
文本处理三剑客 grep、sed、awk
grep
以文本的 ”行“ 为单元把所需要的文本筛选出来(主要用于查找)
形式一:grep [ option ] [ pattern ] [file1, file2,...]
形式二:some command | grep [ option ] [ pattern ]
选项 含义
-i 忽略大小写
-c 只输出匹配行的数量
-n 显示行号
-r 递归搜索
-E 支持拓展正则表达式
-w 匹配整个单词
-l 只列出匹配的文件名
-F 不支持正则,按字符串字面意思进行匹配
根据字符串、变量名过滤文档

过滤的错误信息存到/dev/null目录下,使用“ >> ”保存到一个回收文件夹“/dev/null”,该文件夹只保留正常运行的,若需要保存错误和正常的使用 “ &> ” 符合

sed
流编辑器,对文件逐行进行处理
方式一:sed [ option ] "pattern command" file
方式二:some command | sed [ option ] "pattern command"
选项 含义
-n 只打印模式匹配的行
-f 加载存放动作的文件
-r 支持拓展正则
-i 直接修改文件
pattern模式
匹配模式 含义
5 只处理第5行
5,10 只处理第5到第10行
/pattern1/ 只处理能匹配pattern1的行
/pattern1/, /pattern2/ 只处理从匹配pattern1的行到匹配pattern2的行
