 完成WordCount编程 |
| 作业正文 | 软工实践寒假作业(2/2) |
| 其他参考文献 | .gitignore配置语法 关于单元测试和回归测试 |
阅读《构建之法》并提问
1. 如何准确记录PSP?
在书中2.3中,看到PSP的一条特点是:PSP依赖于数据。而这些数据需要工程师自己记录和考察,因此我觉得会出现极大的不准确性。有看到的说法是要处理好中断时间,做好记录以及计划。但是,从这次的实践来说,估计一个自己还未着手的项目的时候,并不能很好地预估到底需要多少时间。并且,在执行的过程中,很少会去关注时间,并且期间很多时候,中断的时间也难以记录和估计。并且特地关注时间感觉反而降低了效率。因此,关于记录PSP这方面的具体操作不是很明白。
2. 如果团队中的队员能力差距较大该怎么办?
在书中3.1中,关于团队对于个人的期望方面中提到要全力以赴投入团队之中。但是,在现有的团队合作中,每个人之间的能力都有着区别。很多时候,并不是不想参与,而是因为队员间的能力差距有些大而导致的沟通上产生巨大的问题。在关于课业的团队合作中,有的人可能会因为能力差距大而产生只要能过就好、反正也办不上什么忙以及自己什么都不会的心思游离于团队之外。这种情况应该怎么解决?是平均一下团队中的能力,从简做起;还是说,从一开始就不应该成为一个团队。
3. 如果不是长期合作的话,结对编程效率会高吗?
在书中4.5.4中,在结对编程过程中,双方需要互相磨合和学习。这样看来,想要使得结对编程的效率比单人高需要投入一定的时间成本。而且,结对编程过程中,肯定会出现意见不合的时候。这些讨论问题的时间也大大降低了效率。并且,如果跟水平比自己高的大佬一起结对编程的话,对于己方来说,能够更快地跟上进度。但是,很有可能导致无法很好的胜任领航员的角色。从这方面考虑的话,是不是就无法达到结对编程的目的了。
4. 美工没设计好页面的话,前端的工作能先开始吗?
在书中12.2中,写到程序员不应该等着设计师的线稿图才开始工作。但是,如果没有相应的页面的话,前端的页面该怎么设计。就是说,在只知道需求的情况下,并没有一个完整的页面结构,前端应该如何开展工作?还是说,前端先根据需求进行相关的工作,最后再根据美工的图进行修改。但是这样的话,如果双方设想的页面差距过大,是不是相当于前端之前开展的工作都得推翻掉?
5. 先行者会有优势吗?
在书中16.1.4中,关于创新不是一马当先的。从其中的例子可以看出最后的领导者往往都不是先行者。那些后起者可以借助先行者的经验,站在前者的肩膀上更进一步。那这样子的话,相比于自己去想到一些好点子,不如跟着市场的脚步,在原有的基础上开拓一些新东西。而且,对于大规模的创新来说,并不是很多人都能接受的。就像16.1.2中说的一样,当你提出一个新点子的时候,反对的声音可能远远大于支持的。在这种情况下,先行者是不是意味着吃亏呢?
冷知识和故事
在某个夏天,美国海军中尉哈珀正领着他的一个小组构造名为“马克二型”的计算机。由于没有空调,所有的窗户都敞开散热。而当时,“马克二型”还不是完全的电子计算机,是使用了大量的继电器。突然,“马克二型”死机了。技术人员做了很多努力,终于将问题锁定在第70号继电器。哈珀观察这个出了问题的继电器,发现一直飞蛾躺在中间,已经被继电器打死。他将飞蛾夹出来,用透明胶布贴到记录本中,并注明“First actual case of bug being found”
bug的来历
WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| • Estimate | • 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 660 | 480 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 60 |
| • Design Spec | • 生成设计文档 | 60 | 30 |
| • Design Review | • 设计复审 | 30 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 180 | 150 |
| • Code Review | • 代码复审 | 60 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 90 |
| Reporting | 报告 | 150 | 65 |
| • Test Report | • 测试报告 | 60 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 870 | 605 |
解题思路描述
- 首先是要解决文件输入输出的问题。这方面之前已经学习相关方法,去百度其他方法并发现了语法糖。
- 读取了文件中的内容,要根据相关要求进行处理统计。
- 统计字符数,只需要统计ASCII码的数量。在假设会出现中文的情况下,判断每一个是否为ASCII码并进行计数。由于后期知道不会出现中文,改为直接计算字符串的长度。
- 统计单词数,根据正则表达式,先通过分隔符获取到疑似单词的列表;再通过正则表达式对单词的判定,将符合条件的单词放入字典中,并进行计数。
- 统计有效行数,通过
python自带的函数判断是否为空行。如果返回为非,则进行计数。 - 统计最多的10个单词及其词频,前面已经将全部的单词放入字典中。通过对字典进行排序并切片,最终剩下前十的单词及其词频。
- 将得到的数据写入文件中。
- 单独将相关功能独立成为单独的模块,并对代码进行相应的修改和增加异常处理。
- 通过参考文献,进行单元测试和性能测试。
代码规范制定链接
https://github.com/lilith0120/PersonalProject-C/blob/main/111801429/codestyle.md
设计与实现过程
将统计字符数、统计单词数以及统计最多的10个单词及其词频的函数单独写入一个文件。之后想要调用相关函数,可以通过导入该模块或是单独导入该模块中的某个方法进行调用。
- 统计每行字符数,将字符串传入该函数,并返回得到的结果:
# 统计字符数
def count_character(line):
# character_num = len([i for i in list(line) if ord(i) <= 127])
character_num = len(line)
return character_num
- 统计单词数,将字符串以及存放单词的字典传入该函数,修改字典并返回单词数:
# 统计每行单词数
def count_word(line, count):
words = 0
word = re.split(r'[^a-z0-9]+', line)
pattern = re.compile(r'[a-z]{4}[a-z0-9]*')
for w in word:
if re.match(pattern, w):
words += 1
if w in count:
count[w] += 1
else:
count[w] = 1
return words
- 统计最多的10个单词及其词频,将字典传入该函数,并返回前十结果:
# 统计最多的10个单词及其词频
def count_most(count):
ans = sorted(count.items(), key=lambda x: (-x[1], x[0]))
result = {k: v for k, v in ans[:10]}
return result
- 在主程序中通过
from Lib import *导入该模块。 - 在读取输入文件的时候,通过语法糖的迭代器,先将每一行的大写字符都转化为小写,再进行相关的处理:
with open(input_file, encoding='utf-8', newline='') as f:
for line in f:
line = line.lower()
# 统计每行字符数
characters += count_character(line)
# 统计非空白行数
if not line.isspace():
lines += 1
# 统计每行单词数
words += count_word(line, count)
- 最后根据要求的格式将内容写入输出文件:
with open(output_file, 'w', encoding='utf-8', newline='') as f:
f.write("characters: {0}\n".format(characters))
f.write("words: {0}\n".format(words))
f.write("lines: {0}\n".format(lines))
# 输出最多的10个单词及其词频
result = count_most(count)
for k, v in result.items():
f.write("{0}: {1}\n".format(k, v))
性能改进
通过
python的读取文件的语法糖:
with open(<FILE>) as f:
for lines in f:
