


1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
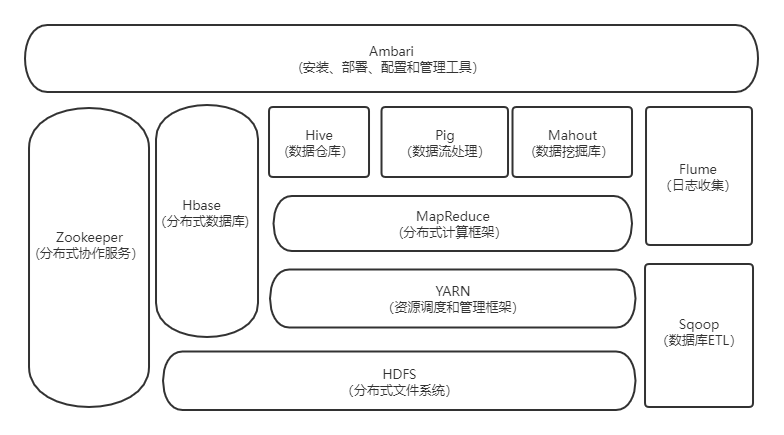
1.HDFS(分布式文件系统)
HDFS是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
2.YARN(资源调度和管理框架)
YARN 是负责集群资源调度管理的组件。
3.MapReduce(分布式计算框架)
MapReduce是分布式并行编程模型,用于大规模数据集的并行计算。
4.Hive(数据仓库)
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
5.Pig(数据流处理)
Pig是数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业
6.Mahout(数据挖掘库)
Mahout用于机器学习和数据分析。
7.Hbase(分布式列存数据库)
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
8.Zookeeper(分布式协作服务)
Zookeeper是协调服务。主要解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
9.Flume(日志收集工具)
Flume 是 一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
10.Sqoop(数据库ETL)
Sqoop主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
11.Ambari
Ambari是配置,监控和管理hadoop的平台。
2.对比Hadoop与Spark的优缺点。
| Hadoop | Spark | |
| 优点 |
1.具有按位存储和处理数据能力的高可靠性 2.通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性。 3.能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。 4.能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。 |
1.运算速度快 2.使用方便,支持多语言,本地调试很方便 3.丰富的操作算子 4.支持的场景多 5.生态完善、社区活跃,文档很全 |
| 缺点 |
1.不适用于低延迟数据访问 2.不能高效存储大量小文件 3.不支持多用户写入并任意修改文件 |
1.流式计算不咋地,功能不太全 2.资源消耗较高 |
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop MapReduce、HBase、Stom和Spark等,都可以运行再资源管理框架YARN之上,因此,可以再YARN之上进行统一的部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号