command命令
查询:p,打印
新增:
a,在匹配行后新增
i,在匹配行前新增
r,外部文件读入,行后新增
w,匹配行写入外部文件
删除:d
修改:s
s / old / new / :只修改匹配行中的第一行
s / old / new / g :修改匹配行中所有的old
s / old / new / ig :忽略大小写
a,在匹配行后新增内容
![]()
r,外部文化读入,行后新增

w, 匹配后写入外部文件

修改

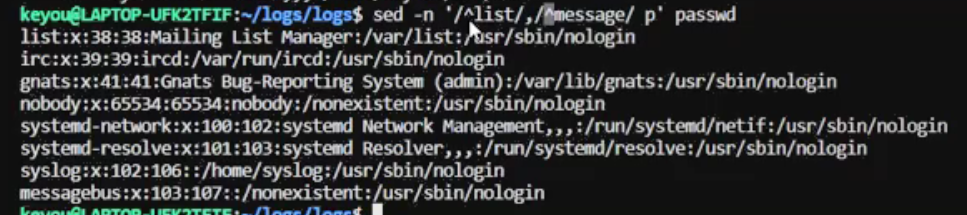
以list开头到以message开头的行
awk
文本处理工具,处理数据并生成结果报告(针对某一列字段的数据进行处理)
方式一:awk ‘ BEGIN{} pattern { commands }END{} ’ file
方式二:some command | grep [ option ] [ pattern ]
格式 含义
BEGIN{ } 处理数据之前执行
pattern 匹配模式
{ command } 处理的命令
END{ } 处理数据之后执行
内置变量 含义
$0 整行整列所有内容
$1-$n 当前行的第1-n个字段
NF(Number Field) 当前每行的字段数
NR(Number Row) 当前每行的行号,从1开始
FS(Field Separator) 输入字段分割符,默认为空格或tab键
