
优秀jvm原理和实战链接:https://developer.51cto.com/art/201201/312639.htm
1.JVM8内存模型:
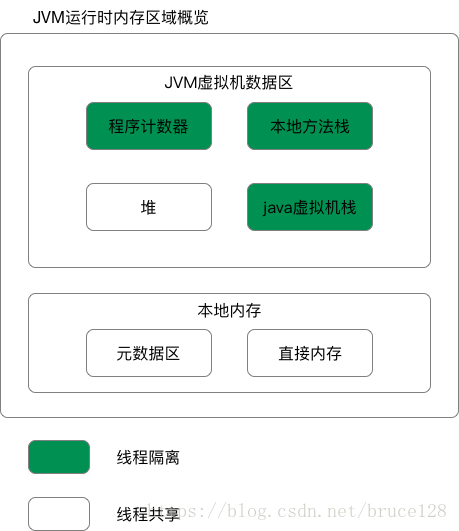
1.各区域介绍:
1. 程序计数器:
1.PC 寄存器,也叫程序计数器。
1.当前线程所执行的字节码的行号指示器;
2.当前线程私有;
3.不会出现OutOfMemoryError情况
2.JVM支持多个线程同时运行,每个线程都有自己的程序计数器。
3.倘若当前执行的是 JVM 的方法,则该寄存器中保存当前执行指令的地址;
4.倘若执行的是native 方法,则PC寄存器中为空(undefined)。
2. Java虚拟机栈:

1.每个线程有一个私有的栈,随着线程的创建而创建,其生命周期与线程同进同退。
2.栈里面存着的是一种叫“栈帧”的东西,每个Java方法在被调用的时候都会创建一个栈帧,一旦完成调用,则出栈。
3.所有的的栈帧都出栈后,线程也就完成了使命。
4.栈帧中存放了局部变量表(基本数据类型和对象引用)、操作数栈、动态链接(指向当前方法所属的类的运行时常量池的引用等)、方法出口(方法返回地址)、和一些额外的附加信息。
5.栈的大小可以固定也可以动态扩展。当栈调用深度大于JVM所允许的范围,会抛出StackOverflowError的错误,不过这个深度范围不是一个恒定的值。
1.线程私有,生命周期与线程相同;
2.java方法执行的内存模型,每个方法执行的同时都会创建一个栈帧,存储局部变量表(基本类型、对象引用)、操作数栈、动态链接、方法出口等信息;
3.StackOverflowError异常:当线程请求的栈深度大于虚拟机所允许的深度;
4.OutOfMemoryError异常:如果栈的扩展时无法申请到足够的内存。
3. 本地方法栈:
1.本地方法栈与Java栈的作用和原理非常相似。区别只不过是Java栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的.
4. 堆:
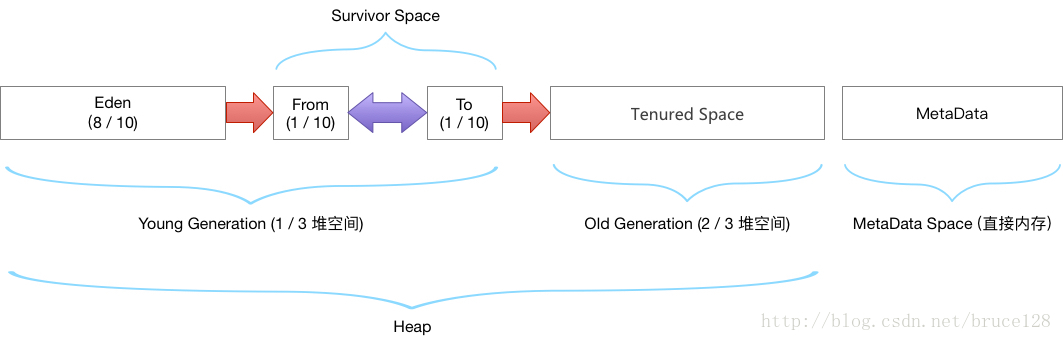
5. 元数据区
1.元数据区取代了1.7版本及以前的永久代。元数据区和永久代本质上都是方法区的实现。方法区存放虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
2.JDK 8 中永久代向元空间的转换的几点原因
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
2.JVM垃圾收集算法优化:
原文链接:https://www.cnblogs.com/csniper/p/5592593.html
1.根据Java虚拟机规范,JVM将内存划分为:
1.New(年轻代)
1.年轻代用来存放JVM刚分配的Java对象;
2.New又分为几个部分
1.Eden:Eden用来存放JVM刚分配的对象
2.Survivor1和Survivor2:两个Survivor空间一样大,当Eden中的对象经过垃圾回收没有被回收掉时,会在两个Survivor之间来回Copy,当满足某个条件,比如Copy次数,就会被Copy到Tenured。
2.Tenured(年老代)
1.年轻代中经过垃圾回收没有回收掉的对象将被Copy到年老代;
3.永久代(Perm)
1,永久代存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间;
4.其中New和Tenured属于堆内存,堆内存会从JVM启动参数(-Xmx:3G)指定的内存中分配;
5.Perm不属于堆内存,有虚拟机直接分配,但可以通过-XX:PermSize -XX:MaxPermSize 等参数调整其大小。
2.垃圾回收算法:
1.垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
1.Serial算法(单线程)
2.并行算法:并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行;
3.并发算法:并发算法,也是多线程回收,但期间不停止应用执行;
2.什么时候会发生GC?