# do some thing with the line...
该方法在文件操作结束之后,会自动关闭文件。并且带有迭代器,采用缓存
IO以及内存管理。
下图为测试了100W个字符的速度以及输出结果:

characters: 1000000
words: 27832
lines: 19763
bwyj: 3
otcs: 3
oxpp: 3
ahaw: 2
augt: 2
avsf: 2
azhu: 2
bdlb: 2
cfaz: 2
copk: 2
单元测试
本次单元测试用到了
python中的unittest框架进行测试。因为将相关功能写成单独的模块,就只针对该模块进行单元测试。
- 测试字符数的正确性,其中生成的输入文件由随机的ASCII码组成:
# 测试统计字符数
class TestCharacter(TestCase):
def test_character(self):
x = string.printable
with open('input.txt', 'w', encoding='utf-8', newline='') as f:
for i in range(100):
line = ""
for j in range(100):
line += random.choice(x)
f.write(line)
result = 0
with open("input.txt", encoding='utf-8', newline='') as f:
for l in f:
l = l.lower()
result += count_character(l)
self.assertEqual(result, 10000)
- 测试统计单词数的正确性,其中的输入文件由字母、数字以及分隔字符组成:
# 测试统计单词数
class TestWord(TestCase):
def test_word(self):
with open('input.txt', 'w', encoding='utf-8', newline='') as f:
for i in range(100):
line = ""
n = random.randint(1, 10)
m = random.randint(1, 10)
line += "".join(random.sample(string.ascii_letters, 4))
line += "".join(random.sample(string.ascii_letters +
string.digits, n))
for j in range(m):
line += random.choice('!@#$%^&*()')
line += "".join(random.sample(string.ascii_letters, 4))
line += "".join(random.sample(string.ascii_letters +
string.digits, n))
f.write(line + '\n')
result = 0
with open("input.txt", encoding='utf-8', newline='') as f:
for l in f:
l = l.lower()
result += count_word(l, {})
self.assertEqual(result, 200)
- 测试统计最多的10个单词及其词频的正确性,其中设置随机的十个合法单词以及出现次数:
# 测试统计最多的10个单词及其词频
class TestMost(TestCase):
def test_most(self):
count = {}
for i in range(10):
line = ""
n = random.randint(1, 10)
m = random.randint(1, 100)
line += "".join(random.sample(string.ascii_letters, 4))
line += "".join(random.sample(string.ascii_letters +
string.digits, n))
count[line] = m
ans = dict(sorted(count.items(), key=lambda x: (-x[1], x[0])))
result = count_most(count)
self.assertEqual(result, ans)
测试覆盖率截图:
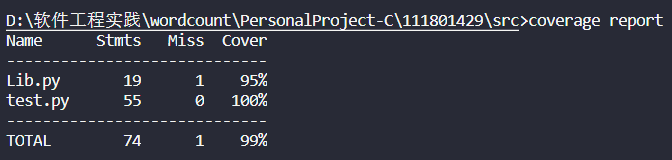
啊,我觉得如果模块中的方法的粒度减小,能减小编写单元测试的难度以及增加其覆盖率
异常处理说明
由于相关模块已经进行了单元测试,因此只对命令行的相关输入进行异常处理。
- 对于命令行中没有出现输入或者输出文件:
python WordCount.py
except IndexError:
print("未指明输入/输出文件")
- 对于找不到输入文件:
except FileNotFoundError:
print("找不到输入文件{0}".format(input_file))
- 因为其他原因的异常:
except:
info = sys.exc_info()
print(info[1])
心路历程与收获
心路历程:
最开始看到这个作业的时候,感觉整体的一个流程好像不是太难。但是真正上手的时候,才发现完成需求后面的模块才是真的重头戏。也是因此,接触到了单元测试。最开始进行单元测试的时候感觉是一件很复杂很厉害的事情,后来操作起来好像也不会是个大山。但是,要达到覆盖率高的问题,就是一件很头疼的事情,想到可能是前期的功能没有划分好。
收获:
学习如何用python进行单元测试和性能分析
首次尝试手打.gitignore
学习python读取文件的多种方式
巩固了正则表达式
学习python关于字典的排序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号