RS(Row Separator) 输入行分割符,默认为回车符
OFS(Output Field Separator) 输出字段分割符,默认为空格
ORS(Output Row Separator) 输出行分割符,默认为回车符
printf 格式符
格式符 含义
%s 字符串
%d 十进制数字
%f 浮点数
修饰符 含义
+ 右对齐
- 左对齐
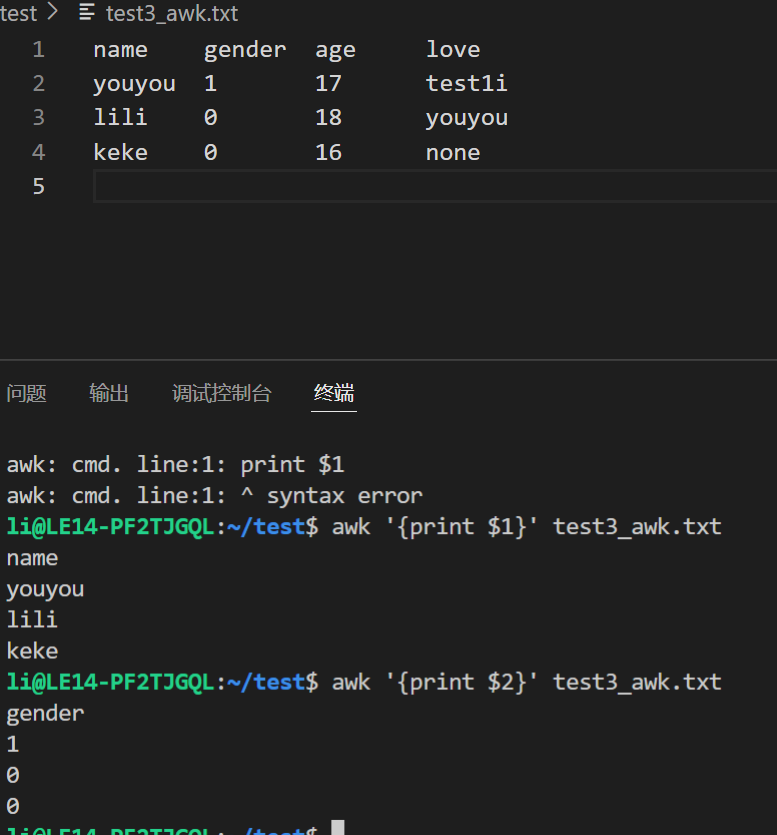
取文本中第一个字段的数据
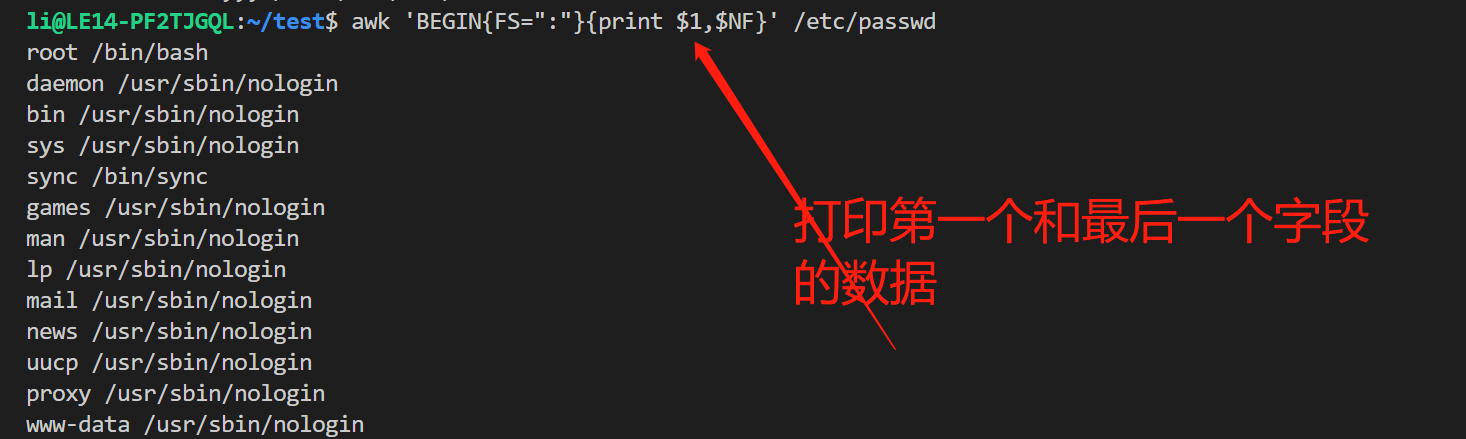
变量 $NF :取最后一个字段的数据;变量 $NF -1 :取倒数第二个字段的数据