1.当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC;
2.当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代;
3.当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载;
3.OutOfMemoryException如何发生?
1.并不是内存被耗空的时候才抛出
2. 满足这两个条件将触发OutOfMemoryException
1.JVM98%的时间都花费在内存回收
2.每次回收的内存小于2%
3.内存泄漏及解决方法:
1.系统崩溃前的一些现象:导致系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
1.每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s;
2.FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC;
3.年老代的内存越来越大并且每次FullGC后年老代没有内存被释放;
2.生成堆的dump文件
1.通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
3.分析dump文件
1.下面要考虑的是如何打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux。当然我们可以借助X-Window把Linux上的图形导入到Window。我们考虑用下面几种工具打开该文件:
- Visual VM
- IBM HeapAnalyzer
- JDK 自带的Hprof工具
2.使用这些工具时为了确保加载速度,建议设置最大内存为6G。
1.使用后发现,这些工具都无法直观地观察到内存泄漏,Visual VM虽能观察到对象大小,但看不到调用堆栈;
2.HeapAnalyzer虽然能看到调用堆栈,却无法正确打开一个3G的文件。
3.因此,我们又选用了Eclipse专门的静态内存分析工具:Mat。
4.分析内存泄漏
1.通过Mat我们能清楚地看到,哪些对象被怀疑为内存泄漏,哪些对象占的空间最大及对象的调用关系。
2.针对本案,在ThreadLocal中有很多的JbpmContext实例,经过调查是JBPM的Context没有关闭所致。
3.通过Mat或JMX我们还可以分析线程状态,可以观察到线程被阻塞在哪个对象上,从而判断系统的瓶颈。
5.回归问题
1.Q:为什么崩溃前垃圾回收的时间越来越长?
A:根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
2. Q:为什么Full GC的次数越来越多?
A:因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
3.Q:为什么年老代占用的内存越来越大?
