
对硬盘进行"SMART"和"BadBlocks"检测
Smartctl-硬盘监控和分析工具
1,安装Smartctl
对于Ubuntu $ sudo apt-get install smartmontools
对于CentOS和RHEL # yum -y install smartmontools
2,常用的磁盘检测命令:(“X”使用硬盘盘符替换)
| 命令 | 目的 |
| smartctl -A /dev/X | 查看硬盘的详细信息 |
| smartctl -s on /dev/X | 打开SMART特性支持 |
|
smartctl -s on /dev/X -S VALUE, --saveauto=VALUE (ATA) Enable/disable Attribute autosave on device (on/off) |
打开SMART属性自动保存功能 |
| smartctl -t short /dev/X | 快速检测硬盘 |
| smartctl -t long /dev/X | 详细检测硬盘 |
| smartctl -X /dev/X | 中断后台检测硬盘 |
| smartctl -l selftest /dev | 显示硬盘检测日志 |
| smartctl -l error /dev/X | 显示硬盘错误汇总 |
| smartctl -H /dev/X | 磁盘健康状态检查 |
3,测试前需要先卸载所有挂载点
例如:
# df -h
/dev/sde 551G 299G 224G 58% /data/disk01
/dev/sdf 551G 296G 227G 57% /data/disk02
卸载磁盘
# umount dev/sde
# umount dev/sdf
4,自检测试命令:
smartctl -t short /dev/X
对硬盘进行短时快速自检,short测试中最多用时两分钟。
smartctl -t long /dev/X
对硬盘进行长时间自检,long测试中没有时间限制,因为它会读取并验证磁盘的每个段。
例如:
# smartctl -t long /dev/sde
# smartctl -t long /dev/sdf
生成硬盘的详细信息log:smartctl -a /dev/X > smart-all-X-Y .log
(“X”使用硬盘盘符替换,“Y”用设备IP代替,生成的[smart-all-X-Y.log]文件需收集保存)
smartctl -a /dev/sde > smart-all-sde-2022-11-15.log
smartctl -a /dev/sdf > smart-all-sdf-2022-11-15.log
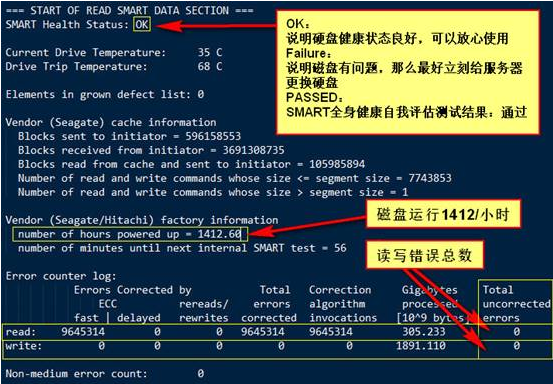
5,分析log:【SAS盘显示结果,其它种类磁盘输出结果可能会有不同】
# vim smart-all-sde-192.172.12.154.log
6,总结
我们还可以通过smartctl -l background [device]
来检查smartctl在后台对潜在坏道的维护,
如果检查到 Recovered via rewrite in-place,表示发生了一次潜在的坏块,硬盘已经自动重定向了一个好块代替它,这种情况越多,表明硬盘的速度就会下降。
如库存的硬盘,做smartctl工具的检测。
具体作法应是:
先启动smartctl -t long [device],
然后进行一次50G的文件写入以及读检测
然后用smartctl -x [device]检查相关的信息。
重点关注:uptime 读出量,写入量(确定硬盘是否是新的)
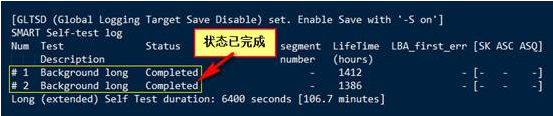
Background long 状态是不是 Completed,如果不能completed肯定是有严重问题。
关注ecc 纠正率,确认盘是较好质量的。
badblocks 检测
Linux badblocks命令用于检查磁盘装置中损坏的区,执行指令时须指定所要检查的磁盘装置,及此装置的磁盘区块数。
1,语法:
badblocks [-svw][-b <区块大小>][-o <输出文件>][磁盘装置][磁盘区块数][启始区块]
2,参数说明:
-b<区块大小> 指定磁盘的区块大小,单位为字节。
-o<输出文件> 将检查的结果写入指定的输出文件。
-s 在检查时显示进度。
-v 执行时显示详细的信息。
-w 在检查时,执行写入测试。
[磁盘装置] 指定要检查的磁盘装置。
[磁盘区块数] 指定磁盘装置的区块总数。
[启始区块] 指定要从哪个区块开始检查。
3,测试命令:
badblocks -s -v /dev/sdb -o bdblocks-sdb &
badblocks -s -v /dev/X -o bdblocks-X-Y &
“X”使用硬盘盘符替换,“Y”用设备IP代替
"&"后台运行,目的同时对所有磁盘执行检查
4,实例:
目的:同时对磁盘/dev/sde与/dev/sdf进行检测并写入检测结果到指定文件
# badblocks -s -v /dev/sde -o bdblocks-sde-192.172.12.154.log &
# badblocks -s -v /dev/sdf -o bdblocks-sdf-192.172.12.154.log &
~~~~~~~~~~~~~~
[1] 50498
[root@localhost]# 正在检查从 0 到 1953514583的块
Checking for bad blocks (read-only test): 0.18% done, 0:23 elapsed. (0/0/0 errors)
[root@localhost]# 0.19% done, 0:24 elapsed. (0/0/0 errors)
[root@localhost]# 0.20% done, 0:25 elapsed. (0/0/0 errors)
[root@localhost]#
~~~~~~~~~~~~~~
注:0.20% done 显示检查百分比,0:25 elapsed显示用时/秒
如磁盘坏块较多,用时将相应延长
5,检查输出结果
# ls -lh 查看输出文件大小,发现sde盘的输出log有22k大小,而其他盘大小为0,说明sde盘上有坏道

使用“vi”打开sde磁盘log,按G到文件末端会发现共有2191行,而每一行代表磁盘的一个坏道,也就是说磁盘sde上有2191个坏道。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号