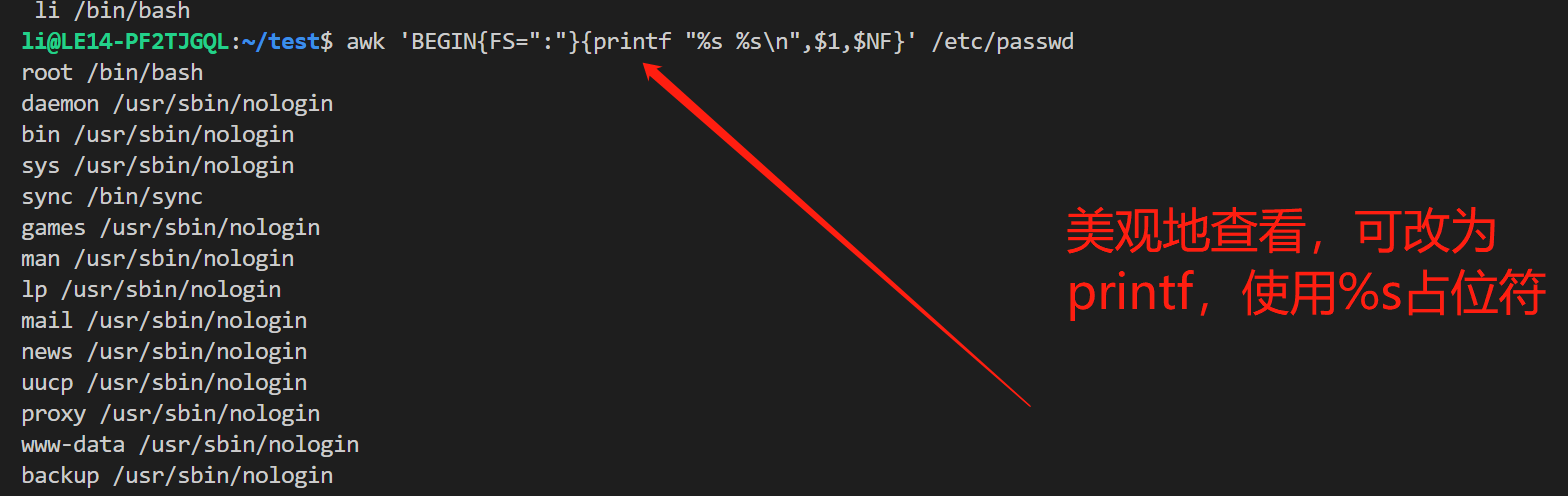
使用printf 格式化
使用正则,只取文件中含有某字母的数据,如:/mail/
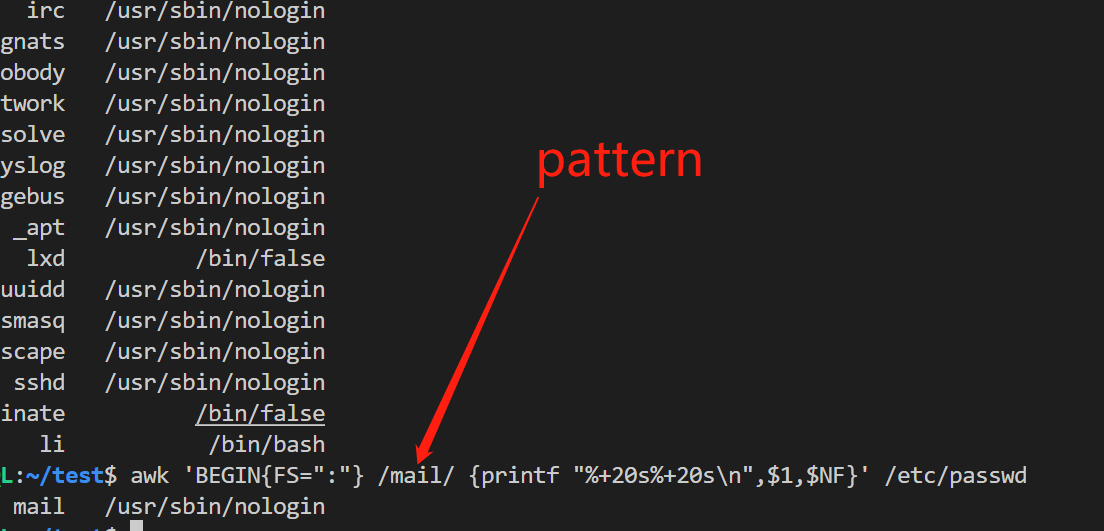
使用正则,查找从某行的数据开始到某行的数据结束

使用正则,查找大于100的某行某列的数据

使用正则,查找的结果总数有两种方式,方式一:wc -l ;方式二:END{ }

使用脚本执行 awk
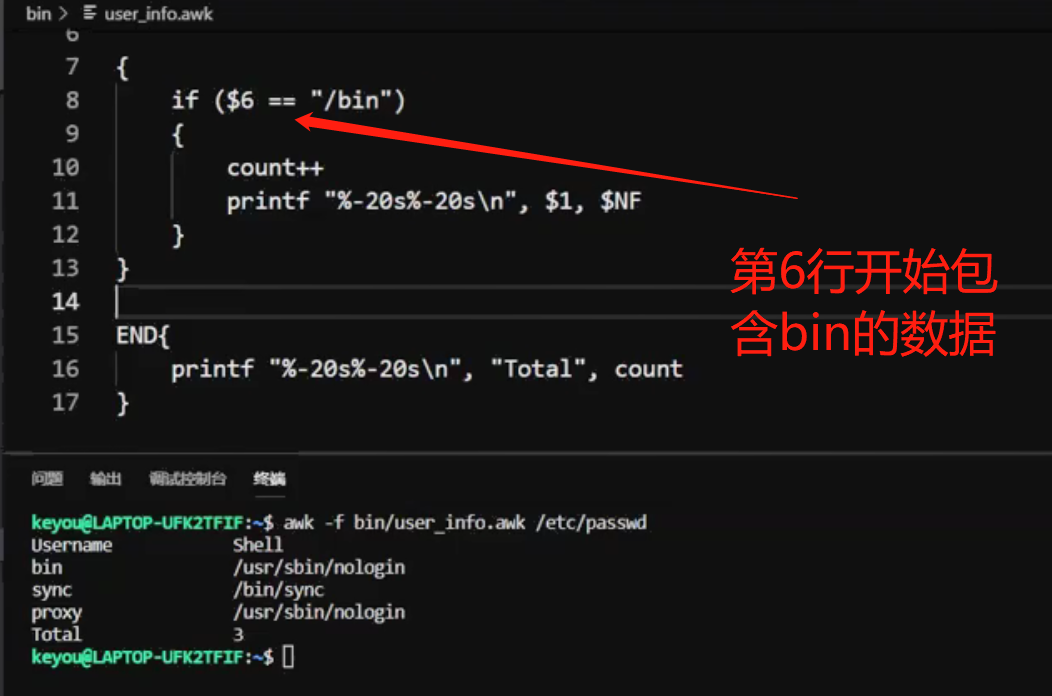
当awk的命令行太长时,可写在一个文件中运行
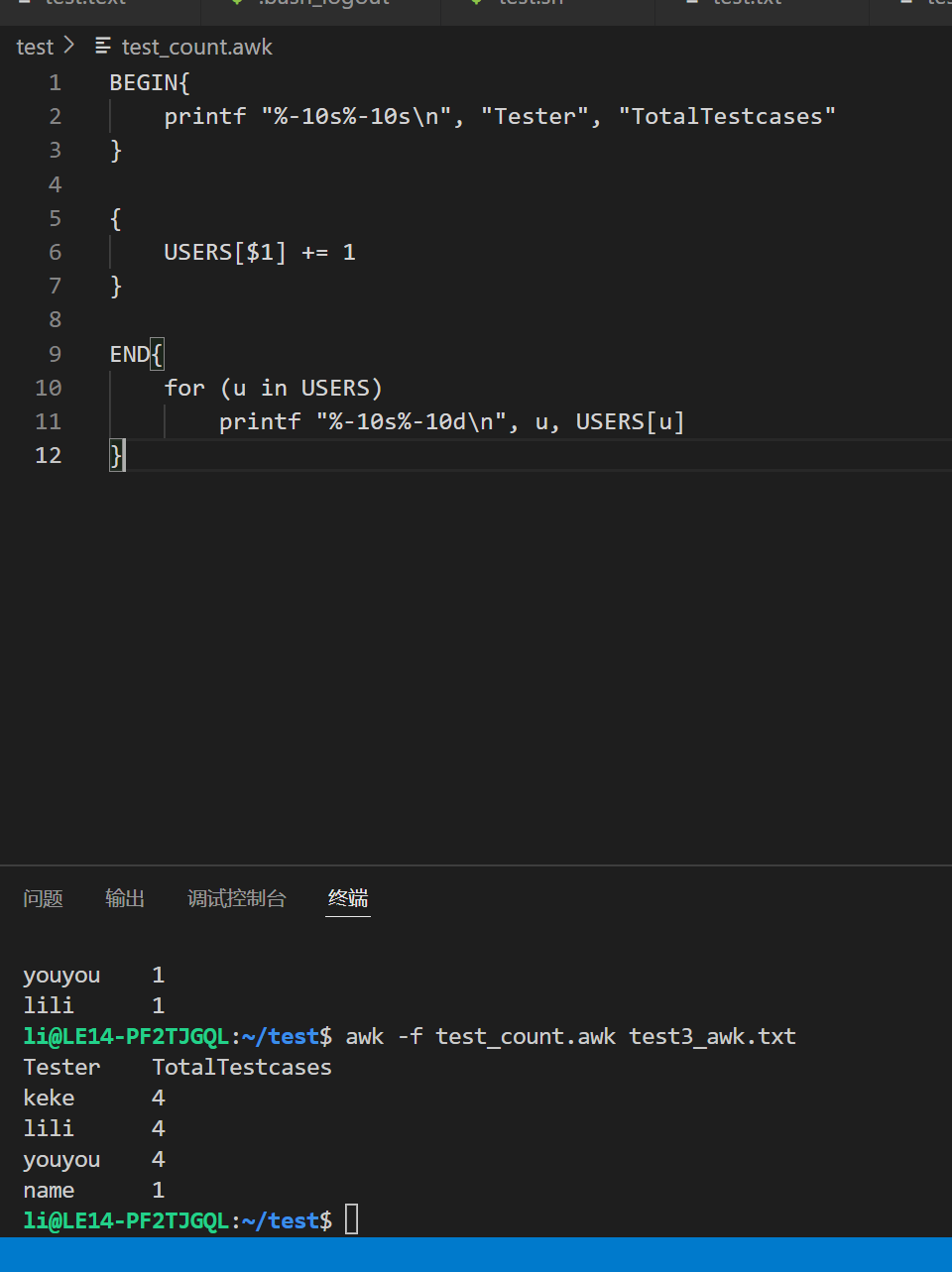