A:因为年轻代的内存无法被回收,越来越多地被Copy到年老代
4.性能调优:
1.在CPU负载不足的同时,偶尔会有用户反映请求的时间过长,我们意识到必须对程序及JVM进行调优,以下几个方面:
1.Java线程池(java.util.concurrent.ThreadPoolExecutor):解决用户响应时间长的问题
1.Java线程池有几个重要的配置参数:
1.corePoolSize:核心线程数(最新线程数)
2.maximumPoolSize:最大线程数,超过这个数量的任务会被拒绝,用户可以通过RejectedExecutionHandler接口自定义处理方式
3.keepAliveTime:线程保持活动的时间
4.workQueue:工作队列,存放执行的任务。Queue的不同选择,线程池有完全不同的行为:
1.SynchronousQueue: 一个无容量的等待队列,一个线程的insert操作必须等待另一线程的remove操作,采用这个Queue线程池将会为每个任务分配一个新线程
2.LinkedBlockingQueue : 无界队列,采用该Queue,线程池将忽略 maximumPoolSize参数,仅用corePoolSize的线程处理所有的任务,未处理的任务便在LinkedBlockingQueue中排队
3.ArrayBlockingQueue: 有界队列,在有界队列和 maximumPoolSize的作用下,程序将很难被调优:更大的Queue和小的maximumPoolSize将导致CPU的低负载;小的Queue和大的池,Queue就没起动应有的作用。
2.连接池(org.apache.commons.dbcp.BasicDataSource):
3.JVM启动参数:
1.jvm调优原则(目标):
1.GC的时间足够的小
2.GC的次数足够的少
3.发生Full GC的周期足够的长
4.如果满足下面的指标,则一般不需要进行GC:
1.Minor GC执行时间不到50ms;Minor GC执行约10秒一次;
2.Full GC执行时间不到1s; Full GC执行不低于10分钟1次;
2.前两个目前是相悖的,要想GC时间小必须要一个更小的堆,要保证GC次数足够少,必须保证一个更大的堆,我们只能取其平衡:
(1)针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值;
(2)年轻代和年老代将根据:
1.默认的比例(1:2)分配堆内存;
2.可以通过调整二者之间的比率NewRadio来调整二者之间的大小;
3.也可以针对回收代,比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小。
(3)年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。我们观察一下二者大小变化有哪些影响
1.年轻代越大,必然导致年老代越小:
1.大的年轻代会减少普通GC的次数,但会增加每次GC的时间;
2.小的年老代会增加的Full GC频率;
2.年轻代越小,必然导致年老代越大:
1.小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;
2.大的年老代会减少Full GC的频率
3.如何选择应该依赖应用程序对象生命周期的分布情况:
1.如果应用存在大量的临时对象,应该选择更大的年轻代;
2.如果存在相对较多的持久对象,年老代应该适当增大。
3.但很多应用都没有这样明显的特性,在抉择时应该根据以下两点:
(1)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理
(2)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间
4.在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC ,默认为Serial收集
5.线程堆栈的设置:每个线程默认开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言默认值,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但实际上还受限于操作系统。
4.程序算法:改进程序逻辑,使用合理算法提高性能
5.调优工具:
1. dump:format=b,file=文件名.hprof pid 来dump内存,生成dump文件,并使用Eclipse下的mat差距进行分析
2.Eclipse MAT 安装及使用https://blog.csdn.net/kas_uo/article/details/80179856
3.垃圾收集器:
垃圾收集器总结文章:https://blog.csdn.net/SilenceOO/article/details/77869485?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-1.base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-1.base
1.收集器搭配:

2.年轻代收集器如下:
1.Serial收集器:
1.Serial收集器是在client模式下默认的新生代收集器,其收集效率大约是100M左右的内存需要几十到100多毫秒;
2.在client模式下,收集桌面应用的内存垃圾,基本上不影响用户体验。所以,一般的Java桌面应用中,直接使用Serial收集器(不需要配置参数,用默认即可)。
2.ParNew收集器:
1.Serial收集器的多线程版本,这种收集器默认开通的线程数与CPU数量相同,-XX:ParallelGCThreads可以用来设置开通的线程数。
2.可以与CMS收集器配合使用,事实上用-XX:+UseConcMarkSweepGC选择使用CMS收集器时,默认使用的就是ParNew收集器,所以不需要额外设置-XX:+UseParNewGC,设置了也不会冲突,因为会将ParNew+Serial Old作为一个备选方案;
3.如果单独使用-XX:+UseParNewGC参数,则选择的是ParNew+Serial Old收集器组合收集器。
4.一般情况下,在server模式下,如果选择CMS收集器,则优先选择ParNew收集器。
3.Parallel Scavenge收集器:
1.关注的是吞吐量(关于吞吐量的含义见上一篇博客),可以这么理解,关注吞吐量,意味着强调任务更快的完成,而如CMS等关注停顿时间短的收集器,强调的是用户交互体验。
2.在需要关注吞吐量的场合,比如数据运算服务器等,就可以使用Parallel Scavenge收集器。
2.老年轻收集器如下:
1.Serial Old收集器:
1.在1.5版本及以前可以与 Parallel Scavenge结合使用(事实上,也是当时Parallel Scavenge唯一能用的版本),另外就是在使用CMS收集器时的备用方案,发生 Concurrent Mode Failure时使用。
2.如果是单独使用,Serial Old一般用在client模式中。
2.Parallel Old收集器:
1.在1.6版本之后,与 Parallel Scavenge结合使用,以更好的贯彻吞吐量优先的思想,如果是关注吞吐量的服务器,建议使用Parallel Scavenge + Parallel Old 收集器。
3.CMS收集器:
1.这是当前阶段使用很广的一种收集器,国内很多大的互联网公司线上服务器都使用这种垃圾收集器(http://blog.csdn.net/wisgood/article/details/17067203),CMS收集器以获取最短回收停顿时间为目标,非常适合对用户响应比较高的B/S架构服务器。
4.CMSIncrementalMode:
1.CMS收集器变种,属增量式垃圾收集器,在并发标记和并发清理时交替运行垃圾收集器和用户线程。
3.G1 收集器:
1.面向服务器端应用的垃圾收集器,计划未来替代CMS收集器。G1的设计原则就是简单可行的性能调优。
2.G1收集器原理:

1.G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器。
2.不过,这些区域的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。
3.老年代也分成很多区域,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。
4.这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。
5.在G1中,还有一种特殊的区域,叫Humongous区域:
1.如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。
2.为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
3.对象分配策略,它分为3个阶段:
- TLAB(Thread Local Allocation Buffer)线程本地分配缓冲区
- TLAB为线程本地分配缓冲区,它的目的为了使对象尽可能快的分配出来。如果对象在一个共享的空间中分配,我们需要采用一些同步机制来管理这些空间内的空闲空间指针。
- Eden区中分配
- 在Eden空间中,每一个线程都有一个固定的分区用于分配对象,即一个TLAB。分配对象时,线程之间不再需要进行任何的同步。
- Humongous区分配
- 对TLAB空间中无法分配的对象,JVM会尝试在Eden空间中进行分配。如果Eden空间无法容纳该对象,就只能在老年代中进行分配空间
- TLAB(Thread Local Allocation Buffer)线程本地分配缓冲区
4.G1提供了两种GC模式,Young GC和Mixed GC:
1.G1的Young GC:
1.Young GC主要是对Eden区进行GC,它在Eden空间耗尽时会被触发。
2.在这种情况下,Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升到年老代空间。
3.Survivor区的数据移动到新的Survivor区中,也有部分数据晋升到老年代空间中。最终Eden空间的数据为空,GC停止工作,应用线程继续执行。
4.G1引进了RSet的概念。它的全称是Remembered Set,作用是跟踪指向某个heap区内的对象引用。
2.G1的 Mix GC:
Mix GC不仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的老年代分区。
它的GC步骤分2步:
- 全局并发标记(global concurrent marking),5个步骤:
- 初始标记(initial mark,STW)
在此阶段,G1 GC 对根进行标记。该阶段与常规的 (STW) 年轻代垃圾回收密切相关。 - 根区域扫描(root region scan)
G1 GC 在初始标记的存活区扫描对老年代的引用,并标记被引用的对象。该阶段与应用程序(非 STW)同时运行,并且只有完成该阶段后,才能开始下一次 STW 年轻代垃圾回收。 - 并发标记(Concurrent Marking)
G1 GC 在整个堆中查找可访问的(存活的)对象。该阶段与应用程序同时运行,可以被 STW 年轻代垃圾回收中断 - 最终标记(Remark,STW)
该阶段是 STW 回收,帮助完成标记周期。G1 GC 清空 SATB 缓冲区,跟踪未被访问的存活对象,并执行引用处理。 - 清除垃圾(Cleanup,STW)
在这个最后阶段,G1 GC 执行统计和 RSet 净化的 STW 操作。在统计期间,G1 GC 会识别完全空闲的区域和可供进行混合垃圾回收的区域。清理阶段在将空白区域重置并返回到空闲列表时为部分并发。
- 初始标记(initial mark,STW)
- 拷贝存活对象(evacuation)
- 全局并发标记(global concurrent marking),5个步骤:
5.三色标记算法
1.提到并发标记,我们不得不了解并发标记的三色标记算法。它是描述追踪式回收器的一种有用的方法,利用它可以推演回收器的正确性。 首先,我们将对象分成三种类型的。
1.黑色:根对象,或者该对象与它的子对象都被扫描
2.灰色:对象本身被扫描,但还没扫描完该对象中的子对象
3.白色:未被扫描对象,扫描完成所有对象之后,最终为白色的为不可达对象,即垃圾对象