统计某个人做了某件事
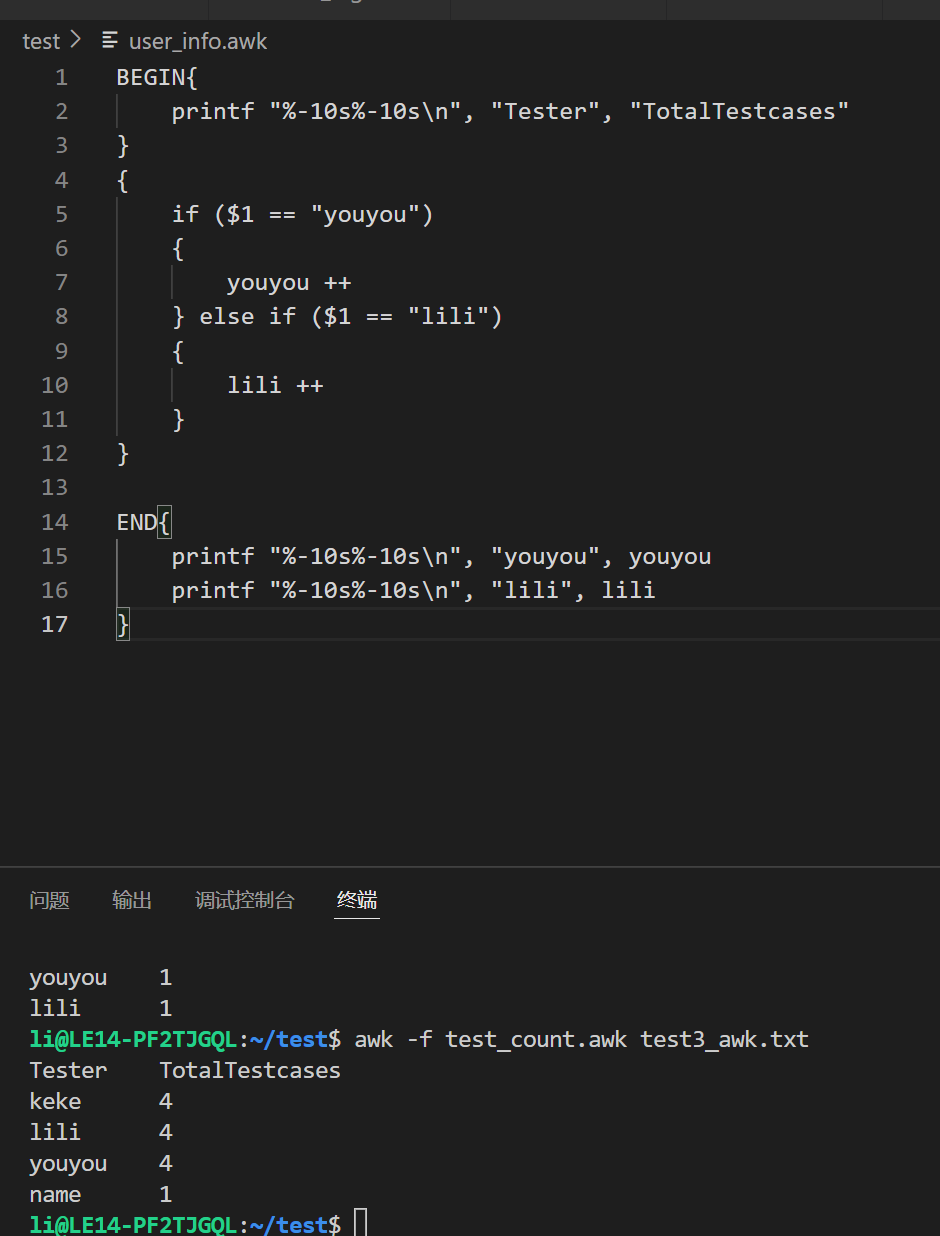
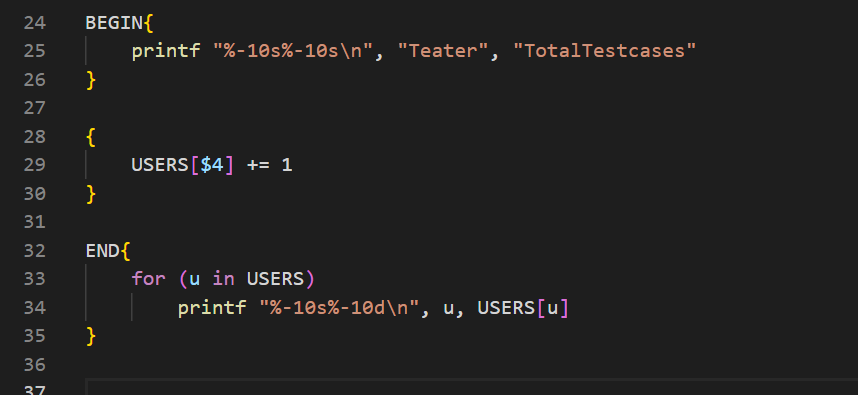
统计每位测试人员执行用例的总数
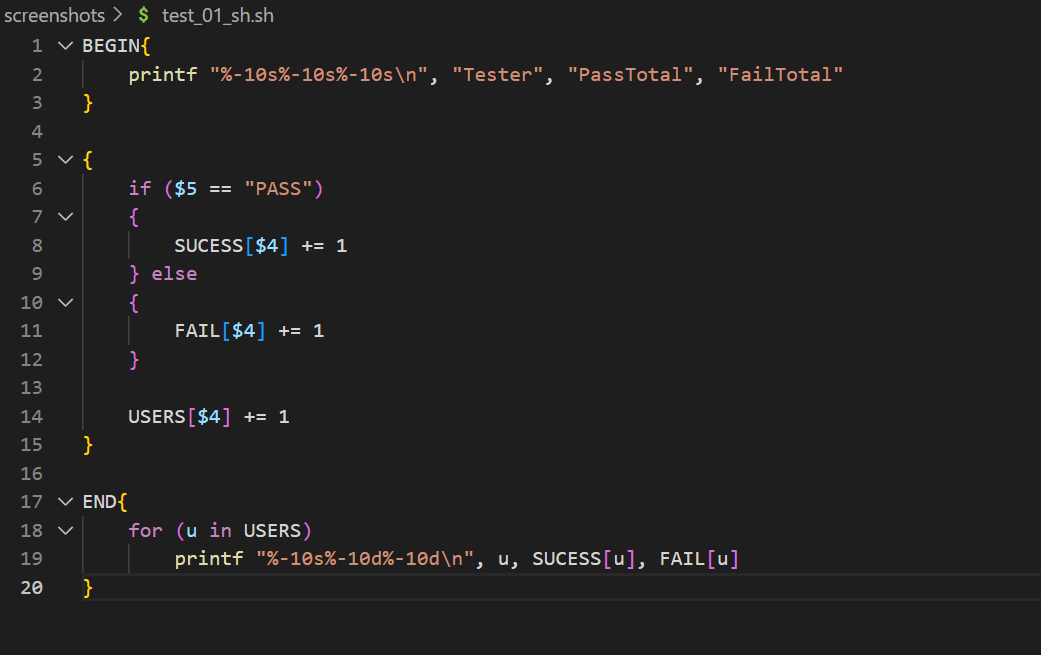
分别统计每位测试人员执行用例成功和失败的总数
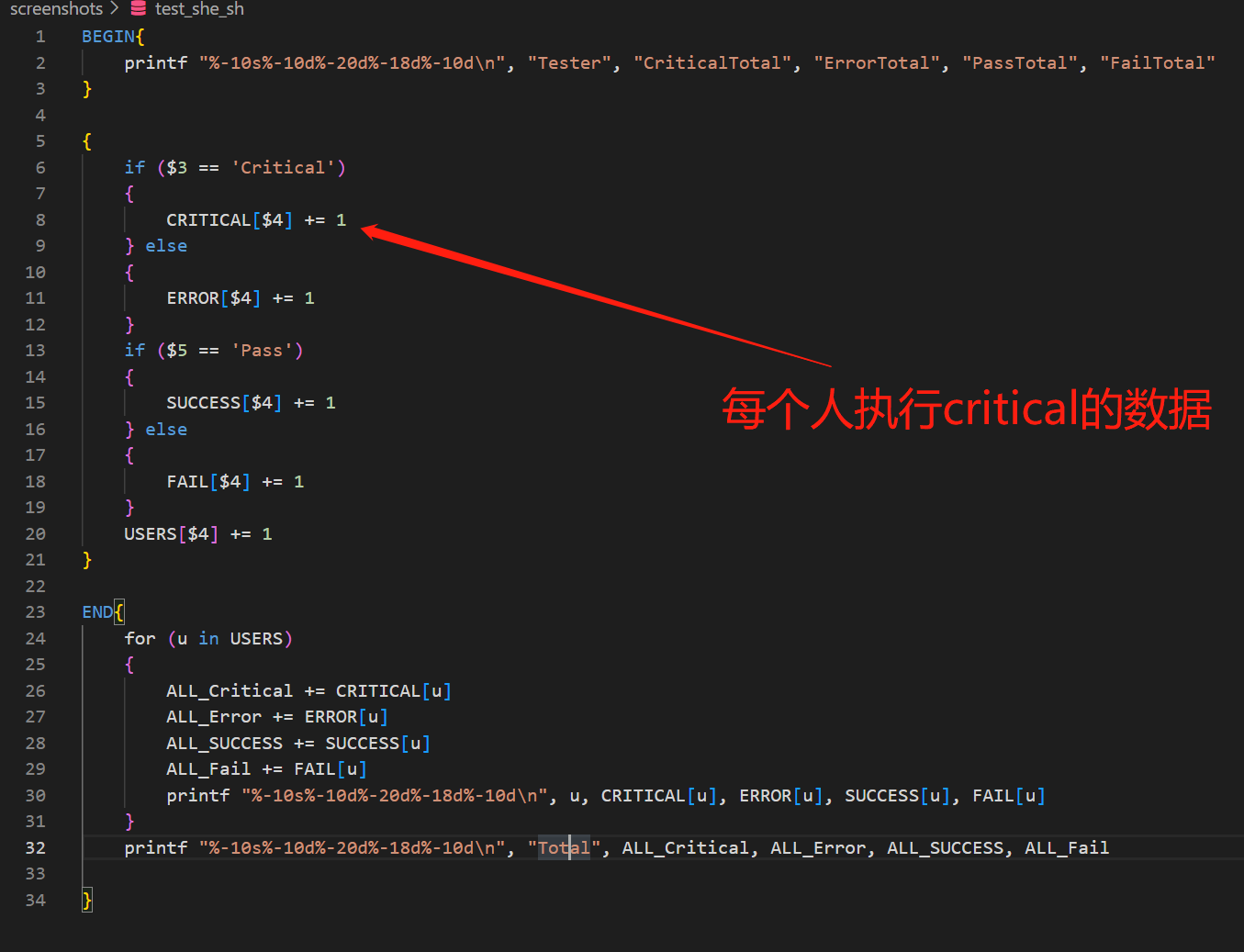
统计每位测试人员分别执行了多少条critical、error、success、fail 用例,以及每项的总和

 浙公网安备 33010602011771号
浙公网安备 33010602011771号